-
Flink -- 状态与容错
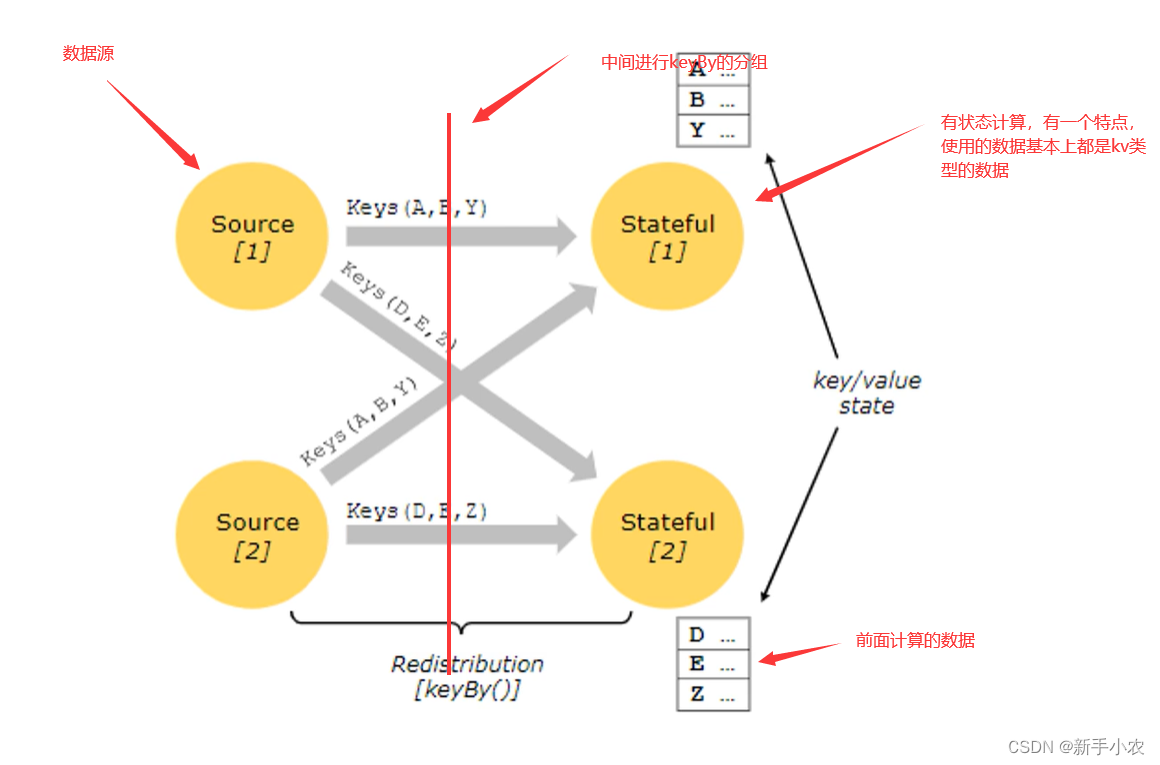
1、Stateful Operations 有状态算子:
有状态计算,使用到前面的数据,常见的有状态的算子:例如sum、reduce,因为它们在计算的时候都是用到了前面的计算的结果
总结来说,有状态计算并不是独立存在的,每一次的计算都与前面的数据是有关系的。所有的聚合算子都是有状态算子。
2、CheckPoint:
1、CheckPoint:定时将Flink的计算的状态持久化到Hdfs上,如果Flink的任务失败可以基于Hdfs中保存的状态恢复任务,能够保证任务的计算状态不丢失。checkpoint可以维护TB级别的计算状态。
2、Fllink会将计算状体存储两份,一份是存储在Flink内存中,放在内存中是为了获取查询更新,因为Flink在处理数据的是过程中,计算状态会改变,第二份是通过CheckPoint将计算状态持久化的存储到Hdfs中,这样可以保证Flink任务失败的时候可以基于Hdfs中存储的计算状态恢复任务。
总结:就是原先Flink的计算的状态是存储在内存中,但是为了防止计算状态丢失,就将Flink的计算状态持久化到Hdfs中。当任务中途失败后,找到最新的一个checkpoint,基于这个checkpoint中存储的数据作为计算状态恢复任务。
3、CheckPoint的开启方式:
1、在代码中单独开启checkpoint:
- // 每 10000ms 开始一次 checkpoint
- env.enableCheckpointing(10000)
- // 高级选项:
- // 设置模式为精确一次 (这是默认值)
- env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
- // 确认 checkpoints 之间的时间会进行 500 ms
- env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
- // Checkpoint 必须在一分钟内完成,否则就会被抛弃
- env.getCheckpointConfig.setCheckpointTimeout(60000)
- // 允许两个连续的 checkpoint 错误
- env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)
- // 同一时间只允许一个 checkpoint 进行
- env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
- // 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
- env.getCheckpointConfig.setExternalizedCheckpointCleanup(
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
- //增量快照
- env.setStateBackend(new EmbeddedRocksDBStateBackend(true))
- //将状态保存到hdfs中
- env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/file/checkpoint")
- public class Demo01CheckPoint {
- public static void main(String[] args) throws Exception{
- /**
- * 使用checkpoint来保存计算状态
- */
- //构建Flink环境:
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- //开socket
- DataStreamSource
lineDS = env.socketTextStream("master", 8888); - //开启checkpoint
- //指定10秒拍一次checkpoint
- env.enableCheckpointing(10000);
- //使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
- env.getCheckpointConfig().setExternalizedCheckpointCleanup(
- CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
- //将计算状态保存到hdfs中
- env.getCheckpointConfig().setCheckpointStorage("hdfs://master:9000/file/checkpoint");
- //指定计算状态在Flink中的存储的位置:是基于磁盘还是存储在内存中
- //HashMapStateBackend(),表示的是数据存储在Flink的内存中
- env.setStateBackend(new HashMapStateBackend());
- //做wordCount
- SingleOutputStreamOperator
wordDS = lineDS.flatMap((line, out) -> { - String[] split = line.split(",");
- for (String word : split) {
- //将数据循环发送到下游:
- out.collect(word);
- }
- },Types.STRING);
- //将上游传输过来的数据构建成kv形式的数据:
- SingleOutputStreamOperator
- //将构建好的数据进行分组
- KeyedStream
- //统计数量
- SingleOutputStreamOperator
- //打印数据
- countDS.print();
- //执行Flink:
- env.execute();
- }
- }
2、在集群中统一开启checkpoint:
修改flink-conf.yaml配置文件- # 修改以下配置
- execution.checkpointing.interval: 5000
- execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
- execution.checkpointing.max-concurrent-checkpoints: 1
- execution.checkpointing.min-pause: 0
- execution.checkpointing.mode: EXACTLY_ONCE
- execution.checkpointing.timeout: 10min
- execution.checkpointing.tolerable-failed-checkpoints: 0
- execution.checkpointing.unaligned: false
- state.backend: hashmap
- state.checkpoints.dir: hdfs://master:9000/file/checkpoint
在hdfs中查看checkpoint文件:
hdfs dfs -ls /file/checkpoint/用可视化界面查看checkpoint的信息:
 3、提交任务
3、提交任务例如: 使用yarn-session.sh -d 启动Flink集群:提交jar包,两种方式,第一种是通过网页的自动提交,第二种是通过session命令提交。
第一次提交任务:在使用命令行的模式提交jar包的时候需要注意的是:第一次提交任务的时候可以直接提交:例如:
- 使用session提交任务:
- flink run -t yarn-session -Dyarn.application.id=application_1698996244566_0009 -c flink.core.Demo1WordCount flink-1.0.jar
当第一次提交后并失败,重启任务:当任务失败过后,并且开启了checkpoint,重启任务:
flink run -t yarn-session -Dyarn.application.id=application_1698996244566_0009 -s hdfs://master:9000/file/checkpoint/deed690403e740b734ea62fcd1963daf/chk-33 -c flink.core.Demo1WordCount flink-1.0.jar当选择在页面再次提交任务,需要指定最新的checkpoint的文件的位置:

需要注意的是当使用checkpoint做快照的时候,会在指定的时间拍一次快照,并生成一个新文件来覆盖前面旧的文件存储在hdfs上面。

3、checkpoint的原理:
1、首先JobManager中的checkpoint Coonaotr checkpoint控制器会定期的向source task 发送checkpoint trigger
2、source task 就会在数据流中安插checkpoint barrier,就像一个挡板一样的
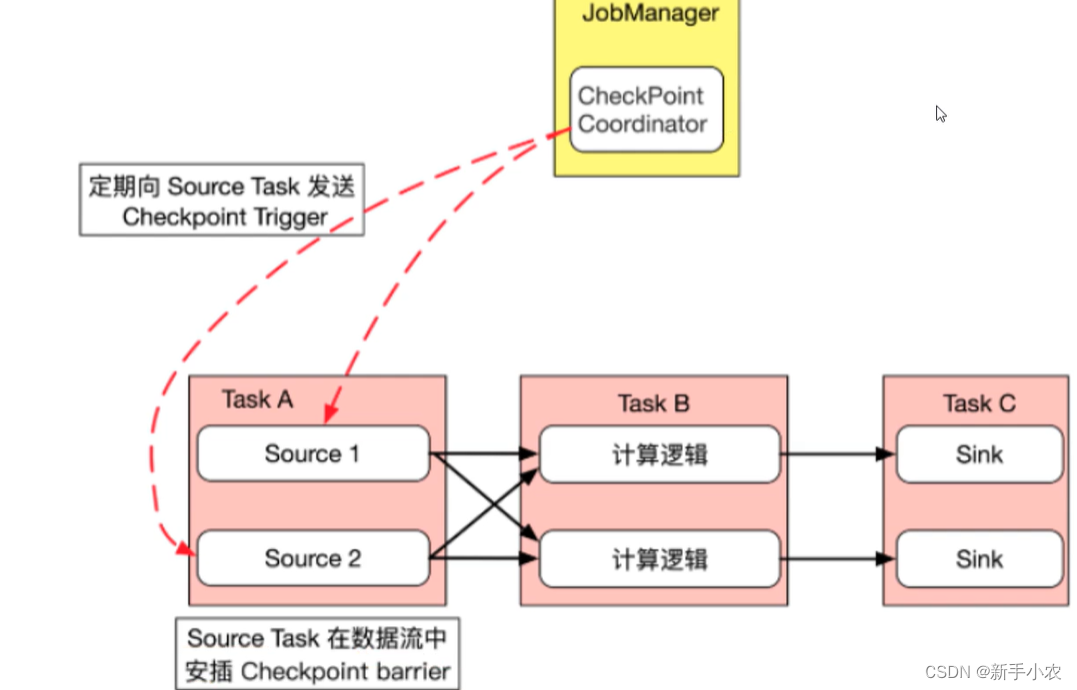
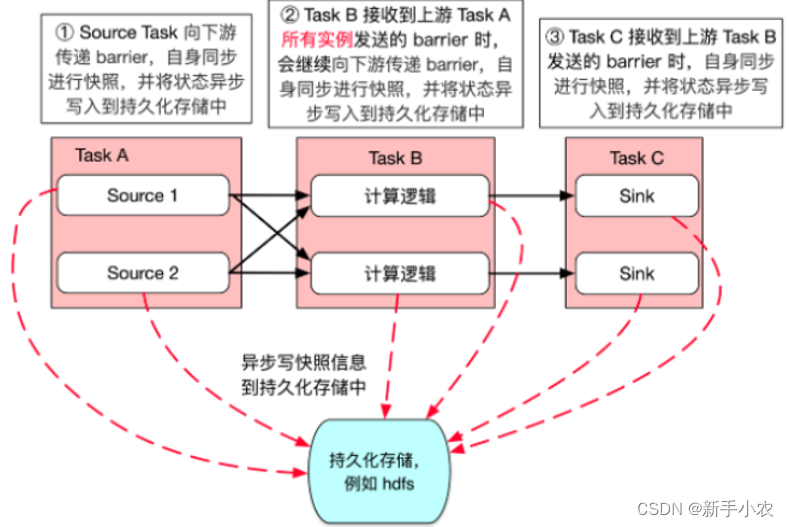
3、source task 向下游传递barrier,自生也会同步快照,并将状态持久化写入到hdfs中。
4、Task B接收到上游Task A所有实例发送的barrier 时,会继续向下游传递barrier,自身同步进行快照,并将状态持久化写入到hdfs中
5、Task C接收到上游Task B发送的 barrier时,自身同步进行快照,并将状态异步写持久化写入到hdfs中
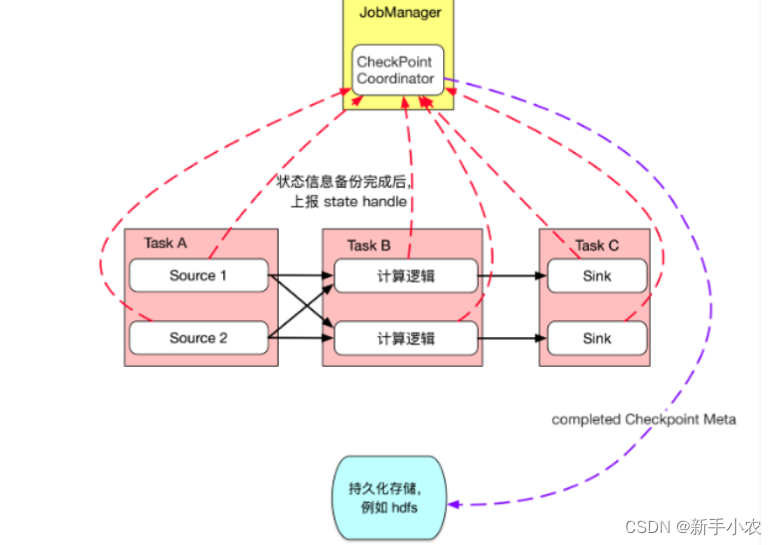
6、状态信息备份完成以后上报state handle
4、Keyed State
1、ValueState(单值状态):
保存一个可以更新和检索的值(例如每一个值都对应到当前的输入数据key,因此算子接收到的每一个key都有可能对应一个值),这个值可以通过updata进行更新,可以通过value进行检索。flink的ValueState状态,会对每一个key都保存一个值,并且可以更新,数据会被checkpoint定期的存储到hdfs中做持久化。
- public class Demo02ValueState {
- public static void main(String[] args) throws Exception{
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(2);
- DataStream
wordsDS = env.socketTextStream("master", 8888); - //安装单词分组
- KeyedStream
- DataStream
- .process(new KeyedProcessFunction
- //Flink中的单值状态valueState,对于Flink来说,如果使用的是HashMap来说,虽然对于不同的key是可以用来存储
- // 但是数据是存储在内存中,如果中途任务失败,那么任务重新启动的难度会比较大
- //flink的ValueState状态,会对每一个key都保存一个值,并且可以更新,数据会被checkpoint定期的存储到hdfs中做持久化。
- //需要重写open方法:是每一个task启动的时候会执行一次,用于对任务的初始化
- ValueState
state; - @Override
- public void open(Configuration parameters) throws Exception {
- //获取flink的执行上下文对象,使用上下文对象进行初始化
- RuntimeContext context = getRuntimeContext();
- //创建描述对象,描述状态的类型和名称:
- ValueStateDescriptor
count = new ValueStateDescriptor<>("count", Types.INT); - //获取状态
- state = context.getState(count);
- }
- @Override
- public void processElement(String word,
- KeyedProcessFunction
- Collector
- //从中间获取单词的数量,返回值的类型是一个包装类,所以返回的值如果是空就会使用null表示
- Integer count = state.value();
- if(count==null){
- count=0;
- }
- count++;
- //将单词的数量返回出去
- state.update(count);
- //将结果返回到下游:
- out.collect(Tuple2.of(word,count));
- }
- });
- countDS.print();
- env.execute();
- }
- }
2、ListState
: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索,可以通过add或者是addall进行添加元素,通过Iterable get ()获取整个列表,还可以通过update(list
)来覆盖当前的列表。 3、ReducingState
: 保存一个值,表示添加到状态的所有值的聚合。接口与ListState类似,但是使用add添加元素,时使用提供的ReduceFuncation进行聚合。
4、AggregatingState
保留一个单值,表示添加到状态的所有值的集合。与ReducingState相反,聚合类可能与添加到状态的元素的类型不同,接口与ListState类似,但是使用add(IN)天机的元素会使用指定的AggregateFunction进行聚合
5、MapState
维护了一个映射列表,可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用put(UK,UV)或者是ptuALL(Map
entries(),keys()和values()分别检索映射、键和值的可迭代视图。你还可以通过isEmpty()来判断是否包含任何键值对。5、数据处理的语义:
1、主要分成三种:Exactly Once(唯一一次)、至少一次、最多一次
2、Exactly Once:指的是数据不多不少只会被处理一次
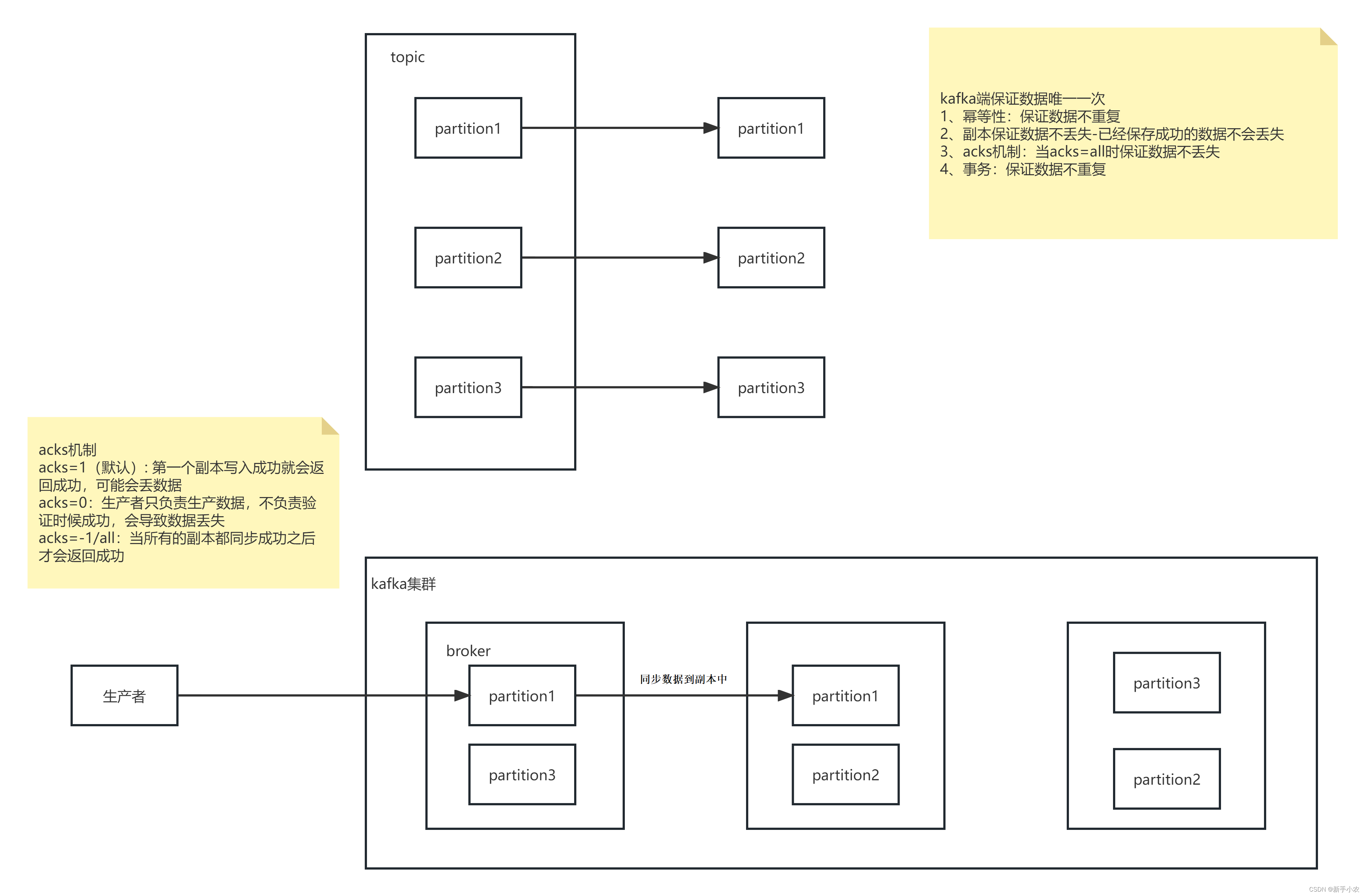
3、kafka唯一一次:
1、数据生产端唯一一次:
a、kafka 0.11之后,Producer的send操作现在是幂等的,保证了数据的不重复,在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次。
b、ACKS机制+副本,保证数据不丢失
副本:保证存储到kafka副本中的数据不会丢失
ACKS机制:
- acks机制:
- acks=1 (一般默认)第一个副本写入成功后就会返回成功,可能会丢失会丢失数据
- acks=0 生产者只负责写入数据,不负责验证数据是否成功,可能会丢失数据
- acks=-1/all 当所有的副本都同步成功之后才会返回成功
- kafka端保证数据的唯一一次:
- 1、幂等性:保证数据不重复
- 2、副本:保证成功存入的数据不丢失
- 3、acks机制:当acks的结果是all的时候数据不丢失
- 4、事务:保证数据不重复

2、数据消费端:
a、Flink 分布式快照保存数据计算的状态和消费的偏移量,保证程序重启之后不丢失状态和消费偏移量

3、Sink端:
a、将Flink的结果数据再写入到kafka中
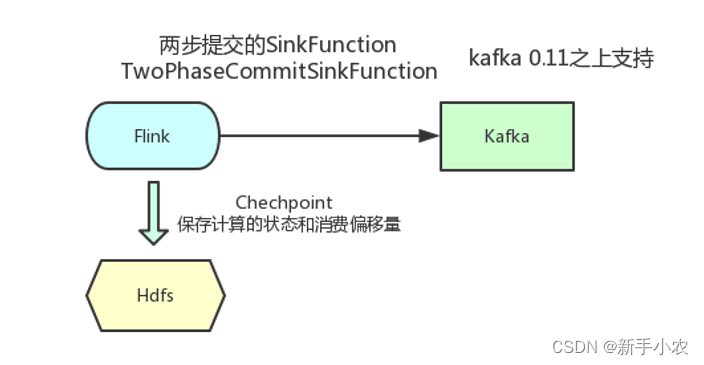

如果任务在执行过程中失败,恢复到原先的状态,此时在将结果写入到Kafka中,就有可能会有重复的数据,想要保证数据的不重复,就在两个checkpoint中间的数据存放一个事务中。当前一个事务开始,到后面的一个事务提交,一个事务才算提交完成,如果中间出现错误,此时任务就会失败,就不会导致数据重复,但是会产生延迟。
b、将数据写入kafka的唯一一次
- public class Demo5KafkaExactlyOnce {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- //构建kafka source
- KafkaSource
source = KafkaSource. builder() - //指定broker列表
- .setBootstrapServers("master:9092,node1:9092,node2:9092")
- //指定topic
- .setTopics("in")
- //消费者组
- .setGroupId("my-group")
- //指定读取数据的位置:earliest:读取最早的数据, latest: 读取最新的数据
- .setStartingOffsets(OffsetsInitializer.earliest())
- //读取数据的格式
- .setValueOnlyDeserializer(new SimpleStringSchema())
- .build();
- //使用 kafka source
- DataStreamSource
kafkaDS = env - .fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
- //堆数据进行清洗过滤
- SingleOutputStreamOperator
filterDS = kafkaDS - .filter(word -> !"java".equals(word));
- Properties properties = new Properties();
- //设置事务超时时间
- properties.setProperty("transaction.timeout.ms", String.valueOf(10 * 60 * 1000));
- //创建kafka sink
- KafkaSink
sink = KafkaSink. builder() - //kafka broker列表
- .setBootstrapServers("master:9092,node1:9092,node2:9092")
- //指定而外的配置
- .setKafkaProducerConfig(properties)
- //指定数据的格式
- .setRecordSerializer(KafkaRecordSerializationSchema.builder()
- //指定topic,如果topic不存在会自动创建一个分区为1副本为1的topic
- .setTopic("out1")
- //指定数据格式
- .setValueSerializationSchema(new SimpleStringSchema())
- .build()
- )
- //指定数据处理的语义
- //EXACTLY_ONCE:唯一一次,flink会将两次checkpoint中间的结果放到一个事务中,要么都成功要么都失败
- .setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
- .build();
- filterDS.sinkTo(sink);
- env.execute();
- }
- }
- #向kafka中生产新的数据
- kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic in
- #1、第一次直接提交
- flink run -t yarn-per-job -c flink.state.Demo5KafkaExactlyOnce flink-1.0.jar
- #2、任务执行失败重启
- flink run -t yarn-per-job -c flink.state.Demo2ExactlyOnce -s hdfs://master:9000/flink/checkpoint/3c1e5dcabcd934a6d93ab6af04f10ca9/chk-5 flink-1.0.jar
- #消费数据时需要设置只读已提交
- # read_committed: 读已提交数据,
- kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --isolation-level read_committed --from-beginning --topic out
6、checkpoint的主要流程:
1、首先Flink在计算的过程中会产生有状态算子,首先会默认将状态算子存储到TaskManager内存中,如果数据源是来时Kafka,此时Kafksa中的source task会将偏移量也保存到状态中,一同存储到TaskManager内存中。
为什么会存储偏移量:任务失败重启过后,可以通过偏移量获取失败前任务读取数据的位置,再从这个位置开始读取数据。
2、然后在被checkpoint定时持久化到Hdfs中
3、当任务失败重启后,基于HDFS中的存储的数据,重启启动任务,会将HDFS中存储的状态读取到TaskManager内存中。
7、数据容错的过程,保证数据不丢失的:
对于上游的Task和下游的Task是同时做checkpoint还是在同一条数据做checkpoint?
Flink的流处理的过程中时Task是在同一条数据做checkpoint,例如图所示,
1、在使用kafka当作数据源的时候,source task 会在数据里中安插一个挡板
2、当上游的Task任务和下游的Task都到达第一个挡板的位置时都会做checkpoint,此时在内存中状态入图所示就是[偏移量:4 ,计算的结果是:a:2,b:1,c:1,d:1]
3、当任务在执行的过程中,任务失败,此时就会将状态恢复到第一次checkpoint的位置,再重新启动任务读取数据。
4、需要注意的是对于数据源,必须是可重复读取的数据源,假设任务指定到图中箭头位置失败,此时在会恢复到快照的位置,如果数据不能重复读,那么中间的数据就会丢失。

-
相关阅读:
C语言的结构体
教育src漏洞挖掘-2022-白帽必挖出教程
数据治理:微服务架构下的数据治理
kafka集群穿透到公网实现过程
数字化转型的必备工具:智能呼叫中心系统的应用
java高级——类加载机制
Mac 安装PHP swoole扩展
Linux 内核启动分析
Kotlin 协程调度切换线程是时候解开真相了
短出行日渐成熟,电动两轮车迎来下半场
- 原文地址:https://blog.csdn.net/m0_62078954/article/details/134277071
