-
【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割5(训练篇)
在本系列的开篇,就对整个项目训练所需要的所有模块都进行了一个简要的介绍,尤其是针对训练中需要引入的各个结构,进行一个串联介绍。
而在之前的数据构建篇和网络模型篇中,都对其中的每一个组块进行了分别的验证。预先在未开始训练前,检验其中各个模块的正确性,避免在训练时候,问题连连,着实抓马。
通过这一系列文章的学习后,我相信绝大部分的模块都已经介绍过了。包括:
- 综述篇中对优化器、模型获取和保存模型进行了介绍;
- 在数据流模块中,学习了如何导入数据,验证数据流;
- 网络模型那里,损失函数
loss的调用。
本篇其实存在的最大意义,就在于将这些零零散散的东西,拼接成一个整体。至于推理阶段,将单独新开一节,放到后面。通过这个系列的学习,也能多一些思考,加深一些感悟。
一、损失函数
在分割任务中,把目标分割任务的
mask,转化为对像素点的分类任务。所以在计算损失的时候,论文里面的损失函数采用的就是交叉熵损失函数。在后续的损失改进中,多引入
dice loss或focal loss。我们就从交叉熵损失函数开始,探讨下它为什么可以应用在分割任务中。本文继续沿着在网络模型评估阶段,使用的交叉熵损失函数,定义如下。对于其他分割的损失函数,参考这篇文章:【AI面试】CrossEntropy Loss 、Balanced Cross Entropy、 Dice Loss 和 Focal Loss 分类损失横评:
1.1、CrossEntropyLoss
在上一篇关于网络模型中,对模型的测试阶段,引入了交叉熵损失函数。链接在这:【3D图像分割】基于 Pytorch 的 VNet 3D 图像分割3(3D UNet 模型篇)。其中引入
loss的方式,如下这样:expected_output_shape = (batch_size, num_out_classes, 64, 64, 64) assert output.shape == expected_output_shape, "Unexpected output shape, check the architecture!" # Defining loss fn ce_layer = torch.nn.CrossEntropyLoss() # Calculating loss ce_loss = ce_layer(output, ground_truth) print("CE Loss = {}".format(ce_loss))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其中,
ground_truth的大小是BxDxHxWoutput的大小是BxCxDxHxW- 对于输入的预测张量,通常会在C维度上进行softmax操作,使得每个通道(类别)的输出值都在
[0,1]范围内,并且所有通道的输出值之和为1。 - 这样做的目的是将预测结果转换成概率分布,方便计算交叉熵损失。
- 在
PyTorch中,torch.nn.CrossEntropyLoss()函数会自动将输入进行softmax操作。
1.2、Dice loss
Dice系数中的"Dice"实际上是一位科学家名字的缩写,其全名是Sørensen–Dice coefficient,常被称为Dice similarity coefficient或者F1 score。它由植物学家Thorvald Sørensen和Lee Raymond Dice独立研制,分别于1948年和1945年发表。Dice系数是一种常见的相似度计算方法,主要用于计算两个集合的相似度。在
Dice Loss中,用 Dice 系数来计算预测结果和真实标签的相似度,因此得名Dice Loss。dice coefficient定义如下:
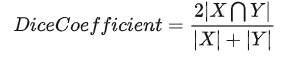
如果看作是对像素点类别的分类任务,也可以写成:
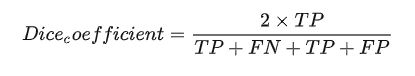
于是,
dice loss就可以表示为:
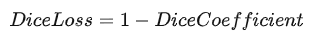
Dice系数的中文名称为“Dice相似系数”或“Dice相似度”,因此 Dice Loss 也可以称为“Dice相似度损失”或“Dice相似系数损失”。multi dice loss定义如下:import torch import numpy as np def one_hot_encode(label, num_classes): """ Torch One Hot Encode :param label: Tensor of shape BxHxW or BxDxHxW :param num_classes: K classes :return: label_ohe, Tensor of shape BxKxHxW or BxKxDxHxW """ assert len(label.shape) == 3 or len(label.shape) == 4, 'Invalid Label Shape {}'.format(label.shape) label_ohe = None if len(label.shape) == 3: label_ohe = torch.zeros((label.shape[0], num_classes, label.shape[1], label.shape[2])) elif len(label.shape) == 4: label_ohe = torch.zeros((label.shape[0], num_classes, label.shape[1], label.shape[2], label.shape[3])) for batch_idx, batch_el_label in enumerate(label): for cls in range(num_classes): label_ohe[batch_idx, cls] = (batch_el_label == cls) label_ohe = label_ohe.long() return label_ohe def dice(outputs, labels): eps = 1e-5 outputs, labels = outputs.float(), labels.float() outputs, labels = outputs.flatten(), labels.flatten() intersect = torch.dot(outputs, labels) # 对应元素相乘再相加 union = torch.add(torch.sum(outputs), torch.sum(labels)) dice_coeff = (2 * intersect + eps) / (union + eps) dice_loss = 1 - dice_coeff return dice_loss def dice_n_classes(outputs, labels, do_one_hot=False, get_list=False, device=None): """ Computes the Multi-class classification Dice Coefficient. It is computed as the average Dice for all classes, each time considering a class versus all the others. Class 0 (background) is not considered in the average(不计入平均数). :param outputs: probabilities outputs of the CNN. Shape: [BxCxDxHxW] :param labels: ground truth Shape: [BxDxHxW] :param do_one_hot: set to True if ground truth has shape [BxHxW] :param get_list: set to True if you want the list of dices per class instead of average :param device: CUDA device on which compute the dice :return: Multiclass classification Dice Loss """ num_classes = outputs.shape[1] if do_one_hot: labels = one_hot_encode(labels, num_classes) labels = labels.cuda(device=device) dices = list() for cls in range(1, num_classes): outputs_ = outputs[:, cls].unsqueeze(dim=1) labels_ = labels[:, cls].unsqueeze(dim=1) dice_ = dice(outputs_, labels_) dices.append(dice_) if get_list: return dices else: return sum(dices) / (num_classes-1) def get_multi_dice_loss(outputs, labels, device=None): return dice_n_classes(outputs, labels, do_one_hot=True, get_list=False, device=device)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
二、Dice coeff(系数)评价指标
在定义
Dice loss的时候,就已经介绍了Dice coeff,他们两者之间的关系是:Dice loss = 1- Dice coeff。在本文中,尽管是只有一个类别,但是还是给出了多个类别情况下的
Dice coeff,求平均就是average Dice coeff。但是,由于本篇的输出有个背景类,在计算的时候是不算上背景的。所以计算Dice coeff时候是从1开始的。代码如下:
def one_hot_encode_np(label, num_classes): """ Numpy One Hot Encode :param label: Numpy Array of shape BxHxW or BxDxHxW :param num_classes: K classes :return: label_ohe, Numpy Array of shape BxKxHxW or BxKxDxHxW """ assert len(label.shape) == 3 or len(label.shape) == 4, 'Invalid Label Shape {}'.format(label.shape) label_ohe = None if len(label.shape) == 3: label_ohe = np.zeros((label.shape[0], num_classes, label.shape[1], label.shape[2])) elif len(label.shape) == 4: label_ohe = np.zeros((label.shape[0], num_classes, label.shape[1], label.shape[2], label.shape[3])) for batch_idx, batch_el_label in enumerate(label): for cls in range(num_classes): label_ohe[batch_idx, cls] = (batch_el_label == cls) return label_ohe def dice_coeff(gt, pred, eps=1e-5): dice = np.sum(pred[gt == 1]) * 2.0 / (np.sum(pred) + np.sum(gt)) return dice def multi_dice_coeff(gt, pred, num_classes): print('loss shape:', gt.shape, pred) labels = one_hot_encode_np(gt, num_classes) outputs = one_hot_encode_np(pred, num_classes) dices = list() for cls in range(1, num_classes): outputs_ = outputs[:, cls] labels_ = labels[:, cls] dice_ = dice_coeff(outputs_, labels_) dices.append(dice_) return sum(dices) / (num_classes-1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
对于多个类别的情况,在调用
multi_dice_coeff前,需要先进行如下的操作:(下面的操作,默认了一种情况,那就是target的mask,是以不同的数字,代表不同的类别的,比如0-背景;1-类别1;2-类别2;3-类别3)outputs = torch.argmax(output, dim=1) # B x Z x Y x X outputs_np = outputs.data.cpu().numpy() # B x Z x Y x X labels_np = target.data.cpu().numpy() # B x Z x Y x X multi_dice = multi_dice_coeff(labels_np, outputs_np, config.num_outs)- 1
- 2
- 3
- 4
其中,
torch.argmax在类别channel上进行argmax操作,确定该像素属于哪个类别。如此得到的output,就与target的方式,保持了一致。三、训练和验证
在综述篇,已经把框架固定内容基本上都介绍完了,到了本文就显得没什么好展开的了。那就把训练和验证中大的组块给补上。再配合上模型和数据流两篇文章,搭建好自己的训练代码不是问题。
3.1、main 主函数部分
主函数部分,其实是统筹整个训练主代码的。他包括了:
- 对训练超参数的定义
- 数据流的加载
- 网络模型的创建
- 优化器的定义
- 学习率的调整策略
- 损失函数的定义
- 训练和验证函数循环
- 训练过程参数的保存
- 训练模型的保存
这个过程在综述篇基本上已经介绍了,感兴趣的可以翻过去,再仔细的看看。如果是你自己来构建,是不是可以完整的走完这些内容。
下面就是主函数的代码,如下:
def main(): Config = Configuration() Config.display() train_loader, valid_loader = get_Dataloader(Config) print('---start get model now---') model = get_model(Config).to(DEVICE) # ---- OPTIMIZER ---- if Config.OPTIMR == "SGD": optimizer = optim.SGD(model.parameters(), lr=Config.LR, momentum=Config.momentum, weight_decay=Config.weight_decay) elif Config.OPTIMR == "Adam": optimizer = optim.Adam(model.parameters(), lr=Config.LR, betas=(0.9, 0.999)) elif Config.OPTIMR == "AdamW": optimizer = optim.AdamW(model.parameters(), lr=Config.LR, betas=(0.9, 0.999)) elif Config.OPTIMR == "RMSProp": optimizer = optim.RMSprop(model.parameters(), lr=Config.LR) scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.05, patience=20, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08) # Defining loss fn ce_layer = torch.nn.CrossEntropyLoss() train_loss_list = [] # 用来记录训练损失 valid_loss_list = [] # 用来记录验证损失 valid_dice_list = [] epoch_list = [] for epoch in range(1, Config.Max_epoch + 1): epoch_list.append(epoch) train_loss = train_model(model, DEVICE, train_loader, optimizer, ce_layer, epoch) # 训练 valid_loss, valid_dice = valid_model(model, DEVICE, valid_loader, ce_layer, epoch) # 验证 train_loss_list.append(train_loss) # 记录每个epoch训练损失 valid_loss_list.append(valid_loss) # 验证损失 valid_dice_list.append(valid_dice) draw_plot(epoch_list, valid_dice_list, 'valid_dice') draw_plot(epoch_list, valid_loss_list, 'valid_loss') draw_plot(epoch_list, train_loss_list, 'train_loss') if valid_dice > Config.Dice_Best: path_ckpt = os.path.join(Config.model_path, 'best_model.pth') save_model(path_ckpt, model) Config.Dice_Best = valid_dice else: path_ckpt = os.path.join(Config.model_path, 'last_model.pth') save_model(path_ckpt, model) scheduler.step(valid_loss) print('best val Dice is ', Config.Dice_Best)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
3.2、训练部分
单个
epoch的训练过程,和单个epoch的验证过程,在这里单独来定义。这样做的好处就是主函数的代码,相对会简洁一些,避免都放到一起,缩进了太深了,反正影响阅读。下面是训练的部分,包括了:
- 对单个
epoch中所有batch的迭代 - 对单个
batch的前向推理 - 对单个
batch预测结果损伤计算 - 对单个
batch的预测结果进行dice coeff计算 - 梯度清零,反向回归
- 实时打印
下面是训练代码:
def train_model(model, device, train_loader, optimizer, ce_layer, epoch): # 训练模型 config = Configuration() batch_time = AverageMeter() data_time = AverageMeter() losses = AverageMeter() end = time.time() multi_dices = list() model.train() bar = Bar('Processing train ', max=len(train_loader)) for batch_index, (data, target) in enumerate(train_loader): # 取batch索引,(data,target),也就是图和标签 data_time.update(time.time() - end) data, target = data.to(device), target.to(device) output = model(data) # 图 进模型 得到预测输出 # loss = Loss(output, target) # 计算损失 loss = ce_layer(output, target) losses.update(loss.item(), data.size(0)) outputs = torch.argmax(output, dim=1) # B x Z x Y x X outputs_np = outputs.data.cpu().numpy() # B x Z x Y x X labels_np = target.data.cpu().numpy() # B x Z x Y x X multi_dice = multi_dice_coeff(labels_np, outputs_np, config.num_outs) multi_dices.append(multi_dice) optimizer.zero_grad() # 梯度归零 loss.backward() # 反向传播 optimizer.step() # 优化器走一步 # measure elapsed time batch_time.update(time.time() - end) end = time.time() multi_dices_np = np.array(multi_dices) mean_multi_dice = np.mean(multi_dices_np) # plot progress bar.suffix = '(Epoch: {epoch: .1f} | {batch}/{size}) Data: {data:.3f}s | Batch: {bt:.3f}s | Total: {total:} | ETA: {eta:} | Loss: {loss:.4f} | Dice: {dice:.4f}| LR: {lr:.6f}'.format( epoch=epoch, batch=batch_index + 1, size=len(train_loader), data=data_time.val, bt=batch_time.val, total=bar.elapsed_td, eta=bar.eta_td, loss=losses.avg, dice=mean_multi_dice, lr=optimizer.param_groups[0]['lr'] ) bar.next() bar.finish() return losses.avg # 返回平均损失- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
3.3、验证部分
验证部分与训练部分基本上一致的,只不过:
- 在训练阶段,
model.train(),而在验证阶段,需要model.eval() - 验证阶段不进行梯度回归更新模型,损失只是为了统计使用
其他几乎是没什么两样了,代码如下:
def valid_model(model, device, test_loader, ce_layer, epoch): # 加了个test 1是想打印时好看(区分valid和test) 2是test要打印图,需要特别设计 config = Configuration() # 模型训练-----调取方法 model.eval() # 用来验证或测试的 batch_time = AverageMeter() data_time = AverageMeter() losses = AverageMeter() end = time.time() multi_dices = list() bar = Bar('Processing valid ', max=len(test_loader)) with torch.no_grad(): # 不进行 梯度计算(反向传播) for batch_index, (data, target) in enumerate(test_loader): # 枚举batch索引,(图,标签) data_time.update(time.time() - end) data, target = data.to(device), target.to(device) output = model(data) loss = ce_layer(output, target) losses.update(loss.item(), data.size(0)) outputs = torch.argmax(output, dim=1) # B x C x Z x Y x X > B x Z x Y x X outputs_np = outputs.data.cpu().numpy() # B x Z x Y x X labels_np = target.data.cpu().numpy() # B x Z x Y x X multi_dice = multi_dice_coeff(labels_np, outputs_np, config.num_outs) multi_dices.append(multi_dice) multi_dices_np = np.array(multi_dices) mean_multi_dice = np.mean(multi_dices_np) std_multi_dice = np.std(multi_dices_np) # plot progress bar.suffix = '(Epoch: {epoch: .1f} | {batch}/{size}) Data: {data:.3f}s | Batch: {bt:.3f}s | Total: {total:} | ETA: {eta:} | Loss: {loss:.4f} | Dice: {dice:.4f}'.format( epoch=epoch, batch=batch_index + 1, size=len(test_loader), data=data_time.val, bt=batch_time.val, total=bar.elapsed_td, eta=bar.eta_td, loss=losses.avg, dice=mean_multi_dice ) bar.next() bar.finish() return losses.avg, mean_multi_dice- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
3.4、训练感触
在
3D UNet模型那一篇中,我们提到:模型在训练阶段,是不需要在最后增加
sigmoid或softmax操作的。只有在推理阶段,才需要。但是,反观
CrossEntropyLoss,它尽管没有在模型中,定义使用了sigmoid或softmax操作,但是他在计算损失函数的时候,是偷偷使用了sigmoid或softmax操作的。如果不用
CrossEntropyLoss,采用Dice loss,那在计算损失函数前,需要先对模型输出,做一个类似于CrossEntropyLoss的归一化操作吗?依照我自己训练发现:如果在计算
Dice loss前,未进行归一化操作,梯度很容易消失,表现出来的就是没法收敛,很难训练。这或许及时sigmoid或softmax起到的规范化作用,使得模型的训练更加简单了。至于其他的原因和现象,待发现了进一步补充。四、总结
上次有人评论说要完整的代码,这个到最后肯定是会都发出来的。其中在单个文章里面,基本上已经将完整的代码给都贴上去了,稍作做下问题排查,应该就没什么问题。即便有什么问题,也都是一些简单的小问题,这点我都做过了验证。
对于一些初学的,比如
python的os文件操作的库,都不明白的,建议看看其他的文章,把这部分的知识给补齐,再继续学习。如果出现了报错,第一时间先看看报错提示的修改建议,或者根据提示,定位到错误的地方,针对性的修改。不行就百度,绝大部分的问题,网上都已经有人遇到过了。最后实在不行,就在评论区留言,大家一起解决问题,会比较的快。
最后,还差一个预测篇,继续往后看吧。
-
相关阅读:
【Python_PySide2学习笔记(十八)】勾选按钮QCheckBox类的基本用法
工业相机中的不同的图像格式的优缺点
【MYSQL】库和数据表
(王道考研计算机网络)第四章网络层-第六节:IP组播
C/C++test——高效完成白盒测试
【黄色手套22】6话:构造数据类型
【驱动】I2C驱动分析(二)-驱动框架
操作系统reboot之后ddr内容还在吗?
一文轻松实现在VSCode中编写Go代码
105.从前序与中序遍历序列构造二叉树
- 原文地址:https://blog.csdn.net/wsLJQian/article/details/134250370