-
【ElasticSearch系列-06】Es集群架构的搭建以及集群的核心概念
ElasticSearch系列整体栏目
内容 链接地址 【一】ElasticSearch下载和安装 https://zhenghuisheng.blog.csdn.net/article/details/129260827 【二】ElasticSearch概念和基本操作 https://blog.csdn.net/zhenghuishengq/article/details/134121631 【三】ElasticSearch的高级查询Query DSL https://blog.csdn.net/zhenghuishengq/article/details/134159587 【四】ElasticSearch的聚合查询操作 https://blog.csdn.net/zhenghuishengq/article/details/134159587 【五】SpringBoot整合elasticSearch https://blog.csdn.net/zhenghuishengq/article/details/134212200 【六】Es集群架构的搭建以及集群的核心概念 https://blog.csdn.net/zhenghuishengq/article/details/134258577
Es集群架构的搭建以及集群的核心概念
一,深入理解es集群架构的底层原理
前面讲解了es的安装,基本使用等,接下来这篇主要讲解es的集群架构的底层原理,es的索引分片,副本等基本知识
1,集群的核心概念
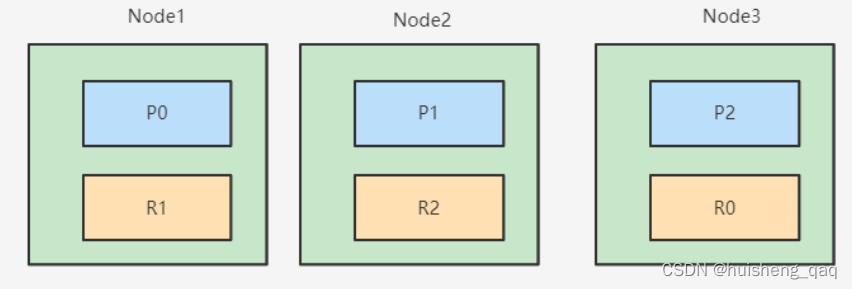
在安装集群之前,先了解一下集群的几个概念。如下图 ,就是一个三个节点组成的es集群,p0、p1、p2表示一个节点中的分片,R0、R1、R2表示分片对应的副本

1.1,节点以及节点类型
一个集群中可以有一个或者多个节点,每一个节点就是一个Es的实例,其本质就是一个java进程。一般在一台机器上,建议运行一个ElasticSearch的实例。在Es集群中,存在多种节点类型,主要有以下几种节点,在搭建es集群时,需要根据不同的结点类型设置不同的参数。每个结点在启动之后,默认就是一个可以参与选举的 Master eligible 结点
- Master Node:主节点,如上图中的Node1就是master主节点,主要是负责一些索引的创建、删除、决定分片要分配到哪个结点、维护整个集群的更新等
- Master eligible nodes:可以参与选举的合格节点,当主节点挂了该节点就可以参与选举,该节点也是Master主结点的一个从结点
- Data Node:专门用于存放数据的节点,如索引插入的数据就是存放在这个节点中。由master主结点负责如何将分片分发到数据节点上,通过数据节点解决数据的水平扩展和解决数据的单点问题。
- Coordinating Node:协调节点,用于接收和响应请求,完成数据的接收和分发
1.2,请求和响应流程
一个简单的es的集群架构如下,在一个客户端的请求下,首先会经过这个协调结点的接收和分发,让请求具体落实到Data Node数据节点,或者是Master主结点。如果是查询数据,可以直接分发到Data数据节点,如果是增删改,需要涉及到集群,分片或者副本的变化,那么可以直接分发到这个Master主结点上面。
在将数据从结点的分片中查询之后,又会将数据汇总到这个Coordinating 协调结点上面,经过一些统计计算等,最后将结果返回

如果es要做读写分离来增加高性能的话,可以增加这个Ingest Node结点,该节点名为前置处理转换结点,支持pipeline管道设置,可以使用这个Ingest节点对数据进行过滤以及转换操作

1.3,分片
在创建索引时,可以指定索引分片的个数,副本的个数等。分片又可以分为主分片和副本分片。
主分片 :Primary Shard,主要是用于解决数据水平扩展的问题,通过主分片,可以将数据分发到集群的所有结点上面,每一个分片是一个Lucene的一个实例,分片在创建之后,不允许被修改,因为获取数据需要通过hash取模运算,改了数量就会直接影响结果
副本分片 : Replica Shard,用于解决数据高可用的问题,就是主分片的一个拷贝,主分片数在创建之后不允许被修改,副本分片数是允许被修改的,并且在一定程度上,可以通过增加副本数来提高服务读取数据的性能。但是副本分片最好是设置成0或者1,如果是日志数据,可以直接设置为0,如果是商品信息这种检索数据,那么可以直接设置成为1。
如下面在创建索引的时候,可以设置分片的数量以及设置副本的数量。
PUT /zhs_db { "settings": { "number_of_shards": 3, //设置分片数 "number_of_replicas": 1 //设置副本数 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
分片数和节点数有关,如有一个三个节点组成的集群,那么设三个分片,那么会根据默认的hash算法,一个节点中就会有一个分片,就会是下图中的P0、P1、P2和R0、R1、R2这种情况
在非单机的情况下,副本分片一般和主分片不在一个节点上面,副本分片一般是在同一个集群中的不同结点上面,具体在哪个结点上面,需要通过这个Master主结点去分配
单节点的分片数目也不宜设置过多,因为过多的话会影响算分的结果性,同时也会浪费很多资源
2,集群搭建
2.1,es集群搭建
在第一篇文章中,讲解了es的单节点集群的搭建方式,那么es集群的搭建,需要有三台机器,重复单节点的搭建即可,并且都可以简单的通过docker的方式搭建
主要就是修改这个 elasticsearch.yml 中的文件中的内容,最主要的就是修改这个discovery.seed_hosts 中的三台搭建了es结点的服务器的host主机号,用于节点发现,之前单机设置的是只有当前结点的主机号。
在指定这个结点的名称时,这个yml文件设置的这个node.name也要不一致,第一台设置node-1,第二胎设置为node-2,第三台设置为node-3,在初始化集群节点的时候,需要将这三个值配置到 cluster.initial_master_nodes 属性中
# 指定集群名称3个节点必须一致 cluster.name: docker-cluster #指定节点名称,每个节点名字唯一 node.name: node-1 #是否有资格为master节点,默认为true node.master: true #是否为data节点,默认为true node.data: true # 绑定ip,开启远程访问,可以配置0.0.0.0 network.host: 0.0.0.0 #指定web端口 #http.port: 9200 #指定tcp端口 #transport.tcp.port: 9300 #用于节点发现,三个节点的主机号 discovery.seed_hosts: ["xxx.xxx.xxx.166", "xxx.xxx.xxx.167", "xxx.xxx.xxx.168"] #7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。 #该选项配置为node.name的值,指定可以初始化集群节点的名称 cluster.initial_master_nodes: ["node-1","node-2","node-3"] #解决跨域问题 http.cors.enabled: true http.cors.allow-origin: "*"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.2,kibana安装
这个在第一篇安装也详细的讲解过,但是在 kibana.yml 中,也需要修改部分配置如下,需要把es所在服务器的主机号以及端口号进行配置
server.port: 5601 server.host: "xxx.xxx.xxx.166" elasticsearch.hosts: ["http://xxx.xxx.xxx.166:9200","http://xxx.xxx.xxx.167:9200","http://xxx.xxx.xxx.168:9200"] i18n.locale: "zh-CN"- 1
- 2
- 3
- 4
3,X-pack安全认证
为了解决数据的安全性,防止出现数据被抓包的可能,因此需要为每台机器上面的结点创建一个安全认证,这里选择通过这个 x-pack的方式实现
首先进入每一台机器的容器中,如这个166这台
docker exec -it elasticsearch /bin/bash- 1
随后直接执行下面的命令,随后会出现提示,需要输入两次密码
// 为集群创建一个证书 elasticsearch-certutil ca- 1
- 2
继续执行下面的命令
// 为集群中的结点生成证书和私钥 elasticsearch-certutil cert --ca elastic-stack-ca.p12- 1
- 2
执行成功之后,给es文件夹下的两个文件授权
chmod 777 elastic-certificates.p12- 1
随后再修改每台机器中 elasticsearch.yml 中的配置,在原有的基础上,在增加以下的参数
## elasticsearch.yml 配置 xpack.security.transport.ssl.enabled: true xpack.security.transport.ssl.verification_mode: certificate xpack.security.transport.ssl.client_authentication: required xpack.security.transport.ssl.keystore.path: elastic-certificates.p12 xpack.security.transport.ssl.truststore.path: elastic-certificates.p12- 1
- 2
- 3
- 4
- 5
- 6
在增加完上面的安全认证之后,随后在增加这个开启xpack安全认证的配置,依旧是每台服务中的这个 elasticsearch.yml 中
xpack.security.enabled: true # 开启xpack认证机制- 1
随后重启es服务,重启完成之后,再进入这个es
docker exec -it elasticsearch /bin/bash- 1
进入es之后,再输入一下命令
elasticsearch-setup-passwords interactive- 1
进入到里面之后,可以发现这里面可以设置es,kibana,logstach等system系统的一些密码,可以手动的创建密码
Enter password for [elastic]: Reenter password for [elastic]: Enter password for [apm_system]: passwords must be at least [6] characters long Try again. Enter password for [apm_system]: Reenter password for [apm_system]: Enter password for [kibana_system]: Reenter password for [kibana_system]: Enter password for [logstash_system]: Reenter password for [logstash_system]: Enter password for [beats_system]: Reenter password for [beats_system]: Enter password for [remote_monitoring_user]: Reenter password for [remote_monitoring_user]: 1234Changed password for user [apm_system] 56Changed password for user [kibana_system] Changed password for user [kibana] Changed password for user [logstash_system] Changed password for user [beats_system] Changed password for user [remote_monitoring_user] Changed password for user [elastic]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
比如给kibana设置密码,直接在进入kibana内部,随后再打开这个 kibana.yml 配置,随后修改往这个yml文件中加入以下的账号密码
elasticsearch.username: "kibana" elasticsearch.password: "123456"- 1
- 2
再重启这个kibana之后,就可以发现在打开这个kibana的之后,是需要输入这个上面配置的账号密码的
4,Node结点类型
4.1,不同结点的配置
上面提到了节点的类型有Master主结点、Master eligible从节点、Coordinaing协调结点、Data数据节点等节点,而每一个结点都是一个java进程,并且最初都是可以参与选举的从节点,那么在进行配置的时候,就需要通过不同的参数,设置成不同的结点

设置节点类型的参数如下,需要通过这几个属性设置对应的结点

设置成主结点的方式如下,只需要一个node.master为true即可,其他的全部设置为false
node.master: true node.ingest: false node.data: false- 1
设置成数据节点的方式如下,只需要node.data的值为true即可,其他的设置成false
node.master: false node.ingest: false node.data: true- 1
设置成ingest节点的方式如下,只需要node.ingest为true即可,其他的设置成false
node.master: false node.ingest: false node.data: true- 1
协调结点可以直接将三个值全部设置为false,如果并没有设置协调结点,那么在接收到请求的节点就默认当成协调节点
node.master: false node.ingest: false node.data: false- 1
4.2,单一职责的好处
上面说了同一个进程,通过不同的参数设置,实现不同的功能,通过不同角色实现单一职责,从而增加整个ElasticSearch的高可用性
- 如单一职责的Master主结点,主要用于索引和分片的管理,如创建删除等等,影响整个集群数据的结点,因此在实际开发中,可以选择低配置的CPU、RAM处理器和磁盘等
- 如这个可以参与选举的默认的从结点,主要用于负责集群的状态管理,主结点挂了就参与选举称为主结点,在实际开发中,也可以选择低配置的CPU、RAM处理器和磁盘等
- 如这个处理数据大Data结点,负责数据处理,解决水平扩展等问题,可以使用高配置的CPU、RAM处理器以及磁盘
- 如这个ingest结点,主要也是负责数据的处理,那么也可以使用这个高配置的CPU,中配置的RAM处理器和低配置的磁盘
- 而这个协调者结点,主要负责数据的接收和转发,并且最后需要对查询的数据进行计算和汇总,那么需要高配置的CPU、高配置的RAM处理器和低配置的磁盘即可
当系统重有大量的复杂的查询时,可以通过增加协调者结点的个数,来增加查询的性能。
当磁盘容量无法满足需求或者读写的压力比较大时,可以增加数据节点
-
相关阅读:
2024-06-12 问AI: 在大语言模型中,什么是Jailbreak漏洞?
【译】使用 .NET Aspire 和 Visual Studio 开发云原生应用
Anaconda虚拟环境创建管理流程
数据结构的两个选择,感觉题库答案不对啊
【网络编程】IO模型
第十九章总结(绘制图片)
如何将平板或手机作为电脑的外接显示器?
win10部署 Mistral-7B 文本生成模型
GBase 8s数据库级别权限
Java的继承到底是怎么回事?看这篇让你明明白白
- 原文地址:https://blog.csdn.net/zhenghuishengq/article/details/134258577
