-
Yolov7代码解析
代码解析

backbone
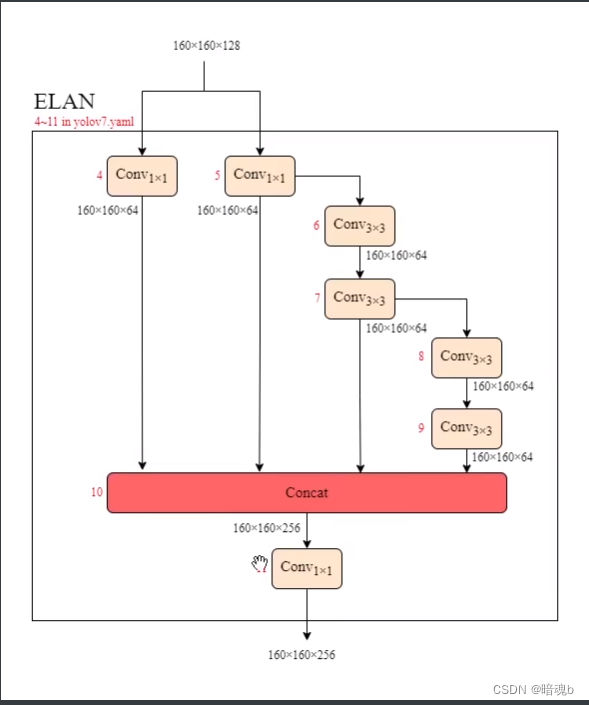
# -1代表前一层,channel:32 size:3 stride:1 [[-1, 1, Conv, [32, 3, 1]], # 0 [-1, 1, Conv, [64, 3, 2]], # 1-P1/2 [-1, 1, Conv, [64, 3, 1]], [-1, 1, Conv, [128, 3, 2]], # 3-P2/4 #ELAN 4-11层 [-1, 1, Conv, [64, 1, 1]], [-2, 1, Conv, [64, 1, 1]], [-1, 1, Conv, [64, 3, 1]], [-1, 1, Conv, [64, 3, 1]], [-1, 1, Conv, [64, 3, 1]], [-1, 1, Conv, [64, 3, 1]], # 接收来自 -1,-3,-5,-6层的输入,并沿通道数拼接 [[-1, -3, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1]], # 11- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
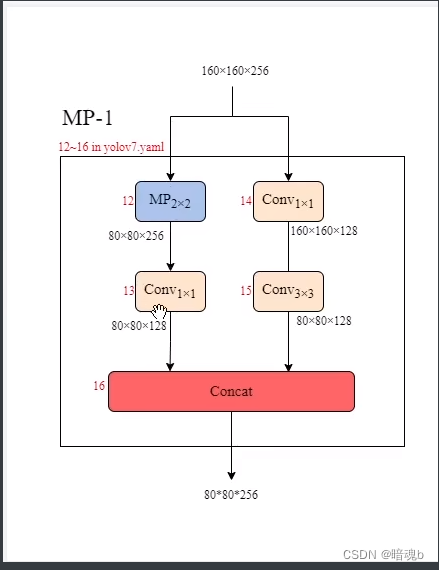
#MP1 复杂版的最大池化层,通道数不变,尺寸减半 [-1, 1, MP, []], [-1, 1, Conv, [128, 1, 1]], [-3, 1, Conv, [128, 1, 1]], [-1, 1, Conv, [128, 3, 2]], [[-1, -3], 1, Concat, [1]], # 16-P3/8 #ELAN [-1, 1, Conv, [128, 1, 1]], [-2, 1, Conv, [128, 1, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [[-1, -3, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [512, 1, 1]], # 24 #MP1模块 [-1, 1, MP, []], [-1, 1, Conv, [256, 1, 1]], [-3, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [256, 3, 2]], [[-1, -3], 1, Concat, [1]], # 29-P4/16 #ELAN模块 [-1, 1, Conv, [256, 1, 1]], [-2, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [[-1, -3, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [1024, 1, 1]], # 37 #MP1 [-1, 1, MP, []], [-1, 1, Conv, [512, 1, 1]], [-3, 1, Conv, [512, 1, 1]], [-1, 1, Conv, [512, 3, 2]], [[-1, -3], 1, Concat, [1]], # 42-P5/32 #ELAN [-1, 1, Conv, [256, 1, 1]], [-2, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [[-1, -3, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [1024, 1, 1]], # 50- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
head
SPPCSPC
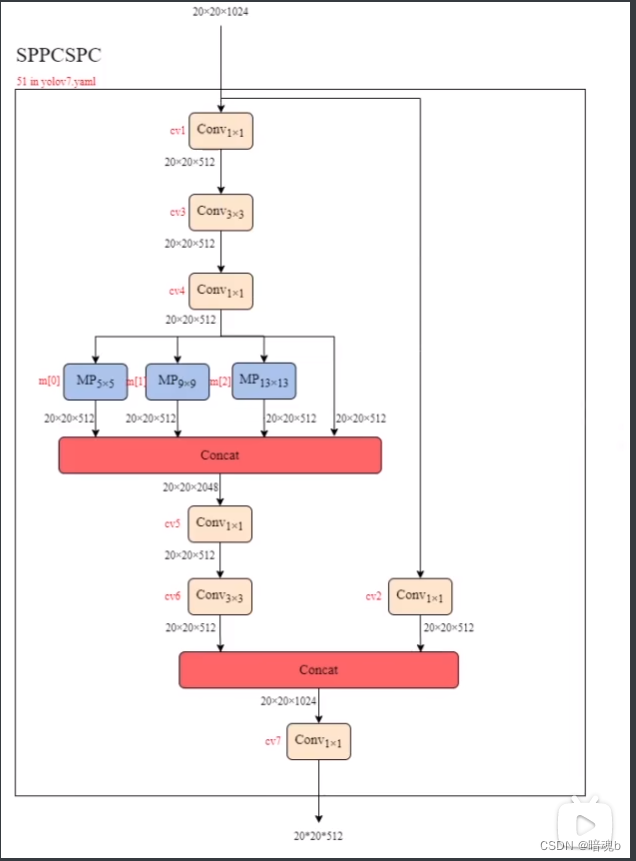
class SPPCSPC(nn.Module): # CSP https://github.com/WongKinYiu/CrossStagePartialNetworks def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)): super(SPPCSPC, self).__init__() c_ = int(2 * c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c1, c_, 1, 1) self.cv3 = Conv(c_, c_, 3, 1) self.cv4 = Conv(c_, c_, 1, 1) self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k]) self.cv5 = Conv(4 * c_, c_, 1, 1) self.cv6 = Conv(c_, c_, 3, 1) self.cv7 = Conv(2 * c_, c2, 1, 1) def forward(self, x): x1 = self.cv4(self.cv3(self.cv1(x))) y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1))) y2 = self.cv2(x) return self.cv7(torch.cat((y1, y2), dim=1))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
head: [[-1, 1, SPPCSPC, [512]], # 51 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [37, 1, Conv, [256, 1, 1]], # route backbone P4 [[-1, -2], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1]], [-2, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [[-1, -2, -3, -4, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1]], # 63 [-1, 1, Conv, [128, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [24, 1, Conv, [128, 1, 1]], # route backbone P3 [[-1, -2], 1, Concat, [1]], [-1, 1, Conv, [128, 1, 1]], [-2, 1, Conv, [128, 1, 1]], [-1, 1, Conv, [64, 3, 1]], [-1, 1, Conv, [64, 3, 1]], [-1, 1, Conv, [64, 3, 1]], [-1, 1, Conv, [64, 3, 1]], [[-1, -2, -3, -4, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [128, 1, 1]], # 75 [-1, 1, MP, []], [-1, 1, Conv, [128, 1, 1]], [-3, 1, Conv, [128, 1, 1]], [-1, 1, Conv, [128, 3, 2]], [[-1, -3, 63], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1]], [-2, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [-1, 1, Conv, [128, 3, 1]], [[-1, -2, -3, -4, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [256, 1, 1]], # 88 #MP-2模块 [-1, 1, MP, []], [-1, 1, Conv, [256, 1, 1]], [-3, 1, Conv, [256, 1, 1]], [-1, 1, Conv, [256, 3, 2]], [[-1, -3, 51], 1, Concat, [1]], [-1, 1, Conv, [512, 1, 1]], [-2, 1, Conv, [512, 1, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [-1, 1, Conv, [256, 3, 1]], [[-1, -2, -3, -4, -5, -6], 1, Concat, [1]], [-1, 1, Conv, [512, 1, 1]], # 101 [75, 1, RepConv, [256, 3, 1]], [88, 1, RepConv, [512, 3, 1]], [101, 1, RepConv, [1024, 3, 1]], [[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5) ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
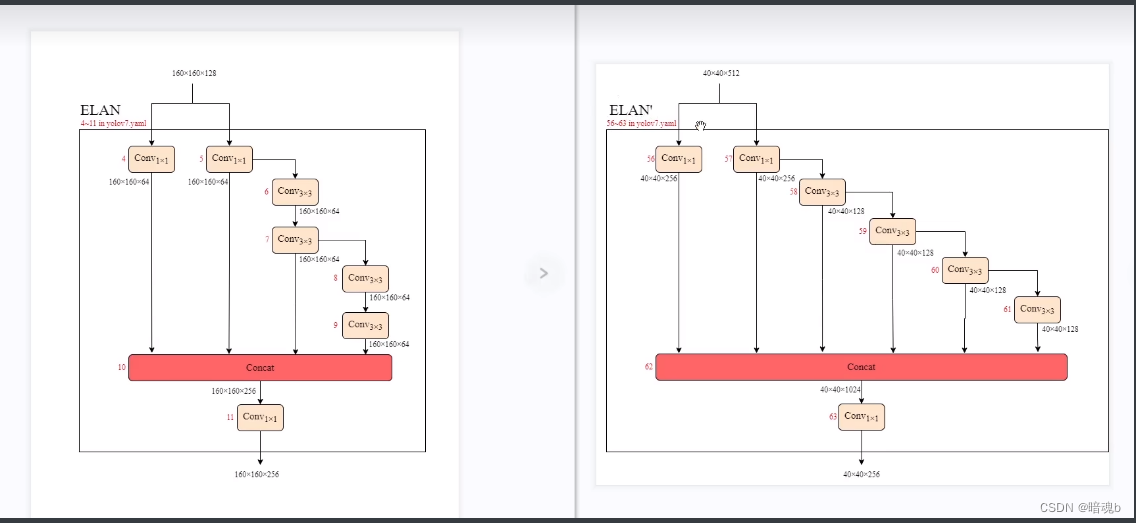
56-63层 ELAN’ ELAN的变形
MP-2
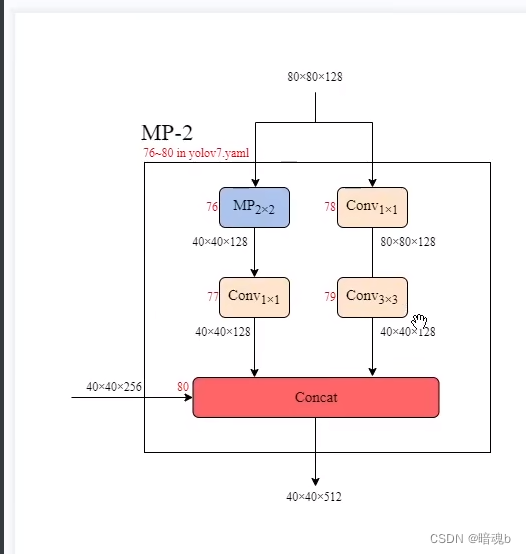
CBS
Conv = Conv2d+BatchNorm2d+SiLu激活函数
BatchNorm2d
对输入的四维数组进行批量标准化处理,具体计算公式如下:
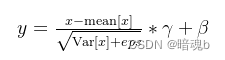
对于所有的batch中样本的同一个channel的数据元素进行标准化处理,即如果有C个通道,无论batch中有多少个样本,都会在通道维度上进行标准化处理,一共进行C次
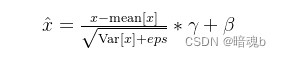
SiLu
SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数
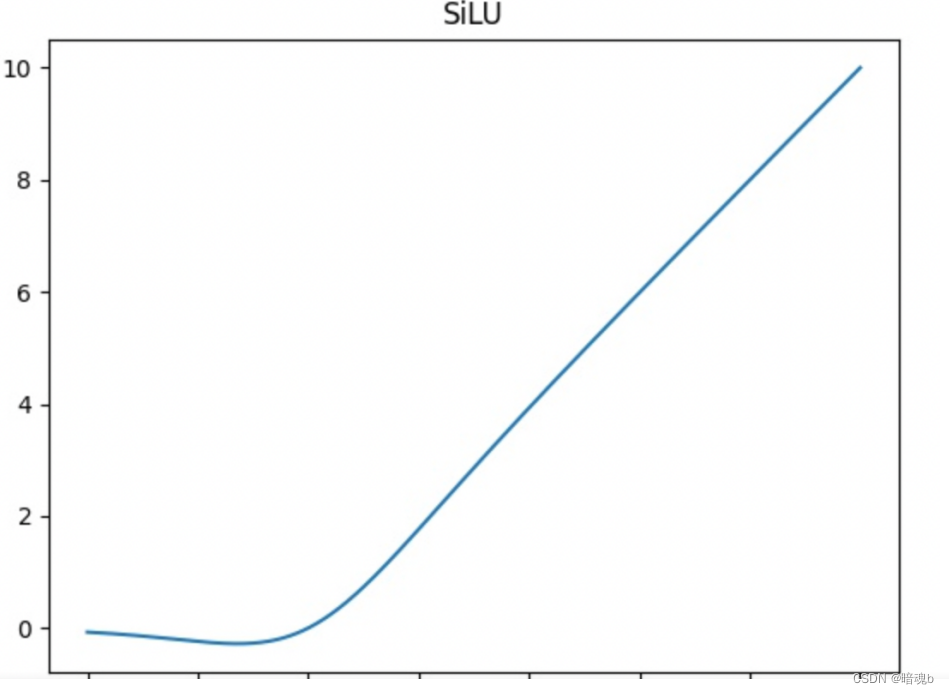
class SiLU(nn.Module): def forward(x): return x * torch.sigmoid(x)- 1
- 2
- 3
E-ELAN
分组卷积
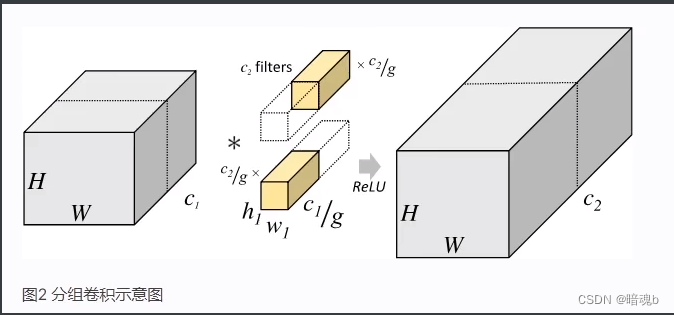
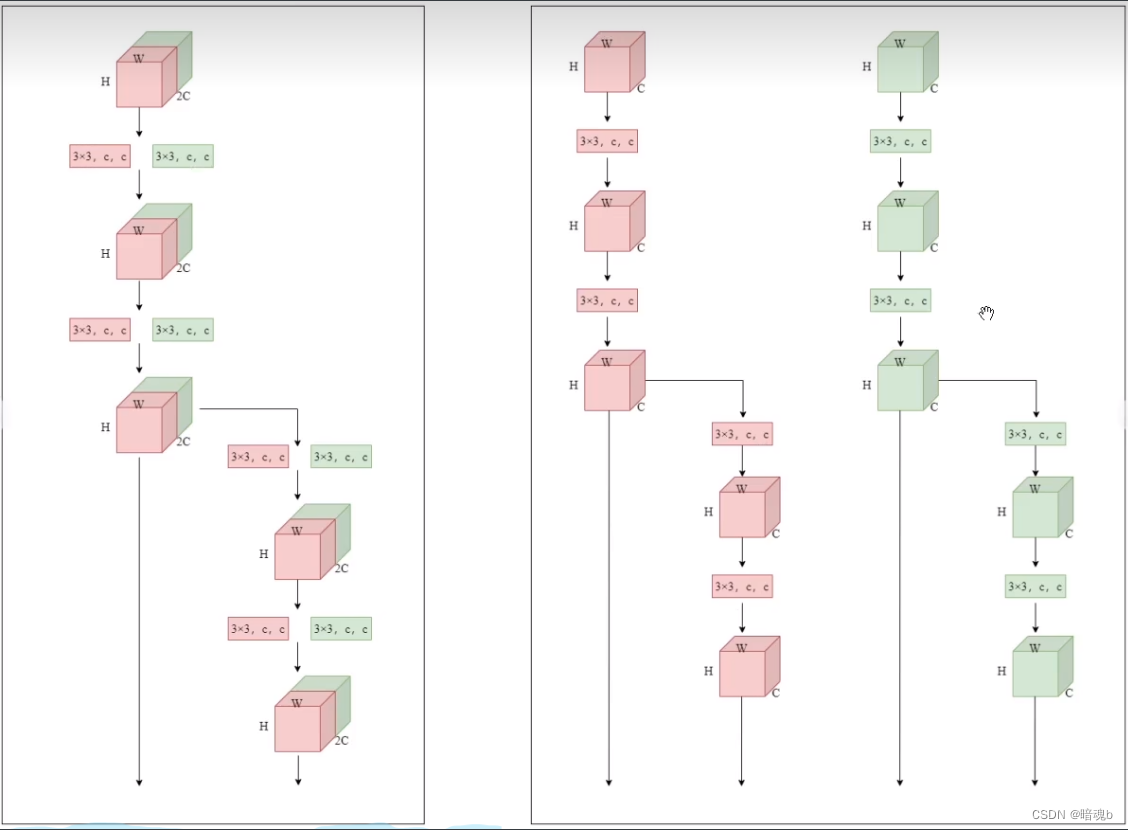
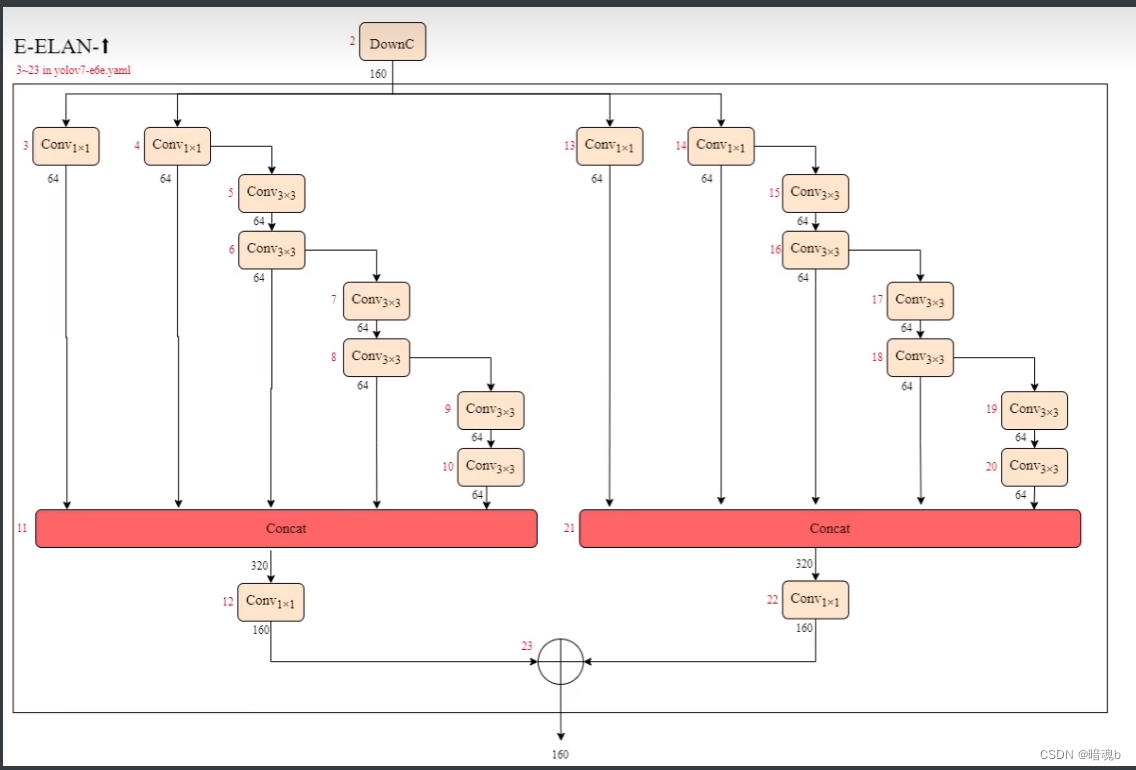
模型缩放方法
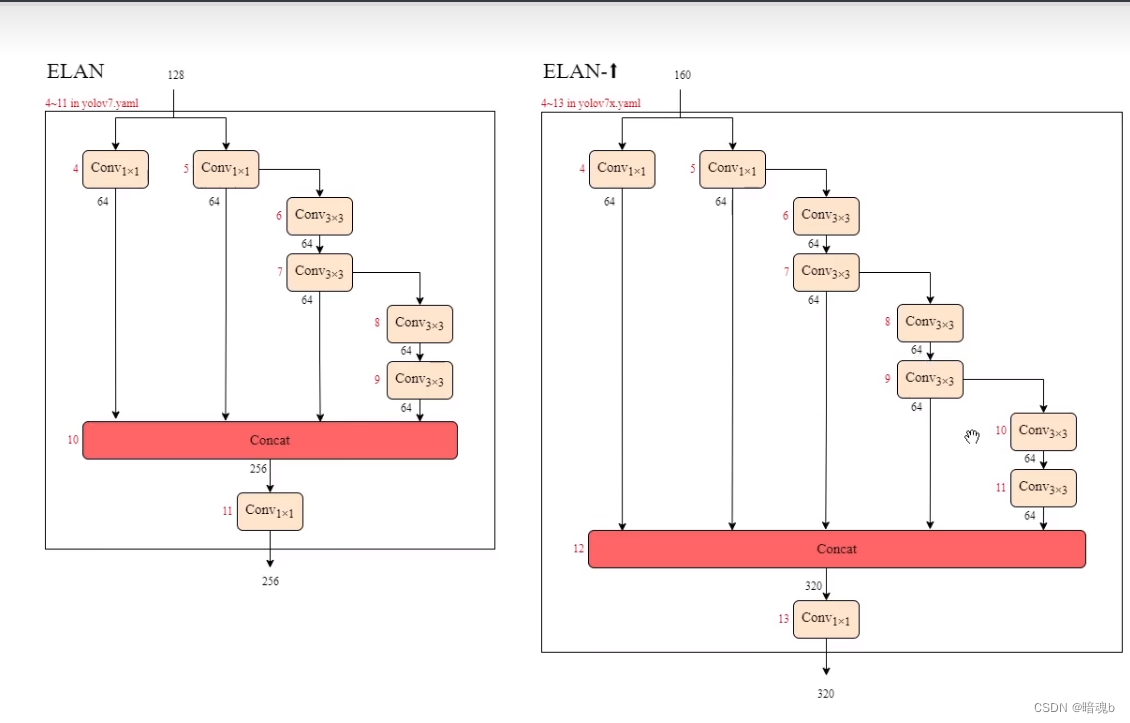
多了一条有两个卷积的支路,扩大了深度,输出的通道数比原来多1.25倍,扩大了宽度
深度监督
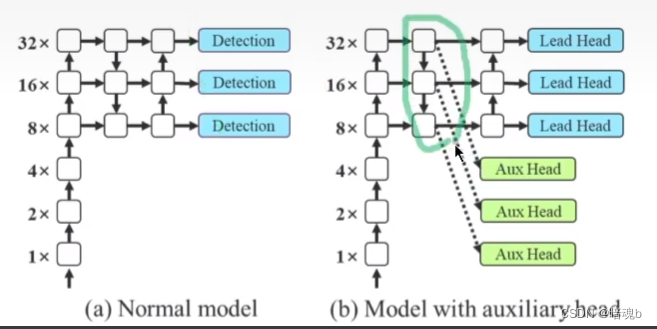
增加了 Aux Head,Aux head也参与损失函数的计算并反向传播参与协助前面的层更新参数
-
相关阅读:
利用vue-cli构建SPA项目以及在SPA项目中使用路由
结合对称加密、非对称加密浅析HTTPS协议
【软件测试】(北京)字节跳动科技有限公司二面笔试题
变量与运算符
Python Scrapy中的POST请求发送和递归爬取
[SpringBoot系列]数据层技术解析
艾美捷FcyRl (CD64),FCGR1A,生物活性活动分析结果
学生个人网页设计作品:旅游网页设计与实现——成都旅游网站4个页HTML+CSS web前端网页设计期末课程大作业 学生DW静态网页设计 学生个人网页设计作品
HTML5期末考核大作业——学生网页设计作业源码HTML+CSS+JavaScript 中华美德6页面带音乐文化
typora|将绝对路径的图片,全部替换为相对路径
- 原文地址:https://blog.csdn.net/weixin_47020721/article/details/133919824
