-
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(一)

前言
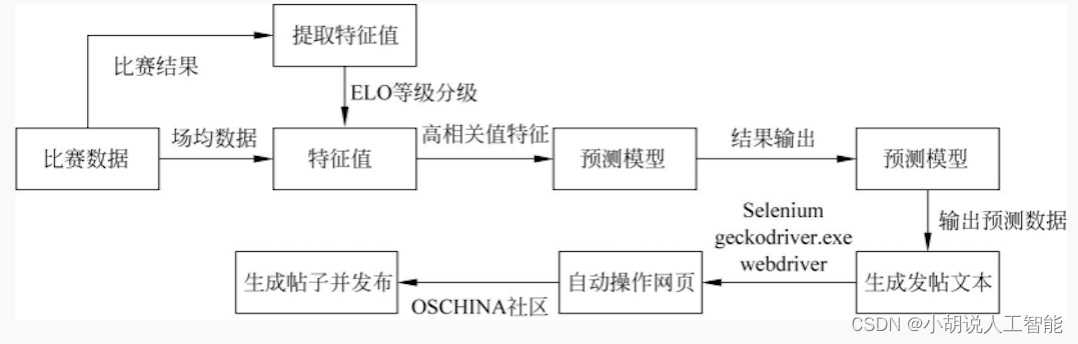
本项目使用了从NBA官方网站获得的数据,并运用了支持向量机(SVM)模型来进行NBA常规赛和季后赛结果的预测。此外,项目还引入了相关系数法、随机森林分类法和Lasso方法,以评估不同特征的重要性。最后,使用Python库中的webdriver功能实现了自动发帖,并提供了科学解释来解释比赛预测结果。
首先,项目采集了NBA官方网站上的各种数据,这些数据包括球队与对手的历史表现、球员数据、赛季统计等。这些数据用于构建常规赛或季后赛结果的预测模型。
其次,支持向量机(SVM)模型被用来分析这些数据以进行常规赛或季后赛结果的预测。SVM是一种强大的机器学习算法,可以通过分析数据来确定不同特征对比赛结果的影响。
项目还使用了相关系数法、随机森林分类法和Lasso方法,以评估每个特征对常规赛或季后赛结果的重要性。这有助于识别哪些因素对比赛胜负有更大的影响。
最后,项目利用Python中的webdriver库自动发帖,在开源中国论坛中发布关于比赛预测的帖子。这些帖子不仅提供了预测结果,还附带了科学解释,以便其他球迷能够理解模型如何得出这些预测。这对于NBA球迷和数据科学爱好者来说可能是一个非常有趣的项目,能够帮助他们更好地理解比赛和预测比赛结果。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
系统流程图
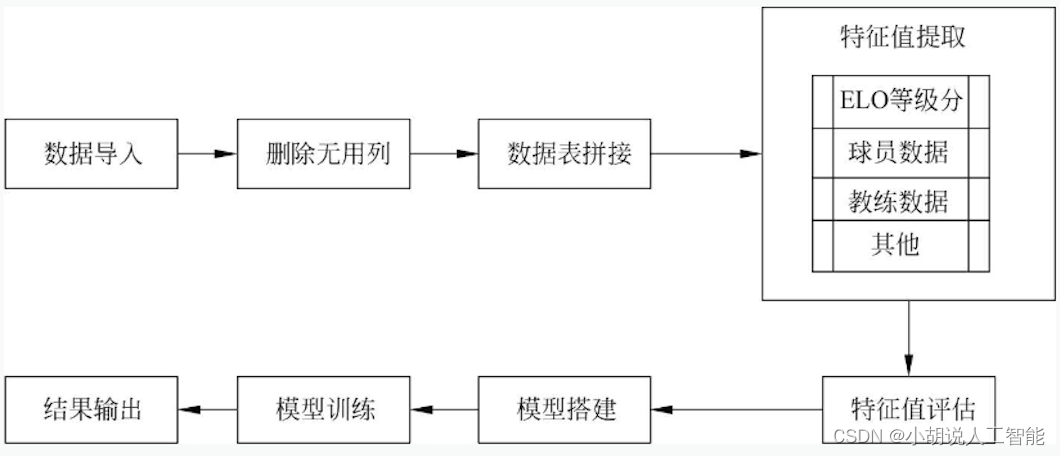
模型处理流程如图所示。
自动发帖流程如图所示。

运行环境
本部分包括Python环境、Jupyter Notebook环境、PyCharm环境和Matlab环境。
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
鼠标右击“我的电脑”,单击“属性”,选择高级系统设置。单击“环境变量”,找到系统变量中的Path,单击“编辑”然后新建,将Python解释器所在路径粘贴并确定。
Jupyter Notebook环境
打开Anaconda Prompt,转到HOME界面,单击JupyterNotebook的下载按钮,选择6.0.1版本或者更高的版本下载即可。
PyCharm环境
安装PyCharm并激活,PyCharm下载地址为http://www.jetbrains.com/pycharm/download/#section=windows,进入网站后单击Comminity版本下的DOWNLOAD下载安装包,下载完成后安装。
MATLAB环境
MATLAB版本为9.5.0.944444 (R2018b) ,MATLAB许可证编号为968398。操作系统为Microsoft Windows10企业版,2016长期服务版为Version10.0 (Build14393) 。
模块实现
本项目包括4个模块:数据预处理、特征提取、模型训练及评估、模型训练准确率,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
数据处理分为常规赛和季后赛。
1)常规赛数据处理
数据集地址为https://www.basketball-reference.com/,下载后导入。使用Pandas的
read_csv函数读取数据表,相关代码如下:Mstat = pd.read_csv('nbadata/17-18Miscellaneous_Stat.csv') #球队赛季总和统计数据 Ostat = pd.read_csv('nbadata/17-18Opponent_Per_Game_Stat.csv') #对手赛季平均每场比赛统计数据 Tstat = pd.read_csv('nbadata/17-18Team_Per_Game_Stat.csv') #球队赛季平均每场比赛统计数据 result_data = pd.read_csv('nbadata/2017-2018_result.csv') #18~19赛季比赛日历和结果 Mstat# 球队综合数据图 Ostat.head()#球队对手数据图 Tstat.head()#球队场均数据图- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
部分数据如图1-图3所示。

图1 球队综合数据 
图2 球队对手数据 
图3 球队场均数据 进行数据初始化如下:
#删除无用列 new_Mstat = Mstat.drop(['Rk', 'Arena'], axis=1) new_Ostat = Ostat.drop(['Rk', 'G', 'MP'], axis=1) new_Tstat = Tstat.drop(['Rk', 'G', 'MP'], axis=1) #根据队名横向拼接前两个表 team_stats1 = pd.merge(new_Mstat, new_Ostat, how='left', on='Team') #根据队名横向拼接上三个表 team_stats1 = pd.merge(team_stats1, new_Tstat, how='left', on='Team') team_stats=team_stats1.set_index('Team', inplace=False, drop=True) team_stats1.head()#拼接表显示 result_data.head()#常规赛结果- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
拼接结果如图所示。

2017-2018赛季比赛结果前5个数据如图所示。

2)季后赛数据处理
季后赛预测需要提取的特征有常规赛球队得分、核心球员数量、核心球员得分、教练常规赛执教总场数、常规赛执教总胜率、季后赛执教总场数和季后赛执教总胜率,共7个特征。需要准备的数据有:常规赛队伍场均数据和对手场均数据,位于
data/team_and_op文件夹下;教练数据,位于data/coach文件夹下;球员各项数据,位于data/player_score文件夹下;季后赛数据,位于data/playoff文件夹下。所有数据均为2010-2011赛季至2018-2019赛季数据。相关代码如下:
tfname = glob.glob('data/team_and_op/*t.csv') ofname = glob.glob('data/team_and_op/*o.csv') for tname, oname, playoff in zip(tfname, ofname, playfname): #读取队伍数据 df = pd.read_csv(tname) #读取队伍对手数据 df_ = pd.read_csv(oname)- 1
- 2
- 3
- 4
- 5
- 6
- 7
获得的原数据中,队名列中随机带有“*”,将其删除;教练数据及球员数据的队名是缩写,将其替换为全名;在采取数据的9个赛季中,有些队伍更改了名称,需统一为当前队名。使用pandas DataFrame对象的replace方法完成。
相关代码如下:
df.replace(oldname, newname)- 1
相关其它博客
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(二)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(三)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(四)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。 -
相关阅读:
当你离开现在的公司,你的百万业务量还能保持吗?
React【Context_作用、函数组件订阅Context、Fragments 、错误边界_概念 、错误边界_应用、Refs & DOM】(四)
Navicat 现已支持 OceanBase 企业版
2023-09-27力扣每日一题
瑞_23种设计模式_策略模式
C语言实现printf同行输出(刷新显示)
网络管理配置怎么路由
南大通用数据库-Gbase-8a-学习-10-Gbase8a通过Dblink访问Oracle
Spring Cloud(Spring全家桶)
数据结构:线性表之-队列
- 原文地址:https://blog.csdn.net/qq_31136513/article/details/133745858