-
35 _ Trie树:如何实现搜索引擎的搜索关键词提示功能?
搜索引擎的搜索关键词提示功能,我想你应该不陌生吧?为了方便快速输入,当你在搜索引擎的搜索框中,输入要搜索的文字的某一部分的时候,搜索引擎就会自动弹出下拉框,里面是各种关键词提示。你可以直接从下拉框中选择你要搜索的东西,而不用把所有内容都输入进去,一定程度上节省了我们的搜索时间。

尽管这个功能我们几乎天天在用,作为一名工程师,你是否思考过,它是怎么实现的呢?它底层使用的是哪种数据结构和算法呢?
像Google、百度这样的搜索引擎,它们的关键词提示功能非常全面和精准,肯定做了很多优化,但万变不离其宗,底层最基本的原理就是今天要讲的这种数据结构:Trie树。
什么是“Trie树”?
Trie树,也叫“字典树”。顾名思义,它是一个树形结构。它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。
当然,这样一个问题可以有多种解决方法,比如散列表、红黑树,或者我们前面几节讲到的一些字符串匹配算法,但是,Trie树在这个问题的解决上,有它特有的优点。不仅如此,Trie树能解决的问题也不限于此,我们一会儿慢慢分析。
现在,我们先来看下,Trie树到底长什么样子。
我举个简单的例子来说明一下。我们有6个字符串,它们分别是:how,hi,her,hello,so,see。我们希望在里面多次查找某个字符串是否存在。如果每次查找,都是拿要查找的字符串跟这6个字符串依次进行字符串匹配,那效率就比较低,有没有更高效的方法呢?
这个时候,我们就可以先对这6个字符串做一下预处理,组织成Trie树的结构,之后每次查找,都是在Trie树中进行匹配查找。Trie树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。最后构造出来的就是下面这个图中的样子。
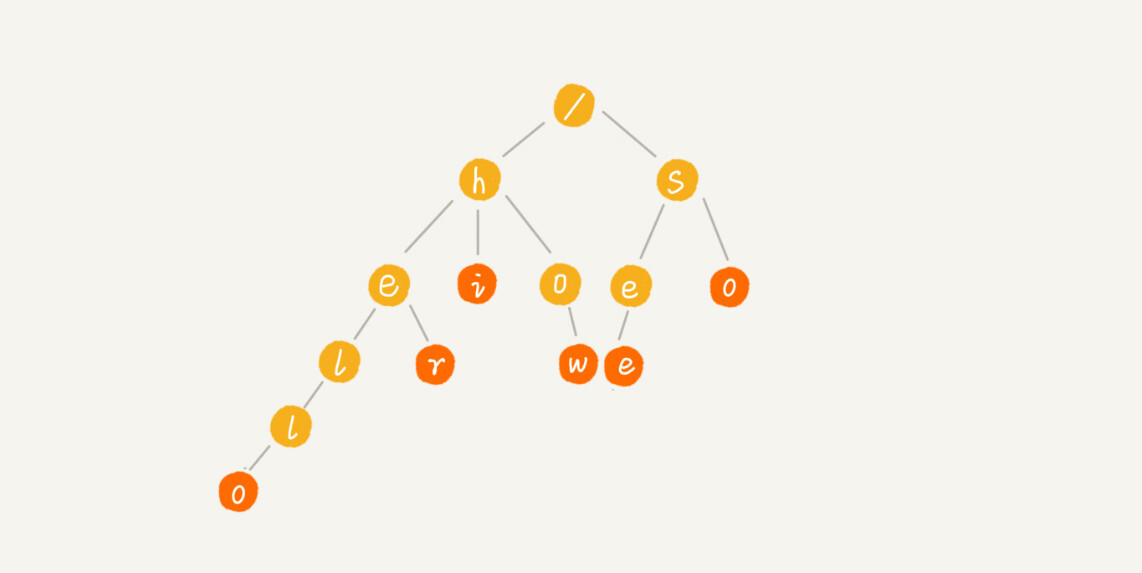
其中,根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串(注意:红色节点并不都是叶子节点)。
为了让你更容易理解Trie树是怎么构造出来的,我画了一个Trie树构造的分解过程。构造过程的每一步,都相当于往Trie树中插入一个字符串。当所有字符串都插入完成之后,Trie树就构造好了。


当我们在Trie树中查找一个字符串的时候,比如查找字符串“her”,那我们将要查找的字符串分割成单个的字符h,e,r,然后从Trie树的根节点开始匹配。如图所示,绿色的路径就是在Trie树中匹配的路径。
-
相关阅读:
【设计模式】第5节:创建型模式之“简单工厂、工厂方法和抽象工厂模式”
数字IC/FPGA面试题目合集解析(一)
RPC原理
面向对象回顾
【数据结构】树与二叉树(七):二叉树的遍历
大幅提升CLIP图像分类准确率-Tip-Adapter
【QT】QTableWidget
30天Python入门(第九天:深入了解Python中的条件语句)
九方云学堂学员告诉你学习可以掌握哪些内容
Linux:进程的状态理解
- 原文地址:https://blog.csdn.net/fujuacm/article/details/134206777