-
Pytorch数据集读出到transform全过程
最近写代码又遇见了这个问题,又忘记了,于是写一篇博客记录一下。
一般我们使用pytorch获取CIFAR10数据集,一般这样写:
mean = [0.4914, 0.4822, 0.4465] std = [0.2023, 0.1994, 0.2010] transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)]) dst_train = datasets.CIFAR10(data_path, train=True, download=True, transform=transform) dst_test = datasets.CIFAR10(data_path, train=False, download=True, transform=transform)- 1
- 2
- 3
- 4
- 5
最后出来的结果都是小数和xxx数。
Q1. 数据从读入到处理结束
如果使用了
ToTensoer,那么会将原始数据都归一化到0~1的范围内,数据都将除以255。


归一化之后,就是标准化,我们使用Normalize并传入mean和std,公式是:
o u t p u t = i n p u t − m e a n s t d output = \frac{input -mean}{std} output=stdinput−mean
注意!input已经被除255了。
这样就得到了最后的结果。Q.2 如何访问原始数据
其实数据一直都没有被修改,当你使用
dst_train = datasets.CIFAR10(data_path, train=True, download=True, transform=transform)- 1
得到一个训练集的时候,原始数据并没有被transform,数据其实一直保存在dst_train.data里
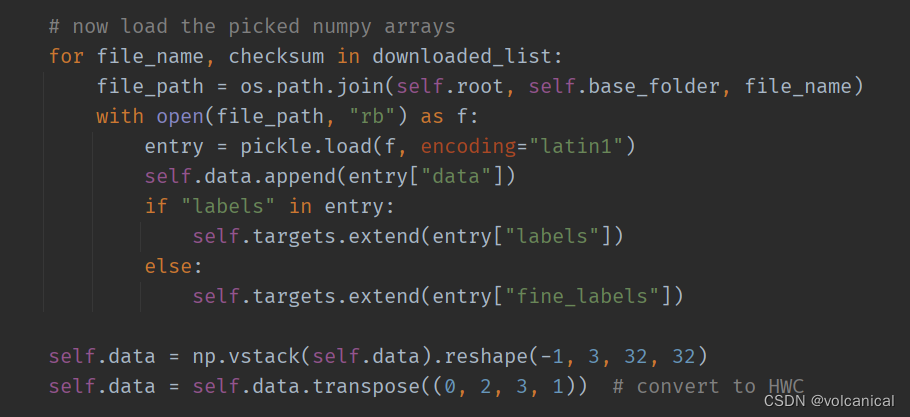
在迭代或者通过下标获取数据时,才会使用transform来修改数据。
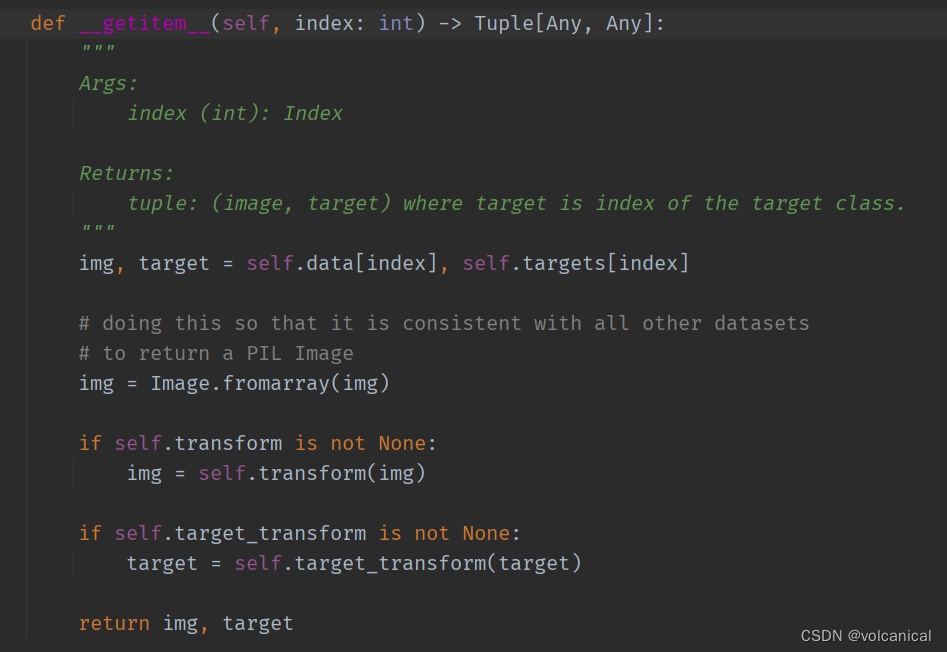
这个类维持一个data原始数据,因此有时候如果要修改数据,其实没必要去修改标准化后的数据,直接修改.data即可。如果有人做的是后门攻击,可以尝试一下重写CIFAR10数据集的类,重写__getitem__ 即可。
-
相关阅读:
跟着李老师学线代——矩阵(持续更新)
【C++】函数参数扩展 ( 默认参数 | 默认参数定义规则 | 默认参数定义在参数列表末尾 )
队列的基本操作(C语言实现)
商城数据库设计说明书
免费、强大的笔记软件推荐:Obsidian、Zettlr、Joplin、FlowUs
Oracle触发器设置
网站被大量cc攻击导致打不开怎么解决
《财富》500 强企业要求 curl 开源工具作者提供免费及时的支持;基于Chromium的Edge浏览器正在整合文本预测功能 | 开源日报
论文阅读记录--关于水文系统的传递函数
图像处理之彩色图像处理
- 原文地址:https://blog.csdn.net/huoshanshaohui/article/details/134407183