-
论文笔记-Sharing More and Checking Less:SaTC
文章提出了一个新的静态污点检测解决方案SaTC,用于有效检测嵌入式设备提供的网络服务中的安全漏洞。Web界面上的字符串通常在前端页面和后端二进制文件之间共享,以对用户的输入进行编码。文章从前端提取常用的关键字,并使用它们来定位后端的参考点,这些参考点表示输入入口。然后应用目标数据流分析来精确检测非信任用户输入的危险使用。在6个流行的供应商提供的39个嵌入式系统固件上进行了评估,SaTC发现了33个未知的错误,其中30个由CVE/CNVD/PSV确认。

1 提出问题
无线路由器通常为终端用户提供基于web的界面来配置系统。底层固件包含web服务器、各种前端文件和后端二进制程序。web服务器接受来自前端的HTTP请求,并调用后端二进制文件来处理它们。在这种情况下,攻击者可能会在前端构建恶意输入,以破坏相应的后端二进制文件。
现有的方法无法有效分析嵌入式系统中的服务以检测漏洞。动态方法如模糊测试和仿真,只能到达程序所有可能状态的一小部分,导致很高的误报率。静态方法如KARONTE依赖前后端之间的通用进程间通信(IPC)来定位处理输入数据的代码,并执行集中测试,但这些方法可能会导致许多误报。文中发现从嵌入式系统发现bug的关键点是使用web前端用户提供的数据来定位后端处理该数据的代码。
2 解决方案
文章提出了一种新颖的静态分析方法,可以跟踪前端和后端之间用户输入的数据流,以精确检测安全漏洞。处理用户输入的后端函数通常与相应的前端文件共享一个关键字:在前端,用户输入被标记为关键字并编码在数据包中;在后端,使用相同或相似的关键字从数据包中提取用户输入。因此,可以使用共享关键字来标识前端和后端之间的连接,并在后端找到用户输入的入口。
2.2 贡献
- 提出了一种新的技术,利用嵌入式系统前端和后端之间的公共关键字来定位后端二进制文件中的数据录入。
- 设计并实现了SaTC,利用粗粒度污点分析和跟踪合并方法来有效检测嵌入式系统中的漏洞。
- 在39个真实世界固件样本上评估了SaTC,发现了33个未知错误,包括命令注入、缓冲区溢出和不正确的访问控制错误。源代码和实验数据公布在GitHub - NSSL-SJTU/SaTC: A prototype of Shared-keywords aware Taint Checking, a novel static analysis approach that tracks the data flow of the user input between front-end and back-end to precisely detect security vulnerabilities.。
3 方法介绍
SaTC分为三个组件:输入关键字提取器(从前端文件中收集关键字)、输入入口识别器(在后端二进制文件中定位输入入口)、输入敏感污点引擎(有效检测漏洞)。

图2展示了SaTC的系统架构。SaTC首先使用如binwalk等解包器对输入的固件映像进行解包,根据文件类型识别前端文件和后端程序:如HTML、JavaScript和XML通常为前端文件,可执行二进制程序和库为后端文件。然后,SaTC分析前端文件并利用典型模式来提取用户输入的潜在关键词。如图1中的deviceName、target和goform/setUsbUnload将被确定为输入关键词。
接下来SaTC识别后端中的边界二进制文件(该文件根据用户输入的关键字调用不同的处理函数),通过这些函数找到检索用户输入的点。

3.1 可行性验证
为了验证共享关键词想法是否适用于正常的物联网设备,检查了5家供应商的10台路由器。文章基于以下三个原则从后端和前端提取字符串:1)字符串为网络包中的一些"key",其格式为...&key=value&...,通过在前端手动触发尽可能多的操作,以覆盖更多的请求信息。2)选择用于消息中检索输入数据的的后端字符串。定义几种常用于获取输入值的函数,如websGetvar
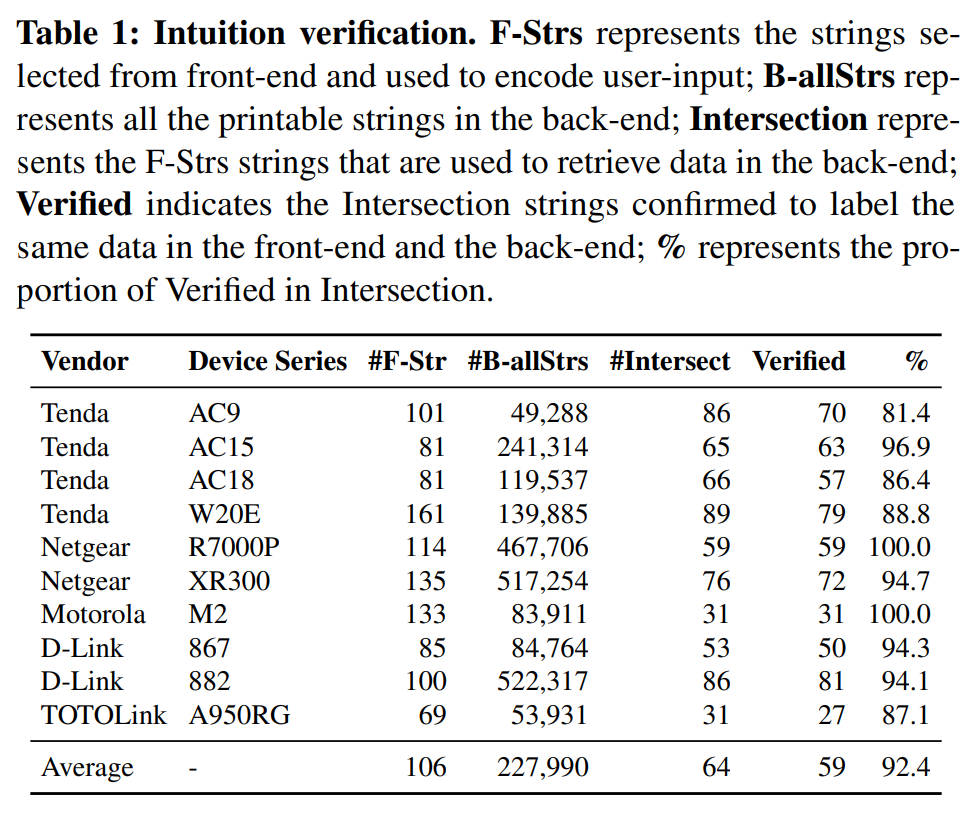
websGetvar 函数等,收集这些函数的常量字符串参数作为目标后端字符串。3)收集前端和后端字符串的交集。对于交集中的每个字符串,在前端改变相关变量的值,如果后端该变量的值发生了变化,那么确认被测试的字符串是一个代表用户输入的共享关键字,并通过多次改变值来避免后端变量的意外改变。表1展示了验证结果,可以总结为:前端捕获的关键字-值对中平均有92.4%与后端相匹配,这表明共享关键字的想法适用于这些常见的设备。
3.2 关键字提取
给定一个已解包的固件,SaTC首先从前端文件中提取潜在的关键字。根据关键字在后端的使用情况将其分为两种类别:1)标记用户的输入(参数关键字);2)标记处理函数(动作关键字)。对于HTML和XML文件,由于其标准格式,如id、name和action属性的值,使用正则表达式来提取关键字。对于JavaScript,将其解析为抽象语法树(AST),扫描每个Literal节点以提取值,如果Literal节点包含符号/,则将字符串作为动作关键字。进一步搜索所有的CallExpression节点,找到使用典型API作为其被调用方的节点,如sendSOAPAction,匹配节点的API方法或参数同样被视为动作关键字。
文中将那些通常在前端使用,但在后端没有对应的字符串称为无效关键字,为了过滤上述无效关键字,首先删除带有特殊字符的字符串,如!和@(这些在前端生成HTTP请求时会被转义)。其次,如果字符串以=结束,那么只保留字符串的左侧部分。最后,过滤掉长度小于阈值(文中阈值为5)的字符串,因为参数关键字和动作关键字通常具有特殊的名称。
执行上述过滤后,候选列表仍然包含许多未用作输入关键字的干扰项。采取两种手段再次过滤:1)如果JavaScript文件被众多HTML文件引用,则将其视为一个通用的JS库文件,由于库文件中通常不包含输入关键字,因此可以忽略这些文件里的所有输入关键字候选项。2)如果关键字被许多前端文件引用,如Button和Cancel等这些普通字符串,则删除这些关键字。
边界二进制识别
在固件后端,边界二进制文件将设备功能导出到前端,同时接受来自前端的用户输入。SaTC从每个后端二进制文件中提取字符串,并尝试将它们与输入的候选输入关键字匹配,将具有最大匹配度关键字的二进制文件视为边界二进制文件。
3.3 入口识别
该模块基于对前端关键字的引用来检测后端二进制文件中的入口点。
3.3.1 关键字引用定位器
下列公式展示了从后端边界二进制文件定位输入入口的方法。s(ki)
s(ki) 表示一个字符串,它要么完全等于输入关键字ki,要么包含子字符串ki。定位器检测边界二进制文件内对字符串s(ki)的引用位置。由于处理函数通常使用输入关键词来从请求中提取目标数据,SaTC定位以输入关键词为参数的函数调用L,如foo("devName")。在所有关键字引用中,优先考虑动作处理程序中的关键字引用。特别地,SaTC搜索以动作关键字和函数指针为参数的函数调用P。由于操作关键字用于检索特定输入的处理程序,将函数指针中指定的例程视为操作处理程序。如果参数关键字的一些参考点L在这些处理程序函数中,将优先探索L。s(ki)={ki concat (ki, str ),ki∈ keywords, str is anystring
L: ret = foo (ski,…),ki∈ parameter_keywords
P:ret=bar(ski,…,& foo ),ki∈ action_keywords
3.3.2 隐式入口查找器
在实验中,后端的几个真实输入条目在前端没有对应的关键字,为解决该问题,可在分析时考虑已知输入项周围的类似代码模式。如公式2所示:如果识别了一个输入项L,只要foo具有与L相似的代码模式,围绕L的另一个调用foo的函数将被视为另一个输入条目。将这里缺少的关键字pi称为隐式关键字。
Lp: ret =foo(pi,…),pi∉ keywords, ∃L:dist(Lp,L)<MAX
3.3.3 跨程序入口查找器
一些输入的数据流可能在进程边界处中断,SaTC使用跨进程入口搜索器(CPEF)来跟踪跨固件二进制或组件的用户输入。它搜索各种使用共享字符串来标记数据的进程间通信范式,并建立从设定点到使用点的数据流。CPEF提供必要的逻辑来检测二进制文件或函数之间共享数据的通信范式(如NVRAM通信)。它主要支持两类进程间的通信范式:NVRAM和环境变量。

3.4 敏感污点分析
SaTC利用路径探索和污点分析技术来跟踪输入数据,以检测后端的危险使用。根据固件的独特功能设计了三种优化方法:粗粒度污点引擎、高效路径探索和路径优先策略。
3.4.1 粗粒度污点引擎
污点源:
污点引擎根据输入条目识别的结果来标记污点源,污点源可以是一个变量或一个目标函数的参数。如清单1所示,字符串deviceName被用作函数WebsGetVar的参数,因此其内存位置将被设置为污点源。

污点规范:
SaTC的污点引擎在指令层传播污点属性。为了恰当地处理函数调用,首先将函数分为以下几类:可总结的函数、一般函数和嵌套函数。可总结的函数是与内存区域的操作有关的标准库函数,如strcpy和memcpy。一般的函数不包含函数调用指令,或者只包含通往可总结函数的分支(例如图3中的funcA)。其余的函数,包含对一般函数的函数调用,为嵌套函数。在图3的代码中,函数strcpy和strlen被视为可归纳的函数。 funcA没有调用非可归纳的函数,因此它是一个通用函数。funcB调用了另一个普通函数funcC,因此因此是一个嵌套函数。

3.4.2 高效路径探索
敏感轨迹引导:
尽管之前的模块减少了污点分析的目标,但仍可能有相当数量的输入条目需要分析。为了提高分析效率,SaTC在探索任何路径之前都会搜索每个目标的汇点调用轨迹。一个汇点调用轨迹代表了调用图中从输入条目到潜在汇入函数的函数调用序列。SaTC根据一个函数的调用树来搜索该函数的汇点调用痕迹,该调用树以该函数为根节点。如果一个函数不包含调用痕迹,那么从这个函数到汇点就没有可达路径,SaTC将从目标集中删除该函数的所有输入条目。在探索过程中,SaTC检查每个函数调用指令,看目标是否属于调用轨迹,如果是,就把探索引向函数主体。
调用轨迹合并:
为减少调用轨迹,根据起始点和输入关键词对所有轨迹进行聚类。其次,把调用轨迹中的所有函数分为两类:汇入函数和引导函数,并记录函数调用指令的类型和地址。引导函数代表了汇入函数在汇点调用痕迹中的支配者。在探索过程中,当遇到一个跳转到引导函数的调用指令后,SaTC将步入该函数进行细粒度分析。
3.4.3 路径优先策略
为了减轻特殊函数的负面影响(如sanitizer函数可能导致无限循环),识别它们并应用特殊的规则。如果1)一个函数至少包含一个循环;2)函数的比较指令的数量大于阈值;3)部分比较指令可以限制函数参数所指向的内存区域的内容(即值),则将将其视为类似memcmp函数。根据信息保存的数量。将这些函数分为两类:Parsers和Sanitizers。
Parsers:
一个Parser函数通常包含一个循环,如图3中的funcA。如果变量s1不受约束,那么总有一条路径从默认语句到for循环的头部。在这些路径中,只有那些通过第一个case语句(第5行)的路径会将污点传播到函数之外。换句话说,缺少这些路径的分析会错误地认为用户的输入不能影响变量s2和后来的执行路径。
Sanitizers:
Sanitizer函数要么清理恶意数据,要么对潜在的威胁发出警告。考虑到图5中的例子,为了过滤特定的字符串,如?,Netgear在类似系统函数之前插入了一个sanitizer函数FUN_7b83c,它包含一个对用户输入的复杂检查(第7行)。由于while循环和比较操作导致了许多路径,为了获得对用户输入的完整约束,只关注长的路径。

4 实验评估
4.1 SaTC能否有效检测出真实产品中的漏洞?与目前最先进的工具相比效率如何?
检测出真实世界中的漏洞:
如表4所示,SaTC检测到33个以前未知的错误,其中30个已被其开发人员确认。25个漏洞是命令注入漏洞;其中两个是缓冲区溢出错误;其他6个属于不正确的访问控制,可能导致隐私泄露。

与KARONTE工具的对比:
表5显示了对比结果。SaTC发出了2084条警报,其中683条为真阳性;KARONTE发出了74次警报,其中46次为真阳性。结果表明,SaTC比KARONTE能找到更多的漏洞。

如表6所示。SaTC成功发现36个漏洞,而KARONTE在任何样本中均未发现任何漏洞。

4.2 SaTC提取关键词的准确率如何?

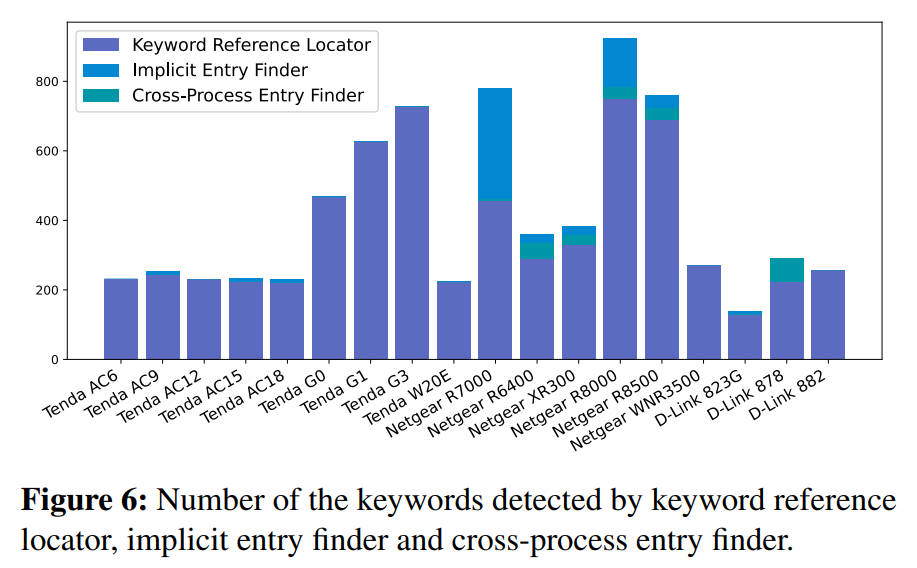
图6列出了关键字引用定位器、隐式条目查找器和跨流程条目查找器检测到的每个样本中的关键字数量。可以看到,大多数输入关键字都是由关键字引用定位器收集的,特别是对于Tenda设备。Netgear示例包含由隐式条目查找器定位的相对较多的关键字,而D-Link示例包含与不同二进制文件之间共享数据相关的更多关键字。
4.3 SaTC污点分析的准确率怎么样?
4.3.1 路径融合
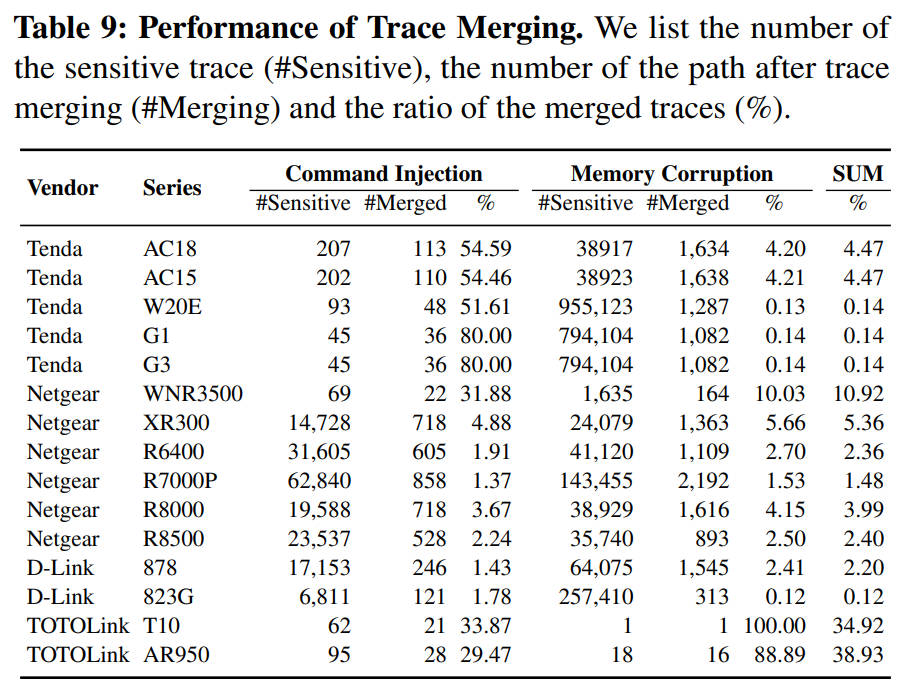
SaTC通过合并具有相同输入条目的调用痕迹来减少需要探索的路径数量。表9显示了轨迹合并前后的探索路径数量。
4.3.2 路径优先级
SaTC在Netgear样本中发现了5个解析和sanitizer函数。其中3个用于对字符实体进行编码,2个用于解析输入字符串,转义字符和生成内部的变量。
4.3.3 污点引擎

对于表9中的所有固件样本,SaTC发出了101个警报,其中46个是真阳性。作者手动分析了警报中的20个假阳性。如清单5所示,一些过度污点问题的发生是由于常见函数的抽象缺失,如atoi。字符变量pIndex的污点状态被传递给一个整数变量(第8行),它被用作索引,从一个列表中提取数据,并将数据存入字符串sUserId(第9行)中。SaTC发出警报是因为v6最终影响了doSystemCmd函数(第10行)。事实上,攻击者无法通过接口关键字vpnUserIndex来控制该字符串。
5 总结
5.1 个人总结
文章提出了一种检测嵌入式系统中安全漏洞的新方法SaTC。基于变量关键字通常在前端文件和后端函数之间共享的思想,SaTC精确识别后端二进制文件中的输入条目,然后利用本文为嵌入式系统定制的污点引擎,有效地检测出对不可信任的输入的危险使用。
5.2 SaTC的缺陷
- 当后端程序直接从HTTP消息中读取数据时(即没有使用共享关键字),SaTC会遗漏相关漏洞。
- 如果后端程序中没有与前端相关的共享字符串,或者这些条目不能通过启发式方法检测出来,SaTC可能会导致假阴性。
- 当物联网设备制造商采用代码加密或代码混淆来保护产品时,SaTC无法建立前端和后端的联系,此时会失效。
-
相关阅读:
DASCTF X CBCTF 2022九月挑战赛 Writeup
WPF数据视图
2 Java NIO--Buffer使用说明
POJ2367Genealogical tree题解
python 2018全国自学考试第5章 第36题。好激动呀 排名23310
与灰度观点相左?欧科云链研究院带你一文读懂BTC链上表现
传统加密技术(恺撒+仿射)
基于matlab的异步(感应)电机直接转矩控制系统
Vue.js核心技术解析与uni-app跨平台实战开发学习笔记 第1章 Vue.js基础入门 1.7 双向数据绑定
7-4 USB接口的定义 (10分)
- 原文地址:https://blog.csdn.net/qq_42052733/article/details/127787763