-
GPT的前世今生:从gpt1到chatgpt的能力提升
从2017年google brain提出transformer模型,到2018年基于transformer模型open ai推出了gpt1模型以及google推出了bert模型,到2019-2021年open ai陆续推出gpt2和gpt3,再到2022-2023年推出chat-gpt和gpt4,大语言模型已经发展成了一个具有3个大分支的参天大树[LLM:大语言模型]。在这里主要写写关于gpt的那些事。
GPT发展路径
GPT-1到GPT-3到ChatGPT
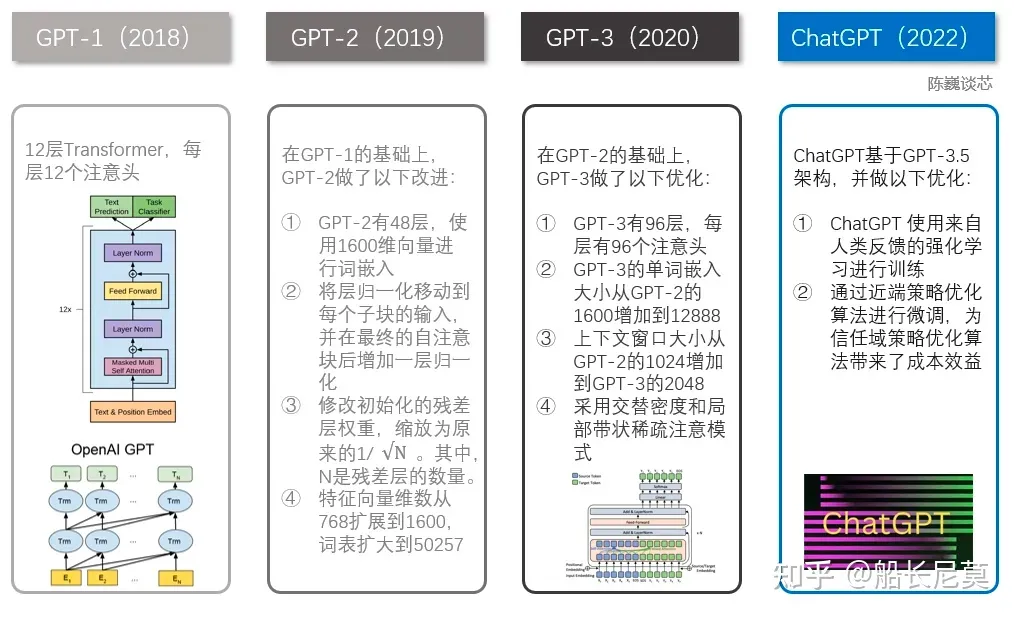
各GPT的技术路线:
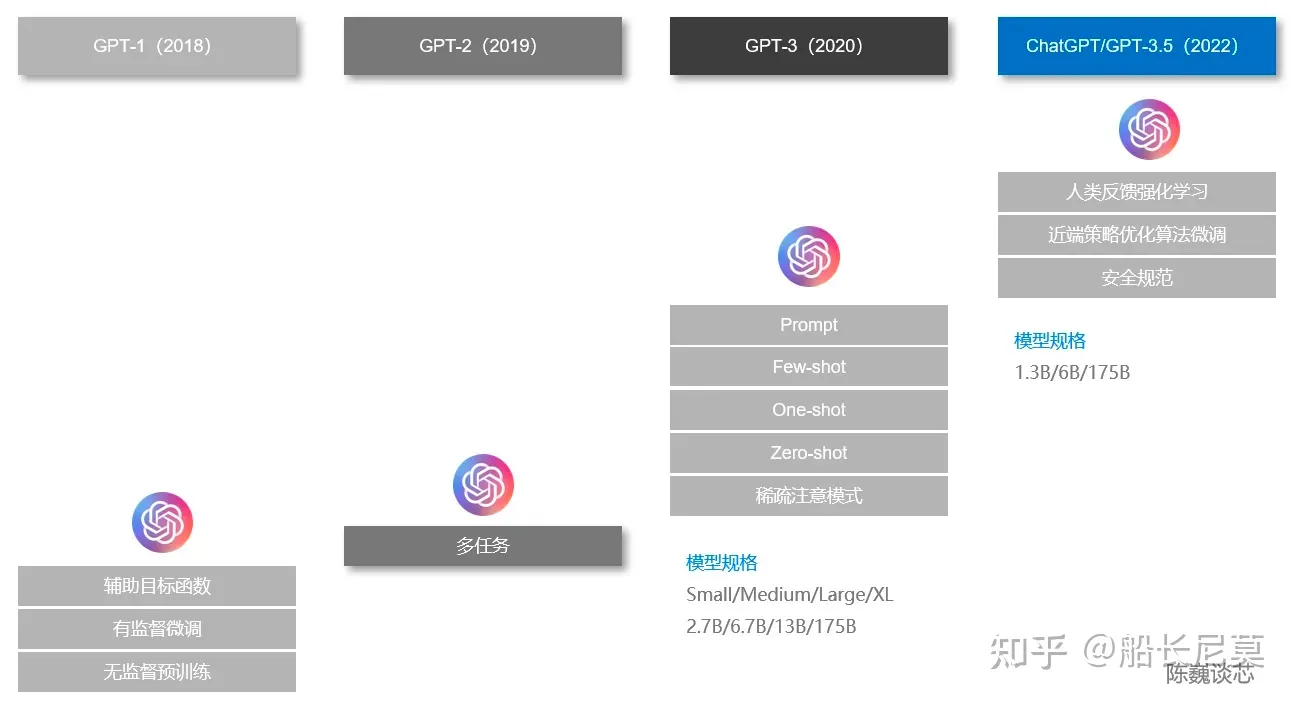
各GPT的模型大小:
模型 发布时间 参数量 预训练数据量 GPT 2018 年 6 月 1.17 亿 约 5GB GPT-2 2019 年 2 月 15 亿 40GB GPT-3 2020 年 5 月 1,750 亿 45TB GPT-3.5 的进化树:
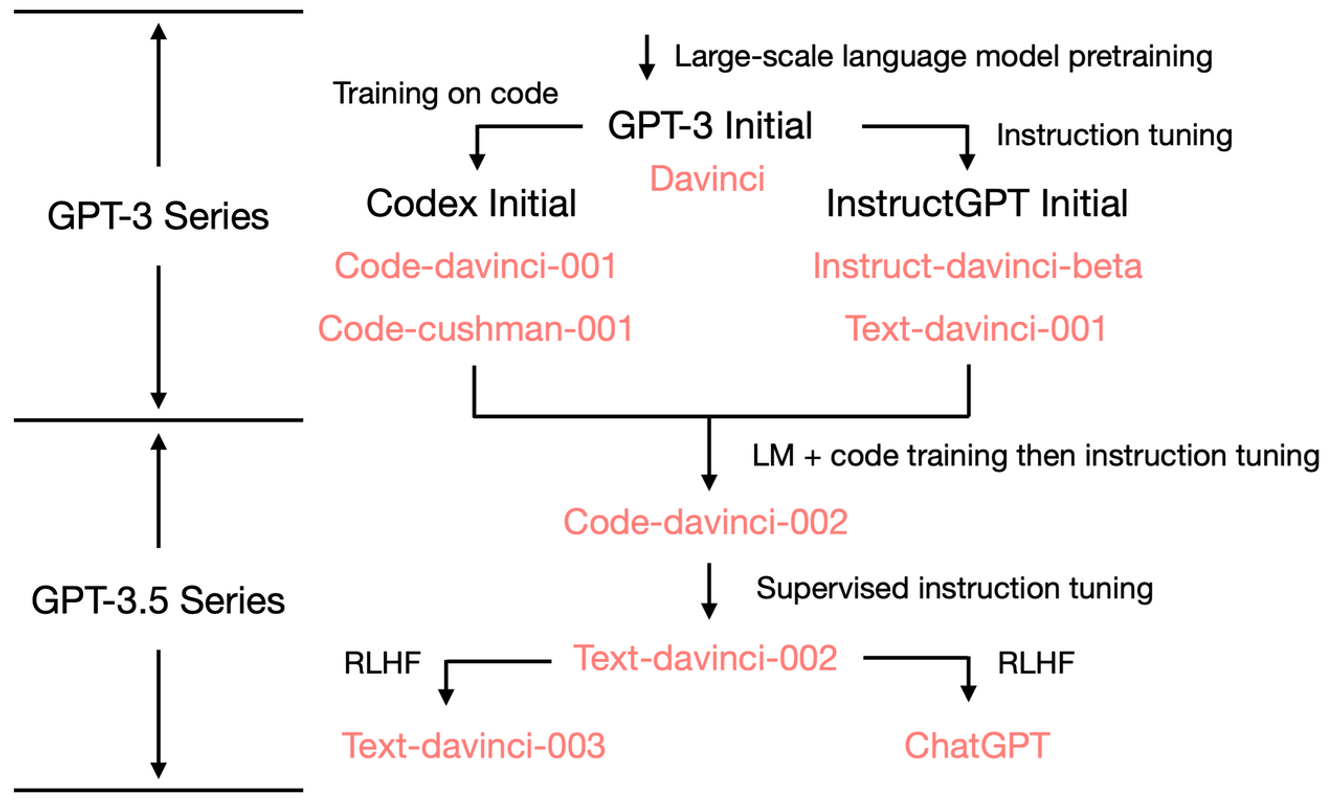
Note: 图中的几个概念:
1 Instruction tuning 有两个版本,一个是 supervised tuning,另一个是 reinforcement learning from human feedback (RLHF).
2 supervised instruction tuning 使用自然语言作为任务描述,而supervised fine tuning 使用固定格式或标签作为任务描述。supervised instruction tuning 的数据集包含指令、输入和输出三个部分,而supervised fine tuning 的数据集只包含输入和输出两个部分。
GPT-1、GPT-2和GPT-3模型
codex:code-davinci-002
[论文:Evaluating Large Language Models Trained on Code]
InstructGPT
参考[InstructionGPT]
[论文:Training language models to follow instructions with human feedback]
ChatGPT
ChatGPT的博客中讲到ChatGPT和InstructGPT的训练方式相同,不同点仅仅是它们采集数据上有所不同,但是并没有更多的资料来讲数据采集上有哪些细节上的不同。
考虑到ChatGPT仅仅被用在对话领域,猜测ChatGPT在数据采集上有两个不同:1. 提高了对话类任务的占比;2. 将提示的方式转换Q&A的方式。
关于多轮对话
微调模型如 standard_alpaca,或者alpaca-lora,这些都是单轮的对话。对于多轮对话的模型,我们该怎么去组织数据呢?
1 进行对话推理的时候,历史信息的处理和训练的时候是类似的,维护一个列表叫做history。操作起来的时候,就是将历史信息分别按照User和Assistant的角色拼起来,再镶嵌到模板里面,第一轮对话的时候,这个history是个空列表。[Chinese-Vicuna中的对话数据处理方式 - 知乎]
2 ChatGPT也可以使用记忆网络(MemoryNetwork)等技术对对话历史进行编码和表示,然后使用生成模型或分类模型等方法进行回复生成。
GPT-4
GPT-4(Generative Pre-trained Transformer 4)是 OpenAI 2023年发布的GPT 系列模型 [GPT-4 Technical Report]。它是一个大规模的多模态模型,可以接受图像和文本输入,产生文本输出。输出任务依旧是一个自回归的单词预测任务。
GPT-4的主要改进和性能提升表现在以下几个方面:
1 训练稳定性和预测性能
GPT-4 的开发经历了全面重建深度学习堆栈的过程,并与 Azure 共同设计了专门为其工作负载而优化的超级计算机。通过将 GPT-3.5 视为系统的首次“试运行”,OpenAI 发现并修复了一些错误,改进了理论基础。这使得 GPT-4 的训练运行非常稳定,并成为他们首个能够准确预测训练性能的大型模型。OpenAI 还计划持续专注于可靠的扩展,以进一步提高预测能力,为未来的应用做好准备。2 模型性能
GPT-4 在许多专业和学术基准测试中展现出了显著的性能提升。举例来说,GPT-4 在模拟律师资格考试中的成绩超过了90%的考生,而 GPT-3.5 仅在后10%范围内。这表明 GPT-4 在解决复杂问题、创造性写作等方面具备更高的可靠性和灵活性。3 多模态能力
一个关键的改进是 GPT-4 的多模态能力,即接受图像和文本输入,能够结合图像和文本信息生成更丰富的输出,具有在图像理解、图像分类和问题回答等方面的能力。4 安全性和可控性
通过引入对齐方案和加入额外的安全奖励信号,提高了模型的安全性能。此外,OpenAI 还邀请了多位专家对模型进行对抗测试,以发现并修复潜在的安全问题,减少了生成有害内容的风险。5 模型架构和训练方法
GPT-4 的架构与之前的 GPT 模型相似,采用了 Transformer 的结构。预训练阶段使用了公开可用的互联网数据和第三方提供的数据,并且在微调阶段应用了RLHF来微调。6 引入了可预测的拓展
GPT-4 引入了一个可预测扩展的深度学习栈,该栈能够在不同的规模下表现出可预测的行为。通过开发基础设施和优化方法,团队能够在小规模模型上进行实验,并准确地预测在大规模模型上的性能,提高了工作效率和模型性能。WebGPT
WebGPT 论文发表于2021年12月,让 GPT 调用了搜索引擎。
[WebGPT: Improving the factual accuracy of language models through web browsing]
ChatGPT能力溯源
ChatGPT 是怎么变得这么强的?它强大的涌现能力(Emergent Ability)到底从何而来?
Note: 很多能力小模型没有,只有当模型大到一定的量级之后才会出现的能力称为Emergent Abilities。
OpenAI有一个独特的先发优势,它在2020年就开放了GPT-3的接口,因此收集了大量的真实用户提问。可以预见,随着ChatGPT的商业化,OpenAI会逐步形成自己的数据生态循环。
初代 GPT-3(davinci)
初代 GPT-3(在 OpenAI API 中被称为davinci) [GPT-3]。一方面,它合理地回应了某些特定的查询,并在许多数据集中达到了还不错的性能;另一方面,它在许多任务上的表现还不如 T5 这样的小模型,它的能力与当今的标准也形成了尖锐的对比。虽然初代的 GPT-3 可能表面上看起来很弱,但后来的实验证明,初代 GPT-3 有着非常强的潜力。这些潜力后来被代码训练、指令微调 (instruction tuning) 和基于人类反馈的强化学习 (reinforcement learning with human feedback, RLHF) 解锁,最终展示出极为强大的涌现能力。
初代GPT-3三个重要能力
- 语言生成:遵循提示词(prompt),然后生成补全提示词的句子 (completion)
- 能力来自于语言建模的训练目标 (language modeling)。
- 世界知识 (world knowledge):包括事实性知识 (factual knowledge) 和常识 (commonsense)
- 世界知识来自 3000 亿单词的训练语料库。模型的 1750 亿参数是为了存储知识,Liang et al. (2022) 的文章进一步证明了这一点。 他们的结论是,知识密集型任务的性能与模型大小息息相关。
- 上下文学习 (in-context learning): 遵循给定任务的几个类似的示例,然后为新的测试用例生成解决方案。上下文学习才是 GPT-3的真正重点
- 能力来源及为什么上下文学习可以泛化仍然难以溯源。直觉上,这种能力可能来自于同一个任务的数据点在训练时按顺序排列在同一个 batch 中。然而,很少有人研究为什么语言模型预训练会促使上下文学习,以及为什么上下文学习的行为与fine-tuning)如此不同。
Codex:code-davinci-002
初始的 Codex 是根据(可能是内部的,数据可能使用C4 的 2019-2021 版本)120 亿参数的 GPT-3 变体进行微调的,后来这个 120 亿参数的模型演变成 OpenAI API 中的code-cushman-001。
在 2022 年 4 月至 7 月的,OpenAI 开始对code-davinci-002模型进行 Beta 测试,也称其为 Codex。Code-davinci-002 可能是第一个深度融合了代码训练和指令微调的模型。
尽管 Codex 听着像是一个只管代码的模型,但code-davinci-002可能是最强大的针对自然语言的GPT-3.5 变体(优于 text-davinci-002和 -003)。
text-davinci-002
2022 年 5-6 月发布的text-davinci-002是一个基于code-davinci-002的有监督指令微调 (supervised instruction tuned) 模型,在以下数据上作了微调:(一)人工标注的指令和期待的输出;(二)由人工标注者选择的模型输出。
在code-davinci-002上面进行指令微调很可能降低了模型的上下文学习能力,但是增强了模型的零样本能力。- 当有上下文示例 (in-context example) 的时候, Code-davinci-002 更擅长上下文学习;当没有上下文示例 / 零样本的时候, text-davinci-002 在零样本任务完成方面表现更好。从这个意义上说,text-davinci-002 更符合人类的期待(因为对一个任务写上下文示例可能会比较麻烦)。- OpenAI 不太可能故意牺牲了上下文学习的能力换取零样本能力 —— 上下文学习能力的降低更多是指令学习的一个副作用,OpenAI 管这叫对齐税。
第一版GPT3.5 模型的能力
code-davinci-002和text-davinci-002,这两兄弟是第一版的 GPT3.5 模型,一个用于代码,另一个用于文本。它们表现出了四种与初代 GPT-3 不同的重要能力:- 响应人类指令:以前GPT-3 的输出主要是训练集中常见的句子。现在的模型会针对指令 / 提示词生成更合理的答案(而不是相关但无用的句子)。
- 能够响应人类指令的能力是指令微调的直接产物。
- 泛化到没有见过的任务: 这种能力对于上线部署至关重要,因为用户总会提新的问题,模型得答得出来才行。
- 当用于调整模型的指令数量超过一定的规模时,模型就可以自动在从没见过的新指令上也能生成有效的回答[T0、Flan 和 FlanPaLM 论文]。
- 代码生成和代码理解:这个能力很显然,因为模型用代码训练过。
- 利用思维链 (chain-of-thought) 进行复杂推理:思维链推理之所以重要,是因为思维链可能是解锁涌现能力和超越缩放法则 (scaling laws) 的关键。[A Closer Look at Large Language Models Emergent Abilities]
- 使用思维链进行复杂推理的能力很可能是代码训练的一个神奇的副产物,且代码数据量足够大(例如PaLM 有 5% 的代码训练数据)。
- - 初代 GPT-3 没有接受过代码训练,它不能做思维链(能力很弱甚至没有),而code-davinci-002 和 text-davinci-002 是两个拥有足够强的思维链推理能力的模型。
- - text-davinci-001 模型虽然经过了指令微调,但思维链推理的能力非常弱,所以指令微调可能不是思维链存在的原因。区分代码训练和指令微调效果的最好方法可能是比较 code-cushman-001、T5 和 FlanT5。
- - 面向过程的编程 (procedure-oriented programming) 跟人类逐步解决任务的过程很类似,面向对象编程 (object-oriented programming) 跟人类将复杂任务分解为多个简单任务的过程很类似。
- - 没有非常确凿的证据证明代码就是思维链和复杂推理的原因。
- 代码训练另一个可能的副产品是长距离依赖,正如Peter Liu所指出:“语言中的下个词语预测通常是非常局部的,而代码通常需要更长的依赖关系来做一些事情,比如前后括号的匹配或引用远处的函数定义”。这里我想进一步补充的是:由于面向对象编程中的类继承,代码也可能有助于模型建立编码层次结构的能力。
- 使用思维链进行复杂推理的能力很可能是代码训练的一个神奇的副产物,且代码数据量足够大(例如PaLM 有 5% 的代码训练数据)。
text-davinci-003
text-davinci-003和 ChatGPT,它们都在 2022 年 11 月发布,是使用的基于人类反馈的强化学习的版本指令微调 模型的两种不同变体。
text-davinci-003 恢复了(但仍然比code-davinci-002差)一些在text-davinci-002 中丢失的部分上下文学习能力(大概是因为它在微调的时候混入了语言建模) 并进一步改进了零样本能力(得益于RLHF)。
ChatGPT
ChatGPT 似乎牺牲了几乎所有的上下文学习的能力来换取建模对话历史的能力(即chatgpt不需要你给这个任务{对话}示例,我只在乎当前对话历史说过什么即可)。
关于指令微调
完成
code-davinci-002时,所有的能力都已经存在了。很可能后续的指令微调,无论是通过有监督指令微调还是RLHF,都会做以下事情:- 指令微调不会为模型注入新的能力 —— 作用是解锁 / 激发这些能力。这主要是因为指令微调的数据量77K比预训练数据量少几个数量级(基础的能力是通过预训练注入的)。其他指令微调论文如 Chung et al. (2022) Flan-PaLM 的指令微调仅为预训练计算的 0.4%。
- 指令微调将 GPT-3.5 的分化到不同的技能树。有些更擅长上下文学习,如
text-davinci-003,有些更擅长对话,如ChatGPT。 - 指令微调通过牺牲性能换取与人类的对齐(alignment)。 OpenAI 的作者在他们的指令微调论文中称其为 “对齐税” (alignment tax)。许多论文都报道了
code-davinci-002在基准测试中实现了最佳性能(但模型不一定符合人类期望),进行指令微调后模型可以生成更加符合人类期待的反馈(或者说模型与人类对齐),例如:零样本问答、生成安全和公正的对话回复、拒绝超出模型它知识范围的问题。
关于RLHF
通过对比text-davinci-002和text-davinci-003/ChatGPT,可知大多数新模型的行为都是 RLHF 的产物。
RLHF 的作用是触发 / 解锁涌现能力:
- 翔实的回应: text-davinci-003 的生成通常比 text-davinci-002长。 ChatGPT 的回应则更加冗长,以至于用户必须明确要求“用一句话回答我”,才能得到更加简洁的回答。这是 RLHF 的直接产物。
- 公正的回应:ChatGPT 通常对涉及多个实体利益的事件(例如政治事件)给出非常平衡的回答。这也是RLHF的产物。
- 拒绝不当问题:这是内容过滤器和由 RLHF 触发的模型自身能力的结合,过滤器过滤掉一部分,然后模型再拒绝一部分。
- 拒绝其知识范围之外的问题:例如,拒绝在2021 年 6 月之后发生的新事件(因为它没在这之后的数据上训练过)。这是 RLHF 最神奇的部分,因为它使模型能够隐式地区分哪些问题在其知识范围内,哪些问题不在其知识范围内。
总结
- 语言生成能力 + 基础世界知识 + 上下文学习都是来自于预训练(
davinci) - 存储大量知识的能力来自 1750 亿的参数量。
- 遵循指令和泛化到新任务的能力来自于扩大指令学习中指令的数量(
Davinci-instruct-beta) - 执行复杂推理的能力很可能来自于代码训练(
code-davinci-002) - 生成中立、客观的能力、安全和翔实的答案来自与人类的对齐。具体来说:
- 如果是监督学习版,得到的模型是
text-davinci-002 - 如果是强化学习版 (RLHF) ,得到的模型是
text-davinci-003 - 无论是有监督还是 RLHF ,模型在很多任务的性能都无法超过 code-davinci-002 ,这种因为对齐而造成性能衰退的现象叫做对齐税。
- 如果是监督学习版,得到的模型是
- 对话能力也来自于 RLHF(
ChatGPT),具体来说它牺牲了上下文学习的能力,来换取:- 建模对话历史
- 增加对话信息量
- 拒绝模型知识范围之外的问题
GPT-3.5 目前不能做什么
GPT-3.5不具备的某些重要属性:
- 实时改写模型的信念:当模型表达对某事的信念时,如果该信念是错误的,我们可能很难纠正它:
- 例子:ChatGPT 坚持认为 3599 是一个质数,尽管它承认 3599 = 59 * 61。
- 然而,模型信念的强度似乎存在不同的层次。一个例子是即使我告诉它达斯·维达(星球大战电影中的人物)赢得了2020年大选,模型依旧会认为美国现任总统是拜登。但是如果我将选举年份改为 2024 年,它就会认为总统是达斯·维达是 2026 年的总统。
- 形式推理:GPT-3.5系列不能在数学或一阶逻辑等形式严格的系统中进行推理。
from:-柚子皮-
ref: [OpenAI的模型索引]
- 语言生成:遵循提示词(prompt),然后生成补全提示词的句子 (completion)
-
相关阅读:
攻防世界misc2-1
File类和IO流的字节流(1)
【面试题】Java基础
C理解(四):链表
巴特沃斯、切比雪夫I型、切比雪夫Ⅱ型和椭圆型滤波器的相同和不同之处
百度文心一言
Java基础(二十)Stream练习
PHP低代码开发平台 V5.0.7新版发布
C# PaddleDetection 安全帽检测
软件测试面试会问哪些问题?
- 原文地址:https://blog.csdn.net/pipisorry/article/details/134013879