-
oracle使用regexp_substr来拆分,CONNECT BY LEVEL查询卡死,速度慢的问题。
一、问题
oracle 使用regexp_substr+CONNECT BY LEVEL来,根据特定字符拆分成多行。
(注意这里我的数据是每个值都有“ ; ”,即使后面没有值,后面也会有个“ ; ”, 如果是正常的分隔符,sql 需要改成” LEVEL < = regexp_count(name, ‘;’)+1 ”)select distinct regexp_substr(name, '[^;]+', 1, LEVEL) name from (select distinct name from table_name a where TIME1 > sysdate - 1 / 24) CONNECT BY LEVEL < = regexp_count(name, ';');- 1
- 2
- 3
- 4
- 5
执行后发现特别慢,查询了好几分钟没没出来。
如果单独拿select distinct name
from table_name a
where TIME1 > sysdate - 1 / 24
查询,发现挺快的。
查看下执行计划
二、解决方法
调整后。通过利用rownum 进行join ,sql:
select distinct regexp_substr(name, '[^;]+', 1, n) name from (select distinct name, regexp_count(name, ';') rn from table_name a where TIME1 > sysdate - 1) join (SELECT rownum n from table_name a where rownum <= 999) on n <= rn- 1
- 2
- 3
- 4
- 5
- 6
- 7
(rownum <= 999可以改成rownum <=(select max(regexp_count(name, ‘;’)) from table_name where TIME1 > sysdate - 1) )
注意:
这个里table_name表的总行数,需要比(select max(regexp_count(name, ‘;’)) from table_name where TIME1 > sysdate - 1) 大。如果没有,随便拿个比较大的表替代,不可使用(SELECT LEVEL n FROM DUAL CONNECT BY LEVEL <= 99)替代。执行计划:
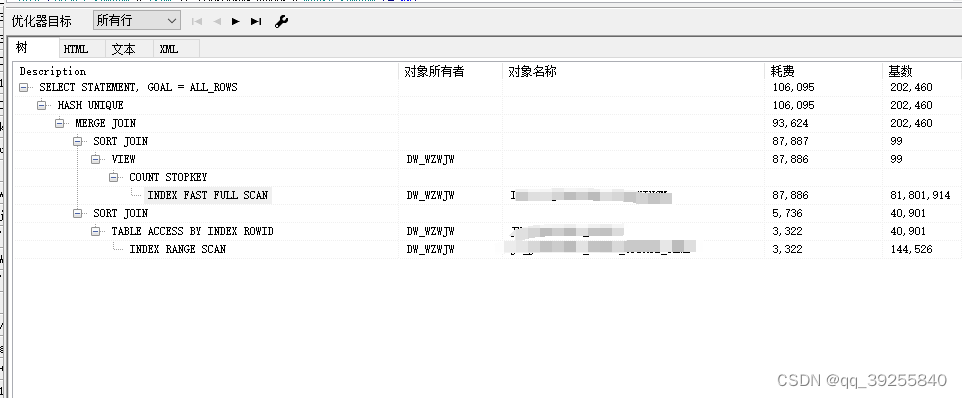
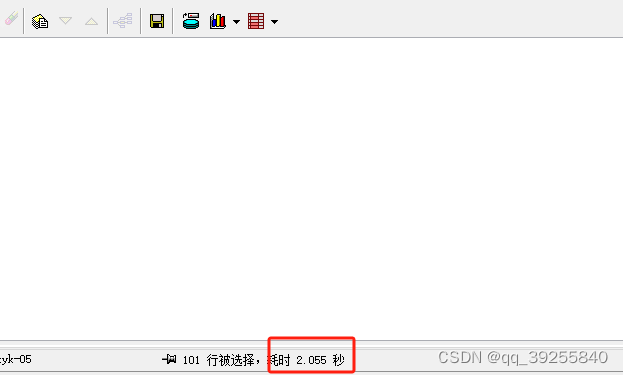
查询耗时只需要2s多
三、总结
CONNECT BY是层次查询,一般用来构造树形的构造,这里查询不太适用。通过rownum构造虚拟的表,进行jion查询,执行计划就会执行MERGE JOIN 进行关联,效率将会大大提高 。
-
相关阅读:
力扣 827. 最大人工岛
queryWrapper手册及示例
Java学习路线(就业导向)
探索Lighthouse性能分数计算背后的奥秘
Maven生命周期与插件
MySQL 全局锁、表级锁、行锁详解
jlink系列 v9 和 v11 调试器版本区别
STC51单片机36——51单片机简单分两路控制步进电机
java计算机毕业设计基于安卓/微信的农产品特产销售商城小程序 uniAPP
信安软考 第二十五章 移动应用安全需要分析与安全保护工程
- 原文地址:https://blog.csdn.net/qq_39255840/article/details/134269109