-
Producer
Producer开发样例
版本说明
新客
户端, 从Kafka 0.9.x 开始, client基于Java语言实现。同时提供C/C++, Python等其他客户端实现。开发步骤
- 配置客户端参数以及创建客户端实例;
- 构建待发送消息;
- 发送消息;
- 关闭生产者实例;
代码示例
public class KafkaProducer { public static Properties initConfig() { Properties props = new Properties(); props.put("bootstrap.server", "localhost:9092"); // key.serializer // value.serializer // client.id xxx return props; } public static void main(String[] args) { Properties props = initConfig(); KafkaProducer- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Producer参数配置
配置项目
部分配置项在后续文章中介绍
配置项 意义 bootstrap.servers broker列表(至少2个, client会从中得到所有) key.serializer 序列化key使用 value.serializer 序列化value使用 client.id 默认为"“,不设置会创建为"producer-1”,"producer-2"等 partitioner.class 为消息分配分区使用 interceptor.classes 执行消息拦截逻辑 小技巧
基本原则: 将拼写配置转换为代码编译, 借助代码编译器的校验能力来辅助检查
- 配置项拼写错误通过引用静态变量解决;
- key.serializer填写应该为全限定类名, 容易拼写错误, 可以基于Serializer.class.getName()来解决;
- KafkaProducer是ThreadSafe;
消息发送
消息构造
由于使用Kafka发送消息是一个非常频繁的动作, 因此ProduceRecord的构造也非常频繁。构造ProducerRecord对象, 必选属性key,value, 其他均为可选属性。
class ProduceRecord { String topic; Integer partition; Headers headers; // 增加应用相关信息 K key; // 相同key被发送到同一个partition, 支持消息压缩 V value; Long timestamp; // CreateTime 创建时间; LogAppendTime 追加到日志文件的时间; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
发送方式
Kafka Producer本身支持3种模式, 同步, 异步和发后即忘, 并且Kafka Producer在实现上做到了三种模式的统一。
Producer#send声明如下:Futuresend(ProducerRecord<> record); - 1
具体具体使用哪种模式, 取决于我们对返回值Future的处理。
模式实现 Future处理 同步 发送线程,Future#get获得结果 异步 非发送线程单独处理 发后即忘 不处理 关于异步模式, 实际中更多基于callback处理, 即调用send(record, callback)方法比较多, 避免应用侧对Future的管理。Producer内部可以保证对callback调用的顺序是分区有序。
class Callback{ public void onComplete(RecordMetadata meta, Exception e) {} }- 1
- 2
- 3
异常处理
发送异常一般由2种, 可重试异常(多由于集群处于一种状态迁移过程中, 比如Leader选举过程, partition rebalance过程)和不可重试异常(不满足硬性约束, 比如RecordTooLarge)。对于可重试异常, 如果配置了retries参数, KafkaProducer内部会自动重试给定次数, 依然不成功则抛出异常。
|发送模式| 结果 | 可靠性 vs 性能 |
|—|—|—|—|
|同步| 成功或异常 | 可靠性最好但牺牲性能 |
|异步| 成功或异常 | 兼顾可靠性和性能 |
|发送即忘| 不确定 | 性能最好牺牲可靠性 |资源释放
直接通过close()或者close(long timeout, TimeUnit timeUnit)方法完成。后者支持等待一定时间, 建议基于后者来完成, 实际应用中的关闭是个复杂的过程, 也是会受到协作应用影响的过程, 但好在最终由操作系统兜底完成资源释放。底线是避免应用侧产生错误数据, 因此如何关闭是个case by case的选择。
serializer
作用
发送侧: 将待发送的对象转换为byte[], 在网络上传输。
接受侧: 将接收到的byte[]转换为Java对象, 在应用中处理。常见类型
Byte、Short、Long、Float、Double、String对应的Serializer。当然也可以自己实现Serializer。
约束
发送侧和接收侧应该使用兼容的Serialzer, 否则无法进行消息解码, 因此建议使用通用serilizer。
partitioner
作用
给待发送的消息分配消息分区。如果ProducerRecord中的partition字段已设置, 则Partitioner不起作用, 否则将由Partitioner决定消息分区。
默认与自定义
Kafka默认的Partioner是DefaultPartioner。我们可以基于Partioner接口进行自定义, 自定义Partitioner可以通过partitioner.class来显示指定。
使用案例
大型电商存在多个仓库, 使用仓库名称或者ID作为key, 灵活记录商品/发单信息。
Producer Interceptor
声明与作用
ProducerInterceptor声明
ProducerRecord- 1
- 2
- 3
KafkaProducer在消息序列化和分区前调用onSend, 在有发送结果后调用onAcknowledgement,该方法提前于Callback执行。
自定义实现后需要在配置项interceptor.classes中声明。
拦截器可以按顺序形成拦截器链, Kafka的拦截器链会从上一个执行成功的上下文继续执行, 如果拦截器出现异常, 可能产生副作用。使用场景
- 类型于Java Web开发中的Filter, 增加一些通用的规则性逻辑, 比如增加统一前缀。
整体流程
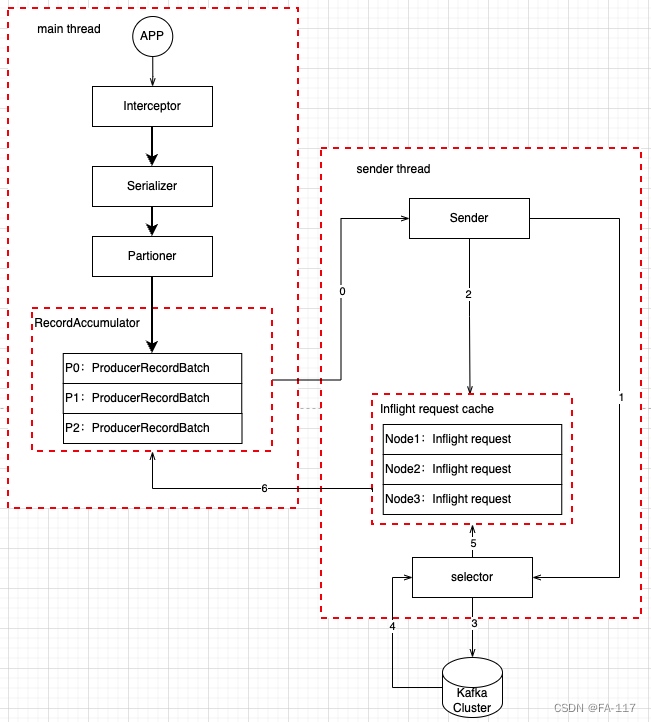
消息发送过程涉及两个关键线程main和sender。Main Thread中, 应用侧完成消息放入RecordAccumulator中。sender则轮询RecordAccumulator, 完成消息发送。
其中RecordAccumulator, 按照partion完成消息合并, 将消息发送单位从逐条发送, 转变为按批发送, 从而提高消息发送效率。
Sender则将每个partion的消息转换为面向每个Node的请求, 毕竟partion是个逻辑概念, node才是物理存在的。
在整个发送过程中, producer需要知道cluster对应的metadata, 例如node/partion对应关系等, 从而及时调整目标Node。这里也涉及metadata更新等问题。这里仅做简要说明, 后续文章中做进一步阐述。
总结
本文介绍了Kafka Producer发送数据中涉及的线程和各自的职责,重点介绍了与应用直接相关的Interceptor, Serializer和Partitioner。希望能帮助你初步认识Kafka, 感谢你的阅读。
-
相关阅读:
使用GPT和FastAPI构建智能数据库查询服务器
Windows内核对象
【华为OD机试真题 JS】找最小数
Linux下jar包的运行、查看、终止
字符串排序
RabbitMQ工作模式-主题模式
Redis的下载与安装
Kubernetes Pod调度策略
C++和汇编混编开发
Linux网络编程学习笔记(TCP)
- 原文地址:https://blog.csdn.net/weilaizhixing007/article/details/134358233
