-
springboot缓存篇之mybatis一级缓存和二级缓存
前言
相信很多人都用过
mybatis,这篇文章主要是介绍mybatis的缓存,了解一下mybatis缓存是如何实现,以及它在实际中的应用一级缓存
什么是
mybatis一级缓存?我们先看一个例子:@GetMapping("/list") public Result<Void> listGoods(){ GoodsExample goodsExample = new GoodsExample(); goodsMapper.selectByExample(goodsExample); goodsMapper.selectByExample(goodsExample); return Result.okWithNullData(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上面这个例子有两个相同的查询方法,我们看看日志
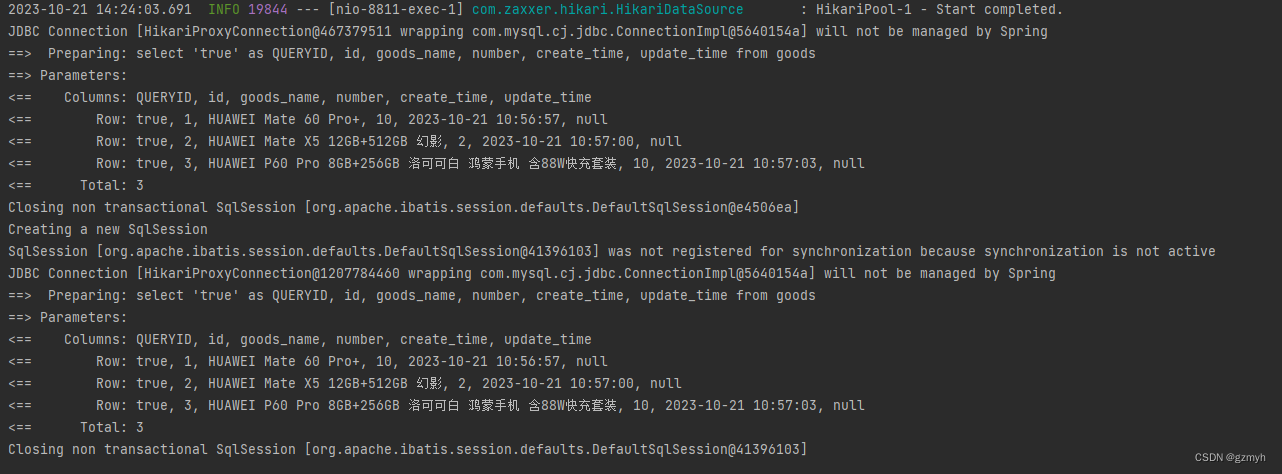
我们看到即使两个查询方法一样,它也查询了两次数据库。
mybatis为了优化这种情况,既然两次查询语句一样,那么就将第一次结果缓存起来,那么第二次查询就不用再查数据库。其实要实现这个功能也是挺简单的,你只需在方法上加上
@Transactional即可@Transactional public Result<Void> listGoods(){ // 代码省略 }- 1
- 2
- 3
- 4
再看看运行日志
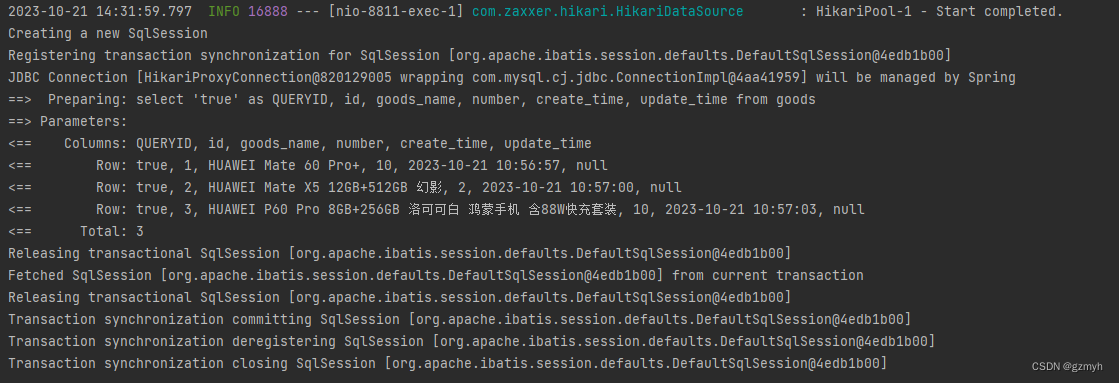
我们可以看到只有一次查询,正常情况下每发起一次查询就会创建一个
SqlSession,查询结束了,SqlSession就会被销毁。如果开启了事务,那么就可以为多个查询创建一个共同的SqlSession,那么在同一个事务中,如果说存在相同的查询,那么后面的查询都会直接拿第一次查询的结果。这么看来,
mybatis的一级缓存还不错,但现实告诉你如果你的项目比较大,比较复杂,比如分布式,如果使用mybatis的一级缓存,很容易就踩坑了,因此一些大公司都会要求禁用它,而使用redismybatis是默认开启一级缓存的,如果要关闭,可以在配置文件这样配置:# 默认值是session,如果要关闭,设置成statement即可 mybatis.configuration.local-cache-scope=statement- 1
- 2
为什么说很容易踩坑呢?
其实简单来说就是第一次缓存的结果,被另外的线程更新了,那么如果后面再拿到的数据就是脏数据。
总之禁用它,使用
redis代替它准没错二级缓存
假如说现在有100个请求在同一时间请求列表数据,就上面那段代码而言,正常情况下要查询200次数据库
@GetMapping("/list") public Result<Void> listGoods(){ GoodsExample goodsExample = new GoodsExample(); // 第一次查询 goodsMapper.selectByExample(goodsExample); // 第二次查询 goodsMapper.selectByExample(goodsExample); return Result.okWithNullData(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
如果开启了一级缓存,那么也要查询100次,因此
mybatis就提供了二级缓存二级缓存的设置也很简单,只需在
Mapper.xml文件中加上cache标签即可DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.demo.dao.mapper.GoodsMapper"> <cache>cache> <resultMap id="BaseResultMap" type="com.example.demo.domain.entity.Goods"> <id column="id" jdbcType="BIGINT" property="id" /> <result column="goods_name" jdbcType="VARCHAR" property="goodsName" /> <result column="number" jdbcType="INTEGER" property="number" /> <result column="create_time" jdbcType="TIMESTAMP" property="createTime" /> <result column="update_time" jdbcType="TIMESTAMP" property="updateTime" /> resultMap>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
当我们再次请求list接口时,看看控制台的日志
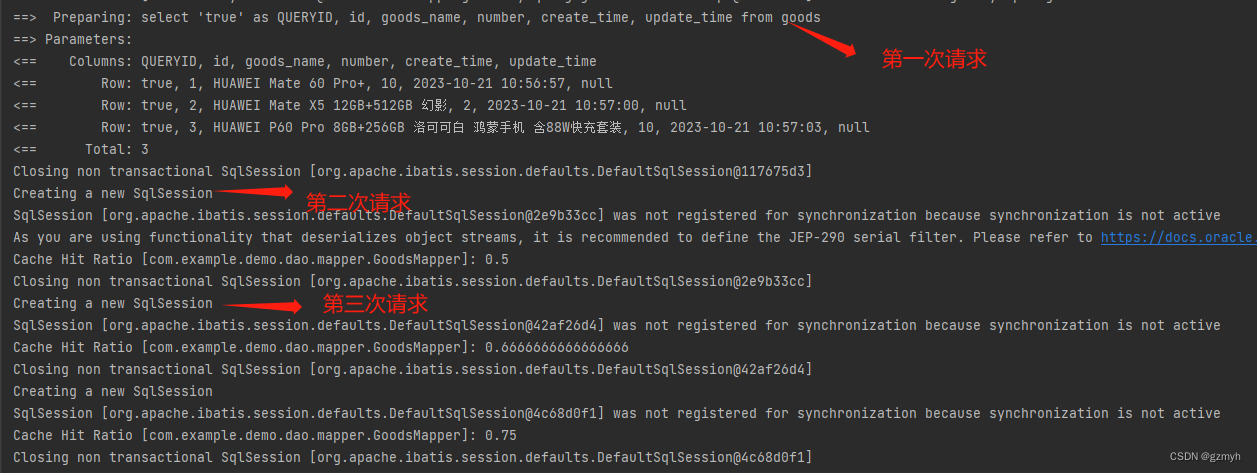
我们可以看到除了第一次查询要查询数据库外,后面的几次查询列表都是直接从缓存中拿数据
mybtais二级缓存看上去好像挺好用的,但现实当中还是给你来个暴击,最好不要用。我们要搞清楚它的作用范围,它时针对命名空间的,就比如说上面提到的
mapper.xml,如果说你部署在一个节点,那么就只有一个mapper.xml,缓存的结果直接从这个空间下获取即可,但很多时候随着业务的增大可能要部署多个节点,那每个节点都有自己的mapper.xml,而每个节点更新缓存只会更新自己节点的mapper.xml,因此可能会出现下面的问题客户端有个请求过来,从A节点获取列表数据的,如果有缓存查缓存,没有就查数据库,比如说meta 60产品数据,它的价格时6000元
客户端再发个请求过来,从B节点获取列表数据的,如果有缓存查缓存,没有就查数据库,比如说meta 60产品数据,它的价格时6000元
这是没有问题的,但现在管理人员调整了产品价格,从6000改成5000,他的这次更新请求刚好请求了B节点(客户端请求节点是随机的),此时B节点缓存刷新了
那现在是不是会出现这样的情况,有些用户看到的商品价格是6000(刚好访问了A节点,直接读取缓存),有些用户看到的价格却是5000(请求了B节点,B节点会重新查库)
所以
mybtais二级缓存慎用! -
相关阅读:
RNN 浅析
大数据平台功能
大数据必学Java基础(六十六):BlockingQueue常见子类
chmod - R递归修改文件权限
开发常用指令
智能家居生态:华为、小米各异
ML/DL2022面试必备500知识点-《机器和深度学习纲要》免费分享
【学习笔记】图的连通性与回路
【附源码】计算机毕业设计JAVA成绩分析系统
Java程序员学习资料分享,等你来收藏!
- 原文地址:https://blog.csdn.net/gzmyh/article/details/133962866