-
ES性能优化最佳实践- 检索性能提升30倍!
Elasticsearch是被广泛使用的搜索引擎技术,它的应用领域远不止搜索引擎,还包括日志分析、实时数据监控、内容推荐、电子商务平台、企业级搜索解决方案以及许多其他领域。其强大的全文搜索、实时索引、分布式性能和丰富的插件生态系统使其成为了许多不同行业和领域的首选技术。虽然Elasticsearch是一款强大的搜索引擎技术,但在超大规模数据检索中,尤其是在处理大量检索关键词(150个以上)、对多个字段执行检索并使用脚本排序时,可能会面临严重的性能问题。在我们实际的业务中,检索的时间可能到达300秒,无法满足实时交互需求。本文带你打开一个新思路。在 千亿级数据检索背景下,在 未添加任何资源的情况下,我把性能提升了 30倍,请求时间控制在 10s内。多数请求能在3秒5秒内完成。一起来看看我是如何做到的叭。前言:检索性能问题
-
复杂性查询的挑战:当涉及大量检索关键词和多字段检索时,查询变得复杂,需要更多计算资源来处理这些复杂的查询。这会导致性能下降。
-
脚本排序开销:使用脚本排序可以在排序时进行自定义计算,但脚本的执行会增加额外的计算负担,尤其在大规模数据集上。
-
分片和节点负载:Elasticsearch分布式架构依赖于分片和节点,如果查询请求分布不均匀或某些节点负载过重,性能问题可能会显著增加。
-
内存和磁盘资源:大规模查询需要更多的内存和磁盘资源来存储索引和数据,因此,硬件资源的配置可能成为性能瓶颈。
一、综合排序检索性能提升
1.1 性能提升效果
优化前后响应时间如下图1所示

图1
1.1.1 性能对比说明
- 其中横轴为普通检索场景,由检索时间范围和检索关键词个数组成。纵轴是请求平均响应时间,单位为秒。
- 在坐标轴上,红色代表的是性能优化前的请求响应时间,绿色代表的是优化后的请求响应时间。黑色虚线代表的是目标线,目标为,单次请求在5s内。
1.1.2 响应时间影响因素:
- 检索资源越多(服务器),响应时间越短。
- 检索时间范围越大(一次检索数据越多),响应时间越长。目前支持最大的检索时间跨度为3个月。
- 检索关键词越多,响应时间越长。目前能够给业务开放支持的是 100个检索词。
1.1.3 优化后效果
- 整体性能提升效果明显,提升在 1~ 30倍。
- 其中对于慢查询提升效果更好。对于检索时间范围越长,效果提升越好;对于检索关键词越多,效果提升越好。
- 最终的检索效果,检索关键词小于等于50个,响应时间可以控制在5s内,能够达到目标。其中只有检索时间跨度到3个月,检索关键词100无法达到5s内,目前是7s。
1.3 测试数据说明
性能提升前后测试数据如下图2:
- 测试对比数据由测试组同事提供。
- 测试接口为服务总线生产环境,检索逻辑为实际的业务检索条件。响应时间略大于ES的响应时间。其中有0.3~0.5花在网络传输上。
- 其中提升前,是指综合排序,使用脚本实现,是闻海2.0实现思路。提升后是指使用cutting off机制,对搜索进行优化。
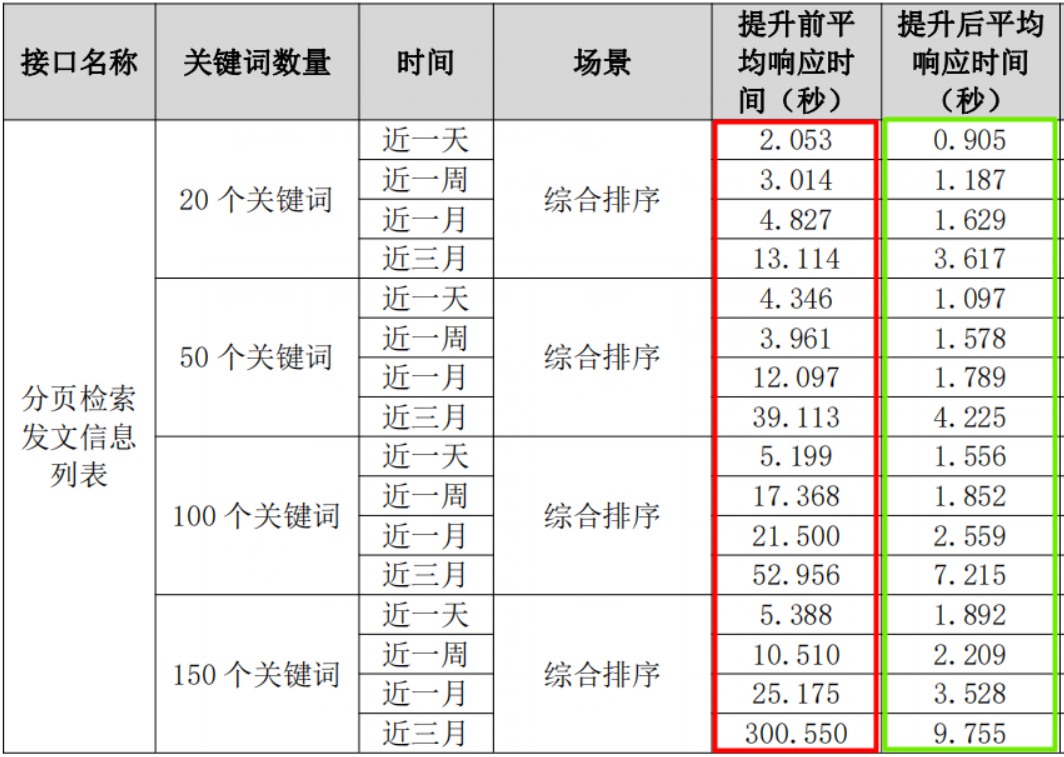
图2
1.4 关于综合排序说明
综合排序,是业务上使用最频繁的一种数据排序方式,也是默认的排序方式。其可以结合多个字段以及ES的BM25相关性分数,做一个综合的排序。在实现上,使用script提取每一条数据的N个字段,然后计算一个分数,并和ES的相关性分数做融合。
其最大的优点是召回的数据质量好,可以满足相关性的排序效果。
其最大的缺点是单次检索,有非常大的计算量,需要花费大量的资源。单个检索随着命中的数据变多,检索的时间复杂度增加,响应时间增加。使用script,需要对命中的所有数据做实时计算,计算过程需要将所需要的字段IO出来,会产生大量小文件的IO。由于每一条数据都需要做计算,索引,会占用大量的CPU资源,最终导致整体检索效果慢N倍,N>5。且随着关键词命中的结果集合增大,额外的IO和CPU计算导致检索性能越来越差。50个检索词在三个月中,耗时39s。150个词在三个月数据中检索时间300s。
1.5 优化说明
1.5.1上述综合排序中的问题,归结为两点。
- 有脚本的存在,且需要实时计算。ES中脚本排序是一种低性能的检索方式。
- 单次检索需要扫描全量的数据,且要对命中的数据做计算。单次检索复杂度高。其中最大检索时间跨度下,全部数据约450亿数据。最大检索关键词数下,100个检索关键词OR的逻辑,能够命中上亿的数据。
1.5.2 针对问题,提出解决方案:
- 分数预处理机制:对于多个要参与排序的字段分数,可以提前计算好,用一个额外的字段承接此分数。此操作可避免实时计算,从IO多个字段,变为IO 一个字段。如下图所示,在数据处理层,在数据入ES前,通过对数据的预处理,计算文档的质量分数。利用ES的插入排序能力,将高质量的文档在插入的时候放在最前边检索。

- 避免扫描全量数据。利用数据写入排序,可以做到将高质量数据在存储上总是排在前边,优先被检索到。在数据根据质量有序以后,则请求可以做截断。优先遍历高质量数据,找到topK的满足条件的数据,此时分数也是最高的,达到召回条件后,则提前终止请求。

-
-
相关阅读:
QT移植腾讯云C-SDK结合实现OTA更新
NetFlow Analyzer-网络检测和响应
Linux——文件权限属性和权限管理
[2023年]-hadoop面试真题(三)
mysql的存储过程
MySql安装包配置
毕业设计选题uniapp+springboot新闻资讯小程序源码 开题 lw 调试
【图论C++】链式前向星(图(树)的存储)
Netty面试经典问题
多维时序 | MATLAB实现ELM极限学习机多维时序预测(股票价格预测)
- 原文地址:https://blog.csdn.net/star1210644725/article/details/134063852