-
Linux入门攻坚——4、shell编程初步、grep及正则表达式
bash的基础特性(续):
1、提供了编程环境:
编程风格:过程式:以指令为中心,数据服务于执行;对象式:以数据为中心,指令服务于数据shell编程,编译执行。基本结构:数据存储:变量、数组,表达式,语句。(命令的堆砌)
shell脚本:文本文件
#!/bin/bash
#!/usr/bin/python
#!/usr/bin/perlshebang,告诉cpu解释器是什么,由谁来解释其后的内容。
magic number:魔数 :#!
第一个shell脚本:first.sh
- #!/bin/bash
- #
- cat /etc/fstab
- wc -l /etc/fstab
shell脚本就是一个文本文件,如何运行呢?就靠第一行,来告诉cpu使用/bin/bash来执行。所以下面的命令都是bash运行的。就像我们在bash交互界面输入cat,然后输入wc命令一样,顺序执行,将结果输出。
运行:在当前目录下直接运行first.sh:提示

linux不像window,默认会先找当前目录,而是根据PATH环境变量的值,顺序查找first.sh。其值:

因为并没有当前目录,我的当前目录是~/myscripts/,所以要给定明确的路径,如:./firsht.sh或绝对路径:~/myscripts/first.sh

上一篇学过文件权限时,提到过,创建的文件权限默认是没有执行权限x的,所以这里提示没有权限执行。增加执行权:

执行:

也可以不为文件赋执行权限,而是手动启动,即执行:bash first.sh,即不使用shebang,而是我们手动指定了解释器。
变量:命名的内存空间。
变量类型:数据存储格式、存储空间大小、能参与的运算、数据的表示范围。字符和数值——整型、浮点型
编程语言:强类型---定义变量时必须指定类型、弱类型---shell是弱类型,类型隐式转换,变量无需事先定义可直接调用。
逻辑运算:结果true、false。与&&、或||、非!、异或
短路运算:
与:第一个为0,结果必为0,第一个为1,第二个必须参与运算。
或:第一个为1,结果必定为1,第一个为0,第二个必须参与运算。


Linux上文本处理三剑客:
grep:文本过滤(模式:pattern)工具 grep、egrep、fgrep
sed:stream editor,文本编辑工具
awk:Linux上的实现gawk,文本报告生成器。grep:Global search REgular expression and Print out theline
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查:打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
REGEXP:由一类特殊字符及文本字符所编写的模式,其中有些字符不表示字符字面意义,而表示控制或通配的功能。
分两类:基本正则表达式:BRE;扩展正则表达式:ERE,grep -E,egrep正则表达式引擎:
grep [OPTIONS] PATTERN [FILE...]
--color=auto:对匹配到的文本着色显示
-v : 反向匹配,显示不匹配的行
-i : 匹配时忽略大小写
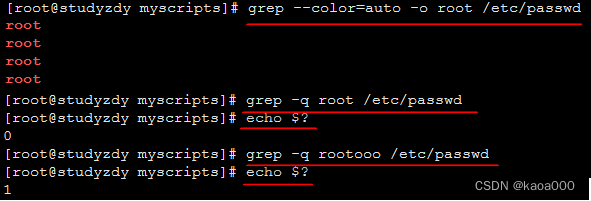
-o : 仅显示匹配的字串
-q : 静默模式,不输出任何信息
-A #: after,匹配行及后#行
-B # :before,匹配行及前#行
-C # :context,前后各#行
-E : 使用ERE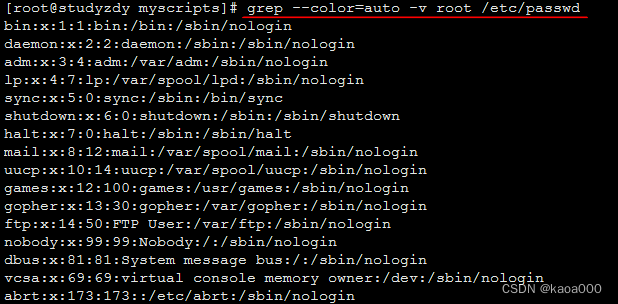

基本正则表达式元字符:
字符匹配:
. :匹配任意单位字符;[] :匹配指定范围内的任意单个字符;[^]:匹配指定范围外的任意单个字符;[:digit:]、[:lower:]、[:upper:]、[:alpha:]、[:alnum:]、[:punct:]、[:space:]、
匹配次数:用在要指定次数的字符后面,指定前面的字符要出现的次数;工作于贪婪模式。
* :匹配前面的字符任意次,仅表示次数。grep “x*y” ——abxy,xay,都可以匹配
.* : 任意长度的任意字符
\? :匹配其前面的字符0或1次。
\+ :匹配前面字符至少1次。
\{m\} : 匹配前面的字符m次。grep '[:alpha:]\{3\}y'
\{m,n\} : 匹配前面的字符至少m次,至多n次。
\{0,n\},匹配前面字符至多n次;\{m,\},匹配前面字符至少m次。
位置锚定:
^ : 行首锚定。用于模式的最左侧 ^root
$ : 行尾锚定。用于模式的最右侧 root$
^PATTERN$ :用于模式匹配整行, ^$:空行,^[[:space:]]*$:空白行
\< 或 \b: 词首锚定,用于单词模式的左侧:
\> 或 \B: 词尾锚定,用于单词模式的右侧:
\
分组:
: 将一个或多个字符捆绑在一起,作为一个整体进行处理;
注意:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量命名方式为:\1,\2,\3...
\1 :从左侧起,第一个左括号以及与之匹配右括号之间的模式所匹配到的字符;
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身。egrep及扩展的正则表达式:
egrep [OPTIONS] PATTERN [FILE...]
扩展正则表达式的元字符:
字符匹配:. 、[]、 [^]
次数匹配:*:任意次、?:0或1次、+:1次或多次、{m}:m次、{m,n}:至少m,至多c次。
锚定:^、$、\< 或\b、\>或\b、
分组:();后向引用,\1,\2\3...
或者:a|b 如: C|cat : C或cat,(C|c)at:Cat或catfgrep:不支持正则表达式搜素。
bash基础特性(续)
变量类型:
bash中的变量的种类:
根据变量的生效范围等标准:
本地变量:生效范围为当前shell进程,对当前shell之外的其他shell进程,包括当前shell的子shell进程均无效。
环境变量:生效范围为当前shell进程及其子进程。declare -x name=value
局部变量:生效范围为当前shell进程中某代码片段(通常指函数)。
位置变量:$1,$2,$3...来表示,用于让脚本在脚本代码中调用通过命令行传递给他的参数。
特殊变量:$?,$0,$*,$@,$#本地变量:
变量赋值:name='value'
value:1)可以是直接字串---name="username" ;2)变量引用---name="$username";3)命令引用---name=`COMMAND`,注意是反引号,name=$(COMMAND)
变量引用:${name},$name
" ":弱引用,其中的变量引用会被替换为变量值;
' ' :强引用,其中的变量引用不会被替换为变量值,保持原字符串。
显示已定义的变量:set
销毁变量:unset name环境变量:
变量声明、赋值:
export name=value
declare -x name=value
变量引用:$name,${name}
显示所有环境变量:export 、 env、 printenv
销毁:unset name
bash有许多内建的环境变量:PATH、SHELL、UID、HISTSIZE、HOME、PWD、OLD、HISTFILE、PS1、变量命名法则:不能使用关键字;只能使用字母、数字及下划线,且不能以数字开头;见名知义;
只读变量:readonly name ; declare -r name ;不能修改不能unset销毁
位置变量:接收参数。
$* :传递给脚本的所有参数;
$@:传递给脚本的所有参数;
$#:传递给脚本的所有参数的个数;
shift #: 换岗操作bash的配置文件:
按生效范围划分,两类:
全局配置:
/etc/profile ,以及/etc/profile.d/*.sh
/etc/bashrc
个人配置:
~/.bash_profile
~/.bashrc
按功能划分,两类:并不绝对
profile类:为交互式登录的shell提供配置
全局:/etc/profile, /etc/profile.d/*.sh
个人:~/.bash_profile
功用:1)用于定义环境变量;2)运行命令或脚本;
bashrc类:为非交互式登录的shell提供配置
全局:/etc/bashrc
个人:~/.bashrc
功用:1)定义命令别名;2)定义本地变量;shell登录:
交互式登录:直接通过终端输入账号密码登录;使用“su - UserName”或“su -l UserName”
读取顺序: /etc/profile --> /etc/profile.d/*.sh --> ~/.bash_profile --> ~/.bashrc --> /etc/bashrc
非交互式登录:su UserName;图形界面下打开的终端;执行脚本;
读取顺序: ~/.bashrc --> /etc/bashrc --> /etc/profile.d/*.shbash中的算术运算:+、-、*、/、%、**
实现算术运算:1)let var=算术表达式;2)var=$[算术表达式] ;3)var=$((算术表达式));4)var=$(expr arg1 arg2 arg3 ...) ,注意有些符号要转义;
bash内建的随机数生成器:$RANDOM
增强型赋值:*=,/=,%=,+=,-+ 如:let count+=1;自增、自减:let var++,let var--条件测试:专用的测试表达式需要由测试命令辅助完成测试过程:
测试命令:
test EXPRESSION
[ EXPRESSION ]
[[ EXPRESSION ]]
注意:EXPRESSION前后必须有空白字符。bash的测试类型:
数值测试:-gt:大于; -ge:大于等于; -eq:等于; -ne:不等于; -lt:小于; -le:小于等于
字符串测试:==/=:等于; >:大于;<:小于; !=:不等于; =~:左侧字符串能否被右侧的PATTERN所匹配; -z “STRING”:测试字符串是否为空,空为真;-n “STRING”:测试字符串是否不空,不空为真;
注意:用于字符串比较时用到的操作数都应该使用引号。
文件测试:man bash
存在性测试
-a FILE:文件存在
-e FILE :文件存在则为真,不存在为假
存在性及类别测试:
-b FILE:存在且为块设备
-c FILE:存在且为字符设备
-d FILE:存在且为目录
-f FILE:存在且为普通文件
-h FILE或-l:存在且为符号链接
-p FILE:存在且为命名管道
-S FILE:存在且为套接字
文件权限测试:
-r FILE:存在且可读
-w FILE:存在且可写
-x FILE:存在且可执行
文件特殊权限测试:
-g FILE:存在且拥有sgid权限
-u FILE:存在且拥有suid权限
-k FILE:存在且拥有sticky权限
文件大小测试:
-s FILE:存在且非空
文件打开性测试:
-t fd:fd表示的文件描述符是否已经打开且与终端相关
-N FILE:文件自上一次被读取之后是否被修改过
-O FILE:当前用户是否为文件属主
-G FILE:当前有效用户是否为文件的属组
双目测试:
FILE1 -ef FILE :1与2是否指向同一个设备上的相同inode
FILE1 -nt FILE :1是否新于2
FILE1 -ot FILE :1是否旧于2组合测试条件:
逻辑运算:两种方式:
1)CMD1&&CMD2 、CMD1||CMD2、 !CMD ;
2)EXPRESION1 -a EXPRESION2、EXPRESION1 -o EXPRESION2、bash自定义退出状态码:exit [n]
注意:脚本中一旦遇到exit命令,脚本会立即终止,终止退出状态取决于exit命令后面的数字;如果未给脚本指定退出状态码,整个脚本的退出状态码取决于脚本中执行的最后一条命令的状态码。vim编辑器
vi:Visual Interface:文本编辑器:行编辑器--sed、全屏编辑器--nano
vi是一个模式化的编辑器:
基本模式:编辑模式---命令模式 ; 输入模式: ;末行模式:内置的命令行接口 ;
打开文件:vim [option] file... ;
+# :打开文件后,直接让光标处于第#行的行首;
+/PATTERN:打开文件后,直接让光标处于第一个被PATTERN匹配到的行的行首;
模式转换:
编辑模式 --> 输入模式
i :insert,在光标所在处输入;
a:append,在光标所在处后面输入;
o:在当前光标所在行的下方打开一个新行;
I:在当前光标所在行行首输入
A:在当前光标所在行行尾输入
O:在当前光标所在行上方打开一个新行输入
c:改变命令,删空并输入
C:输入模式 --> 编辑模式 : ESC
编辑模式 --> 末行模式 : :
末行模式 --> 编辑模式 : ESC
关闭文件:
:q :退出; :q!:强制退出,丢弃做出的修改; :qw :保存退出;:x : 保存退出
:w /PATH/TO/SOMEWHERE :另存为; ZZ:保存退出;光标跳转:
字符间跳转:h左,j下,k上,l右
#COMMAND:跳转由#指定的个数的字符;如7j,向下7行
单词间跳转:
w:下一个单词词首;e:当前或下一个单词的词尾;b:当前或前一个单词词首;
#COMMAND:由#指定一次跳转的单词数
行首行尾跳转:
^:行首第一个非空白字符; 0:行首; $:行尾
行间跳转:
#G:跳转至#行; G:最后一行; 1G,gg:第一行
句间移动: ) ; (
段落间移动:};{
vim的编辑命令:
字符编辑:
x:删除光标处的字符; #x:删除光标处起始的#个字符;
xp:交换光标所在处及其后面字符的位置。
替换命令:r,replace
r:替换光标所在处的字符; #r:替换光标开始后的#个字符
删除命令:
d:删除命令,可结合光标跳转字符,实现范围删除,如的d$,删到行尾
d$、d^、d0、dw、de、db、#COMMAND
dd:删除光标所在的行; #dd,删多行
粘贴命令:p,put,paste
p:缓冲区中存储的如果为整行,则粘贴至当前光标所在行的下方;否则,粘贴至当前光标所在处后面;
P:缓冲区中存储的如果为整行,则粘贴至当前光标所在行的上方;否则,粘贴至当前光标所在处前面;
复制命令:y,yank
y:复制,工作行为类似于d命令:
y$、y0、y^、 ye、yw、yb、 #COMMAND
yy:复制行; #yy:复制多行;
改变命令:c,change
c:修改,编辑模式-->输入模式
c$、c0、c^、 ce、cw、cb、 #COMMAND
cc:删除并输入新内容; #cc:删除多行并输入新内容
可视化模式:
v:按字符选定; V:按行选定; 经常结合编辑命令:d ,c, y
撤销此前的编辑:
u(undo):撤销此前的操作; #u:撤销此前#次操作
撤销此前的撤销:Ctrl + r
重复前一个编辑操作:. 点号
翻屏操作:
Ctrl+f : 向尾部翻一屏;
Ctrl+b:向首部翻一屏;
Ctrl+d :向尾部翻半屏;
Ctrl+u:向首部翻半屏;
vim中的末行模式:
(1)地址定界; —— :start_pos,end_pos
#:具体第#行
#,#:从左侧#表示行起始,到右侧#表示行结尾
#,+#:从左侧#表示行起始,加上右侧#表示的行数
.:当前行
$:最后一行 .,$-1
%:全文,相当于1,$
/pat1/, /pat2/ : 从第一次被pat1模式匹配的行开始,到第一次被pat2模式匹配的行结尾
使用方式:
后跟一个编辑命令: d、y、w 、r
w /PATH/TO/SOMEWHERE :将范围内的行另存至指定文件;
r /PATH/TO/SOMEWHERE :在指定位置插入指定文件中的所有内容
(2)查找
/PATTERN :从当前光标所在处向文件尾部查找;
?PATTERN :从当前光标所在处向文件首部查找;
n、N,同方向、反方向跳转
(3)查找并替换
s:在末行模式下完成查找替换操作
s/要查找的内容/替换为的内容/修饰符:要查找的内容可使用模式;替换的内容不能使用模式,但可以使用\1,\2,...等向后引用符号,还可以使用“&”引用前面查找时查找到的整个内容;
修饰符:i:忽略大小写;g:全局替换,默认情况下,每行只替换第一次出现;
:.,$s/r..t/R\1T/g
查找替换中的分隔符/可替换为其他字符,如:s@@@、s###
多文件模式:
vim FILE1 FILE2 FILE3 ...
:next 下一个文件; :prev 前一个; : first,第一个; :last,最后一个
:wall 保存所有; :qall,退出所有。
窗口分隔模式:
vim -o|-O FILE1 FILE2 FILE3 ... :-o,水平分隔;-O,垂直分隔
在窗口间切换:Ctrl+w,Arrow
单文件窗口分割:Ctrl+w,s:split,水平分隔; Ctrl+w,v:vertical,垂直分隔定制vim的工作特性:
配置文件:
全局:/etc/vimrc
个人:~/.vimrc
末行:当前vim进程有效
(1)行号:set number,set nu,显示行号;setnonumber,set nonu,取消行号
(2)括号匹配:set showmatch,set sm 匹配;set nosm,取消匹配
(3)自动缩进:set ai ,启用;set noai 取消
(4)高亮搜索:set hlsearch ,启用;set nohlsearch,取消
(5)语法高亮:syntax on,启用;syntax off,取消
(6)忽略字符的大小写:set ic,忽略;set noic,不忽略 -
相关阅读:
【C++】哈希思想的应用——位图、布隆过滤器和哈希切割
Spring Cloud Alibaba+saas企业架构技术选型+架构全景业务图 + 架构典型部署方案
ASPICE标准快速掌握「5.2. ASPICE与V模型」
【pytorch】有关nn.EMBEDDING的简单介绍
[计算机提升] 文件的创建与删除原理
【C++风云录】精益求精:探索C++开发中的性能优化艺术
使用Redis实现文章阅读量、收藏、点赞数量记录功能
经典算法之快速排序
nginx启动命令
maven打包时和 deploy时候将不会 依赖包含在生成的项目 jar中方法
- 原文地址:https://blog.csdn.net/kaoa000/article/details/133861840