-
【强化学习】07——规划与学习(Dyna-Q)
前置知识回顾
策略值函数估计(Policy Evaluation)
给定环境MDP和策略𝜋,策略值函数估计如下
V π ( s ) = E [ R ( s 0 , a 0 ) + γ R ( s 1 , a 1 ) + γ 2 R ( s 2 , a 2 ) + ⋯ ∣ s 0 = s , π ] = E a ∼ π ( s ) [ R ( s , a ) + γ ∑ s ′ ∈ S P s π ( s ) ( s ′ ) V π ( s ′ ) ] = E a ∼ π ( s ) [ Q π ( s , a ) ] Q π ( s , a ) = E [ R ( s 0 , a 0 ) + γ R ( s 1 , a 1 ) + γ 2 R ( s 2 , a 2 ) + ⋯ ∣ s 0 = s , a 0 = a , π ] = R ( s , a ) + γ ∑ s ′ ∈ S P s π ( s ) ( s ′ ) V π ( s ′ ) Vπ(s)=E[R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+⋯|s0=s,π]=Ea∼π(s)[R(s,a)+γ∑s′∈SPsπ(s)(s′)Vπ(s′)]=Ea∼π(s)[Qπ(s,a)]Qπ(s,a)=E[R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+⋯|s0=s,a0=a,π]=R(s,a)+γ∑s′∈SPsπ(s)(s′)Vπ(s′) Vπ(s)Qπ(s,a)=E[R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+⋯∣s0=s,π]=Ea∼π(s)[R(s,a)+γs′∈S∑Psπ(s)(s′)Vπ(s′)]=Ea∼π(s)[Qπ(s,a)]=E[R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+⋯∣s0=s,a0=a,π]=R(s,a)+γs′∈S∑Psπ(s)(s′)Vπ(s′)策略提升(Policy Improvement)
- 对于两个策略𝜋,𝜋′,如果满足如下性质,𝜋′是𝜋的策略提升:
- 对于任何状态𝑠,有 Q π ( s , π ′ ( s ) ) ≥ V π ( s ) Q^{\pi}(s,\pi^{\prime}(s))\geq V^{\pi}(s) Qπ(s,π′(s))≥Vπ(s)
- 进而, 𝜋和𝜋′满足:对任何状态𝑠,有 V π ′ ( s ) ≥ V π ( s ) V^{\pi^{\prime}}(s)\geq V^{\pi}(s) Vπ′(s)≥Vπ(s)
- 也即是 𝜋′的策略价值(期望回报)超过𝜋, 𝜋′比𝜋更加优秀。
证明:
v π ( s ) ≤ q π ( s , π ′ ( s ) ) = E [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s , A t = π ′ ( s ) ] = E π ′ [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] ≤ E π ′ [ R t + 1 + γ q π ( S t + 1 , π ′ ( S t + 1 ) ) ∣ S t = s ] = E π ′ [ R t + 1 + γ E [ R t + 2 + γ v π ( S t + 2 ) ∣ S t + 1 , A t + 1 = π ′ ( S t + 1 ) ] ∣ S t = s ] = E π ′ [ R t + 1 + γ R t + 2 + γ 2 v π ( S t + 2 ) S t = s ] ≤ E π ′ [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 v π ( S t + 3 ) ∣ S t = s ] ⋮ ≤ E π ′ [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + ⋯ ∣ S t = s ] = v π ′ ( s ) . vπ(s)≤qπ(s,π′(s))=E[Rt+1+γvπ(St+1)∣St=s,At=π′(s)]=Eπ′[Rt+1+γvπ(St+1)|St=s]≤Eπ′[Rt+1+γqπ(St+1,π′(St+1))|St=s]=Eπ′[Rt+1+γE[Rt+2+γvπ(St+2)|St+1,At+1=π′(St+1)]∣St=s]=Eπ′[Rt+1+γRt+2+γ2vπ(St+2)St=s]≤Eπ′[Rt+1+γRt+2+γ2Rt+3+γ3vπ(St+3)|St=s]⋮≤Eπ′[Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+⋯|St=s]=vπ′(s).vπ(s)≤qπ(s,π′(s))=E[Rt+1+γvπ(St+1)∣St=s,At=π′(s)]=Eπ′[Rt+1+γvπ(St+1)∣St=s]≤Eπ′[Rt+1+γqπ(St+1,π′(St+1))∣St=s]=Eπ′[Rt+1+γE[Rt+2+γvπ(St+2)∣St+1,At+1=π′(St+1)]∣St=s]=Eπ′[Rt+1+γRt+2+γ2vπ(St+2)St=s]≤Eπ′[Rt+1+γRt+2+γ2Rt+3+γ3vπ(St+3) St=s]⋮≤Eπ′[Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+⋯ St=s]=vπ′(s).
模型(Model)
在强化学习中,无特殊说明的话,模型通常指的是环境模型,而非智能体模型。
定义:给定一个状态和动作,模型能够预测下一个状态和奖励的分布: 即 P ( s ′ , r ∣ s , a ) \mathcal P(s',r|s,a) P(s′,r∣s,a)
模型的分类- 分布模型(distribution model)
- 描述了轨迹的所有可能性及其概率
- 相当于白盒模型
- 样本模型(sample model)
- 根据概率进行采样,只产生一条可能的轨迹
- 相当于黑盒模型
模型的作用
- 得到模拟的经验数据(simulated experiences)
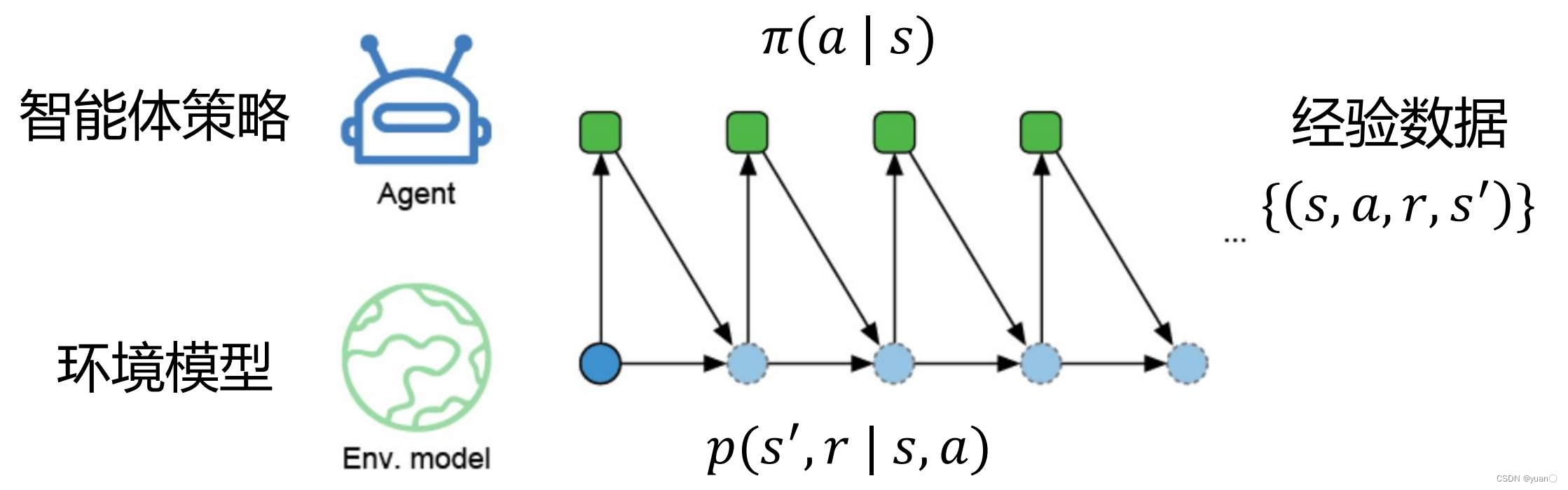
规划(Planning)
定义:输入一个模型,输出一个策略的搜索过程
规划的分类:- 状态空间的规划 (state-space planning)
- 在状态空间搜索最佳策略
- 规划空间的规划 (plan-space planning)
• 在规划空间搜索最佳策略,包括遗传算法和偏序规划
• 这时,一个规划就是一个动作集合以及动作顺序的约束
• 这时的状态就是一个规划,目标状态就是能完成任务的规划
规划的通用框架
- 通过模型采样得到模拟数据
- 利用模拟数据更新值函数从而改进策略

规划的好处 - 任何时间点可以被打断或者重定向
- 在复杂问题下,进行小而且增量式的时间步规划是很有效的
规划与学习(Planning and Learning)
- 不同点
• 规划:利用模型产生的模拟经验
• 学习:利用环境产生的真实经验 - 相同点
• 通过回溯(back-up)更新值函数的估计
• 统一来看,学习的方法可以用在模拟经验上

注意:Q-learning用的是真实环境产生的经验数据,而Q-planning则是利用模型产生的模拟经验。Dyna (集成规划、决策和学习)

通过于环境交互产生的经验可以有以下两种途径:
- 用于更新模型
• 模型学习, 或间接强化学习
• 对经验数据的需求少 - 用于直接更新值函数和策略
• 直接强化学习(无模型强化学习)
• 简单且不受模型偏差的影响
Dyna的框架
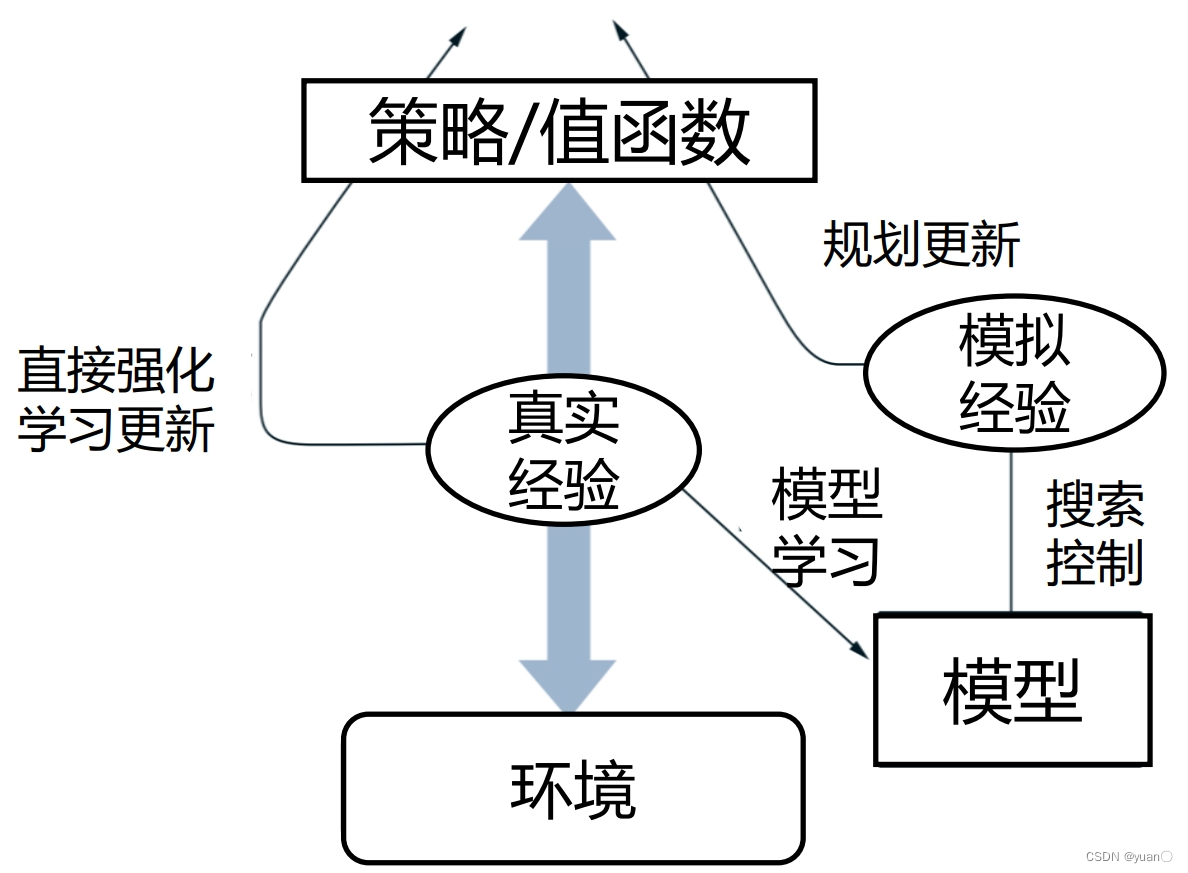
- 和环境交互产生真实经验
- 左边代表直接强化学习
• 更新值函数和策略 - 右下角落边代表学习模型
• 使用真实经验更新模型 - 右边代表基于模型的规划
• 基于模型随机采样得到模拟经验
• 只从以前得到的状态动作对随机采样
• 使用模拟经验做规划更新值函数和策略
Dyna伪代码

Example1:Dyna Maze
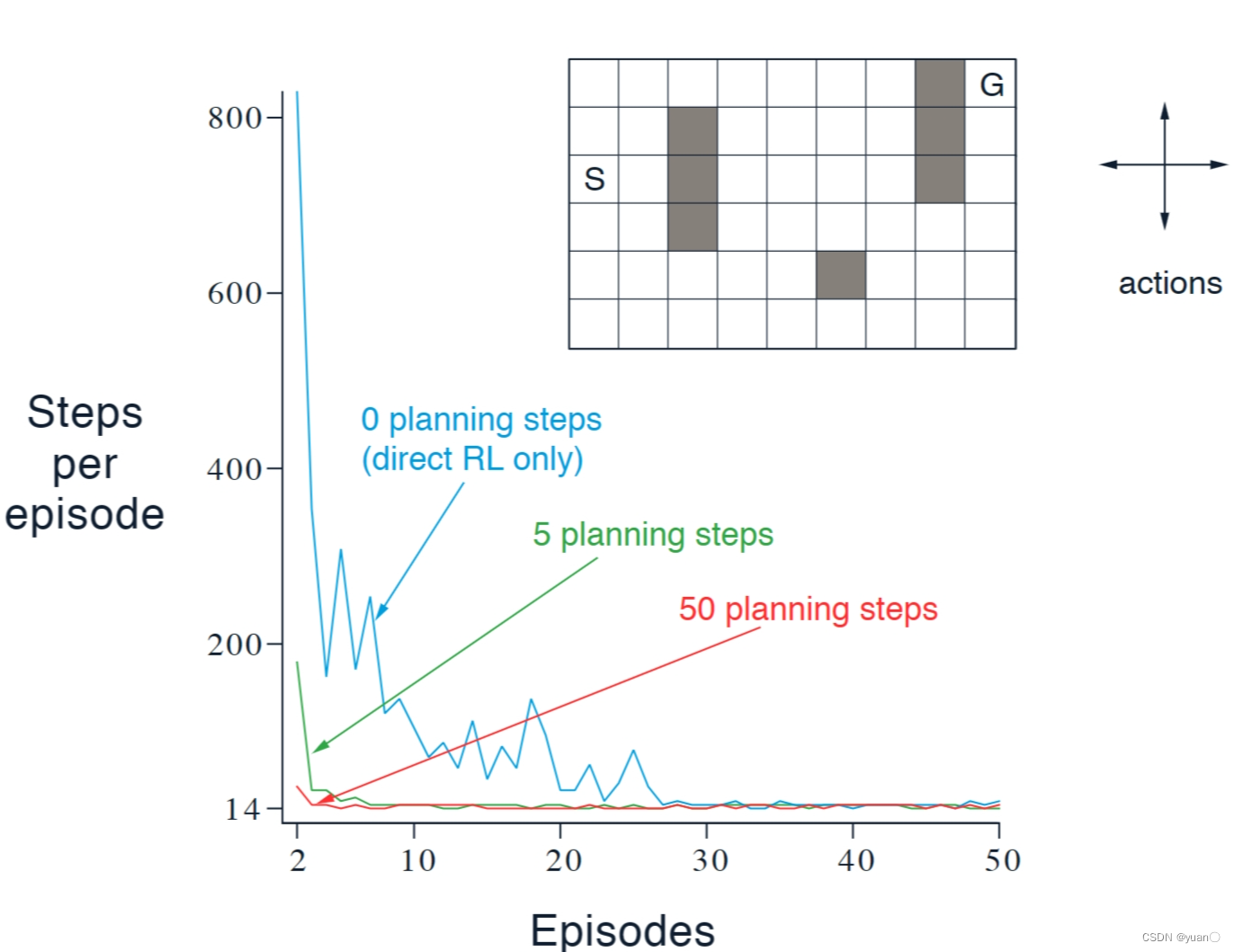
环境
• 4个动作(上下左右)
• 碰到障碍物和边界静止
• 到达目标(𝐺),得到奖励+1
• 折扣因子 0.95
结果
• 横轴代表游戏轮数
• 纵轴代表到达 𝐺 花的时间步长
• 不同曲线代表采用不同的规划步长
• 规划步长越长,表现收敛越快那么为什么Dyna算法会更快呢?

通过更多的sample,可以使得策略更优,更容易靠近终点。模型不准?
原因:- 环境是随机的,并且只观察到了有限的样本
- 模型使用了泛化性不好的函数估计
- 环境改变了,并且还没有被算法检测到
Example2:Blocking Maze
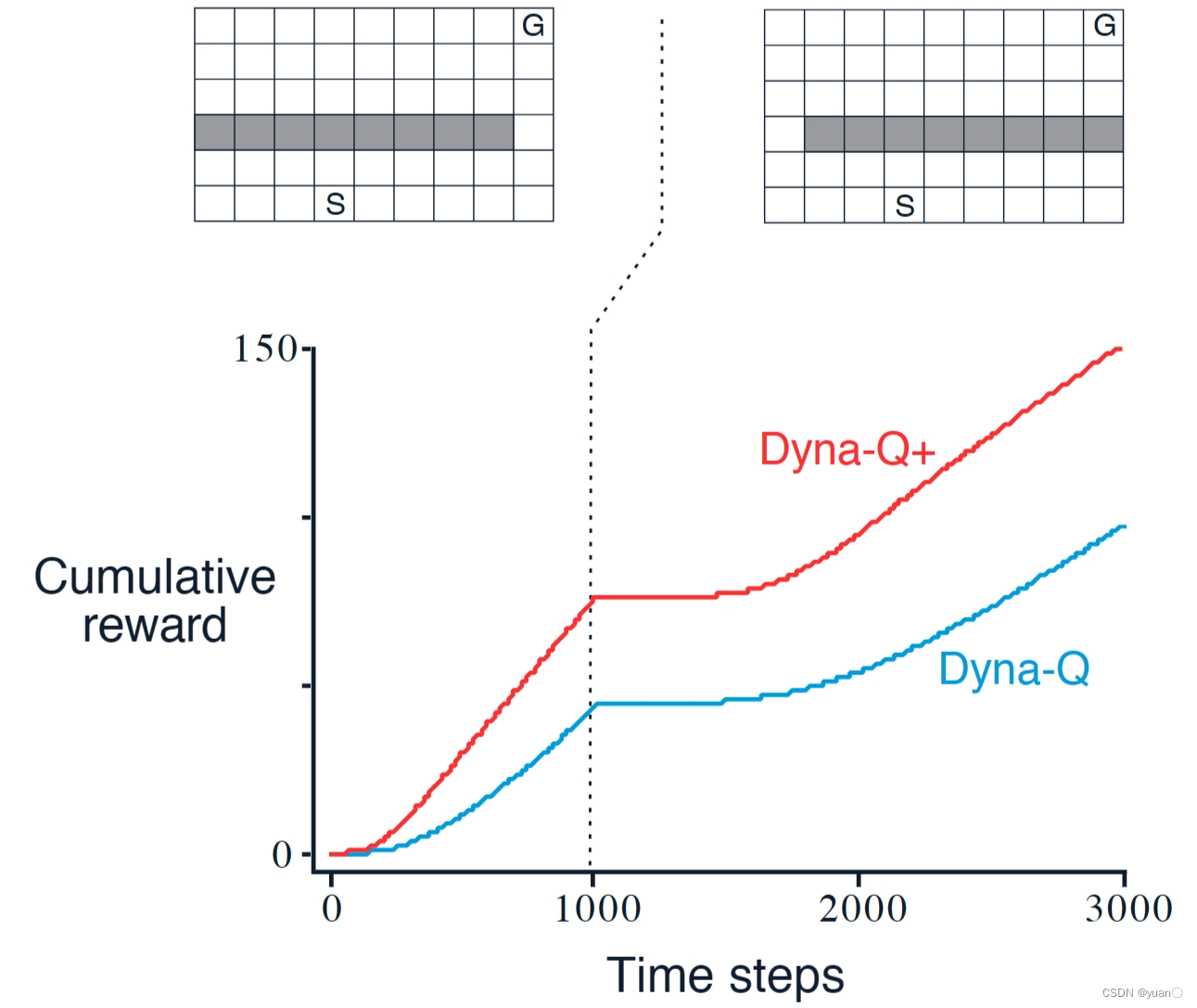
Dyna-Q+:- 奖励更改为
r
+
κ
τ
r+\kappa\sqrt{\tau}
r+κτ
- r r r原来的奖励
- κ \kappa κ小的权重参数
- τ \tau τ某个状态多久未到达过了
Example3:Shortcut Maze
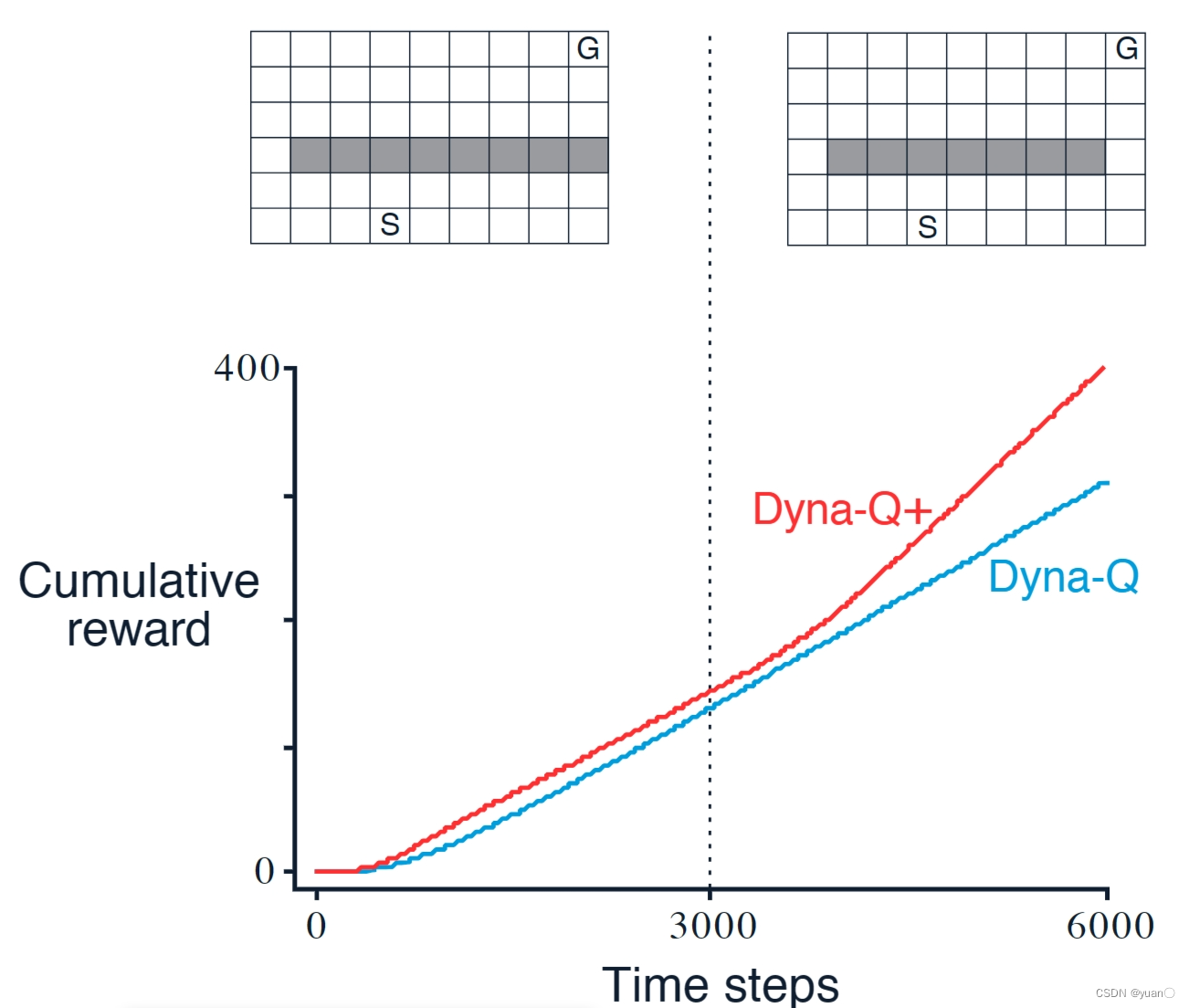
Dyna-Q+能够发现捷径(鼓励探索)代码
class DynaQ(): def __init__(self, env, gamma, alpha, epsilon, numOfEpisodes, numOfTrainQLearning, numOfActions=4): self.env = env self.gamma = gamma self.alpha = alpha self.epsilon = epsilon self.numOfEpisodes = numOfEpisodes self.numOfActions = numOfActions # 初始化Q(s, a)表 self.Q_table = np.zeros([self.env.nrows * self.env.ncols, numOfActions]) # 初始化模型 self.Model = dict() # Q-learning 训练次数 self.numOfTrainQLearning = numOfTrainQLearning # Choose A from S using policy derived from Q (e.g., epsilon-greedy) def ChooseAction(self, state): if np.random.random() < self.epsilon: action = np.random.randint(self.numOfActions) else: action = np.argmax(self.Q_table[state]) return action def DynaQRun(self): # 记录每一条序列的回报 returnList = [] # 显示10个进度条 for i in range(10): # tqdm的进度条功能 with tqdm(total=int(self.numOfEpisodes / 10), desc='Iteration %d' % i) as pbar: # 每个进度条的序列数 for episode in range(int(self.numOfEpisodes / 10)): # initialize state state = self.env.Reset() done = False episodeReward = 0 # Loop for each step of episode: while not done: # Choose A from S using policy derived from Q (e.g., epsilon-greedy) action = self.ChooseAction(state) # Take action A, observe R, S' stateprime, reward, done = self.env.Step(action) episodeReward += reward # Update TD_error = reward + self.gamma * self.Q_table[stateprime].max() \ - self.Q_table[state, action] self.Q_table[state,action] += self.alpha * TD_error # 将数据添加到模型中 self.Model[(state, action)] = stateprime, reward # Q-planning循环 for i in range(self.numOfTrainQLearning): # 随机选择曾经遇到过的状态动作对 (s, a), (s_next, r) = random.choice(list(self.Model.items())) # Q-plannnig TD_error = r + self.gamma * self.Q_table[s_next].max() \ - self.Q_table[s, a] self.Q_table[s, a] += self.alpha * TD_error state = stateprime returnList.append(episodeReward) if (episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报 pbar.set_postfix({ 'episode': '%d' % (self.numOfEpisodes / 10 * i + episode + 1), 'return': '%.3f' % np.mean(returnList[-10:]) }) pbar.update(1) return returnList- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
结果
Q-planning训练次数为0

可以看到,当Dyna-Q的Q-planning训练次数为0时,Dyna-Q就退化成了Q-learning。十次训练平均:

随着 Q-planning 步数的增多,Dyna-Q 算法的收敛速度也随之变快。当然,并不是在所有的环境中,都是 Q-planning 步数越大则算法收敛越快,这取决于环境是否是确定性的,以及环境模型的精度。在上述悬崖漫步环境中,状态的转移是完全确定性的,构建的环境模型的精度是最高的,所以可以通过增加 Q-planning 步数来直接降低算法的样本复杂度。
参考
[1] 伯禹AI
[2] https://www.deepmind.com/learning-resources/introduction-to-reinforcement-learning-with-david-silver
[3] 动手学强化学习
[4] Reinforcement Learning -
相关阅读:
vscode因为大文件而无限崩溃的问题,窗口意外终止(原因:“oom“,代码:“-536870904“
Python爬虫实战-小说网站爬虫开发
freeswitch之媒体协商模式
mybatis自定义注解+拦截器实现自定义方法拦截
pymysql写入时,遇到pandas dataframe中有混合的数据类型以及nan值
H264基础知识入门
01程序执行原理
本季度干货导航 | 2022年Q2
微服务框架 SpringCloud微服务架构 18 操作索引库 18.1 mapping 属性
物联网开发笔记(7)- 使用Wokwi仿真ESP32开发板实现LED灯点亮、按钮使用
- 原文地址:https://blog.csdn.net/sinat_52032317/article/details/134006155
