-
工作中几个问题的思考
对于需要并行多公司并行处理的任务,方案是什么?
多线程、并行流、并发库(ExecutorService、Futrue、Callable),分布式计算- 1
(1)按照公司ID分片
(2)按照业务类型分片处理某类任务,多个线程同时处理,拿到最先处理的完成接口
(1) 采用 CompletableFuture.anyOf(future1, future2, future3), 注意CompletableFuture使用自定义线程池,默认是ForkJoinPool线程池;案例
public class CompletableFutrueAnyOf { public static void main(String[] args) { ExecutorService executorService = Executors.newFixedThreadPool(3); CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> { try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { throw new RuntimeException(e); } return "futrue1 执行结果"; },executorService); CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> { try { TimeUnit.SECONDS.sleep(6); } catch (InterruptedException e) { throw new RuntimeException(e); } return "futrue2 执行结果"; },executorService); CompletableFuture<String> future3 = CompletableFuture.supplyAsync(() -> { try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { throw new RuntimeException(e); } return "futrue3 执行结果"; },executorService); CompletableFuture<Object> objectCompletableFuture = CompletableFuture.anyOf(future1, future2, future3); try { System.out.println(objectCompletableFuture.get()); } catch (InterruptedException e) { throw new RuntimeException(e); } catch (ExecutionException e) { throw new RuntimeException(e); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
(2) Executor框架和Future接口实现
如果同时处理多个任务,只需要提交多个任务到线程池中即可。第一个完成的任务的结果会被get()方法返回在并发查询某一类数据时,流量会全部打到存储,怎么优化该场景
(1)mybatis缓存,此方案只针对使用mybatis当作ORM框架,一级缓存是SqlSession级别的缓存
二级缓存:跨SqlSession级别,通常用于单表、多表会有脏数据
(2)缓存工具,比如redis,针对相同时间内的,相同查询条件,可以直接从结果返回数据;但是也有局限性:(比如分页),或者定时缓存到redis、后续直接从redis查,类似于热点数据缓存
(3)重复请求场景:前端限流,后端限流
(4)数据库层级的优化:索引、分片、查询语句优化、水平/垂直扩展等Java ThreadPoolExecutor配置时,需要配置corePoolSize,maximumPoolSize、queueCapacity、以及拒绝策略,请描述随着线程池提交任务的增加,线程池创建线程的策略;
execute 执行原理
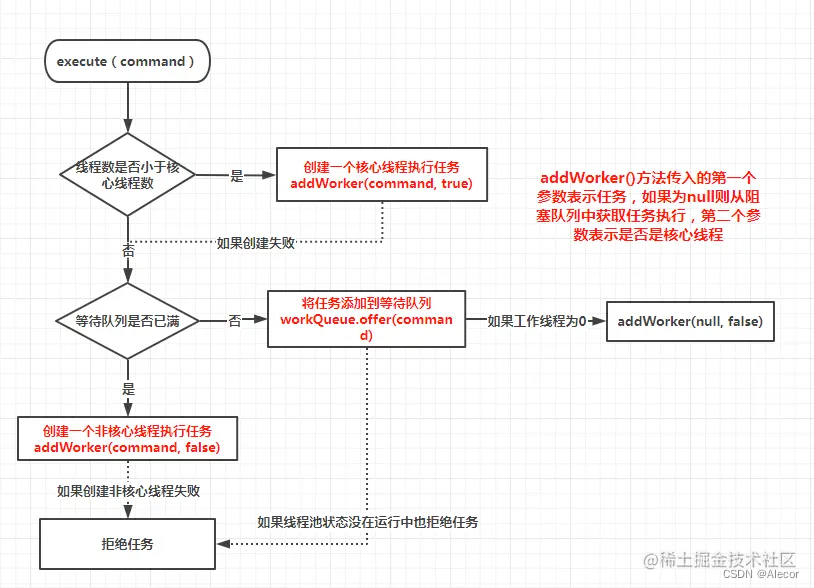
(1)提交任务后会首先进行当前工作线程数与核心线程数的比较,如果当前工作线程数小于核心线程数,则直接调用 addWorker() 方法创建一个核心线程去执行任务;
(2)如果工作线程数大于核心线程数,即线程池核心线程数已满,则新任务会被添加到阻塞队列中等待执行,当然,添加队列之前也会进行队列是否为空的判断;
(3)如果线程池里面存活的线程数已经等于核心线程数了,且阻塞队列已经满了,再会去判断当前线程数是否已经达到最大线程数 maximumPoolSize,如果没有达到,则会调用 addWorker() 方法创建一个非核心线程去执行任务;
(4)如果当前线程的数量已经达到了最大线程数时,当有新的任务提交过来时,会执行拒绝策略
整个顺序就是:优先核心线程、阻塞队列次之,最后非核心线程。addWorker方法
可以看到execute中最关键的就是addWorker方法,它接受两个参数:
第一个参数是要执行的任务,如果为null那么会从等待队列中拉取任务;
第二个参数是表示是否核心线程,用来控制addWorker方法流程的;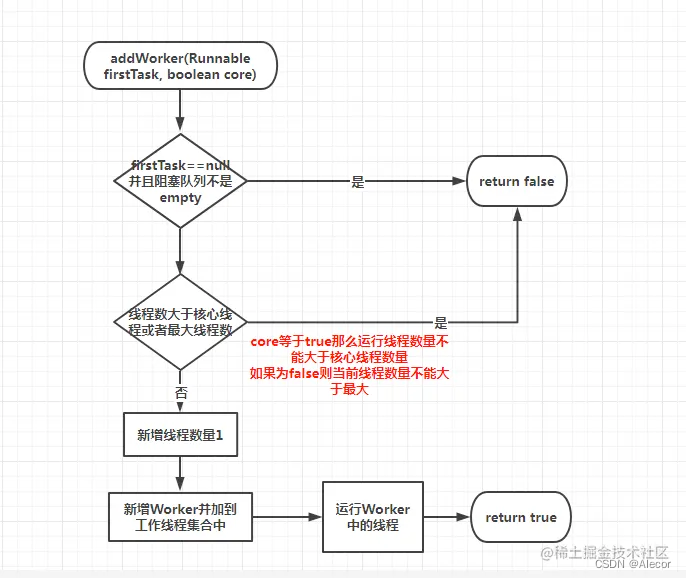
线程池调用execute提交任务—>创建Worker(设置属性thead、firstTask)—>worker.thread.start()—>实际上调用的是worker.run()—>线程池的runWorker(worker)—>worker.firstTask.run();
-
相关阅读:
智慧屏内核崩溃问题分析
C++中类的六个默认成员函数
TypeScript - 枚举类型 -字符型枚举
2.python工厂模式
LeetCode[145]二叉树的后序遍历
测试修改和删除用户功能、测试查询功能
胡说八道(24.6.11)——数电及STM32
55 黑客攻击
【Java 进阶篇】JavaScript二元运算符详解
从入门到进阶,Python程序员必看的6本书籍!
- 原文地址:https://blog.csdn.net/Alecor/article/details/133979260
