-
9.构造器与垃圾收集器 对象的前世今生
9.1 对象与变量的生存空间
栈与堆:生存空间
在Java中,程序员会在乎内存中的两种区域:对象的生存空间堆(heap)和方法调用及变量的生存空间(stack)。当Java虚拟机启动时,它会从底层的操作系统取得一块内存,并以此区段来执行Java程序。至于有多少内存,以及你是否能够调整它都要看Java虚拟机与平台的版本而定。但通常你对这些事情无法加以控制。如果程序设计得不错的话,你或许也不太需要在乎。
我们知道所有的对象都存活于可垃圾回收的堆上,但我们还没看过变量的生存空间。而变量存在于哪一个空间要看它是哪一种变量而定。这里说的“哪一种”不是它的类型,而是实例变量或局部变量。后者这种区域变量又被称为栈变量,该名称已经说明了它所存在的区域。

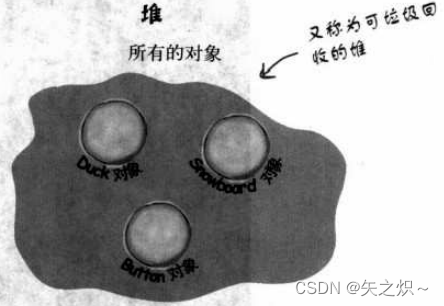
实例变量是被声明在类而不是里面。它们代表每个独立对象的“字段”(每个实例都能有不同的值)。实例变量存在于所属的对象中
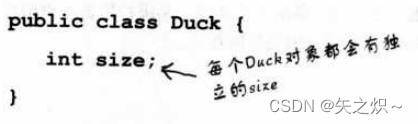
局部变量和方法的参数都是被声明在方法中。它们是暂时的,且生命周期只限于方法被放在栈上的这段期间(也就是方法调用至执行完毕为止)

9.2 stack上的方法
方法会被堆在一起
当你调用一个方法时,该方法会放在调用栈的栈顶。实际被堆上栈的是堆栈块,它带有方法的状态,包括执行到哪一行程序以及所有的局部变量的值。
栈顶上的方法是目前正在执行的方法(先假设只有一个,第14章有更多的说明)。方法会一直待在这里直到执行完毕,如果foo()方法调用bar()方法则bar()方法会放在foo()方法的上面。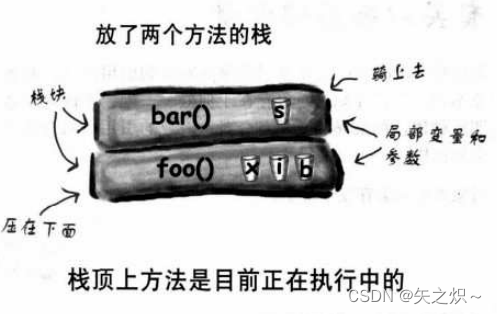
stack的情境
以下有3个方法,第一个方法在执行过程中会调用第二个方法,第二个会调用第三个。每个方法都在内容中声明一个局部变量,而go()方法还有声明一个参数(这代表go()方法有两个局部变量)

1.某段程序代码调用了doStuff()使得doStuff()被放在stack最上方的栈块中

2.doStuff()调用go(),go()就被放在栈顶

3.go()又调用crazy()使得crazy()现在处于栈顶

4.当crazy()执行完成后,它的堆栈快就被释放掉。执行就回到了go()

9.3 局部变量的空间
有关对象局部变量
要记得非primitive的变量只是保存对象的引用而已,而不是对象本身。你已经知道对象存在于何处——堆。不论对象是否声明或创建,如果局部变量是个对该对象的引用,只有变量本身会放在栈上。
对象本身只会存在于堆上。

9.4 实例变量的空间
当你要新建一个CellPhone()时,Java必须在堆上帮CellPhone找一个位置。需要足以存放该对象所有实例变量的空间。实例变量存在于对象所属的堆空间上。
对象的实例变量的值是存放于该对象中。如果实例变量全都是primitive主数据类型的,则Java会依据primitive主数据类型的大小为该实例变量留下空间。int需要32位,long需要64位,依此类推。Java并不在乎私有变量的值,不管是32或32,000,000的int都会占用32位。

但若实例变量是个对象呢?如果CellPhone对象带有一个Antenna对象呢?也就是说CellPhone带有Antenna类型的引用变量呢?当一个新建对象带有对象引用的变量时,此时真正的问题是:是否需要保留对象带有的所有对象的空间?不是这样的。无论如何,Java会留下空间给实例变量的值。但是引用变量的值并不是对象本身,所以若CellPhone带有Antenna,Java只会留下Antenna引用量而不是对象本身所用到的空间。

那么Antenna对象会取得在堆上的空间吗?我们得先知道Antenna对象是在何时创建的。这要看实例变量是如何声明的。如果有声明变量但没有给它赋值,则只会留下变量的空间:
private Antenna ant;
直到引用变量被赋值一个新的Antenna对象才会在堆上占有空间:
private Antenna ant = new Antenna();
9.5 创建对象的奇迹
3个步骤的回顾:声明、创建、赋值
1.声明引用变量
2.创建对象
3.连接对象与引用
Duck myDuck = new Duck();
9.6 构造函数
Duck myDuck = new Duck();
调用Duck的构造函数
构造函数看起很像方法,感觉上也很像方法,但它并不是方法。它带有new的时候会执行的程序代码。这段程序代码会在你初始一个对象的时候执行。
唯一能够调用构造函数的办法就是新建一个类。(严格说起来,这是唯一在构造函数之外能够调用构造函数的方式,本章稍后会讨论这个部分)。可以为类编写构造函数,若你没有写,编译器会帮你写一个:
public Duck() {
}

方法有返回类型,构造函数没有返回类型。构造函数一定要与类的名称相同
构造Duck
构造函数的一项关键特征是它会在对象能够被赋值给引用之前就执行。这代表你可以有机会在对象被使用之前介入。也就是说,在任何人取得对象的遥控器前,对象有机会对构造过程给予协助。在Duck的构造函数中,我们没有作出什么有意义的事情,但还是有展示出事件的顺序。
- public class Duck {
- public Duck() {
- System.out.println("Quack");
- }
- }
- public class UseADuck {
- public static void main (String[] args)
- Duck d = new Duck();
- }
9.7 鸭子的初始状态
新建Duck状态的初始化
大部分的人都是使用构造函数来初始化对象的状态。也就是说设置和给对象的实例变量赋值。
- public Duck() {
- size = 34;
- }
这在开发者知道Duck类应该有多大时是没问题的。但如果是要由使用Duck的程序员来决定时应该怎么办?
你可以使用该类的setSize(来设定大小。但这会让Duck暂时处于没有大小数值的状态(实例变量没有默认值),且需要两行才能搞定。下面就是这么做的:- public class Duck() {
- int size;
- public Duck() {
- System.out.println("Quack");
- }
- public void setSize(int newSize) {
- size = newSize;
- }
- }
- public class UseADuck {
- public static void main(String[] args) {
- Duck d = new Duck();
- d.setSize(42);
- }
- }
使用构造函数来初始化Duck的状态
如果某种对象不应该在状态被初始化之前就使用,就别让任何人能够在没有初始化的情况下取得该种对象!让用户先构造出Duck对象再来设定大小是很危险的。如果用户不知道,或者忘记要执行setSize()怎么办?
最好的方法是把初始化的程序代码放在构造函数中,然后把构造函数设定成需要参数的。- public class Duck {
- int size;
- public Duck(int duckSize) {
- System.out.println("Quack");
- size = duckSize;
- System.out.println("size is " + size);
- }
- }
- public class UseADuck {
- public static void main (String[] args) {
- Duck d = new Duck(42);
- }
- }
Duck的简易饲养方法 一定要有不需参数的构造函数
如果Duck的构造函数需要一项参数会怎样?上一页的Duck只有一个构造函数,且它需要一个int型的size参数。这也许不是个问题,但却让程序员感到更为困难,特别是在不知道Duck的大小时。如果有预设的大小让程序员在不知道适当大小时也可以创建出Duck不是更好吗?
想象一下你可以让用户在创建Duck时有两个选项:一个可以指定Duck的大小(通过构造函数的参数),另外一个使用默认值而无需指定大小。
你无法只依靠单一的构造函数就能够很清楚地达到这个目的。要记得,如果某个方法或构造函数有一项参数,你就必须在调用该方法或构造函数的时候传入适当的参数。你没有办法作出一种没给参数时就使用默认值的方法,因为在这个情况下没有给参数就无法通过编译程序。也许你可以用下面这种不太理想的方法取代:
- public class Duck {
- int size;
- public Duck(int newSize) {
- if (newSize == 0) {
- size = 27;
- } else {
- size = newSize;
- }
- }
- }
这代表程序员必须要知道传入0对于创建Duck的构造函数意味着要使用默认的大小而不是真正的0。万一程序员真的做出0大小的Duck怎么办?这样的问题在于传入0的意图无法确实的分辨。
需要有两种方法来创建出新的Duck:
- public class Duck2 {
- int size;
- public Duck2() {
- //指定默认值
- size = 27;
- }
- public Duck2(int duckSize) {
- //使用参数指定
- size = duckSize;
- }
- }
知道大小时:
Duck2 d = new Duck2(15);
不知道大小时:
Duck2 d = new Duck2();
因此这会需要两个构造函数来分辨两种选项。一个需要参数,另外一个不需要参数。如果一个类有一个以上的构造函数,这代表它们也是重载的。
编译器只会在你完全没有设定构造函数时才会调用。如果你已经写了一个有参数的构造函数,并且你需要一个没有参数的构造函数,则你必须自己动手写!
如果类有一个以上的构造函数,则参数一定要不一样。这包括了参数的顺序与类型,只要是不一样就可以。这就跟方法的重载是相同的,不过细节会留到其他的章节再讨论。
9.8 构造函数的覆盖
重载构造函数代表有一个以上的构造函数且参数都不相同
下面列出的构造函数都是合法的,因为参数都不相同。假设说有两个构造函数的参数都是只有一个int,则肯定无法通过编译程序。编译器看的是参数的类型和顺序而不是参数的名字。你可以做出相同类型但是顺序不同的参数。使用String以及int型的参数顺序与使用int以及String型的参数顺序是不同的。

9.9 父类的构造函数
父类的构造函数在对象的生命中所扮演的角色
在创建新对象时,所有继承下来的构造函数都会执行
这代表每个父类都有一个构造函数(因为每个类至少都会有一个构造函数),且每个构造函数都会在子类对象创建时期执行。
执行new的指令是个重大事件,它会启动构造函数连锁反应。还有,就算是抽象的类也有构造函数。虽然你不能对抽象的类执行new操作,但抽象的类还是父类,因此它的构造函数会在具体子类创建出实例时执行。
在构造函数中用super调用父类的构造函数的部分。要记得子类可能会根据父类
的状态来继承方法(也就是父类的实例变量)。完整的对象需要也是完整的父类核心,所以这就是为什么父类构造函数必须执行的原因。就算Animal上有些变量是Hippo不会用到的,但Hippo可能会用到某些继承下来的方法必须读取Animal的实例变量。构造函数在执行的时候,第一件事是去执行它的父类的构造函数,这会连锁反应到Object这个类为止。

创建Hippo也代表创建Animal与Object
- public class Animal {
- public Animal() {
- System.out.println("Making an Animal");
- }
- }
- public class Hippo extends Animal {
- public Hippo() {
- System.out.println("Making a Hippo");
- }
- }
- public class TestHippo {
- public static void main (String[] args) {
- System.out.println("Starting...");
- Hippo h = new Hippo();
- }
- }
1.某个程序执行new Hippo()的动作,Hippo()的构造函数进入堆栈最上方的堆栈块

2.Hippo()调用父类的构造函数导致Animal()的构造函数进入栈顶

3.Animal()调用父类的构造函数导致Object()的构造函数进入栈顶

4.Object()执行完毕,它的堆栈块被弹出,接着继续执行Animal()的

调用父类的构造函数
调用super()
- public class Duck extends Animal {
- int size;
- public Duck(int newSize) {
- super();
- size = newSize;
- }
- }
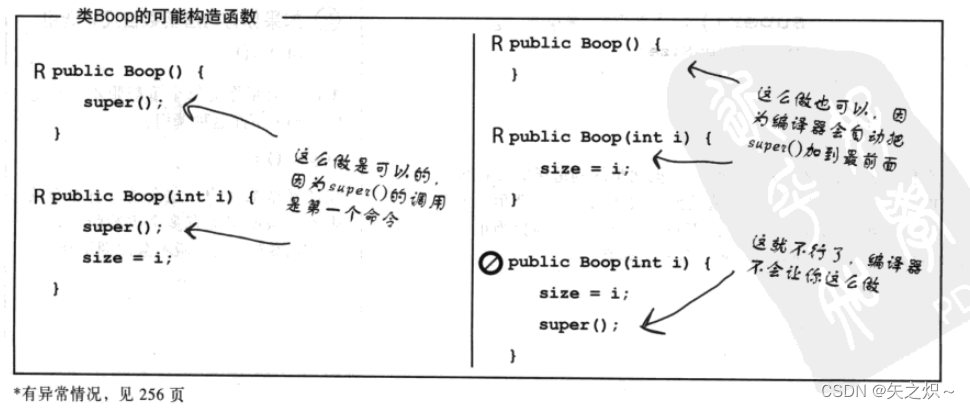
在你的构造函数中调用super()会把父类的构造函数放在堆栈的最上方。父类的构造函数会调用它的父类构造函数。这会一路上去直到Object的构造函数为止。然后再一路执行、弹出回到原来的构造函数。
如果我们没有调用super()会发生什么事?
编译器会帮我们加上super()的调用。所以编译器有两种涉入构造函数的方式:- 如果你没有编写构造函数。
- public ClassName() {
- super();
- }
- 如果你有构造函数但没有调用super()。
编译器会帮你对每个重载版本的构造函数加上下面这种调用:
super();编译器帮忙加的一定会是没有参数的版本,假使父类有多个重载版本,也只有无参数的这个版本会被调用到。
父类的部分必须在子类创建完成之前就必须完整地成型。子类对象可能需要动用到从父类继
承下来的东西,所以那些东西必须要先完成。父类的构造函数必须在子类的构造函数之前结
束。对super()的调用必须是构造函数的第一个语句”。
有参数的父类构造函数
Hippo有getName()这个方法但是没有name实例变量。Hippo要靠Animal的部分来维持name实例变量,然后从getName()来返回这个值,但Animal要如何取得这个值呢?唯一的机会是通过super()来引用父类,所以要从这里把name的值传进去,让Animal把它存到私有的name实例变量中。
- public class Animal {
- private String name;
- public String getName() {
- return name;
- }
- public Animal(String theName) {
- name = theName;
- }
- }
- public class Hippo extends Animal{
- public Hippo(String name) {
- super(name);
- }
- }
- public class MakeHippo {
- public static void main(String[] args) {
- Hippo h = new Hippo("Buffy");
- System.out.println(h.getName());
- }
- }
9.10 使用this()
从某个构造函数调用重载版的另一个构造函数
如果有某个重载版的构造函数除了不能处理不同类型的参数之外,可以处理所有的工作,那要怎么办?你不想让相同的程序代码出现在每个构造函数中(维护起来很麻烦),所以你想把程序代码只摆在某个构造函数中(包括对super()的调用)。如此一来,所有的构造函数都会先调用该构造函数,让它来执行真正的构造函数。这很容易,只要调用this()或this(aString)或this(27,x)就行。

换句话说,this就是个对对象本身的引用。
this()只能用在构造函数中,且它必须是第一行语句!
每个构造函数可以选择调用super()或this(),但不能同时调用!
使用this()来从某个构造函数调用另一个构造函数
9.11 对象生命周期
对象的生命周期要看引用变量的生命周期而定

1.局部变量只会存活在声明该变量的方法中

2.实例变量的寿命与对象相同。若对象还活着,则实例变量也会是活的

Life
只要变量的堆栈块还存在于堆栈上,局部变量就算活着,一直到方法执行完毕为止
Scope
局部变量的范围只限于声明它的方法之内。当此方法调用别的方法时,该变量还活着,但不在目前的范围内。执行其他方法完毕返回时,范围也就跟着回来。


当局部变量活着的时候,它的状态会被保存。只要doStuff()还在栈上,b变量就会保持它的值。但b变量只能在doStuff()待在栈顶时才能使用。也就是说,局部变量只能在声明它的方法在执行中才能被使用。
9.12 资源回收
引用的规则与primitive主数据类型相同。引用变量只能在处于它的范围中才能被引用
“变量的生命周期如何影响对象的生命周期?”
只要有活着的引用,对象也就会活着。如果某个对象的引用已经不在它的范围中,但此引用还是活着的,则此对象就会继续活在堆上。
如果对对象的唯一引用死了,对象就会从堆中被踢开。引用变量会跟堆栈块一起解散,因此被踢开的对象也就正式的声明出局。关键在于知道何时对象会变成可被垃圾收集器回收的。
一旦对象符合垃圾收集器(GC)的条件,你就无需担心回收内存的问题。如果程序内存不足,GC就会去歼灭部分或全部的可回收对象。你可能还是会遇到内存不足的状况,但这要等到所有可回收的都被回收掉也还不够的时候才会发生。你要注意的是对象用完了就要抛弃,这样才能让垃圾收集器有东西可以回收。如果你把持着对象不放,垃圾收集器也帮不了什么忙。除非有对对象的引用,否则该对象一点意义也没有。若无法取得对象的引用,此对象只是浪费空间罢了。此时GC会知道该怎么做,那种对象迟早会葬送在垃圾收集器的手上
当最后一个引用消失时,对象就会变成可回收的:
有3种方法可以释放对象的引用:
1.引用永久性的离开它的范围
- void go() {
- Life z = new Life();
- }
2.引用被赋值到其他的对象上
- Life z = new Life();
- z = new Life();
3.直接将引用设定为null
- Life z = new Life();
- z = null;



-
相关阅读:
鲁大师10月新机性能/流畅/久用榜:骁龙8 Gen3一鸣惊人,双十一“6系”处理器成井喷状态
Java之继承、枚举、final、static、多态、向上向下转型、抽象类、接口、内部类、匿名内部类、lambda
BUUCTF:[GYCTF2020]FlaskApp
【多线程 - 10、线程同步3 ThreadLocal】
Redis实战案例及问题分析之redis解决商户缓存以及相应缓存问题解决方案(穿透、雪崩、击穿)
Vue3 快速入门及巩固基础
Linux操作系统基础指令II
基于javaweb的农业信息管理系统(java+ssm+jsp+js+html+mysql)
IPv6 RIP(RIPng)
Python趣味入门12:初遇类与实例
- 原文地址:https://blog.csdn.net/weixin_64800741/article/details/133872227