-
数据库连接池
一. 引入
数据库连接是一个相对麻烦的过程,如果获取一个数据库连接,使用一次以后就给它关闭了下一次再去使用的时候就要重新创建一个新的数据库连接。
所以使用了池化思想,将数据库连接对象(Connection)放入数据库连接池,
在使用数据库连接时就不用再去重新创建数据库连接,而是直接从池中获取;
使用完的数据库连接,也不是直接销毁,而是要放回到连接池;总结来说,为什么有数据库连接池的原因:
- 创建和销毁连接会有较大的系统开销;
- 创建和销毁连接所消耗的时间较长;
- 防止大量用户并发访问数据库服务器;
二. 简介
数据库连接池(Connection pooling)是程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态地对池中的连接进行申请,使用,释放。
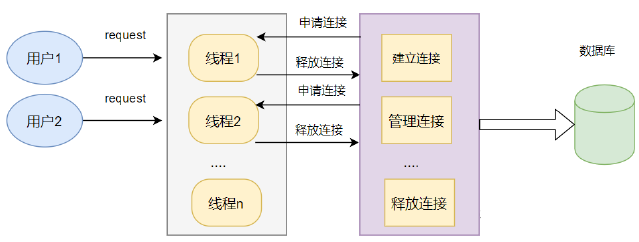
数据库连接池的作用:
- 连接可以被重复利用,减小系统开销;
- 不用临时创建连接,提升了响应速度;
- 统一管理连接,避免数据库连接泄露;
三. 运行机制
- 初始化连接池时,会创建一定数量的连接并存放在连接池,被称为“闲置连接”;
- 当Java程序需要连接时,先判断是否有闲置连接,如果有闲置连接则分配给应用程序;
如果没有闲置连接,则判断连接数量是否达到最大连接数,如果未达到则会创建新的连接供Java程序使用;如果打到看最大连接数则不能创建新的连接,那么会判断是否等待超时,如果没有则需要连接池的连接归还后才能使用连接; - 如果等待超时了,则采取多种方式处理:抛出异常、将连接池中使用最久的连接归还以供当前Java程序使用等;
四. 常见的数据库连接池
- DBCP 是Apache提供的数据库连接池,速度相对c3p0较快,但因自身存在BUG,Hibernate3已不再提供支持
- C3P0 是一个开源组织提供的一个数据库连接池,速度相对较慢,稳定性还可以
- Proxool 是sourceforge下的一个开源项目数据库连接池,有监控连接池状态的功能,稳定性较c3p0差一点
- HikariCP 俗称光连接池,是目前速度最快的连接池
- Druid 是阿里提供的数据库连接池,据说是集DBCP 、C3P0 、Proxool 优点于一身的数据库连接池;
五. Druid 示例
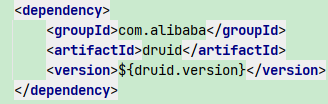
1. 在pom.xml文件中导入Druid的依赖以此导入jar包
2. 在项目的 resources 目录创建一个配置文件,写上连接池和数据源的相关参数;
例如:#驱动类的全限定名 driverClassName=com.mysql.jdbc.Driver #要连接的数据库的URL url=jdbc:mysql://localhost:3306/test? #用户名 username=MySQL用户名 #密码 password=MySQL密码 #初始化连接数 initialSize=5 #最大活动连接数 maxActive=10 #最大等待时间:毫秒 maxWait=1000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3. 代码实现
package com.fm; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.InputStream; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.util.Properties; public class DruidTest01 { public static void main(String[] args) throws Exception { //1. 创建一个 Properties对象,让其去读取 datasource.properties文件 Properties properties = new Properties(); //将 datasource.properties 配置文件转成字节输入流 InputStream resourceAsStream = DruidTest01.class.getClassLoader().getResourceAsStream("datasource.properties"); // 使用properties对象加载流 properties.load(resourceAsStream); //使用DruidDataSourceFactory创建Druid连接池对象 ★ DataSource dataSource = DruidDataSourceFactory.createDataSource(properties); // 使用连接池对象获取连接 Connection connection01 = dataSource.getConnection(); //创建执行SQL语句对象 Statement statement = connection01.createStatement(); //SQL语句 String sql = "select * from user where id = 1"; //执行SQL语句 ResultSet resultSet = statement.executeQuery(sql); while (resultSet.next()) { System.out.println(resultSet.getInt("id")); System.out.println(resultSet.getString("username")); // System.out.println("resultSet.getArray"); } //归还连接到连接池 connection01.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
当超出最大连接数时,会发生什么?
假设连接数量已经达到我们设置的最大连接数10,
当我们再次获取连接时,连接池已经没有连接了,
连接池会根据配置文件里的最大等待时间:maxWait=1000,等待一秒;
一秒后还没有获取到连接就会抛出异常 ! -
相关阅读:
VueX简单又详细的解读,看了就会用
用 TensorFlow API:tf.keras 搭建网络八股
鸿蒙开发组件:【FA模型的Context】
搭建游戏要选什么样的服务器?
MySQL创建表的时候建立联合索引的方法
DRF版本控制(源码分析)
自适应,响应式以及图片的性能优化(响应式图片)
Ubuntu20.04 安装 Matlab R2021a
着巨大风险!力荐这套「软件安装和环境配置手册」,看了直呼NB
Java进阶学习路线图
- 原文地址:https://blog.csdn.net/Swofford/article/details/134042243
