-
深入浅出:Python内存管理机制详解
一、什么是内存?
1.1、RAM简介
随机存取存储器(Random Access Memory,RAM):是计算机中用于临时存储数据的一种硬件组件。它是计算机的主要内存之一,用于存储正在运行的程序和操作系统所需的数据。主要特点:
- 临时存储:RAM 存储的数据是临时的,意味着当计算机关闭或重启时,其中的数据会被清空。这与永久存储设备(如硬盘驱动器)不同,后者可以长期保存数据。
- 随机存取:RAM 具备随机访问能力,这意味着它可以快速访问存储中的任何数据,而无需按照特定的顺序来读取。这使得 RAM 非常适合用作计算机的工作内存,以快速存取和处理数据。
- 高速存储:RAM 是一种高速存储设备,数据可以在毫秒或甚至纳秒级别的时间内被读取或写入。这使得计算机能够快速执行任务,提高性能。
- 容量较小:RAM 的容量通常相对较小,通常以兆字节(MB)或千兆字节(GB)来衡量。计算机的 RAM 容量会影响其多任务处理能力和运行大型程序的性能。
1.2、RAM容量
RAM的容量:表示计算机(当前 / 单次)能够同时加载和计算的数据和程序的总内存上限。例如:当前计算机具有64GB的RAM,那么可以在同一时刻加载和运行的数据和程序总共不能超过64GB。否则将导致(RAM)内存不足,并且可能会导致系统变得非常慢甚至系统崩溃。
内存的使用:
- 操作系统:操作系统需要占用一部分RAM,以便运行系统的核心功能。
- 正在运行的应用程序:每个打开的应用程序需要分配一部分RAM,以存储其数据和代码。更大的应用程序和多任务处理可能需要更多的RAM。
- 正在处理的数据:如打开的文档、图像、视频或音频文件,都需要RAM来存储。
- 缓存和临时数据:操作系统和应用程序通常使用RAM来加速数据的读取和写入,因此一些RAM也会被用于缓存和临时存储。
当超过RAM容量的数据和程序被加载时,计算机性能会受到影响,因为它将不得不频繁地从硬盘或固态硬盘等永久存储设备中读取数据,这通常较慢,导致性能下降。
1.3、查看电脑内存
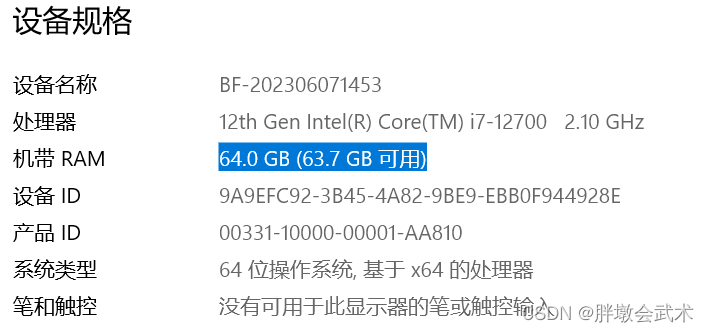
1.4、监控电脑内存
当前内存的使用情况

当前内存的使用占比

二、主机 = (CPU+内存)、设备 = (GPU+显存)
在CUDA编程中
CPU和主存(RAM):称为主机(Host)GPU和显存(VRAM):称为设备(Device)- CPU无法直接读取显存数据,GPU无法直接读取主存数据;
- 主机与设备必须通过总线(Bus)相互通讯;
2.1、RAM是CPU的主内存,显存是GPU的专用内存
2.1.1、内存 + 显存
-
随机存取存储器(Random Access Memory, RAM)):是中央处理器(CPU)的主内存。- (1)用于(临时)存储正在运行的程序和操作系统使用的数据。RAM是一种易失性存储器,意味着当计算机关闭电源时,其中存储的数据会丢失。而固态硬盘(SSD)和机械硬盘(HDD)可以长期存储数据。
- (2)比硬盘的读写速度快:RAM具有非常快的读写速度,比起硬盘等其他存储设备,RAM的访问速度要快得多。
- (3)比硬盘的成本高: 相比于硬盘等其他存储设备,RAM的成本通常较高。因此,为了平衡性能和成本,计算机通常会配备适量的RAM,以满足大多数用户的需求。
- (4)RAM的速度和容量对CPU的性能至关重要。较大且更快的RAM能够更有效地提供所需的数据,从而减少CPU等待数据的时间。
-
显存(Graphics RAM,GRAM):是图形处理器(GPU)的随机存取存储器。- (1)用于(临时)存储GPU在处理图形数据时所需的数据,如图像纹理、帧缓冲区等。与RAM类似,GRAM也是一种易失性存储器,意味着其中存储的数据在计算机关闭时会丢失。
- (2)比内存的读写速度快: 显存通常具有高带宽,能够快速地读取和写入图形数据,以满足图形处理器对大量数据的高速访问需求。
- (3)专门为图形处理任务设计的存储器,拥有独立于计算机主内存(RAM)的物理存储。
- (4)容量比内存小:随着图形处理技术的发展,显存的容量也在不断增加,以满足越来越复杂的图形处理任务。
- (5)显存的大小和类型(如:GDDR5、GDDR6等)直接影响了GPU处理大规模图形数据的能力。更大容量和更高带宽的显存通常意味着GPU能够处理更复杂的图形任务。
2.1.2、GPU内存 = 专用GPU内存(显存) + 共享 GPU内存
当前显存的使用占比

示例:
image.to("GPU"):将图像从CPU上传GPU时,会产生一定的耗时。与数据传输带宽、图像大小和 GPU 设备性能等有关。- (1)若上传图像所需内存超过了专用 GPU 内存(显存),则超出部分将转移到共享 GPU 内存中,以防止程序奔溃,但由于共享 GPU 内存是主存划分出来与 GPU 共享的内存,因此速度会明显减慢。
- (2)硬件性能测试(batch=8):3060TI - 耗时=0.9秒,3090TI=0.3秒
- (3)内存性能测试(batch=8、16、32、64):
- (1)batch=8 / 16:所需内存在专用 GPU 内存范围内;
- (2)batch=32及以上:所需内存超过专用 GPU 内存,则超出部分转移到共享 GPU 内存中。
2.1.3、CPU + GPU
-
中央处理器(Central Processing Unit,CPU): CPU是计算机的大脑,负责执行各种通用计算任务。如控制计算机的运行、处理各种数据和执行应用程序等。- CPU具有较高的单线程性能和通用性,适合处理顺序计算任务和复杂的逻辑运算。
- CPU具有较少的核心(几个到数十个),适用于通用计算。
-
图形处理器(Graphics Processing Unit,GPU):GPU是专门用于处理图形和并行计算任务的处理器。- 最初是为图形渲染而设计的,但由于其并行处理能力,它在科学计算、深度学习等领域也得到广泛应用。
- GPU具有大量的小型处理核心,适用于大规模并行计算。
GPU需要与CUDA结合,才能完成模型训练、PyTorch安装等等。若没有CUDA,GPU在深度学习中就是个摆设。GPU推理速度是CPU的几十倍。
在深度学习中,CPU与GPU具有协同作用:
- CPU:
- 控制和协调整个深度学习模型的训练和推理过程。
- 加载数据并进行预处理,如数据读取、数据增强等。
- 在小规模数据集或较简单的模型上进行训练和推理。
- 处理与深度学习相关的任务外的其他计算任务,如系统管理、网络通信等。
- GPU:
- 加速深度学习模型的训练和推理过程。GPU的并行计算能力可以显著加速深度学习任务的运行速度。
- 处理大规模数据集和复杂模型的训练和推理。由于GPU具有大量的处理核心和高度并行化的计算结构,适合处理深度学习中的大量矩阵运算和神经网络计算。
- 支持深度学习框架的加速计算,如TensorFlow、PyTorch等框架已经针对GPU进行了优化,能够充分利用GPU的计算资源。
- 用于模型的调优和超参数搜索,通过并行计算和并行评估,可以更快地找到最佳模型和超参数组合。
2.1.4、不同数据类型的内存范围
- 图像内存的计算公式:
内存大小 = 宽度 × 高度 × 通道数 x 每个像素的字节数 - 内存的基本存储单元是字节而不是位,且是整数表示。
# 在计算机中,最小的存储单元是位(bit),而一个字节(Byte)通常由8个位组成。 1 TB = 1024 GB = [1024^2] MB = [1024^3] KB = [1024^4] Bytes = [1024^4 x 8] bits 位(bits) + 字节(Bytes) + 千字节(Kilobytes,KB) + 兆字节(Megabytes,MB) + 吉字节(Gigabytes,GB) + 千兆字节(Terabytes,TB) + PB + EB + ZB + YB- 1
- 2
- 3
- 4
数据类型 说明 每个像素的字节数 数据范围 内存范围 bool布尔类型 1位 [0,1] 2bitsint8 有符号8位整数 8位(1字节) [-128,127] [-16,16]Bytes uint8无符号8位整数 8位(1字节) [0,255] [0,32]Bytesint16 有符号16位整数 16位(2字节) [-32768,32767] [-32,32]KB uint16无符号16位整数 16位(2字节) [0,65535] [0,64]KBint32 有符号32位整数 32位(4字节) [-2,147,483,648,2,147,483,647] [-2,2]GB uint32无符号32位整数 32位(4字节) [0,4,294,967,295] [0,4]GBint64 有符号64位整数 64位(8字节) [-9.22×1018,9.22×1018] [-8,8]EB uint64无符号64位整数 64位(8字节) [0,18,446,744,073,709,551,615] [0,16]EB2.2、CUDA:线程 + 块 + 网格
【深度学习环境配置】Anaconda +Pycharm + CUDA +cuDNN + Pytorch + Opencv(资源已上传)
(1)导入CUDA库:
from numba import cuda
(3)在GPU函数(又称为核函数)上,添加@cuda.jit装饰符 —— 表示该函数在GPU设备上运行。从计算逻辑来讲,可以认为GPU是一个高度并行的计算阵列,我们可以想象成一个围棋棋盘的二维网格。
-
软件角度:
- CUDA将一个GPU函数运算称为一个
线程(Thread) - 多个线程组成一个
块(Block) - 多个块组成
网格(Grid)
- CUDA将一个GPU函数运算称为一个
-
硬件角度:
- 一个 thread 运行在一个 CUDA 核心上
- 多个 thread 组成的 blcok 运行在 Streaming Multiprocessor 上
- 多个 block 组成的 grid 运行在一个 GPU 显卡上。
- 备注:Streaming Multiprocessor(SM)是NVIDIA GPU设备上执行并行计算的基本计算单元。每个SM都是一个独立的处理单元,具有自己的寄存器文件、共享内存和其他资源。一个GPU设备通常包含多个SM,每个SM可以并行处理多个线程,这使得GPU能够同时执行大量的计算任务。
如上所述:
一个Grid可以定义为上万个线程,即实现了上万次并行计算。
GPU核函数:
gpu_func[2, 4]()表示开启2个block块,每个block块开启4个线程,故 gpu_func 函数将被并行地执行 2 x 4 = 8次。- 每一行都是一个块,并有自己的块编号;
- 每一列都是一个线程,并有自己的线程编号;
- 每一个白色格子都可以执行一个单独的任务,且所有的白色格子可以同时执行计算任务,这就是GPU加速的来源。
from numba import cuda def get_gpu_info(): gpu = cuda.get_current_device() # 获取当前设备信息 wapp_size = gpu.WARP_SIZE # GPU设备的warp大小。 # Warp(线程束)是GPU硬件并行执行指令的基本单位。它是一组并行执行的线程,这组线程在执行时会同时执行相同的指令。 # Warp的大小是由GPU硬件架构决定的,对于 NVIDIA 的 GPU,通常是32个线程。 max_threads_per_block = gpu.MAX_THREADS_PER_BLOCK # 获取最大线程数 max_block_dimensions = gpu.MAX_BLOCK_DIM_X, gpu.MAX_BLOCK_DIM_Y, gpu.MAX_BLOCK_DIM_Z # 获取线程块的最大维度 max_grid_dimensions = gpu.MAX_GRID_DIM_X, gpu.MAX_GRID_DIM_Y, gpu.MAX_GRID_DIM_Z # 获取线程块在网格中的最大维度 print("Max Threads per Block:", max_threads_per_block) print("Max Block Dimensions :", max_block_dimensions) print("Max Grid Dimensions :", max_grid_dimensions) @cuda.jit def gpu(): print('threadId:', cuda.threadIdx.x, cuda.threadIdx.y, cuda.threadIdx.z , 'gridDim:', cuda.gridDim.x, cuda.gridDim.y, cuda.gridDim.z) # 获取线程索引和维度 print('blockIdx:', cuda.blockIdx.x, cuda.blockIdx.y, cuda.blockIdx.z , 'blockDim:', cuda.blockDim.x, cuda.blockDim.y, cuda.blockDim.z) # 获取块索引和维度 if __name__ == '__main__': # 获取GPU的信息(最大) get_gpu_info() # 定义块大小和网格大小 threads_per_block = (2) # 三个维度: 2, (2,2), (2,2,2) blocks_per_grid = (2) # 三个维度: 2, (2,2), (2,2,2) gpu[threads_per_block, blocks_per_grid]() # 获取GPU的信息(指定) """ Max Threads per Block: 1024 Max Block Dimensions : (1024, 1024, 64) Max Grid Dimensions : (2147483647, 65535, 65535) threadId: 0 0 0 gridDim: 2 1 1 threadId: 1 0 0 gridDim: 2 1 1 threadId: 0 0 0 gridDim: 2 1 1 threadId: 1 0 0 gridDim: 2 1 1 blockIdx: 0 0 0 blockDim: 2 1 1 blockIdx: 0 0 0 blockDim: 2 1 1 blockIdx: 1 0 0 blockDim: 2 1 1 blockIdx: 1 0 0 blockDim: 2 1 1 """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
2.3、获取 GPU 显存信息
方法一:使用 cmd 获取
使用命令行查看GPU设备信息:
Win + R + dxdiag + 显示 + 显示内存VRAM

方法二:使用 GPUtil 获取
import GPUtil # pip install gputil def get_gpu_memory(): try: gpus = GPUtil.getGPUs() # 获取所有可用的GPU for gpu in gpus: print(f"GPU {gpu.id}: {gpu.name}") print(f"Free GPU Memory: {gpu.memoryFree} MB") print(f"Used GPU Memory: {gpu.memoryUsed} MB") print(f"Total GPU Memory: {gpu.memoryTotal} MB\n") except Exception as e: print(f"Error: {e}") get_gpu_memory() # 初始化对象 """ GPU 0: NVIDIA GeForce RTX 3060 Free GPU Memory: 11277.0 MB Used GPU Memory: 846.0 MB Total GPU Memory: 12288.0 MB """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
方法三:使用 torch 获取
import torch # pip install torch def get_gpu_memory_torch(): try: if torch.cuda.is_available(): num_gpus = torch.cuda.device_count() # 获取GPU数量 for i in range(num_gpus): gpu = torch.cuda.get_device_properties(i) print(f"GPU {i}: {gpu.name}") print(f"Free GPU Memory: {torch.cuda.get_device_properties(i).total_memory - torch.cuda.memory_allocated(i)} bytes") print(f"Used GPU Memory: {torch.cuda.memory_allocated(i)} bytes") print(f"Total GPU Memory: {torch.cuda.get_device_properties(i).total_memory} bytes\n") else: print("No GPU available.") except Exception as e: print(f"Error: {e}") get_gpu_memory_torch() # 初始化对象 """ GPU 0: NVIDIA GeForce RTX 3060 Free GPU Memory: 12884377600 bytes Used GPU Memory: 0 bytes Total GPU Memory: 12884377600 bytes """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
三、内存管理
3.1、python是如何分配内存的?
Python内存管理器如何分配内存:根据对象的大小选择一块足够大的内存块,且将这块内存划分为两个部分,一个用于存储对象的数据,另一个用于存储对象的引用。
(1)在Python中,使用对象时自动分配内存,并当不再使用对象时自动释放内存。
(2)在Python中,对象都是动态类型(即声明变量时不需要指定数据类型,python会自动确定),且都是动态内存分配。3.2、python采用自动内存管理机制
Python通过" 引用计数 “和” 循环引用检测 "来自动管理内存(即垃圾回收器)。因此在一般情况下,程序员不需要过多关注内存释放。只有在处理大型数据集或需要及时回收内存的特殊情况下,才需要考虑手动内存管理。
自动内存管理机制:又叫垃圾回收器(garbage collector,gc)。负责定期地扫描并自动回收不再使用的内存和对象,使得开发者可以专注于程序逻辑,而不必担心内存管理问题。
(1)垃圾回收器:具体释放时机由解释器内部的策略控制,而不是由程序员明确控制的。
(2)垃圾回收器:不是严格按照预定的周期运行的,而是按照分代算法进行回收。垃圾回收器的触发因素:
- (1)手动垃圾回收:采用gc.collect()进行手动强制执行垃圾回收,用来解决在内存敏感时(例如:内存不足)加速释放不再需要的内存。
- 1、Python采用自动垃圾回收机制,在后台定期自动检测不再被引用的对象并释放它们的内存。自动垃圾回收与gc.collect()相比,其会有一个等待期(定期检测)。
- 2、在一般情况下,不需要手动使用 gc.collect(),因为Python的垃圾回收机制通常是足够智能的,会在合适的时候自动运行以释放不再需要的内存。
- 3、gc.collect()是加速自动垃圾回收的执行速度,而不是立即释放内存(但也几乎等同)。
- 4、gc.collect()本身也会引起额外的开销,故不建议频繁触发手动垃圾回收。
- (2)引用计数(reference count):垃圾回收机制会记录每个对象被其他对象所引用的次数。
- 1、引用计数从0开始;
- 2、当对象有新的引用指向它时,则引用次数 +1;当该对象指向它的引用失效时(如:
del 对象),则引用 -1。 - 3、当对象的引用计数为0时(如:
对象=None),则列入垃圾回收队列,等待自动垃圾回收,而不是立即释放内存。- 【del 对象】: 使用del语句将对象从命名空间中删除,内存将被立即释放,但Python的内存池机制导致不会立即释放内存给计算机,而是等待复用。
- 【对象=None】: 将对象设置为None,该对象的引用计数变为零,但不会立即释放,而是等待自动垃圾回收机制进行内存释放。
- (3)循环引用检测:若对象之间存在相互引用,则对象间将形成一个环状结构,使得引用计数不会降为零,因此内存无法被自动回收,导致内存泄漏。 分代回收
- 1、
引用链:用于跟踪对象之间的引用关系。当引用计数不为零,但对象之间形成循环引用时。 - 2、
分代回收(generation):将所有对象分为0,1,2三代。所有新创建的对象都是第0代对象;当某一代对象经过垃圾回收后仍然存活,就会升级到下一代。- 11、垃圾回收启动时,一定会扫描所有的0代对象。
- 22、如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。
- 33、当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。
- 1、
- (4)内存池:用于提高小内存对象的内存分配和释放效率。若频繁的进行小内存对象的分配和释放,可能导致内存碎片化和性能下降。
- 1、预分配固定大小的内存块:Python会根据对象的大小选择一个合适的内存块。每个内存块包含多个相同大小的小块。通常以8字节为一块。
- 2、内存块状态:内存块可以有不同的状态,包括空闲、已分配和已释放。Python会维护内存块的状态。
- 2、对象复用:如果内存块中包含已释放的小块,Python会首先复用这些小块以减少内存分配开销。这意味着相同大小的内存块可以多次分配和释放,而不需要每次都与操作系统进行交互。
- 3、延迟释放:对于不再使用的内存块不会立即释放回操作系统,而是将其保留在内存池中,以备将来再次使用(对象复用)。
优点:有助于减少频繁的内存分配和释放带来的性能开销。
缺点:可能导致内存泄漏,因为不再使用的内存块不会立即被操作系统回收。因此,开发者应避免长期保留对不再使用的对象的引用,以避免内存泄漏。
内存池机制(类别于金字塔模型): 图形化理解内存池

-
第-1层,第-2层:由操作系统特定的虚拟内存管理器控制(OS-specific virtual memory manger(VMM))
(第 -1 层):内核动态存储分配和管理
(第 -2 层):物理内存(ROM / RAM) + 二级存储ROM(只读存储器,Read-Only Memory):用于存储计算机或其他电子设备的固件和固定数据的存储设备。常用于存储计算机的引导程序(BIOS)。与RAM不同,ROM中的数据通常无法被修改。RAM(随机访问存储器,Random Access Memory):用于存储正在运行的程序和数据的临时内存存储设备。常用于计算机快速读取和写入数据。RAM是易失性的,断电时数据会丢失。二级存储(交换,Secondary Storage):指非易失性的大容量存储设备,如硬盘驱动器(HDD)或固态驱动器(SSD)。它用于长期存储数据、文件和操作系统。与RAM不同,二级存储的数据在断电时不会丢失。
-
第0层:由C标准库中底层分配器(underlying general-purpose allocator)的malloc、free进行内存分配和内存释放; -
第1层:当申请的内存 >256KB 时,内存分配由 Python 原生的内存分配器(raw memory allocator)进行分配,本质上是调用C标准库中的malloc、realloc等函数。 -
第2层:当申请的内存 <256KB 时,内存分配由 Python 对象分配器(object allocator)实施。 -
第3层:用户使用对象的直接操作层。特点:对于python内置对象(如:int、dict、list、string等),每个数据类型都有独立的私有内存池,对象之间的内存池不共享。如:int释放的内存,不会被分配给float使用。
3.3、python自动内存管理机制的缺点
- (1)内存泄漏:程序在分配内存后,无法正常释放不再使用的内存。最终可能导致程序运行变得缓慢或崩溃。 常见的几种情况如下:
- 如果程序分配了内存,但未在不再需要时释放它,内存将泄漏。
- 如果数据结构设计不正确,可能在不再需要时保留对对象的引用,导致内存泄漏。
- 如果循环引用或不正确的引用计数,可能发生内存泄漏。
- 如果打开文件却未在使用后正确关闭它们,内存将泄漏。
- (2)性能下降:需要同时分配与释放内存,程序可能会变慢。
- (3)内存不足:当程序需要的内存大于系统空间的内存,则会出现内存不足的问题。
3.4、python内存优化的方法
【python如何优化内存1】 + 【python如何优化内存2】
- 降低全局变量的使用率:全局变量会一直存在到程序结束,因此会始终占用内存。若非必要,请尽可能地使用局部变量,并在不需要时尽快将其释放。
- 避免创建非必要的对象:在Python中,创建对象是分配内存的一种方式。因此,尽量避免创建不必要的对象,并通过复用对象的方式来减少内存分配的次数。
- 手动释放非必要的对象:采用gc.collect()进行手动强制执行垃圾回收,用来在内存敏感时(例如:内存不足)立即释放不再需要的内存。
四、项目实战
4.1、查看对象的引用计数
import sys def create_objects(): obj1 = [1, 2, 3] # 创建对象 (obj1对象的引用次数=2) obj2 = [obj1, 1] # 创建对象 (obj2对象的引用次数=1) obj3 = {'a': 1, 'b': 2} # 创建对象 (obj3对象的引用次数=1) print(sys.getrefcount(obj1)) # 获取对象a的引用次数 print(sys.getrefcount(obj2)) # 获取对象a的引用次数 print(sys.getrefcount(obj3)) # 获取对象a的引用次数 ######################################################################### obj1 = None # 将不再使用对象的引用设置为None (obj2对象的引用次数=0) del obj2 # 将不再使用对象的引用设置为None (obj1对象的引用次数=0) print(sys.getrefcount(obj1)) # 获取对象a的引用次数 print(sys.getrefcount(obj3)) # 获取对象a的引用次数 return create_objects() # 创建对象 """################################################################### # 函数:sys.getrefcount(a): 返回对象a的引用计数。 # 注意: 函数内部会增加一次临时引用计数来获取对象的引用数,但该函数执行之后会自动减去临时引用计数,以保持对象的引用计数不变。 # # 【del 对象】: (1)使用del语句将对象从命名空间中删除,该对象的内存将被立即释放; # (2)但Python的内存池机制导致该部分占用的内存不会立即释放给计算机,而是等待复用。 # 【对象=None】: (1)将对象设置为None,该对象的引用计数变为零; # (2)但内存不会立即释放,而是等待自动垃圾回收机制进行内存释放。 ###################################################################"""- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4.2、内存池:设置垃圾回收的第 i 代阈值
import gc gc.set_threshold(700, 10, 5) """################################################################### # 函数功能:设置垃圾回收的第i代阈值。 # 函数简介:gc.set_threshold(threshold0, threshold1, threshold2) # 输入参数: # threshold0 是垃圾回收的第0代阈值。当0代的垃圾数量达到这个值时,触发0代的垃圾回收。 # threshold1 是垃圾回收的第1代阈值。当0代的垃圾数量达到 threshold0,且0和1两代垃圾的总数达到 threshold1,则触发两代的垃圾回收。 # threshold2 是垃圾回收的第2代阈值。当0和1两代垃圾的总数达到 threshold1,且同时0/1/2三代垃圾的总数达到 threshold2,则触发三代的垃圾回收。 ###################################################################"""- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.3、获取系统内存 + 获取进程(实际内存 + 峰值内存)
def memory_usage(): import psutil # (1)获取系统内存信息 mem_info = psutil.virtual_memory() total_memory = mem_info.total / (1024 ** 3) # 总内存大小(字节 - GB) used_memory = mem_info.used / (1024 ** 3) # 已使用内存(字节 - GB) free_memory = mem_info.available / (1024 ** 3) # 空闲的内存(字节 - GB) print(f"系统总内存RAM: {total_memory} GB") print(f"系统已占用内存: {used_memory} GB") print(f"系统未占用内存: {free_memory} GB") print("*" * 50) # (2)获取进程的内存信息 process = psutil.Process() # 创建一个进程对象 mem_info = process.memory_info() # 获取当前进程在RAM中的内存使用量 memory_usage = mem_info.rss / (1024 ** 3) # 表示进程在当前时刻的实际内存使用情况(字节 - GB) peak_memory = mem_info.peak_wset / (1024 ** 3) # 表示进程在任意时间点的内存使用的峰值(字节 - GB) print(f"当前进程实际占用内存: {memory_usage_mb:.8f} GB") print(f"当前进程最大占用内存: {peak_memory_mb:.8f} GB") return memory_usage, peak_memory if __name__ == "__main__": memory_usage() # 创建对象 """ 系统总内存RAM: 63.74748229980469 GB 系统已占用内存: 8.997417449951172 GB 系统未占用内存: 54.750064849853516 GB ************************************************** 当前进程实际占用内存: 0.01511765 GB 当前进程最大占用内存: 0.01512146 GB """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
4.4、手动释放内存
"""######################################################################## # 函数: gc.collect(): 手动垃圾回收管理 # 功能: # 若使用gc.collect(): (1)不能保证立即释放内存,但可以加速自动垃圾回收的执行速度。 # (2)其本身也会引起额外的开销,不建议频繁触发手动垃圾回收。 # 若不使用gc.collect(): 垃圾回收器是自动定期检测并回收内存,但有一定延迟(定期)。 ######################################################################## # 【del 对象】: (1)使用del语句将对象从命名空间中删除,该对象的内存将被立即释放; # (2)但Python的内存池机制导致该部分占用的内存不会立即释放给计算机,而是等待复用。 # 【对象=None】: (1)将对象设置为None,该对象的引用计数变为零; # (2)但内存不会立即释放,而是等待自动垃圾回收机制进行内存释放。 ########################################################################""" import gc import numpy as np def memory_usage(): """用于获取当前程序的内存占用情况(单位:MB)""" import psutil process = psutil.Process() # 创建一个进程对象,用于获取当前程序的内存信息。 mem_info = process.memory_info() # 获取当前进程在RAM中的内存使用量 memory_usage = mem_info.rss / (1024 ** 2) # 表示进程在当前时刻的实际内存使用情况(字节 - MB) peak_memory = mem_info.peak_wset / (1024 ** 2) # 表示进程在任意时间点的内存使用的峰值(字节 - MB) return memory_usage, peak_memory # 1 TB = 1024 GB = [1024^2] MB = [1024^3] KB = [1024^4] Bytes = [1024^4 x 8] bits if __name__ == "__main__": # (1)查看系统初始的内存使用情况 system_memory, peak_memory = memory_usage() print(f"系统初始的内存使用情况(MB): {system_memory:.2f}") ###################################################### # (2)创建一个数组 array = np.random.randint(0, 100, size=(400, 500, 600)) print(f"总内存使用情况(MB): {memory_usage()[0]:.2f}, {memory_usage()[1]:.2f}") ###################################################### # (3)查看系统进程的内存使用情况 array[array <= 2800] = 0 # 灰度强度滤波 print(f"总内存使用情况(MB): {memory_usage()[0]:.2f}, {memory_usage()[1]:.2f}") ###################################################### # (4)查看(手动垃圾回收)系统进程的内存使用情况 array = None gc.collect() # 手动垃圾回收:加速自动垃圾回收 print(f"总内存使用情况(MB): {memory_usage()[0]:.2f}, {memory_usage()[1]:.2f}") """ 系统初始的内存使用情况(MB): 29.73 总内存使用情况(MB): 487.60, 487.61 总内存使用情况(MB): 487.61, 602.06 总内存使用情况(MB): 29.85, 602.06 """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
-
相关阅读:
基于若依ruoyi-nbcio增加flowable流程待办消息的提醒,并提供右上角的红字数字提醒(三)
C# 调用 Rust 来删除文件夹 ( 包含大量软链接 和 无效链接)
HTML期末学生大作业 基于HTML+CSS+JavaScript通用的后台管理系统ui框架模板
C++智能指针[上]
在二叉树中找到两个节点的最近公共祖先
java计算机毕业设计web企业档案管理系统MyBatis+系统+LW文档+源码+调试部署
`算法知识` 线段树
【OpenCV】在MacOS上使用OpenCvSharp
[从零学习汇编语言] - 内中断
计算机网络 MAC地址表管理
- 原文地址:https://blog.csdn.net/shinuone/article/details/133982613