-
python DevOps
在云原生中,python扮演的角色是什么?
在云原生环境中,Python 作为一种高级编程语言,在多个方面扮演着重要角色。云原生是指利用云计算的各种优势(如弹性、可扩展性和自动化),构建和运行应用程序的方法和技术集合。在这样的环境中,Python 的特点和优势如下:
-
微服务架构:云原生应用通常基于微服务架构,这意味着应用被拆分为一系列小的、独立的服务,每个服务执行应用的特定功能。Python 由于其简洁性、易读性和广泛的库支持,非常适合快速开发和部署微服务。
-
容器和编排:在云原生环境中,容器(如Docker)和容器编排技术(如Kubernetes)是核心组件。Python 应用可以容易地容器化,并在任何支持容器技术的环境中部署。此外,还有多个用于管理容器化应用程序生命周期的 Python 库和工具。
-
自动化和API:Python 是自动化的一个非常强大的工具,这在云原生环境中尤为重要。利用 Python,可以编写脚本和工具来自动化部署流程、监控、数据收集等。同时,Python 的广泛的库和框架可以用于快速开发 RESTful API,这对于微服务之间的通信至关重要。
-
数据分析和机器学习:云原生应用程序常常需要处理大量数据以及进行实时分析。Python 在数据科学、分析和机器学习领域非常强大,拥有如 NumPy、Pandas、SciPy、TensorFlow 和 PyTorch 等库,使其能够高效地处理数据操作和计算。
-
DevOps 工具链集成:在云原生和 DevOps 环境中,持续集成和持续部署(CI/CD)是常见的实践。Python 可以集成到 DevOps 工具链中,提供脚本支持,用于构建、测试、部署和监控应用程序。
-
云服务交互:大多数云提供商(如 AWS、Google Cloud Platform、Microsoft Azure 等)都提供了 Python SDK,使得开发人员能够直接与云服务进行交互,更轻松地集成云功能和服务。
总之,Python 由于其灵活性、易用性以及丰富的库生态系统,在云原生开发的许多方面都扮演着关键角色。它帮助团队快速迭代,适应云原生环境中不断变化的需求和挑战。
1、用python的 subprocess就能写出ping 255个ip哪个不通。多进程就能快很多,用fork
import subprocess import multiprocessing # 定义一个函数,用于执行ping命令并返回结果 def ping_ip(ip): # 使用ping命令测试IP地址的连通性,-c表示发送的ping包数量 command = f"ping -c 1 {ip}" # 执行ping命令,并捕获标准输出和标准错误 result = subprocess.run(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True) # 根据ping命令的返回码来判断是否通达 if result.returncode == 0: return f"{ip} is reachable" else: return f"{ip} is not reachable" if __name__ == "__main__": # 要测试的IP地址列表 ip_list = ["192.168.1.1", "8.8.8.8", "10.0.0.1", "nonexistent_ip"] # 创建多个进程来并行执行ping操作 with multiprocessing.Pool(processes=len(ip_list)) as pool: results = pool.map(ping_ip, ip_list) # 打印每个IP地址的测试结果 for result in results: print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2、子进程在循环中不写exit(),会发生再生成子进程,核心就是子进程下次循环就少一次,生出孙进程,循环少两次。。。直到结束
windows是没有os.fork的,多进程不行,但支持多线程
import os import time def main(): for i in range(5): # 仅仅为了示例,我们尝试创建5个子进程 pid = os.fork() if pid == 0: # 判断当前进程是否是子进程 # 这里是子进程 print(f"子进程: {os.getpid()}") # 如果没有exit,子进程将继续执行循环 # ... 子进程需要执行的代码 ... # 非常重要: 子进程完成工作后应该退出 # os._exit(0) else: # 这里是父进程 print(f"父进程: {os.getpid()}, 创建了子进程: {pid}") time.sleep(1) # 让循环稍微慢一点,更容易观察 if __name__ == "__main__": main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3 python和go的区别
Go语言(也称为Golang)是一种由Google开发的编程语言,它在许多领域都有其用武之地。以下是一些Go语言的主要应用领域:
-
Web开发:Go语言非常适合构建高性能的Web应用程序。它有一个强大的标准库,包括用于HTTP处理的包,使其易于创建Web服务器和API。一些知名的Web框架,如Gin和Echo,也是用Go语言编写的,它们提供了额外的功能和性能优化。
-
分布式系统:Go语言具有并发编程的内置支持,使其成为构建分布式系统和微服务的理想选择。它的轻量级线程(goroutines)和通道(channels)机制使并发编程更加容易和高效。
-
容器编程:Go语言是Docker等容器化平台的核心编程语言。Docker的引擎(containerd)和Kubernetes编写部分核心组件也都是用Go语言编写的。
-
系统编程:Go语言可以用于编写操作系统和系统级应用程序,因为它支持低级别的系统调用,并具有良好的性能。
-
云计算:Go语言适用于构建云计算和后端服务,特别是在需要处理高并发的情况下,如云存储、消息队列等领域。
-
网络编程:Go语言的标准库包括一组用于构建网络应用和网络协议的功能丰富的包,使其成为编写网络应用程序的良好选择。
-
数据分析:尽管Go语言的生态系统在数据分析领域不如Python丰富,但它仍然可以用于处理大规模数据和编写数据处理工具,特别是在需要高性能的情况下。
-
物联网(IoT):由于其轻量级和高性能特性,Go语言也可以用于编写物联网设备的控制和通信软件。
总的来说,Go语言的用武之地涵盖了许多不同的应用领域,尤其在需要高性能、并发支持和系统级编程的情况下,它表现出色。如果你在这些领域中工作或有相关需求,Go语言可能是一个不错的选择。
5 爬虫 urllib
可以读取网页内容,保存成文件,图片,视频,声音都可以
有些大文件,每次读取一部分

urllib是比较底层的,可以用上层wget这个工具, python中 import wget可以把网站的所有图片都下载到本地一个文件夹中
面对障碍
1、可以设置一些headers信息(User-Agent),模拟成浏览器去访问这些网站
2、url 里面有中文,阿斯码解不了,浏览器人家是自己给转码了,代码中要加上 request.quote(‘中文’)6 paramiko
pip install paramiko
代码中变成ssh客户端,用于 多线程 执行远程命令7 邮件
发送邮件,收邮件
plain代表纯文本,就像vi编辑的都是文本,富文本就是又有图片,又有链接
下面是给自己主机上面的其他用户发邮件。还可以向互联网上发邮件

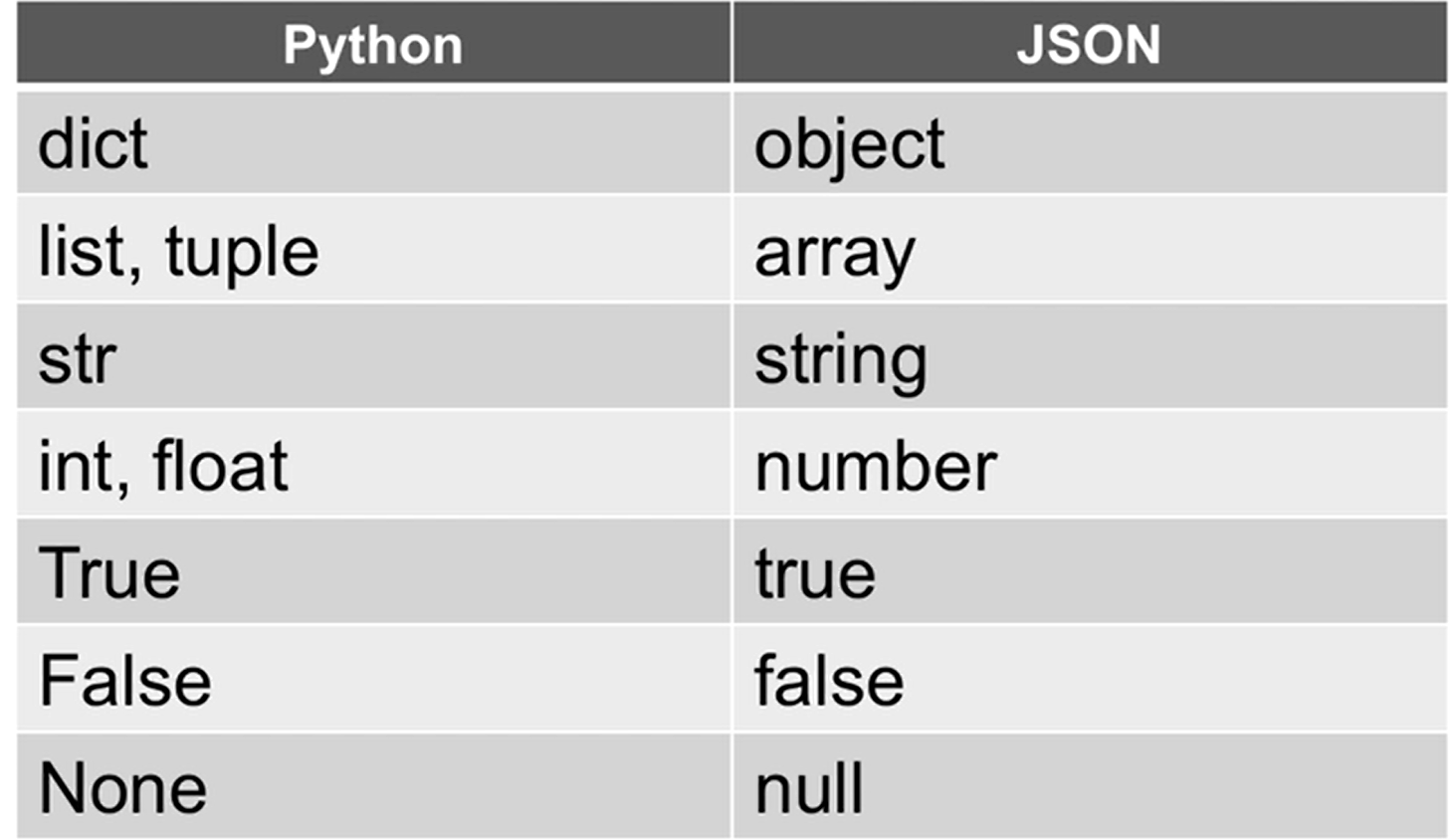
SMTP: 简单邮件传输协议,用的TCP 端口25。python 中用 smtplib8 JSON
跨语言通信,python有元组,列表list,没数组,发送给另一个语言有数组的就会用到 json, 先转成json字符串作为中介
9 request – HTTP库,比urillib3更简单
GET PUT POST DELETE
10 Ansible
它是python编写的,可以 pip install ansible==2.7.2
ssh-keyscan就能把密钥扫描保存下来就省的每台注意ssh后输入yes
比如 ssh-keyscan host1 host2 host3 >> ~/.ssh/known_hosts

playbook
模块名字,目标hosts是谁?tasks干什么?- 能每台机器yum安装,可以更新到最新的版本或者已经存在
- 能设置服务起来并且enable
Ansible API
下面两点 interview 问遇到的问题,这个就可以用上
3. 就是用 python 控制 ansible Adhoc和 Playbook
ssh控制其他主机的时候提供的用户不是root,就需要提权操作
become = yes
become_method= sudo
become_user= root
become_ask_pass = no 不用输入密码,需要设置这个需要提权的用户 NOPASSWD: ALL
4. 不希望 playbook 中明文出现密码的时候,可以用vault_pass加密,
ansible-vault encrypt /tmp/passwd 输入加密密码
cat /tmp/passwd 就是加密文件了
解密用 ansible-valut decrypt /tmp/passwd
5. 运行playbook 就是方法里传入 hosts文件和 yaml 文件Ansible 模块开发
灰色注释就是用法,不过首先要配置环境变量=你设计的这些模块的代码的目录
把注释中的“用法”,删掉,不要有中文,否则编码错误
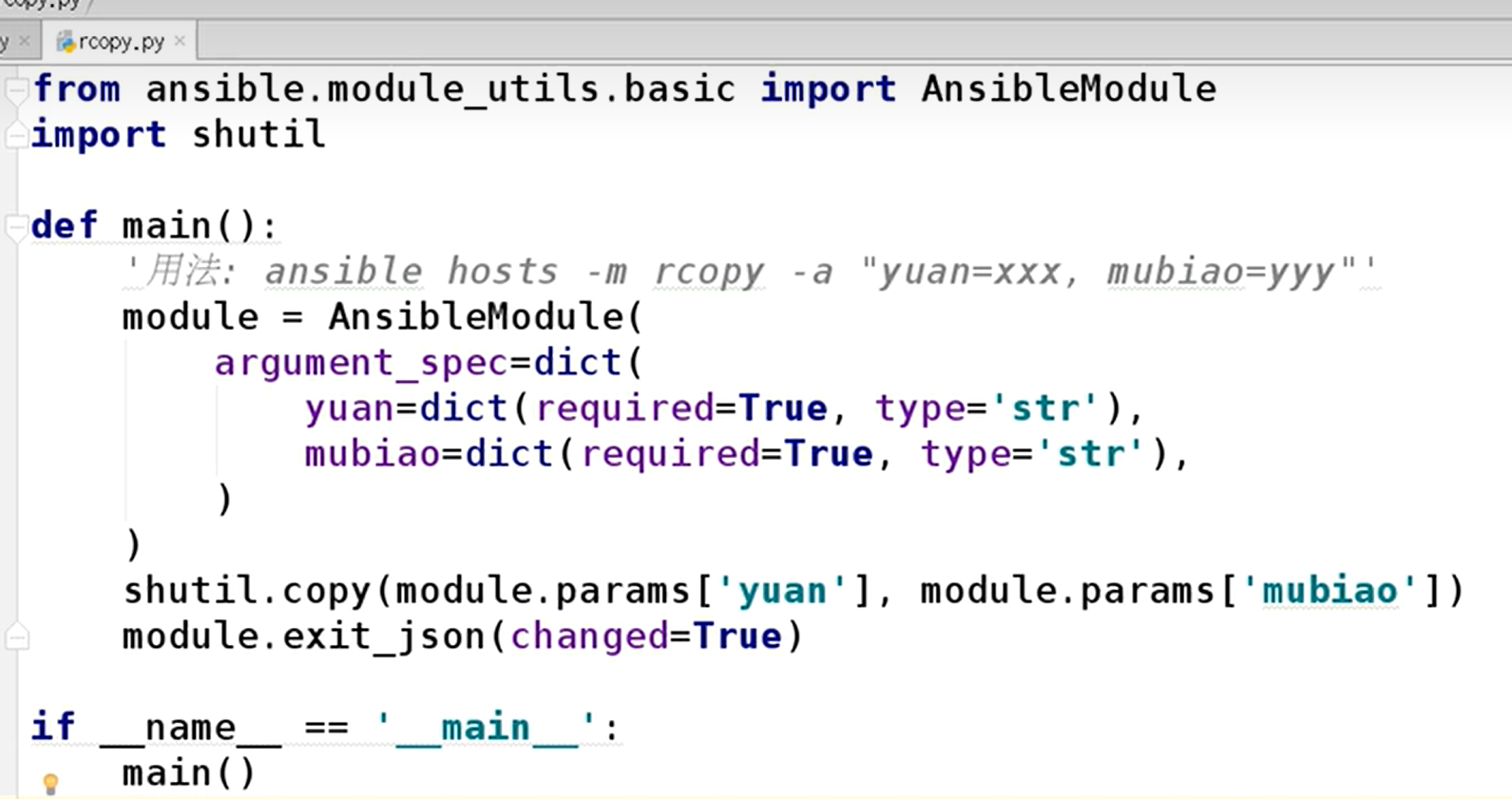
下面是从url文件下载到本地,远程主机,就是执行代码那台也要安装wget

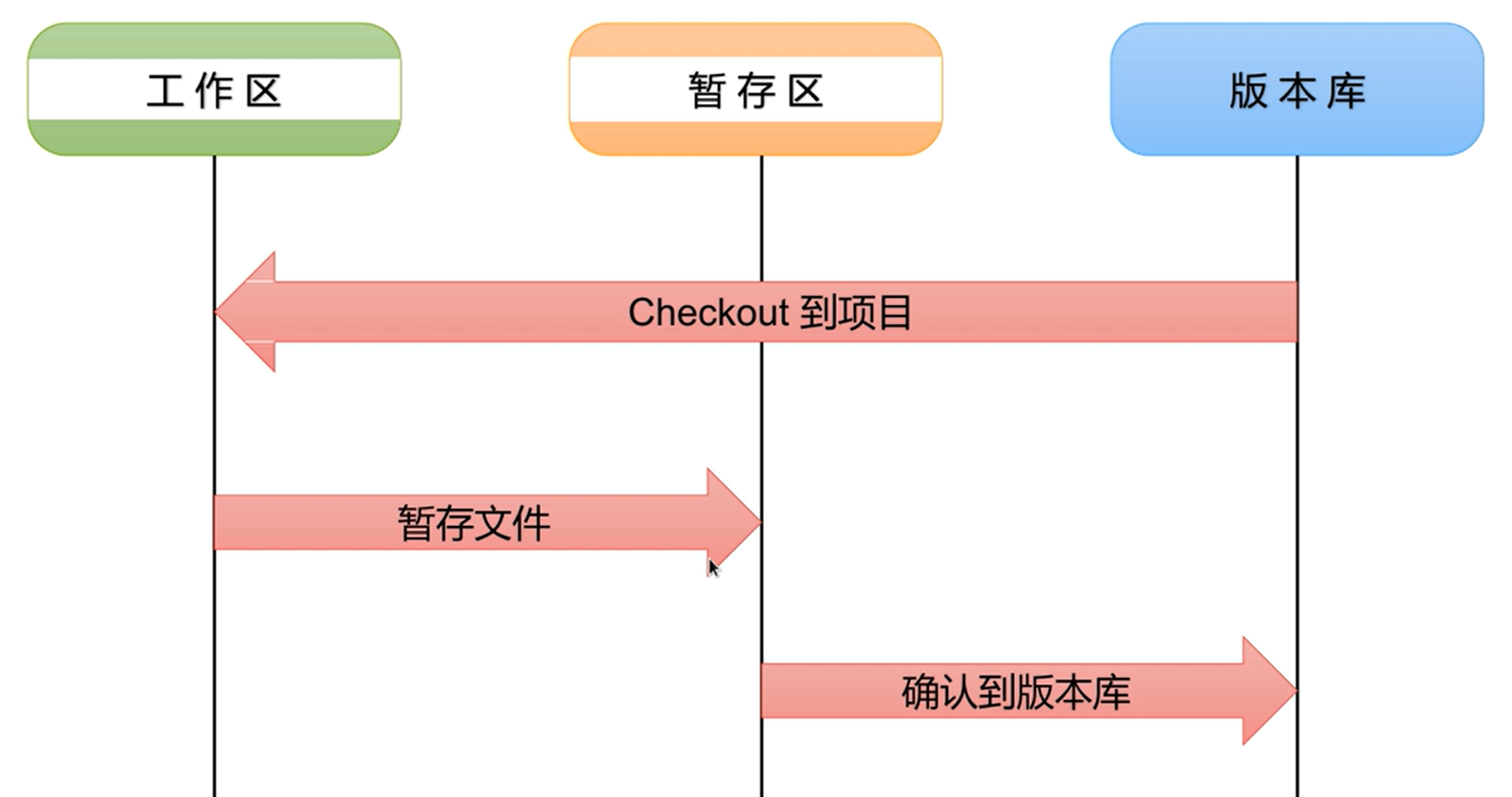
11 Git 版本控制系统
能回溯到以前的版本,多人协作

暂存区就是后悔药
01 git安装后,配置用户信息

–global代表全局生效
执行 git config --global core.editor vim 后,当 Git 需要你编辑文本的时候,它会自动打开 Vim 编辑器让你进行编辑。这是一种个性化你的工作环境的方式,确保 Git 在各种需要输入文本的情况下使用你最喜欢或最习惯的编辑器。02 基础应用
- 创建仓库

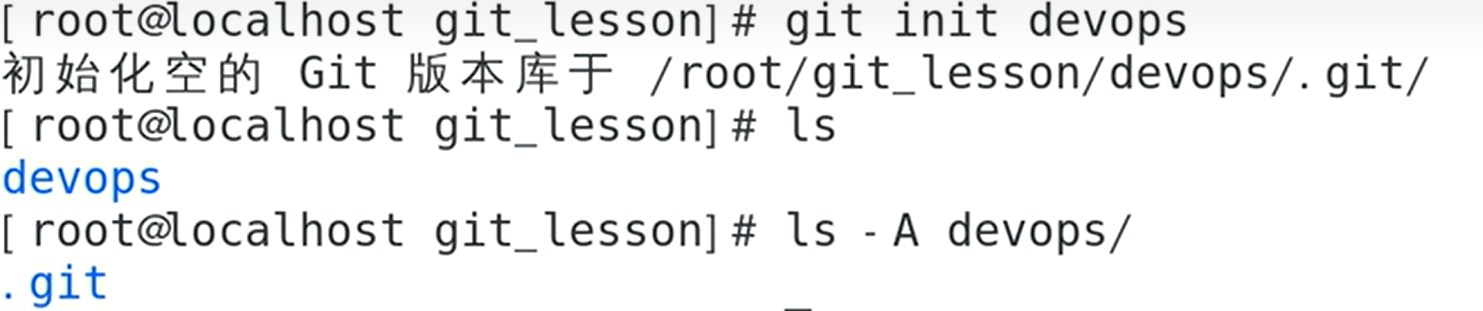
.git就是版本库
也可以git clone过来项目,上面就是初始化仓库的三个方法

git add就是放到暂存区,也就是开始跟踪文件了,commit就是放到版本库里了
git add .把所有的文件都跟踪
不想跟踪某些文件,用 .gitignore来控制
 ls .git会看到 index这个文件,这个就是暂存区,commit之后才会进入到版本库 .git
ls .git会看到 index这个文件,这个就是暂存区,commit之后才会进入到版本库 .git
干净的工作区:就是无文件要提交
git add 后,可以 git reset HEAD … 撤出暂存区。
git commit -m “这次提交的注释”

03
git reset和git rm是 Git 中用于处理文件更改的两个不同命令,它们的用途和行为有重要差异。以下是每个命令的功能及其常见用例。1.
git reset:就是从暂存区撤出,之前修改的内容还在,就是需要再次git add-
用途:
git reset主要用于取消已经暂存的更改。你可以用它来撤销对暂存区的修改,例如错误地添加了一些文件到暂存区(stage)时。 -
行为:当你使用
git add将文件添加到暂存区后,如果你决定不想提交某些文件,可以使用git reset HEAD来将它们从暂存区移回工作区。 -
示例:假设你修改了两个文件
file1.txt和file2.txt并用git add将它们添加到暂存区。如果你决定只提交file1.txt,可以使用git reset HEAD file2.txt将file2.txt从暂存区移除。git add file1.txt file2.txt # 将文件添加到暂存区 git reset HEAD file2.txt # 将 file2.txt 从暂存区移除- 1
- 2
这样,
file2.txt的更改不会出现在接下来的提交中,但文件的更改仍会保留在你的工作目录中。
2.
git rm:-
用途:
git rm用于从工作目录和暂存区中删除文件,它告诉 Git 你希望在接下来的提交中删除这些文件,同时也将文件从你的实际工作目录中移除。 -
行为:
git rm不仅会将文件从暂存区中移除,还会从物理磁盘中删除文件。 -
示例:如果你不再需要
file3.txt,你可以用git rm file3.txt来删除它。git rm file3.txt # 删除文件并从暂存区移除 git commit -m "Remove file3.txt" # 提交这次删除操作- 1
- 2
这会在你的下一次提交中删除
file3.txt,并且file3.txt也不再出现在你的文件系统中。
总的来说,
git reset更多的是关于取消暂存的更改,而git rm是关于完全删除文件(从工作目录和版本历史中)。使用这些命令时需要谨慎,以确保不会误删工作或者将不想提交的更改添加到版本历史中。3. 本地仓库与远程仓库
Git 中的本地仓库和远程仓库之间的关系可以概括为以下几个方面:
-
镜像和独立性:本地仓库在 Git 中是远程仓库的完整镜像。这意味着每个本地仓库包含了所有的历史记录和版本信息,与远程仓库完全独立。这种设计使得开发者可以在没有网络连接的情况下继续工作,并且能够保持所有的项目历史。
-
数据同步:虽然本地仓库和远程仓库是独立的,但它们之间可以通过
push(上传本地更改到远程仓库)和pull(从远程仓库下载更改到本地仓库)命令进行数据同步。这样,不同开发者可以在自己的本地仓库上工作,并与远程仓库同步来共享和合并更改。 -
分支管理:在本地仓库中创建的分支可以被推送到远程仓库(反之亦然),允许多个开发者在不同的分支上并行工作。这种机制促进了团队合作和代码的并行开发。
-
权限和安全:远程仓库通常托管在如 GitHub、GitLab 或 Bitbucket 等服务上,这些服务提供了权限管理和安全机制。这意味着可以对谁可以访问仓库、谁可以推送代码进行控制。
04 git log 查看提交历史
05 git check out 慎用,因为你的修改不在,直接回到解放前某个提交版本
1)分支的用处
在 Git 中,分支概念的应用非常广泛,对于软件开发尤为重要。以下是一些关键的用武之地:
-
功能开发和实验性更改:通过创建一个新的分支,开发者可以在不影响主分支(通常是
master或main)的情况下开发新功能或进行实验性更改。这样可以确保主分支的稳定性。 -
错误修复:对于发现的bug,可以在专门的分支上进行修复,然后将修复合并回主分支。这样有助于保持主分支的稳定和干净。
-
代码审查和合并请求:在多人协作的项目中,通过分支可以轻松实现代码审查。开发者在自己的分支上工作,完成后通过合并请求(Merge Request)或拉取请求(Pull Request)将更改合并到主分支。
-
版本控制:对于发布的每个版本,可以创建一个分支来维护。这对于后续的bug修复和版本更新非常有用。
-
持续集成/持续部署(CI/CD):分支可以与自动化构建和部署流程结合,例如,当推送到特定分支时,自动启动构建和测试流程。
-
多环境开发:在多环境(如开发、测试、生产)的项目中,可以为每个环境维护不同的分支,以便更好地管理和部署。
-
团队合作和分工:在大型项目中,不同的团队或小组可以在不同的分支上工作,从而实现有效的分工合作。
-
备份和恢复:在进行大规模更改前,可以创建一个分支作为当前状态的备份。如果更改失败,可以轻松回滚到这个分支。
-
实验和探索:分支可以用来尝试新的编程技术或探索不同的解决方案,而不会扰乱主分支的代码。
2)分支操作
-
切换分支:如果你想要切换到一个不同的分支,你可以使用
git checkout加上你想要切换到的分支的名字。示例:
git checkout develop- 1
这个命令会将你当前的工作分支切换到名为
develop的分支。如果这个分支不存在,Git 会给出一个错误提示。 -
创建新分支并切换到该分支:如果你想要创建一个新分支并立即切换到这个分支,你可以添加
-b参数来实现。示例:
git checkout -b new-feature- 1
这个命令会创建一个名为
new-feature的新分支,并将当前分支切换到这个新分支。 -
恢复文件:如果你对一些文件进行了修改但还未提交,而现在你想放弃这些修改,返回到最后一次提交的状态,你可以使用
git checkout。示例:
git checkout -- file1.txt- 1
这条命令会放弃对
file1.txt文件的所有修改,使其返回到最后一次提交的状态。请注意,这会删除自上次提交以来对该文件的所有修改,所以在使用此命令前要确保不需要这些修改。 -
检出特定的提交:如果你想查看项目历史中的特定提交或标签,可以使用
git checkout加上提交的哈希值或标签名。示例:
git checkout 7a052cf- 1
这会更新工作目录中的所有文件,使其反映在哈希值为
7a052cf的提交时的状态。在这种状态下,你处于一个“DETACHED HEAD”状态,意味着不在任何分支上,这个状态下的任何更改都不会记录到项目历史中,除非你创建一个新分支。
请注意,在 Git 的新版本中,一些
git checkout的功能已经被更专一的命令所取代,例如用于切换分支的git switch命令和用于恢复文件的git restore命令。这些新命令的目的是使 Git 的操作更加直观和用户友好。不过,git checkout命令在很多情况下仍然可用,且被广泛理解和采纳。06 git 分支管理
git如果两人都同时修改了一个项目的代码,都提交了会发生什么?git是怎样保证多人协作开发一个项目的呢?
-
分支和合并(Branching and Merging):
- Git鼓励使用分支来进行功能开发。每个开发者可以在自己的分支上工作,完成后再将分支合并回主分支(如
main或master)。这样可以减少冲突的可能性。
- Git鼓励使用分支来进行功能开发。每个开发者可以在自己的分支上工作,完成后再将分支合并回主分支(如
-
拉取和合并代码(Pull and Merge):
- 当一个开发者(比如说开发者A)想要提交(push)代码到远程仓库时,如果在此期间另一个开发者(开发者B)已经提交了更新,那么开发者A的提交可能会被拒绝,因为他的本地版本已经落后于远程仓库的版本。
- 在这种情况下,开发者A需要先执行
git pull(这通常会自动合并远程的更改,或者如果有冲突则需要手动解决)或者git fetch然后git merge(如果希望分步操作)来整合开发者B的更改。 - 如果两个开发者更改了同一文件的同一部分,Git无法自动解决合并冲突,此时开发者A需要手动解决这些冲突。
-
解决合并冲突(Resolving Merge Conflicts):
- 在合并时,如果两个开发者修改了同一文件的同一部分,Git会标记出冲突并要求手动解决。开发者需要选择保留哪些更改,或者创建新的内容来替换冲突部分。
- 解决冲突后,开发者需要进行提交,以完成合并过程。
-
代码审查(Code Reviews):
- 在多人团队中,通常会通过Pull Requests(PR)或Merge Requests(MR)来引入更改。这为团队提供了一个审查代码、提出修改建议并讨论更改的平台,从而可以在代码合并到主分支之前确保代码质量。
git fetch和git merge
git fetch和git merge是 Git 中两个不同但经常一起使用的命令,它们有各自的用武之地:-
git fetch:
- 用途:
git fetch用于从远程仓库获取最新的变更,但不自动合并它们到你当前的分支。它只是将远程仓库的分支状态更新到本地,不会改变你的工作目录或当前分支。 - 场景:
- 当你想了解远程仓库的最新状态,但不打算立即合并它们时,可以使用
git fetch。 - 在多人协作项目中,可以使用
git fetch来查看其他团队成员已推送的更改,以便在合并之前进行审查。
- 当你想了解远程仓库的最新状态,但不打算立即合并它们时,可以使用
- 用途:
-
git merge:
- 用途:
git merge用于将一个分支的更改合并到另一个分支。它会将指定分支的更改应用到当前分支,并创建一个新的提交来记录合并操作。 - 场景:
- 当你想将一个分支的更改合并到当前分支时,可以使用
git merge。这通常用于将特性分支的更改合并到主分支(如master或main)。 - 在团队协作项目中,你可以通过合并其他团队成员的分支来整合他们的工作。
- 当你想将一个分支的更改合并到当前分支时,可以使用
- 用途:
常见的工作流程:
- 使用
git fetch来获取远程仓库的最新更改,以确保你了解其他人的工作。 - 使用
git merge来合并其他分支的更改到当前分支,以使你的工作与最新更改保持同步。
需要注意的是,有时候为了更加控制合并过程,开发者也可以使用
git pull命令,它实际上是git fetch和git merge的组合,但可以在一个命令中完成。然而,git pull的使用需要小心,因为它可能导致不可预料的合并冲突。因此,一些开发者更喜欢分别使用git fetch和git merge,以更好地管理合并过程。07 git tag
当你使用Git标签时,你可以选择两种不同类型的标签:轻量标签和附注标签。这是一个通俗易懂的解释:
-
轻量标签(Lightweight Tags):轻量标签就像是给一个特定的提交打上了一个名字。这个名字就是标签的名字,而且它不包含额外的信息,只是一个名字而已,就像给一份文件起个名字一样。这种标签很轻巧,不会包含创建者、日期等额外信息。
例子:你在代码库中有一个重要的版本1.0,你可以用轻量标签 “v1.0” 来表示这个版本。这只是一个简单的名字,没有其他信息。
-
附注标签(Annotated Tags):附注标签更像是一个包含了很多额外信息的标签。它不仅包含了一个名字,还包括了创建者、日期、标签消息等。这就像给一个文件添加详细的描述和作者信息,让其他人能够更好地理解这个标签代表的含义。
例子:在一个大型开源项目中,发布一个新版本时,你可以创建一个附注标签来包含发布说明、签名等详细信息。这对于其他开发者和用户来说非常有帮助。
总之,轻量标签就像是一个简单的名字,适用于简单的情况,而附注标签是一个包含了详细信息的标签,适用于需要更多信息和安全性的情况。你可以根据具体的需要选择使用哪种类型的标签。无论你选择哪种类型,都可以随时创建和使用标签来标记重要的里程碑和版本。
Git 标签(tags)主要用于标识特定的版本提交点,通常用在发布软件版本(如 v1.0 等)的场景中。以下是 Git 标签的几个主要用途及其解决的问题:
1. 版本发布(Releases)
问题:在软件开发过程中,需要有一个明确且不变的方式来标识某个特定点作为“发布版本”。否则,开发者和用户都难以追踪和引用项目的特定状态。
解决:通过创建一个标签,可以清晰地标记软件的重要发布点。
示例:
git tag -a v1.0 -m "Release version 1.0"- 1
这样,就创建了一个名为
v1.0的标签,代表软件的一个发布版本。2. 代码审查(Code Reviews)
问题:在大型项目中,可能会有许多提交和更改,审查者可能希望引用或检查特定的提交。
解决:可以为代码审查创建标签,确保审查者查看正确的代码快照。
示例:
git tag -a review-2023-10-28 -m "Code review on October 28, 2023"- 1
这个标签标识了审查者应该关注的代码状态。
3. 创建里程碑(Milestones)
问题:在项目进展中,需要标识特定的里程碑或成就点,以便将来回溯或参考。
解决:通过对重要提交创建标签来标识项目的关键阶段或里程碑。
示例:
git tag -a milestone-1 -m "Completed the first major segment of the project"- 1
通过这个标签,团队知道这个提交代表了项目的一个重要阶段。
4. 辅助回滚(Aiding Rollbacks)
问题:如果新的代码引入了严重的错误,可能需要回滚到工作良好的状态。
解决:标签可以帮助识别安全的回滚点,尤其是在紧急修复时。
示例:
git tag stable-before-migration- 1
之后,如果需要回滚,可以简单地通过以下命令回到这个稳定状态:
git checkout stable-before-migration- 1
5. 文档或说明(Documentation or Annotations)
问题:项目文档需要引用代码库中的特定点,以说明特定的功能或代码示例。
解决:通过为文档中提及的示例或教程创建标签,读者可以直接访问具体的代码状态。
示例:
git tag -a documented-example -m "This commit was used in the tutorial documentation"- 1
tutorial documentation 教程文档
在项目文档中,可以提及这个标签,方便读者查找。通过使用标签,开发者可以更容易地管理项目的版本历史,无论是对于特定发布、重要更改还是简单的项目里程碑。标签为 Git 仓库提供了一个更加组织化的管理方法,并确保团队成员和最终用户都能准确无误地引用代码的特定状态。
08 分支
大家都在主干上改,很乱,自己写自己的分支,最后首先切换到master分支,然后git merge 你的分支,合并的时候,分支里面特有的文件也进来了
如果合并分支的时候,和主干有相同的文件,但是内容不同,会发生什么?
当尝试合并两个分支时,如果两个分支都对同一文件进行了更改,Git 将尝试自动合并更改。然而,根据更改的性质,情况会有所不同:
- 非冲突更改:如果更改发生在文件的不同部分,Git 通常可以自动合并这些更改。这意味着每个分支对相同文件的不同部分所做的更改都将被结合在一起。
例如:
- 主分支中,你改变了文件的第一部分。
- 在另一个分支中,更改发生在文件的第二部分。
- 合并这两个分支时,Git 将两处更改整合到一起。
- 冲突更改:如果两个分支更改了文件的同一部分,Git 将无法自动合并更改,这会导致合并冲突。
例如:
- 主分支中,你改变了文件的第一部分。
- 在另一个分支中,同样的文件的同一部分被以不同的方式更改。
- 当你尝试合并这两个分支时,Git 不知道应该保留哪个版本,因此它停止合并过程,让你解决这个“冲突”。
当合并冲突发生时,你需要手动介入做决定。Git 会在文件中标记出冲突的部分,大致如下所示:
<<<<<<< HEAD 这里是主分支中的版本内容 ======= 这里是你尝试合并的分支中的版本内容 >>>>>>> feature-branch- 1
- 2
- 3
- 4
- 5
要解决这些冲突,你需要:
- 打开包含冲突的文件。
- 决定保留哪个版本的更改,或者可能手动合并内容,编辑为最终想要的状态。
- 删除
<<<<<<< HEAD,=======, 和>>>>>>> feature-branch这些标记行,它们不应出现在最终内容中。 - 保存文件。
- 提交这些更改。
通过解决所有冲突并提交更改,你将完成合并过程。解决合并冲突是版本控制工作流中的一个重要组成部分,它需要开发者仔细比较冲突的内容,做出最符合项目需求的决策。
在 Git 中,分支(branch)是开发工作流中的一个核心概念。理解和有效管理分支对于协同工作、特性开发、以及保持代码的稳定性至关重要。分支的概念:
-
定义:Git 中的分支本质上是项目历史的不同版本。每个分支代表一个独立的开发线,可以包含特定的更改或新功能。分支可以合并回主线(通常是
main或master分支),这样不同开发线的更改可以集成到一起。 -
工作方式:在 Git 中,提交对象包含一个指向它们父对象的指针。“分支” 实际上是一个轻量级的可移动指针,指向这些提交对象之一。当你创建新的提交时,分支指针自动向前移动,指向新创建的提交。
何时使用分支:
-
新功能开发:当你打算添加一个新功能时,你可以创建一个分支,这样不会影响主开发线(如
main或master分支)。这使得你可以在不打乱主开发流程的情况下工作。 -
实验和探索:如果你想尝试新的想法或不确定的修改,创建一个新分支是安全的,因为它不会影响主分支。
-
修复错误:对于 bug 修复,创建一个新分支可以让你在不影响或阻断其他开发工作的情况下处理这些问题。
-
代码审查和协作:在多人项目中,你可以在分支中工作并推送(push)你的更改,然后请求他人审查并合并你的更改。
怎么使用分支:
以下是使用分支的基本命令和步骤:
-
创建分支:
git branch feature-branch- 1
这将创建一个名为
feature-branch的新分支,但你仍在当前分支上。 -
切换分支:
git checkout feature-branch- 1
这会切换到新创建的
feature-branch。现在,所有新的提交都会添加到这个分支上。注:你可以通过一个命令创建新分支并立即切换到该分支:
git checkout -b feature-branch- 1
-
添加更改并提交:
在分支中,你可以修改文件并提交这些更改:git add . git commit -m "Add my new feature."- 1
- 2
-
推送分支到远程仓库:
如果你想分享这个分支,或将其保存到远程仓库(如 GitHub),你需要推送(push)它:git push origin feature-branch- 1
-
合并分支:
一旦分支中的工作完成,并通过测试,你可能想要将这些更改合并回主分支(比如main):- 首先,切换回主分支:
git checkout main- 1
- 然后,合并你的功能分支:
git merge feature-branch- 1
- 首先,切换回主分支:
-
删除分支:
合并完成后,如果不再需要feature-branch,你可以删除它:- 本地删除:
git branch -d feature-branch- 1
- 远程删除:
git push origin --delete feature-branch- 1
- 本地删除:
通过以上步骤,你可以看到,分支在 Git 工作流中扮演着重要角色,它们帮助团队维护代码的稳定性,同时允许多线程开发。
git fetch然后git merge和git pull的区别是什么?git fetch然后git merge这两步分别做了什么?
git fetch、git merge和git pull都是 Git 中用于更新本地代码库的命令。尽管它们都是为了从远程仓库获取最新更改并将这些更改应用到本地仓库,但它们的工作方式有所不同。下面是每个命令的具体作用和这些命令之间的区别。1.
git fetch:- 当你执行
git fetch时,Git 会连接到远程仓库,检查你当前没有的所有更改或更新(比如其他人提交的新分支或提交等),并将这些信息拉取到你的本地仓库。 - 重要的是,
git fetch只是将这些更新下载到本地仓库,并不会自动合并到你当前的工作分支。这些更改保留在所谓的“远程分支”中。
2.
git merge:- 在执行
git fetch之后,如果你想要将这些更改应用到你的当前分支(比如main),你需要执行git merge(例如,git merge origin/main)。 git merge会将指定分支(在本例中是远程分支origin/main)的更改合并到当前活动分支。如果存在冲突,你需要手动解决这些冲突。
3.
git pull:git pull是一个方便的命令,实际上它是git fetch和git merge的组合。当你执行git pull时,Git 会从远程仓库拉取最新的更改(就像git fetch那样)并立即尝试将这些更改合并到你的当前分支(就像git merge那样)。- 这意味着,如果你直接使用
git pull,你可能需要立即处理合并冲突。而使用git fetch后再使用git merge可以让你有更多的控制:你可以先查看更新,然后再决定如何合并。
总结一下,
git fetch然后git merge提供了更多的控制,允许你在合并之前检查更改。这对于复杂的项目或需要审慎合并的场景特别有用。而git pull是一个更快捷的方式,适用于你信任拉取的更改并希望直接合并它们的情况。在团队协作中,了解何时使用哪种方法是非常重要的,以确保代码库的整洁和项目的稳定性。9 gitlab
一个项目,哪些组能访问,哪些人能访问,最后还是用户上传代码
配置ssh免密登录
自己的服务器生成公钥,拷贝到gitlab.
然后把原来http的remote关联删掉,重建ssh关联
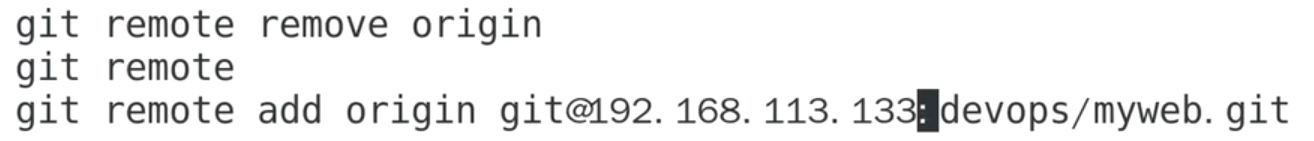
要在 GitLab 上设置免密码登录,通常需要使用 SSH 密钥对。以下是具体的步骤:
-
生成 SSH 密钥对:
- 打开终端(Linux 或 macOS)或 Git Bash(Windows)。
- 运行以下命令生成 SSH 密钥对。你可以替换
ssh-keygen -t rsa -C "" - 1
-
当系统提示你选择密钥文件的存储位置时,可以按 Enter 键接受默认的存储位置(通常是用户的主目录下的
.ssh文件夹)。 -
在生成密钥对的过程中,你可以选择设置一个密码以增加安全性,但这将导致每次使用密钥时都需要输入密码。如果你希望完全免密,请留空密码。
-
添加公钥到 GitLab:
- 打开你的 GitLab 帐户。
- 点击你的头像,然后选择 “Settings”。
- 在左侧导航栏中,选择 “SSH Keys”。

- 在 “Key” 字段中,粘贴你生成的公钥(通常在
~/.ssh/id_rsa.pub文件中)。你可以使用以下命令来复制公钥到剪贴板:
cat ~/.ssh/id_rsa.pub | pbcopy # macOS- 1
cat ~/.ssh/id_rsa.pub | clip # Windows- 1
- 给这个密钥一个标题,以便识别它。
- 点击 “Add key” 按钮以保存公钥。
-
测试 SSH 连接:
- 在终端中,运行以下命令来测试是否可以使用 SSH 密钥连接到 GitLab。替换
ssh -T git@<gitlab_server>- 1
- 如果一切设置正确,你应该看到一条欢迎消息。
- 在终端中,运行以下命令来测试是否可以使用 SSH 密钥连接到 GitLab。替换
-
使用 SSH 克隆/推送:
- 当你在 GitLab 上创建或克隆仓库时,使用 SSH URL 来进行操作。它通常是以
git@的形式。: / .git
- 当你在 GitLab 上创建或克隆仓库时,使用 SSH URL 来进行操作。它通常是以
现在,你已经设置了 SSH 密钥对,并且可以在 GitLab 上免密码登录并进行 Git 操作。请确保保护好你的私钥文件(通常在
~/.ssh/id_rsa)以防止未授权的访问。如果设置了密码,每次使用密钥时都需要输入密码。如果希望完全免密码,可以选择不设置密码,但请注意安全性风险。10 git clone和git fetch
当然,通过一个具体的例子来说明
git clone和git fetch之间的区别可能会更加清晰。假设我们有一个位于GitHub上的项目,我们将通过一系列的步骤来解释这两个命令是如何工作的。步骤 1:使用
git clone假设你刚加入一个新项目,该项目的代码托管在GitHub上。你还没有项目的任何文件,你需要从远程仓库获取代码。这时,你会使用
git clone。git clone https://github.com/exampleuser/exampleproject.git- 1
这个命令做了什么?
- 在你的本地机器上创建了名为 “exampleproject” 的文件夹。
- 初始化了一个空的Git仓库在这个文件夹中(
.git文件夹)。 - 下载了该项目的所有文件,文件夹,和版本历史记录(比如所有的提交)。
- 设置了一个指向原始(或“远程”)仓库的链接,通常这个默认链接名叫做 “origin”。
现在,你有了项目的本地副本,并且可以开始工作了。
步骤 2:项目的进展与
git fetch现在,假设几天已经过去,团队成员已经在远程仓库中做了一些更改。你的本地仓库现在落后于远程仓库。你想看看团队都做了哪些更改,但你不想立即更改你当前的工作或当前分支。这时,你会使用
git fetch。git fetch origin- 1
这个命令做了什么?
- 连接到名为 “origin” 的远程仓库(即你最初克隆的仓库)。
- 下载了所有你还没有的新提交、分支和标签,更新你的本地仓库,使其反映远程仓库的最新状态。
- 并没有 自动合并任何更改到你当前的工作分支。
- 并没有 更改你的工作目录。你的文件保持不变,直到你决定合并这些新拉取的更改。
为了合并这些更改(例如,来自远程的新提交),你通常会使用
git merge或者git rebase。例如,如果你想更新你的主分支,你可能会这样做:git checkout main # 切换到你想要合并更改的分支 git merge origin/main # 合并来自远程主分支的更改- 1
- 2
总结
git clone是你开始工作时使用的,用来获取项目的副本。git fetch用于当你已经有了一个仓库的副本,想了解自上次下载以来发生了什么更改。它让你保持对项目进展的了解,但又不强制立即合并这些更改,从而保持你当前工作的状态。
我们可以通过一个更具体的示例来解释这两个命令之间的区别。假设我们有一个简单的远程仓库,仓库中有几个提交。我们将通过一个场景来详细说明
git clone和git fetch的工作方式和差异。远程仓库的初始状态
假设在GitHub上有一个名为"exampleproject"的远程仓库,仓库的内容很简单:
exampleproject/ │ ├── README.md └── file1.txt- 1
- 2
- 3
- 4
README.md只包含项目的标题。file1.txt包含一些文本。
步骤 1:克隆远程仓库
Alice(一名开发者)没有这个项目的本地副本,她需要开始在项目上工作。她执行以下命令:
git clone https://github.com/exampleuser/exampleproject.git- 1
现在,Alice的本地环境有了项目的完整副本,并且目录结构看起来与远程仓库完全一样。
步骤 2:团队成员做出更改
几天过去了,Bob(另一名开发者)向
exampleproject项目做出了一些更改并提交到了远程仓库。Bob在项目中添加了一个新文件file2.txt,并且更新了README.md。远程仓库现在看起来像这样:
exampleproject/ │ ├── README.md (updated) ├── file1.txt └── file2.txt (new)- 1
- 2
- 3
- 4
- 5
步骤 3:Alice 获取更新
Alice已经在她的本地分支上工作了,她想看看团队成员是否有任何更新。她还不想合并这些更改到她的工作中,所以她决定先获取更新。她执行:
git fetch origin- 1
该命令联系了远程仓库(“origin”),下载了自Alice上次克隆或获取以来其他人所做的所有提交。但是,Alice的当前工作目录还没有改变。她的本地仓库现在包含了对远程更改的引用,但她的工作目录还是旧的状态:
exampleproject/ (Alice's working directory) │ ├── README.md (old version) └── file1.txt- 1
- 2
- 3
- 4
她现在可以查看远程分支上的提交,了解发生了哪些更改。如果Alice决定她现在想合并这些更改,她可以使用
git merge或git rebase将这些新更改应用到她的当前分支。总结
在这个例子中:
git clone是Alice用来最初获取项目的方法。- 当项目有更新,Alice使用
git fetch来了解更改,但她的本地工作未受到影响。 - 这给了Alice一个机会来审查更改,然后她可以决定最佳的合并或重新设置基础的策略,而不是盲目地接受所有新更改。
_____________________+++++++++++++
让我们继续Alice的例子,探讨她是如何查看更改并将它们合并到她的本地分支的。
步骤 4:审查更改
在执行了
git fetch origin之后,Alice想要查看自从她上次更新以来,Bob在远程仓库上具体做了哪些更改。她可以查看远程分支的最新状态,而无需更改本地分支。为了做到这一点,Alice可以使用git log命令:git log main..origin/main- 1
这条命令会显示
main分支和origin/main(即远程的main分支)之间的差异。Alice现在能看到Bob的提交记录,了解他添加了file2.txt并更新了README.md。步骤 5:合并更改
Alice决定Bob的更改对她当前的工作没有影响,并且她想把这些更改合并到她的本地
main分支。她首先确保自己在正确的分支上:git checkout main- 1
然后,Alice可以使用
git merge命令来合并远程仓库的更改:git merge origin/main- 1
这条命令将
origin/main(即她刚刚获取的远程更改)合并到了她当前的main分支。如果有任何冲突,Git将通知Alice,她需要手动解决这些冲突。合并完成后,Alice的工作目录现在将包括Bob所做的更改:
exampleproject/ (Alice's working directory) │ ├── README.md (updated) ├── file1.txt └── file2.txt (new)- 1
- 2
- 3
- 4
- 5
如果Alice希望以一种可以重新组织提交历史的方式来整合更改,她可能会选择使用
git rebase而不是git merge。使用rebase可以为项目历史创建一个更清晰的、线性的提交历史,但它会改变提交ID并可能更复杂一些。总结
在这个情景中,Alice使用了
git fetch来安全地查看项目中的更新,审查了这些更改,并决定了最佳的方法来整合这些更新到她的工作中,无论是通过合并还是变基。这种方式使她能够保持对本地工作环境的完全控制,同时又能保持与远程仓库的同步。
_____________________+++++++++++++
当然可以。我们继续Alice的故事,这次她选择使用git rebase来整合更改。git rebase是另一种合并来自不同分支的更改的方法,但它通过在一系列提交之上重新应用更改来创建一种线性的提交历史。git merge会发生什么,主分支加入了其他分支的功能
让我通过一个示例来说明:
假设你有一个 Git 项目,其中有两个分支:
feature分支和main分支。你在feature分支上开发了一个新功能,并且做了一些提交,如下所示:(feature 分支) \ A - B - C / (main 分支) D - E - F- 1
- 2
- 3
- 4
- 5
- 6
- A、B、C 是你在
feature分支上做的提交。 - D、E、F 是
main分支上的提交。
现在,你希望将
feature分支的更改合并到main分支。你执行以下命令:git checkout main # 切换到 main 分支 git merge feature # 合并 feature 分支的更改到 main 分支- 1
- 2
合并成功后,Git 会创建一个新的合并提交,示意图如下:
(main 分支) D - E - F - G \ A' - B' - C' / (feature 分支) \ A - B - C- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- G 是合并提交,包含了
feature分支的更改。 - A’、B’、C’ 是新的提交,它们是在合并时自动生成的,代表了
feature分支的更改被合并到了main分支。
现在,
main分支包含了feature分支的新功能,你可以继续开发和部署你的项目。这就是git merge的基本工作原理和效果。合并操作将不同分支的更改整合到一起,以便统一管理和维护项目。步骤 6:使用
git rebase整合更改Alice已经用
git fetch获取了最新的远程仓库更改,现在她决定使用git rebase来整合这些更改。她选择rebase的原因是想保持提交历史的清晰性,因为rebase会重写提交历史,使得项目的历史看起来像是一条直线,而非merge产生的多线条状。假设Alice在
main分支上有一些还没推送的本地提交,而Bob的更改已经在远程的main分支。以下是Alice如何将这些远程更改重新应用到她的本地分支上的:首先,她需要确保她在正确的分支上并已经获取了最新的远程更改(这一步在前面的
git fetch中已完成):git checkout main- 1
现在,Alice使用
git rebase开始变基操作:git rebase origin/main- 1
这个命令的作用是:
- 暂停Alice的所有本地提交。
- 将
main分支指向与origin/main相同的提交。 - 依次将Alice暂停的提交应用在
main分支的顶端。
这个过程改变了提交历史的顺序和/或内容,使之看起来像是Alice等待Bob完成他的更改,然后才开始在最新版本的项目上工作。如果在此过程中遇到冲突,
git会暂停rebase并要求Alice解决这些冲突。解决后,她可以使用git rebase --continue来继续应用余下的提交。结果
完成后,项目的提交历史将呈现为线性不分叉的,即使实际上工作是并行进行的。这使得理解项目历史更加直观,因为它避免了由于合并造成的额外的“合并提交”。
Alice的工作目录现在也会反映出Bob的更改,同时她自己的更改也被重新应用了:
exampleproject/ (Alice's working directory) │ ├── README.md (updated) ├── file1.txt └── file2.txt (new)- 1
- 2
- 3
- 4
- 5
警告
尽管
git rebase有很多优点,比如保持提交历史的清晰,但它也有缺点。它改变了提交历史,这意味着如果在共享或团队协作的分支上使用rebase,其他协作者的历史记录与你的不同,这可能会导致混乱。通常,如果你的分支是共享的,那么合并通常是更安全的选择。
_____________________+++++++++++++
当然,我将通过一个更具体的场景来解释git rebase的工作原理及其对提交历史的影响。假设Alice和Bob都在
main分支上工作,并且仓库的提交历史原本看起来是这样的:A - B - C (origin/main & main) ↑ (Alice和Bob共同的起点)- 1
- 2
- 3
这里的每一个字母(A、B、C)都代表一个提交。
场景设置
- Alice在她的本地
main分支上做了一些工作,并且做了两个提交,形成了以下的提交历史:
A - B - C - D - E (main) ↑ (Alice的新提交)- 1
- 2
- 3
- 同时,Bob也在
main分支上做了一些更改,并且他先于Alice将这些更改推送到了远程仓库(origin),使远程的提交历史变成了:
A - B - C - F - G (origin/main) ↑ (Bob的新提交)- 1
- 2
- 3
- 现在,Alice决定将她的更改与远程仓库同步。她首先运行
git fetch来获取远程仓库的最新状态,但她还没有合并这些更改。
Rebase操作
Alice决定使用
git rebase来整合远程仓库中的更改。在她的本地仓库,她执行了以下命令:git rebase origin/main- 1
以下是
rebase过程中发生的事情:- Git暂时移除(“lifts”)Alice的提交(D和E)。
- Git把Alice当前的
main分支指向G,也就是origin/main的最新提交。 - Git尝试重新应用Alice的提交(D和E)到分支的顶端。
处理冲突
如果在这个过程中没有遇到冲突,Alice的提交历史将变为:
A - B - C - F - G - D' - E' (main)- 1
注意,我用D’和E’来表示这些提交是重新应用的,它们会有新的提交哈希值,尽管它们的内容与原先的提交相同。
如果出现冲突,例如Alice在提交D中更改的文件,Bob在提交F中也更改了,那么
git rebase将会在达到那个点时停止,并提示Alice解决冲突。Alice需要手动解决这些冲突,然后:git add . git rebase --continue- 1
- 2
这会让
rebase进程继续前进。结果
无论是否遇到冲突,完成之后,Alice的本地
main分支提交历史将呈现为一条没有分叉的直线,这意味着所有的更改都是按顺序发生的。尽管Alice和Bob实际上是并行工作,但通过使用rebase,Alice的提交历史看起来就像她在Bob完成他的更改之后才开始工作。这使得提交历史更加整洁,也更容易理解每个更改是如何建立在之前的更改之上的。不过,值得注意的是,因为
rebase改变了提交的哈希值(因为它们现在基于不同的父提交),所以在共享分支上使用rebase需要谨慎,因为这可能导致与其他团队成员的历史不一致。
_____________________+++++++++++++
git pull就是 git fetch后,自动git mergegit rebase 适用于保持线性历史和整合更改的情况,而 git merge 适用于保留分支历史和团队协作的情况。选择哪种合并方式取决于项目的需求和你希望如何管理提交历史。
11 分支和仓库

跟踪分支
跟踪分支,通常也被称为“上游分支”,是本地分支与远程分支之间的一个链接,这意味着你可以直接与你的本地仓库的远程分支进行交互。
如何工作:
当你克隆一个仓库,Git 会自动创建一个与远程的
main(或master)分支对应的本地分支,并创建一个跟踪关系。这意味着,当你执行诸如git pull或git push这样的命令时,Git 知道你想与哪个远程分支交互。为什么使用:
使用跟踪分支的好处包括:
- 简化了从远程获取更新或推送更改的流程。
- 提供了关于本地和远程分支之间差异的信息。
举例说明:
-
创建跟踪分支:假设你的同事在远程仓库中创建了一个新分支
feature-x,并且你想在本地上与之合作。你可能会这样做:git fetch origin # 更新你的远程分支列表 git checkout --track origin/feature-x # 创建一个新的本地分支,它会跟踪远程的 feature-x 分支- 1
- 2
这样,你就创建了一个名为
feature-x的本地分支,它自动“跟踪”远程的feature-x分支。这意味着当你使用git push或git pull时,Git 会知道这些操作是针对origin/feature-x。 -
检查状态:当你在你的跟踪分支上工作并想看看你的本地分支与远程分支之间有何差异时,你可以使用:
git status- 1
这可能会告诉你远程分支比你的本地分支多了几次提交,从而提醒你可能需要拉取这些更改。
-
获取更新:由于存在跟踪关系,如果你想更新你的本地分支,你只需做:
git pull- 1
这会自动从远程分支获取更改并合并到你的本地分支中,因为 Git 知道你的分支跟踪的是哪个远程分支。
通过这种方式,跟踪分支简化了与远程分支的交互,并帮助团队成员保持最新状态。
12 数据保护
-
定期备份:
- 使用GitLab内置的备份工具定期创建全站备份。这应包括仓库、数据库、配置文件等。
- 存储备份在不同的物理位置,并定期验证备份的完整性。
-
使用RAID存储:
- 如果使用物理服务器,可以设置RAID(冗余独立磁盘阵列)来提供数据冗余。如果一块硬盘失败,RAID配置将保护你免受数据丢失。
-
数据库复制:
- 如果使用的是高级设置,可以配置数据库复制。这意味着你有一个实时的数据库副本在另一台服务器上运行。
-
故障恢复计划:
- 准备详细的灾难恢复计划。在发生灾难性事件时,团队知道如何迅速行动以最大限度地减少数据丢失。
-
更新和补丁管理:
- 定期应用安全补丁和更新来减少安全漏洞,避免因安全问题导致的数据丢失。
-
访问控制:
- 设置合理的用户和访问权限,防止未经授权的更改。
-
监控系统健康状况:
- 使用系统监控工具来跟踪服务器的健康状况,预防可能的硬件故障。
Pull Requests(PR)或Merge Requests(MR)是什么?请举例说明
Pull Requests(PR)和 Merge Requests(MR)是版本控制协作中的关键概念,常用于多人开发的项目中。这些请求允许开发者通知团队成员他们对代码所作的更改,请求他人审查这些更改,并将它们合并到主分支。这两个术语在功能上非常相似,但它们是由不同的Git仓库托管服务使用的;GitHub使用“Pull Requests”,而GitLab使用“Merge Requests”。
以下是Pull Request或Merge Request的一般流程,以及它们是如何用于团队协作的:
-
创建分支:
开发者从主代码库(通常是main或master分支)创建一个新分支,在这个新分支上进行开发。这确保了主分支的稳定性,即使是在多人同时工作的情况下。 -
提交更改:
开发者在新分支上进行更改,这可能包括修复错误、添加新功能等。更改完成后,开发者会将这些更改提交到新分支,并将该分支推送到远程仓库(如GitHub或GitLab)。 -
发起Pull Request/Merge Request:
开发者在远程仓库上创建一个PR或MR。这实际上是一种请求,要求其他团队成员审查代码、提出反馈或建议,并最终将这个分支的更改合并到主分支。 -
代码审查和讨论:
团队其他成员(如同事、审查者或维护者)审查提交的代码,并在PR或MR的评论或讨论区提供反馈。开发者可以根据反馈继续改进代码。 -
合并或关闭:
- 如果代码审查成功,并且更改被接受,那么维护者或有权限的团队成员会合并这个请求,也就是将这个分支的更改合并到主分支。合并后的代码变更现在是项目代码的一部分。
- 如果代码有问题或者不需要合并,PR或MR可以被关闭,相关的更改也就不会合并到主分支。
通过Pull Requests或Merge Requests,整个团队能够更有效地协作,增强代码质量控制,并保持代码库的整洁和组织性。此流程提供了一个透明、可审计的变更管理机制,使所有团队成员都能看到什么时候、为什么以及如何进行代码更改。
12 CICD
- CI(持续集成)服务器就是Jenkins
webver是构建流水线的时候自己设置的名字。选

构建的时候选 Build with Parameters 就可以选择 tag是1.0还是2.0,还是origin/master也就是最新的呢

构建完成后,他就是1.0的版本或者2.0的版本或者其他

设置这个后,在Jenkins服务器上面拉下来的代码就不会都放在mysite下,会分别放在mysite-版本号 文件夹下

2) Jenkins把下载下来的代码打成tar包,生成md5值,分发给app服务器,进行md5值校验,确认解压的文件没问题
要分发,Jenkins服务器先要做成apache服务器,就是httpd

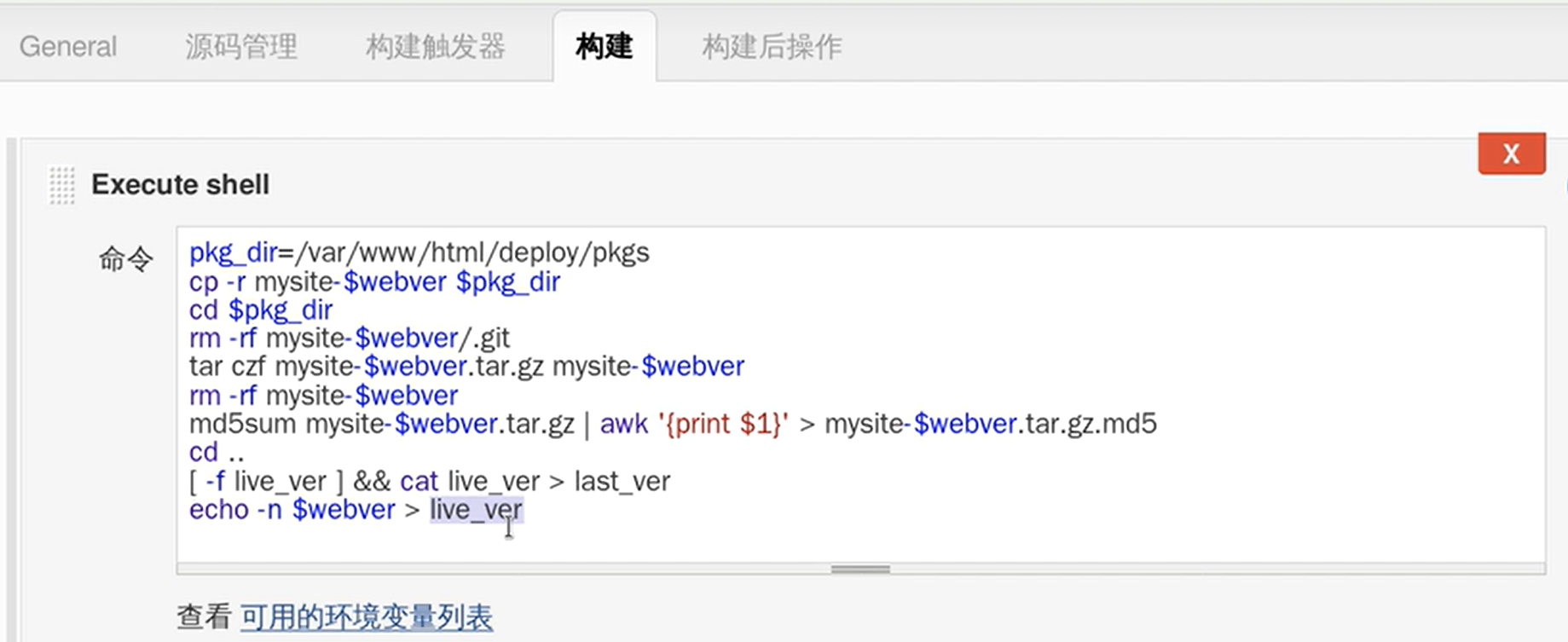
rm -rf .git是因为代码已经移走,版本库是没有用的
把md5值放到 点md5 文件里
echo -n 不要回车的意思,last_ver 是老版本的意思
安装好httpd后在网页输入 ip/deploy出现这个
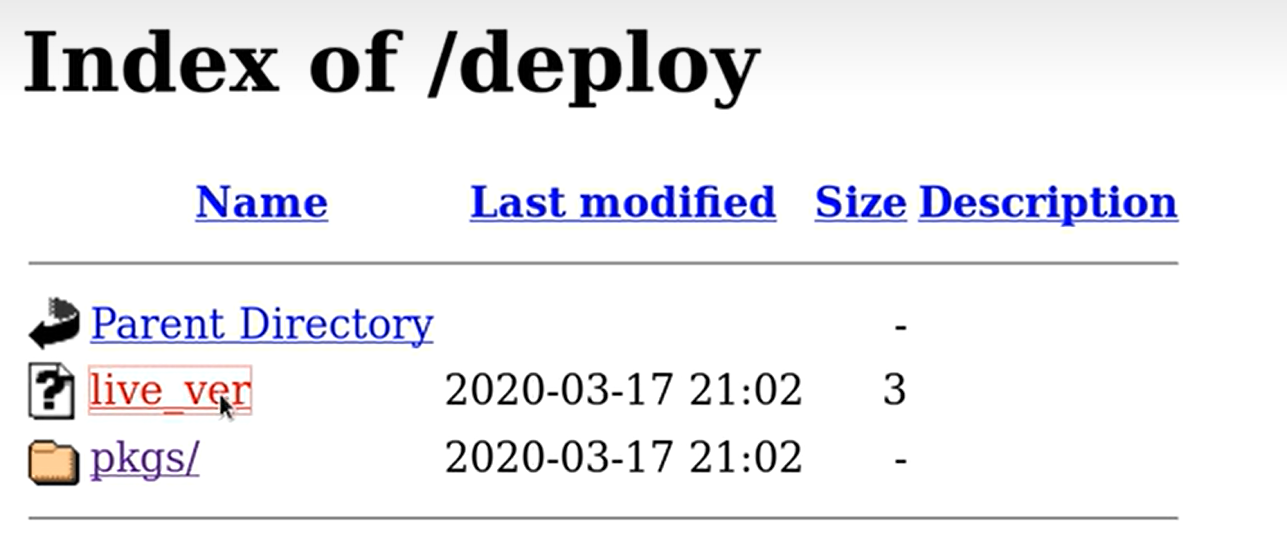
live_ver就是你构建后出现的文件夹app服务器
1)首先装httpd
2)# apache目录 cd /var/www/ # download存储压缩包,把压缩包解压到deploy,比如版本是1.0 mkdir download deploy # 创建 /var/www/html/current 软连接,指向需要部署的应用版本,指向哪个版本是哪个版本- 1
- 2
- 3
- 4
- 5
编写python脚本,手动在app服务器上运行python代码,部署新应用
import wget import requests import os import hashlib # 计算md5值用 import tarfile def has_new_ver(ver_fname, ver_url): '如果服务器上有新版本返回True,否则返回False' # 如果本地没有版本文件,则有新版本 if not os.path.exists(ver_fname): return True # 如果本地版本文件和服务器版本文件不一致,则有新版本 with open(ver_fname) as fobj: local_ver = fobj.read() r = requests.get(ver_url) if local_ver != r.text: return True else: return False def file_ok(fname, md5url): '如果文件未损坏,返回True,否则返回False' m = hashlib.md5() # 当读完,md5就算出来了 # 打开文件 fname 以二进制只读模式 with open(fname, 'rb') as fobj: while 1: # 读取文件中的 4096 字节数据存入 data 变量 data = fobj.read(4096) # 如果未读取到数据(即文件已经全部读取完毕),退出循环 if not data: break # 使用 m.update() 方法更新散列对象 m,传入读取的数据进行更新 m.update(data) r = requests.get(md5url) if m.hexdigest() == r.text.strip(): return True else: return False def deploy(app_fname, deploy_dir, dest): '用于部署软件到web服务器' # 使用 tarfile.open() 方法打开 tar 文件 app_fname tar = tarfile.open(app_fname) # 解压 tar 文件到指定目录 deploy_dir tar.extractall(path=deploy_dir) # 关闭 tar 文件 tar.close() # 拼接出解压后目录的绝对路径 app_dir = os.path.basename(app_fname) # 去除文件扩展名 .tar.gz app_dir = app_dir.replace('.tar.gz', '') app_dir = os.path.join(deploy_dir, app_dir) # 创建链接 # 由于无法覆盖软连接,就先删除 if os.path.exists(dest): os.remove(dest) os.symlink(app_dir, dest) if __name__ == '__main__': # 判断服务器上是否有新版本 ver_url = 'http://192.168.113.137/deploy/live_ver' ver_fname = '/var/www/deploy/live_ver' if not has_new_ver(ver_fname, ver_url): print('未发现新版本') exit(1) # 下载新版本 r = requests.get(ver_url) app_url = 'http://192.168.113.137/deploy/pkgs/mysite-%s.tar.gz' % r.text app_fname = '/var/www/download/mysite-%s.tar.gz' % r.text wget.download(app_url, app_fname) # 校验下载的软件包是否损坏,如果损坏则删除它 md5url = app_url + '.md5' if not file_ok(app_fname, md5url): print('文件已损坏') os.remove(app_fname) exit(2) # 部署软件 deploy_dir = '/var/www/depoy' dest = '/var/www/html/current' deploy(app_fname, deploy_dir, dest) # 更新本地版本文件 if os.path.exists(ver_fname): os.remove(ver_fname) wget.download(ver_url, ver_fname)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94

钉钉机器人发消息,还能设置在群里@某人Jenkinsfile
Jenkinsfile 是一个文本文件,它定义了 Jenkins 流水线的各个阶段和步骤。这个文件会被写入到项目的源代码仓库中,因此它可以被版本控制,与项目的其他源代码一起维护。
下面是一个 Jenkinsfile 的简单示例,演示了一个基本的流水线配置,该配置检出代码,执行构建命令并在成功时发送通知:
pipeline { agent any // 这个流水线可以在任何可用的代理(agent)上执行 stages { stage('Checkout') { // 第一阶段,通常是获取源代码 steps { // 从连接的版本控制系统检出代码 checkout scm } } stage('Build') { // 第二阶段,通常是构建应用 steps { // 运行构建命令 sh 'make' } } stage('Notify') { // 第三阶段,例如发送构建通知 steps { // 假设我们有一个 hypotheticalNotify 函数来发送通知 script { hypotheticalNotify('Build succeeded') } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这个 Jenkinsfile 定义了一个具有三个阶段的流水线:Checkout, Build, 和 Notify。每个阶段执行特定的任务,从检出代码,到运行构建,再到发送构建通知。
Jenkinsfile 的优势包括:
-
版本控制友好: Jenkinsfile 与项目源代码一起存储在版本控制系统(如 Git)中,这意味着流水线更改可以通过提交、拉取请求和代码审查等标准软件开发实践进行跟踪和管理。
-
代码复用与共享: 您可以在多个项目中重用流水线代码,或创建共享的库代码,这可以被不同的 Jenkinsfile 引用,从而保持一致性,并减少重复劳动。
-
自动化触发: 由于 Jenkinsfile 存储在项目中,因此可以设置自动触发器(如代码提交或拉取请求),这些触发器会自动启动流水线构建,实现持续集成/持续部署(CI/CD)。
-
易于审查和协作: 因为流水线定义以代码形式存在,团队成员可以通过代码审查过程对流水线更改提供反馈,就像他们对应用程序代码所做的那样。
-
环境一致性: Jenkinsfile 允许您明确定义构建、测试和部署的环境,这有助于在不同的环境(例如,不同开发人员的机器)之间保持一致性。
通过使用 Jenkinsfile,团队能够以更协作的方式管理 CI/CD 流程,同时确保流水线的健壮性和一致性,无论是在单个项目还是跨多个项目中。
13 gitlab各个角色
在group中如何定义好了Alice是主程序员,那么当project选择group作为管理的时候,Alice自动是主程序员
在GitLab中,访客、报告者、开发人员、主程序员以及所有者是项目成员的角色或权限级别,每个角色都有其特定的权限,允许用户根据其责任执行不同的操作。以下是每个角色的主要权限和例子:-
访客(Guest):
- 权限:最基本的权限,通常只能查看项目和下载源代码。
- 例子:一个访客可能需要查看项目的文件和目录,但他们不能做出任何改变或提出合并请求。
-
报告者(Reporter):
- 权限:除了访客的权限外,还能创建问题(issues)和评论,但无法推送代码更改。
- 例子:当一个用户发现一个bug或想提出一个功能请求时,作为报告者,他们可以在项目中打开一个新的问题。
-
开发人员(Developer):
- 权限:拥有更高级的权限,包括创建合并请求和推送分支,但通常不能直接推送到受保护的分支。
- 例子:开发人员可以在自己的分支上开发新功能或修复bug,并创建一个合并请求,请求将这些更改合并到主分支。
-
主程序员(Maintainer):
- 权限:几乎可以进行所有项目管理的操作,包括推送到受保护的分支、管理项目设置和访问权限等。
- 例子:当项目需要与另一个服务集成时,主程序员可以修改项目设置来添加必要的集成。此外,他们还可以审查和合并其他成员的合并请求。
-
所有者(Owner):
- 权限:具有对项目的完全控制权,包括删除项目和转让项目所有权的能力。具有所有权限
- 例子:如果项目需要转移到新的组织或需要添加更多的维护者,所有者有权限做出这些更改。他们也负责处理敏感的操作,如更改项目可见性或删除项目。
以上各级权限在实际操作中的使用,可能会根据组织的具体政策和项目的需求有所不同。通常,团队成员会根据他们在项目中的职责和所需的访问级别来分配适当的角色。
14 移动mysql
# 在要备份的mysql里面取出来 docker exec 193c /usr/bin/mysqldump -u root --password=123456 soccer > backup.sql- 1
- 2
# 在另一台服务器上 docker run -itd --name mysqlSoccer -p 3336:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0 还手动创建了schema docker exec -i 7b89 /usr/bin/mysql -u root --password=123456 soccer < backup.sql- 1
- 2
- 3
- 4
Jenkins new 节点
需要在目标机器上命令行安装java,ssh knows那个hosts好像也得弄一下,是自定义Jenkins的目录,我记不清了
注意标签pipeline { agent none // 不在主节点上执行任何步骤 stages { stage('Stop and Remove Container') { agent { label 'mysqlAndBackend224' // 使用标签指定远程agent,标签应该与您的远程agent相匹配 } steps { sh "docker stop my-flask_container || true && docker rm my-flask_container || true" } } stage('Checkout') { agent { label 'mysqlAndBackend224' } steps { checkout scm } } stage('Build Docker Image') { agent { label 'mysqlAndBackend224' } steps { sh "docker build -t my-flask ." } } stage('Run Docker Container') { agent { label 'mysqlAndBackend224' } steps { sh "docker run -d -p 3337:3000 --name my-flask_container my-flask" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
-
-
相关阅读:
[CSS案例二]—实现一个响应式网页,兼容PC移动端,ScrollReveal 增加动画
Java 面向对象进阶(一)
ST表(转载自其它博主)
echarts统计图表
美容院开业活动方案
【力扣】矩阵中的最长递增路径
主流商业智能(BI)工具的比较(二):Power BI与Domo
【Redux】Redux 基本使用
机器学习实战:基于sklearn的工业蒸汽量预测
Delay Penalty for RNN-T and CTC
- 原文地址:https://blog.csdn.net/qq_41834780/article/details/134040654
