-
回归模型原理总结及代码实现
前言
本文将介绍回归模型算法,并总结了一些常用的除线性回归模型之外的模型,其中包括一些单模型及集成学习器。
保序回归、多项式回归、多输出回归、多输出K近邻回归、决策树回归、多输出决策树回归、AdaBoost回归、梯度提升决策树回归、人工神经网络、随机森林回归、多输出随机森林回归、XGBoost回归。
需要面试或者需要总体了解/复习机器学习回归模型的小伙伴可以通读下本文,理论总结加代码实操,有助于理解模型。
保序回归
保序回归或单调回归是一种将自由形式的直线拟合到一系列观测值上的技术,这样拟合的直线在所有地方都是非递减(或非递增)的,并且尽可能靠近观测值。
理论规则是
-
如果预测输入与训练中的特征值完全匹配,则返回相应标签。如果一个特征值对应多个预测标签值,则返回其中一个,具体是哪一个未指定。
-
如果预测输入比训练中的特征值都高(或者都低),则相应返回最高特征值或者最低特征值对应标签。如果一个特征值对应多个预测标签值,则相应返回最高值或者最低值。
-
如果预测输入落入两个特征值之间,则预测将会是一个分段线性函数,其值由两个最近的特征值的预测值计算得到。如果一个特征值对应多个预测标签值,则使用上述两种情况中的处理方式解决。
- n = len(dataset['Adj Close'])
- X = np.array(dataset['Open'].values)
- y = dataset['Adj Close'].values
- from sklearn.isotonic import IsotonicRegression
- ir=IsotonicRegression()
- y_ir=ir.fit_transform(X,y)
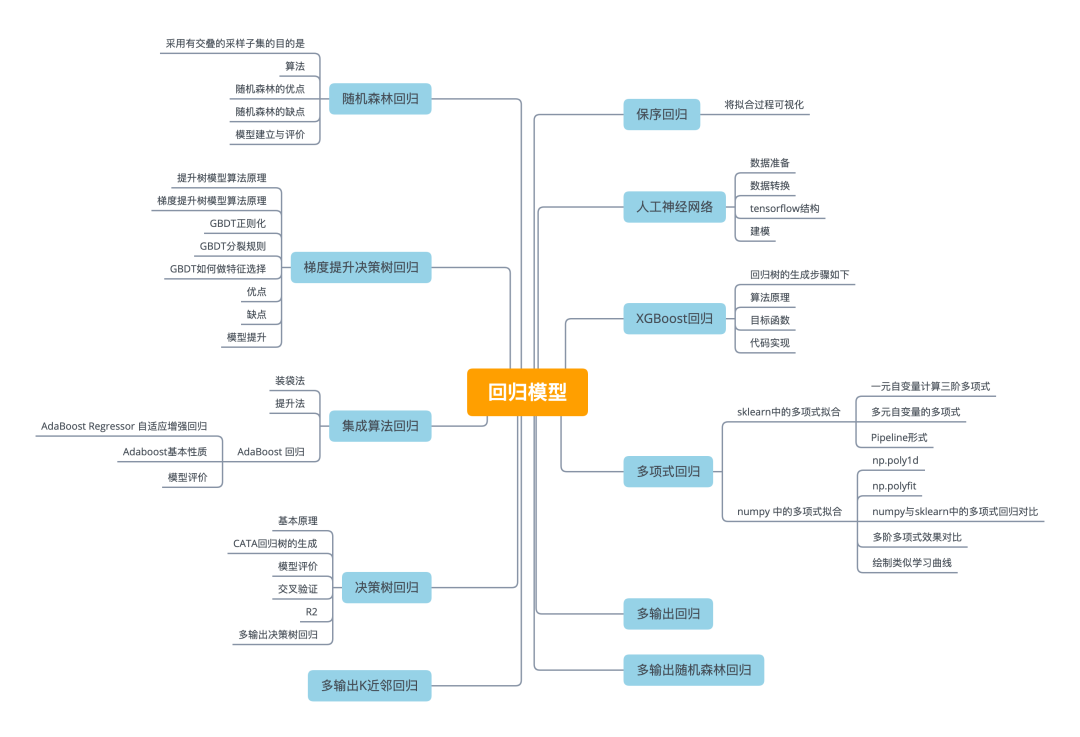
将拟合过程可视化
红色散点图是原始数据
X-y关系图,绿色线为保序回归拟合后的数据X-y_ir关系图。这里以可视化的形式表现了保序回归的理论规则。- lines=[[[i,y[i]],[i,y_ir[i]]] for i in range(n)]
- lc=LineCollection(lines)
- plt.figure(figsize=(15,6))
- plt.plot(X,y,'r.',markersize=12)
- plt.plot(X,y_ir,'g.-',markersize=12)
- plt.gca().add_collection(lc)
- plt.legend(('Data','Isotonic Fit','Linear Fit'))
- plt.title("Isotonic Regression")
- plt.show()
多项式回归
多项式回归(PolynomialFeatures)是一种用多项式函数作为自变量的非线性方程的回归方法。
将数据转换为多项式。多项式回归是一般线性回归模型的特殊情况。它对于描述曲线关系很有用。曲线关系可以通过平方或设置预测变量的高阶项来实现。
sklearn中的多项式拟合
- X = dataset.iloc[ : , 0:4].values
- Y = dataset.iloc[ : , 4].values
- from sklearn.preprocessing import PolynomialFeatures
- from sklearn.linear_model import LinearRegression
- poly=PolynomialFeatures(degree=3)
- poly_x=poly.fit_transform(X)
- regressor=LinearRegression()
- regressor.fit(poly_x,Y)
- plt.scatter(X,Y,color='red')
- plt.plot(X,regressor.predict(poly.fit_transform(X)),color='blue')
- plt.show()
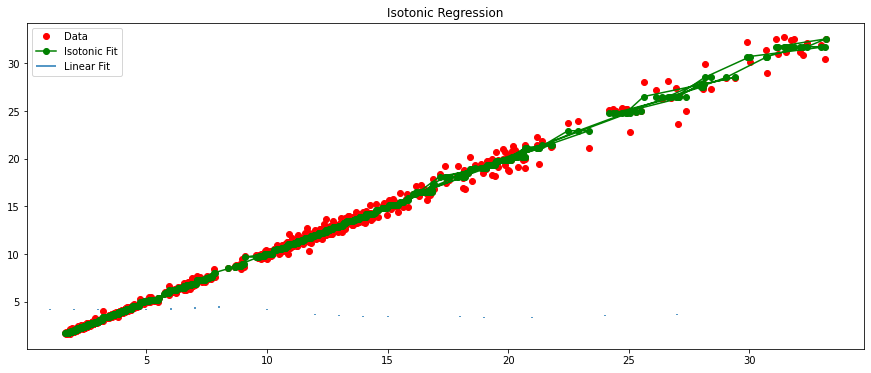
以原始数据绘制
X-Y红色散点图,并绘制蓝色的、经过多项式拟合后再进行线性回归模型拟合的直线图。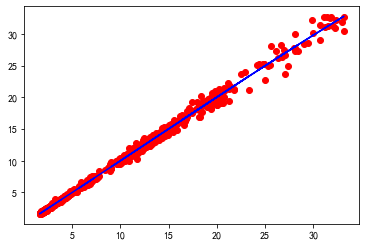
一元自变量计算三阶多项式
- from scipy import *
- f = np.polyfit(X,Y,3)
- p = np.poly1d(f)
- print(p)
多元自变量的多项式
- from sklearn.preprocessing import PolynomialFeatures
- from sklearn import linear_model
- X = np.array(dataset[['Open', 'High', 'Low']].values)
- Y = np.array(dataset['Adj Close'].values)
- Y = Y.reshape(Y.shape[0], -1)
- poly = PolynomialFeatures(degree=3)
- X_ = poly.fit_transform(X)
- predict_ = poly.fit_transform(Y)
Pipeline形式
- from sklearn.pipeline import Pipeline
- X = np.array(dataset['Open'].values)
- Y = np.array(dataset['Adj Close'].values)
- X = X.reshape(X.shape[0], -1)
- Y = Y.reshape(Y.shape[0], -1)
- Input=[('scale',StandardScaler()),('polynomial', PolynomialFeatures(include_bias=False)),('model',LinearRegression())]
- pipe = Pipeline(Input)
- pipe.fit(X,Y)
- yhat = pipe.predict(X)
- yhat[0:4]
numpy 中的多项式拟合
首先理解nump用于多项式拟合的两个主要方法。
np.poly1d
np.poly1d(c_or_r, r=False, variable=None)一维多项式类,用于封装多项式上的"自然"操作,以便上述操作可以在代码中采用惯用形式。如何理解呢?看看下面几个例子。
-
c_or_r系数向量
- import numpy as np
- a=np.array([2,1,1])
- f=np.poly1d(a)
- print(f)
-
r=False是否反推
表示把数组中的值作为根,然后反推多项式。
- f=np.poly1d([2,3,5],r=True)
- #(x - 2)*(x - 3)*(x - 5) = x^3 - 10x^2 + 31x -30
- print(f)
-
variable=None表示改变未知数的字母
- f=np.poly1d([2,3,5],r=True,variable='z')
- print(f)
np.polyfit
np.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)最小二乘多项式拟合
拟合多项式
 。返回一个系数
。返回一个系数'p'的向量,以最小化平方误差的顺序'deg','deg-1',…"0"。推荐使用
类方法,因为它在数值上更稳定。 下图是以原始数据绘制的蓝色
X-Y散点图,以及红色的X分布图。- X = dataset['Open'].values
- y = dataset['Adj Close'].values
- from sklearn.model_selection import train_test_split
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
- plt.figure(figsize=(10,6))
- plt.plot(X_train, y_train, 'bo')
- plt.plot(X_test, np.zeros_like(X_test), 'r+')
- plt.show()
numpy与sklearn中的多项式回归对比
- # numpy
- model_one = np.poly1d(np.polyfit(X_train, y_train,1))
- preds_one = model_one(X_test)
- print(preds_one[:3])
- >>> [11.59609048 10.16018804 25.23716889]
- # sklearn
- from sklearn.linear_model import LinearRegression
- model = LinearRegression()
- model.fit(X_train.reshape(-1, 1), y_train)
- preds = model.predict(X_test.reshape(-1, 1))
- preds[:3]
- >>> array([11.59609048, 10.16018804, 25.23716889])
- # 预测结果是一样的
- print("all close?", np.allclose(preds, preds_one))
- >>> 'all close? True
结果表明两者相比预测结果时一致的。
多阶多项式效果对比
比较一阶、二阶及三阶多项式拟合,多线性回归模型的效果影响。由图可看出,三条线基本重合,且
RMSE相差不大。- model_one = np.poly1d(np.polyfit(X_train, y_train,1))
- model_two = np.poly1d(np.polyfit(X_train, y_train, 2))
- model_three = np.poly1d(np.polyfit(X_train, y_train, 3))
- fig, axes = plt.subplots(1, 2, figsize=(14, 5),sharey=True)
- labels = ['line', 'parabola', 'nonic']
- models = [model_one, model_two, model_three]
- train = (X_train, y_train)
- test = (X_test, y_test)
- for ax, (ftr, tgt) in zip(axes, [train, test]):
- ax.plot(ftr, tgt, 'k+')
- num = 0
- for m, lbl in zip(models, labels):
- ftr = sorted(ftr)
- ax.plot(ftr, m(ftr), '-', label=lbl)
- if ax == axes[1]:
- ax.text(2,55-num, f"{lbl}_RMSE: {round(np.sqrt(mse(tgt, m(tgt))),3)}")
- num += 5
- axes[1].set_ylim(-10, 60)
- axes[0].set_title("Train")
- axes[1].set_title("Test");
- axes[0].legend(loc='best');
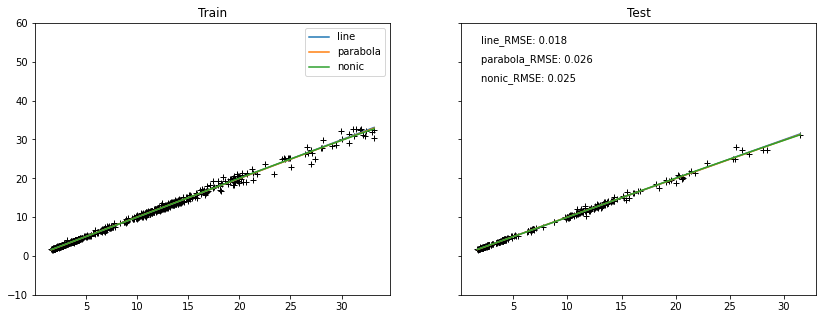
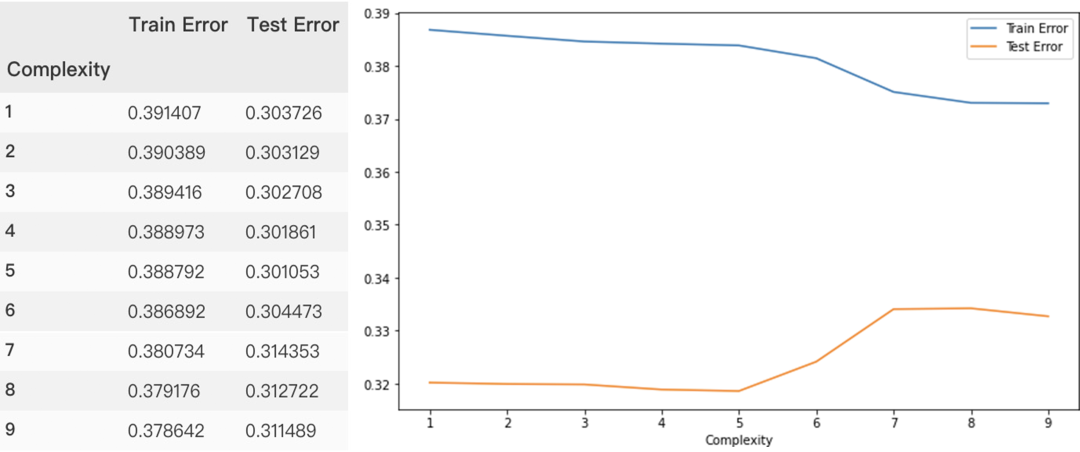
绘制类似学习曲线
因低阶多项式效果相差并不明显,因此增大多项式阶数,并以残差平方和为y轴,看模型拟合效果,由图可以看出,随着多项式阶数越来越高,模型出现严重的过拟合(训练集残差平方和降低,而测试集却在上涨)。
- results = []
- for complexity in [1, 2, 3, 4, 5, 6,7,8, 9]:
- model = np.poly1d(np.polyfit(X_train, y_train, complexity))
- train_error = np.sqrt(mse(y_train, model(X_train)))
- test_error = np.sqrt(mse(y_test,model(X_test)))
- results.append((complexity, train_error, test_error))
- columns = ["Complexity", "Train Error", "Test Error"]
- results_df = pd.DataFrame.from_records(results,
- columns=columns,
- index="Complexity")
- results_df
- results_df.plot(figsize=(10,6))
多输出回归
多输出回归为每个样本分配一组目标值。这可以认为是预测每一个样本的多个属性,比如说一个具体地点的风的方向和大小。
多输出回归支持
MultiOutputRegressor可以被添加到任何回归器中。这个策略包括对每个目标拟合一个回归器。因为每一个目标可以被一个回归器精确地表示,通过检查对应的回归器,可以获取关于目标的信息。因为MultiOutputRegressor对于每一个目标可以训练出一个回归器,所以它无法利用目标之间的相关度信息。支持多类-多输出分类的分类器:
- sklearn.tree.DecisionTreeClassifier
- sklearn.tree.ExtraTreeClassifier
- sklearn.ensemble.ExtraTreesClassifier
- sklearn.neighbors.KNeighborsClassifier
- sklearn.neighbors.RadiusNeighborsClassifier
- sklearn.ensemble.RandomForestClassifier
- X = dataset.drop(['Adj Close', 'Open'], axis=1)
- Y = dataset[['Adj Close', 'Open']]
- from sklearn.multioutput import MultiOutputRegressor
- from sklearn.svm import LinearSVR
- model = LinearSVR()
- wrapper = MultiOutputRegressor(model)
- wrapper.fit(X, Y)
- data_in = [[23.98, 22.91, 7.00, 7.00,
- 1.62, 1.62, 4.27, 4.25]]
- yhat = wrapper.predict(data_in)
- print(yhat[0])
- >>> [16.72625136 16.72625136]
- wrapper.score(X, Y)
多输出K近邻回归
多输出K近邻回归可以不使用
MultiOutputRegressor作为外包装器,直接使用KNeighborsRegressor便可以实现多输出回归。- X = dataset.drop(['Adj Close', 'Open'], axis=1)
- Y = dataset[['Adj Close', 'Open']]
- from sklearn.neighbors import KNeighborsRegressor
- model = KNeighborsRegressor()
- model.fit(X, Y)
- data_in = [[23.98, 22.91, 7.00, 7.00,
- 1.62, 1.62, 4.27, 4.25]]
- yhat = model.predict(data_in)
- print(yhat[0])
- >>> [2.34400001 2.352 ]
- model.score(X, Y)
- >>> 0.7053689393640217
决策树回归
决策树是一种树状结构,她的每一个叶子结点对应着一个分类,非叶子结点对应着在某个属性上的划分,根据样本在该属性上的不同取值降气划分成若干个子集。
基本原理
数模型通过递归切割的方法来寻找最佳分类标准,进而最终形成规则。CATA树,对回归树用平方误差最小化准则,进行特征选择,生成二叉树。
CATA回归树的生成
在训练数据集所在的空间中,递归地将每个空间区域划分为两个子区域,并决定每个子区域上的输出值,生产二叉树。
选择最优切分变量j和最优切分点s,求解

遍历 j,对固定的切分变量 j 扫描切分点 s ,使得上式达到最小值的对 (j,s) ,不断循环直至满足条件停止。
- X = dataset.drop(['Adj Close', 'Close'], axis=1)
- y = dataset['Adj Close']
- # 划分训练集和测试集略
- # 模型实例化
- from sklearn.tree import DecisionTreeRegressor
- regressor = DecisionTreeRegressor()
- # 训练模型
- regressor.fit(X_train, y_train)
- # 回归预测
- y_pred = regressor.predict(X_test)
- df = pd.DataFrame({'Actual':y_test, 'Predicted':y_pred})
- print(df.head(2))
- Actual Predicted
- Date
- 2017-08-09 12.83 12.63
- 2017-11-14 11.12 11.20
模型评价
- from sklearn import metrics
- # 平均绝对误差
- print(metrics.mean_absolute_error(
- y_test, y_pred))
- # 均方差
- print(metrics.mean_squared_error(
- y_test, y_pred))
- # 均方根误差
- print(np.sqrt(
- metrics.mean_squared_error(
- y_test, y_pred)))
- 0.0924680893617
- 0.0226966010212
- 0.1506539114039
交叉验证
- from sklearn.model_selection import cross_val_score
- dt_fit = regressor.fit(X_train, y_train)
- dt_scores = cross_val_score(
- dt_fit, X_train, y_train, cv = 5)
- print("Mean cross validation score: {}".format(np.mean(dt_scores)))
- print("Score without cv: {}".format(dt_fit.score(X_train, y_train)))
- Mean cross validation score: 0.99824909037
- Score without cv: 1.0
R2
- from sklearn.metrics import r2_score
- print('r2 score:', r2_score(y_test, dt_fit.predict(X_test)))
- print('Accuracy Score:', dt_fit.score(X_test, y_test))
- r2 score: 0.9989593390532074
- Accuracy Score: 0.9989593390532074
多输出决策树回归
多输出回归是根据输入预测两个或多个数字输出。在多输出回归中,通常,输出依赖于输入并且彼此依赖。这意味着输出经常不是彼此独立的,可能需要一个模型来预测两个输出在一起或每个输出取决于其他输出。
一个示例说明决策树多输出回归(Decision Tree for Multioutput Regression)。
- X = dataset.drop(['Adj Close', 'Open'], axis=1)
- Y = dataset[['Adj Close', 'Open']]
- from sklearn.tree import DecisionTreeRegressor
- model = DecisionTreeRegressor()
- model.fit(X, Y)
- # 统计值
- # dataset.describe()
- # 根据统计信息输入data_in
- data_in = [23.98, 22.91, 7.00, 7.00, 1.62, 1.62, 4.27, 4.25]
- yhat = model.predict([data_in])
- # 预测值
- print(yhat[0])
- print(model.score(X, Y))
- [15.64999962 16.64999962]
- 1
集成算法回归装袋法
装袋法 (Bagging)的核⼼思想是构建多个 相互独⽴的评估器 ,然后对其预测进⾏平均或多数表决原则来决定集成评估器的结果。装袋法的代表模型就是随机森林。
个体学习器间不存在强依赖关系、可同时生成的并行化方法。
提升法
提升法(Boosting)中,基评估器是相关的,是按顺序⼀⼀构建的。其核⼼思想是结合弱评估器的⼒量⼀次次对难以评估的样本进⾏预测,从⽽构成⼀个强评估器。提升法的代表模型Adaboost和梯度提升树GBDT。
个体学习器间存在强依赖关系、必须串行生成的序列化方法。
AdaBoost 回归
AdaBoost Regressor 自适应增强回归
通过提高那些被前一轮基学习器错误分类的样本的权值,降低那些被正确分类的样本的权值来改变训练样本分布。并对所有基学习器采用加权结合,增大分类误差小的基学习器的权值,减少分类误差率大的基学习器的权值。
理论上的AdaBoost可以使用任何算法作为基学习器,但一般来说,使用最广泛的AdaBoost的弱学习器是决策树和神经网络。
AdaBoost的核心原则是在反复修改的数据版本上拟合一系列弱学习者(即比随机猜测略好一点的模型,如小决策树)。他们所有的预测然后通过加权多数投票(或总和)合并产生最终的预测。
每次所谓的增强迭代的数据修改包括对每个训练样本应用权重
 。
。-
最初,这些权重都被设置为
 ,所以第一步仅仅是在原始数据上训练一个能力较弱的学习器。
,所以第一步仅仅是在原始数据上训练一个能力较弱的学习器。 -
对于每一次连续迭代,样本权值被单独修改,学习算法被重新应用到重新加权的数据。
-
在给定的步骤中,那些被前一步引入的增强模型错误预测的训练例子的权重增加,而那些被正确预测的训练例子的权重减少。
-
随着迭代的进行,难以预测的例子受到越来越大的影响。因此,每一个随后的弱学习器都被迫将注意力集中在前一个学习器错过的例子上。
基分类器
 在加权数据集上的分类误差率等于被 误分类样本的权重之和。
在加权数据集上的分类误差率等于被 误分类样本的权重之和。Adaboost基本性质
能在学习过程中不断减少训练误差,即在训练数据集上的训练误差率。且误差率是以指数数率下降的。
- X = dataset[['Open', 'High', 'Low', 'Volume']].values
- y = dataset['Buy_Sell'].values
- # 划分训练集与测试集略
- from sklearn.ensemble import AdaBoostClassifier
- ada = AdaBoostClassifier(n_estimators=180, random_state=0)
- ada.fit(X_train, y_train)
- y_pred_proba = ada.predict_proba(X_test)[:,1]
- ada.feature_importances_
array([ 0.18888889,0.15,0.26666667,0.39444444])模型评价
- ada.predict(X_test)
- ada.score(X, y)
- from sklearn.metrics import roc_auc_score
- ada_roc_auc = roc_auc_score(y_test, y_pred_proba)
- print('ROC AUC score: {:.2f}'.format(ada_roc_auc))
梯度提升决策树回归
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力较强的算法。
提升树是迭代多棵回归树来共同决策。当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式:残差 = 真实值 - 预测值 。提升树即是整个迭代过程生成的回归树的累加。
提升树利用加法模型和前向分步算法实现学习的优化过程。当损失函数时平方损失和指数损失函数时,每一步的优化很简单,如平方损失函数学习残差回归树。
简单解释:每一次的计算是为了减少上一次的残差,GBDT在残差减少(负梯度)的方向上建立一个新的模型。
提升树模型算法原理
我们利用平方误差来表示损失函数,其中每一棵回归树学习的是之前所有树的结论和残差 ,拟合得到一个当前的残差回归树。提升树即是整个迭代过程生成的回归树的累加。
GBDT需要将多棵树的得分累加得到最终的预测得分,且每一次迭代,都在现有树的基础上,增加一棵树去拟合前面树的预测结果与真实值之间的残差。
梯度提升树模型算法原理
采用向前分布算法,先确定初始提升树,然后每一次提升都是靠上次的预测结果与训练数据中标签值作为新的训练数据进行重新训练,利用损失函数的负梯度来拟合本轮损失函数的近似值,进而拟合一个CART回归树。
对于梯度提升回归树来说,每个样本的预测结果可以表示为所有树上的结果的加权求和。

GBDT正则化
子采样比例方法: subsample(子采样),取值为(0,1],采用的不放回采样。
定义步长v方法来防止过拟合: Shrinkage,即在每一轮迭代获取最终学习器的时候按照一定的步长进行更新。
GBDT分裂规则
利用
 来构建Cart回归树的时候,GBDT分裂会选取使得误差下降最多(如果cart树采用的是均方差作为损失,那么就是最小均方差)的特征进行分裂,如果这棵树不能拟合好,那么就要通过负梯度计算出新的残差向量来拟合新的Cart回归树
来构建Cart回归树的时候,GBDT分裂会选取使得误差下降最多(如果cart树采用的是均方差作为损失,那么就是最小均方差)的特征进行分裂,如果这棵树不能拟合好,那么就要通过负梯度计算出新的残差向量来拟合新的Cart回归树GBDT如何做特征选择
特征 j 的全局重要度通过特征 j 在单颗树中的重要度的平均值来衡量。

其中,M 是树的数量。特征 j 在单颗树中的重要度( 通过计算按这个特征i分裂之后损失的减少值 )的如下:

其中,L 为树的叶子节点数量,L-1 即为树的非叶子节点数量(构建的树都是具有左右孩子的二叉树),
 是和节点 t 相关联的特征,
是和节点 t 相关联的特征, 是节点 t 分裂之后平方损失的减少值。
是节点 t 分裂之后平方损失的减少值。优点
-
相对少的调参时间情况下可以得到较高的准确率。
-
可灵活处理各种类型数据,包括连续值和离散值,使用范围广。
-
可使用一些健壮的损失函数,对异常值的鲁棒性较强,比如Huber损失函数。
缺点
-
弱学习器之间存在依赖关系,难以并行训练数据。
-
需要先处理缺失值。
- X = dataset[['Open', 'High', 'Low', 'Volume']].values
- y = dataset['Adj Close'].values
- # 划分训练集与测试集略
- from sklearn.ensemble import GradientBoostingRegressor
- gb = GradientBoostingRegressor(max_depth=4,
- n_estimators=200,
- random_state=2)
- # 用训练集训练数据
- gb.fit(X_train, y_train)
- # 预测测试集标签
- y_pred = gb.predict(X_test)
- from sklearn.metrics import mean_squared_error as MSE
- # 计算 MSE
- mse_test = MSE(y_test, y_pred)
- # 计算 RMSE
- rmse_test = mse_test**(1/2)
- # 输出 RMSE
- print('Test set RMSE of gb: {:.3f}'.format(rmse_test))
模型提升
- estimator_imp = tf.estimator.DNNRegressor(
- feature_columns=feature_columns,
- hidden_units=[300, 100],
- dropout=0.3,
- optimizer=tf.train.ProximalAdagradOptimizer(
- learning_rate=0.01,
- l1_regularization_strength=0.01,
- l2_regularization_strength=0.01
- ))
- estimator_imp.train(input_fn = train_input,steps=1000)
- estimator_imp.evaluate(eval_input,steps=None)
{'average_loss': 6.139895, 'global_step': 1000, 'loss': 1442.8754}随机森林回归
随机森林采用决策树作为弱分类器,在bagging的样本随机采样基础上,⼜加上了特征的随机选择。
当前结点特征集合( d 个特征),随机选择 k 个特征子集,再选择最优特征进行划分。k 控制了随机性的引入程度,推荐值:

对预测输出进行结合时,分类任务——简单投票法;回归任务——简单平均法
采用有交叠的采样子集的目的
-
为集成中的个体学习器应尽可能相互独立,尽可能具有较大差异,以得到泛化能力强的集成。对训练样本进行采样,得到不同的数据集。
-
如果采样出的每个子集都完全不同,每个学习器只用到一小部分训练数据,甚至不足以进行有效学习。
-
Bagging能不经修改的用于多分类、回归等任务。而Adaboost只适用二分类任务有 36.8% 的袋外数据用于验证集。
算法
-
从样本集N中有放回随机采样选出n个样本。
-
从所有特征中随机选择k个特征,对选出的样本利用这些特征建立决策树(一般是CART方法)。
-
重复以上两步m次,生成m棵决策树,形成随机森林,其中生成的决策树不剪枝。
-
对于新数据,经过每棵决策树投票分类。
随机森林的优点
-
决策树选择部分样本及部分特征,一定程度上避免过拟合 。
-
决策树随机选择样本并随机选择特征,模型具有很好的抗噪能力,性能稳定。
-
能够处理高维度数据,并且不用做特征选择,能够展现出哪些变量比较重要。
-
对缺失值不敏感,如果有很大一部分的特征遗失,仍可以维持准确度。
-
训练时树与树之间是相互独立的,训练速度快,容易做成并行化方法。
-
随机森林有袋外数据obb,不需要单独划分交叉验证集。
随机森林的缺点
-
可能有很多相似决策树,掩盖真实结果。
-
对小数据或低维数据可能不能产生很好分类。
-
产生众多决策树,算法较慢。
- X = dataset.drop(['Adj Close', 'Close'], axis=1)
- y = dataset['Adj Close']
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=42)
- # 数据标准化
- scaler = StandardScaler().fit(X_train)
- X_train_scaled = pd.DataFrame(scaler.transform(X_train), index=X_train.index.values, columns=X_train.columns.values)
- X_test_scaled = pd.DataFrame(scaler.transform(X_test), index=X_test.index.values, columns=X_test.columns.values)
- # PCA降维
- from sklearn.decomposition import PCA
- pca = PCA()
- pca.fit(X_train)
- cpts = pd.DataFrame(pca.transform(X_train))
- x_axis = np.arange(1, pca.n_components_+1)
- # 标准化后的降维
- pca_scaled = PCA()
- pca_scaled.fit(X_train_scaled)
- cpts_scaled = pd.DataFrame(pca.transform(X_train_scaled))
模型建立与评价
- from sklearn.ensemble import RandomForestRegressor
- rf = RandomForestRegressor(n_estimators=500, oob_score=True, random_state=0)
- rf.fit(X_train, y_train)
- from sklearn.metrics import r2_score
- from scipy.stats import spearmanr, pearsonr
- predicted_train = rf.predict(X_train)
- predicted_test = rf.predict(X_test)
- test_score = r2_score(y_test, predicted_test)
- spearman = spearmanr(y_test, predicted_test)
- pearson = pearsonr(y_test, predicted_test)
- print('Out-of-bag R-2 score estimate:', rf.oob_score_)
- print('Test data R-2 score:', test_score)
- print('Test data Spearman correlation:',spearman[0])
- print('Test data Pearson correlation:',pearson[0])
- Out-of-bag R-2 score estimate: 0.99895617164
- Test data R-2 score: 0.999300318737
- Test data Spearman correlation: 0.999380233068
- Test data Pearson correlation: 0.999650364791
多输出随机森林回归
- X = dataset.drop(['Adj Close', 'Open'], axis=1)
- Y = dataset[['Adj Close', 'Open']]
- from sklearn.ensemble import RandomForestRegressor
- model = RandomForestRegressor()
- model.fit(X, Y)
- data_in = [[23.98, 22.91, 7.00, 7.00, 1.62, 1.62, 4.27, 4.25]]
- yhat = model.predict(data_in)
- model.score(X, Y)
- print(yhat[0])
[10.96199994 10.57600012]XGBoost回归
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是CART回归树模型。
回归树的生成步骤如下
-
从根节点开始分裂。
-
节点分裂之前,计算所有可能的特征及它们所有可能的切分点分裂后的平方误差(结构分数之差)。
-
如果所有的平方误差均相同或减小值小于某一阈值,或者节点包含的样本数小于某一阈值,则分裂停止;否则,选择使平方误差最小的特征和切分点作为最优特征和最优切分点进行分裂,并生成两个子节点。
-
对于每一个新生成的子节点,递归执行步骤2和步骤3,直到满足停止条件。
算法原理
不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差
当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数
最后只需要将每棵树对应的分数加起来就是该样本的预测值。

XGB vs GBDT 核心区别:求解预测值的方式不同
GBDT中 预测值是由所有弱分类器上的预测结果的加权求和 ,其中每个样本上的预测结果就是样本所在的叶子节点的均值。
而XGBT中的 预测值是所有弱分类器上的叶子权重直接求和得到。 这个叶子权重就是所有在这个叶子节点上的样本在这一棵树上的回归取值,用或者来表示,其中表示第棵决策树, 表示样本对应的特征向量
目标函数
第一项是衡量我们的偏差,模型越不准确,第一项就会越大。第二项是衡量我们的方差,模型越复杂,模型的学习就会越具体,到不同数据集上的表现就会差异巨大,方差就会越大。

代码实现
- X = dataset[['Open', 'High', 'Low', 'Volume']].values
- y = dataset['Adj Close'].values
- from xgboost import XGBRegressor
- xgb = XGBRegressor(max_depth=5, learning_rate=0.01, n_estimators=2000, colsample_bytree=0.1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
- xgb.fit(X_train,y_train)
- y_pred = xgb.predict(X_test)
- xgb.score(X_test, y_test)
人工神经网络
深度神经网络(DNN)回归器
-
3层: 输入、隐藏和输出
-
特征: 输入数据到网络(特征)
-
标签: 网络输出(标签)
-
损失函数: 用于估计学习阶段的性能的度量
-
优化器: 通过更新网络中的知识来提高学习效果
数据准备
- X = dataset.drop(['Adj Close', 'Close'], axis=1)
- y = dataset['Adj Close']
- # 数据划分略
- y_train = y_train.astype(int)
- y_test = y_test.astype(int)
- batch_size =len(X_train)
数据转换
- ## 数据归一化
- from sklearn.preprocessing import MinMaxScaler
- scaler = MinMaxScaler()
- # Train
- X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
- # test
- X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
tensorflow结构
- import tensorflow as tf
- feature_columns = [tf.feature_column.numeric_column('x', shape=X_train_scaled.shape[1:])]
建模输
- estimator = tf.estimator.DNNRegressor(
- feature_columns=feature_columns,
- hidden_units=[300, 100])
- # 训练模型
- train_input = tf.estimator.inputs.numpy_input_fn(
- x={"x": X_train_scaled},
- y=y_train,
- batch_size=50,
- shuffle=False,
- num_epochs=None)
- estimator.train(input_fn = train_input,steps=1000)
- eval_input = tf.estimator.inputs.numpy_input_fn(
- x={"x": X_test_scaled},
- y=y_test,
- shuffle=False,
- batch_size=X_test_scaled.shape[0],
- num_epochs=1)
- estimator.evaluate(eval_input,steps=None)
输出结果
{'average_loss': 6.4982734, 'global_step': 1000, 'loss': 1527.0942} -
-
相关阅读:
Java -- 定时任务实现方式
深度交流 | 能链科技兰春嘉博士受邀参加中国建设银行内训讲座
【数据集】水文专业常用数据集整理
Golang基础教程
MySQL笔记(进阶篇)
图解哈希表及其原理
【python入门专项练习】-N03.列表
K8s nginx-ingress 如何配置二级目录转发远程静态服务器基于Vue路由history模式打包的应用程序
全局异常处理+JSR303验证
pixhawk飞控和自习开发的stm32芯片通讯问题
- 原文地址:https://blog.csdn.net/qq_39312146/article/details/134272828
