-
MySQL数据库——SQL优化(3/3)-limit 优化、count 优化、update 优化、SQL优化 小结
目录
limit 优化
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。
当在进行分页查询时,如果执行limit 2000000,10,此时需要MySQL排序前2000010条记
录,仅仅返回 2000000 ~ 2000010 的记录,其他记录丢弃,查询排序的代价非常大。优化思路
一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查
询形式进行优化。使用覆盖索引:
- select id from tb_sku order by id limit 2000000,10;
- -- 使用到了主键索引,效率高
加上子查询:(当作两张表进行查询)
- select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a
- where t.id = a.id;
count 优化
概述
在之前的测试中,我们发现,如果数据量很大,在执行count操作时,是非常耗时的。
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的count,MyISAM引起也慢。
InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
如果说要大幅度提升InnoDB表的count效率,主要的优化思路:自己计数,自己维护计数变量(可以借助于redis这样的数据库进行,但是如果是带条件的count又比较麻烦了)。
count用法
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
count用法 含义 count(主键) InnoDB 引擎会遍历整张表,把每一行的主键id值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null) count(字段) 没有not null 约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。
有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
count(数字) InnoDB 引擎遍历整张表,但不取值。以count(1)为例,服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。 count(*) InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。 按照效率排序的话,count(字段) < count(主键 id) < count(1) ≈ count(*),所以,尽量使用 count(*)。
update 优化
我们主要需要注意一下update语句执行时的注意事项。
update course set name = 'javaEE' where id = 1当我们在执行上述的SQL语句时,会锁定id为1这一行的数据,在事务提交之后,行锁才会释放。
但是当我们在执行如下SQL时。
update course set name = 'SpringBoot' where name = 'PHP'当我们开启多个事务,在执行上述的SQL时,我们发现行锁升级为了表锁。
导致该update语句的性能大大降低。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁升级为表锁 。
SQL优化 小结
插入数据
- insert:批量插入、手动控制事务、主键顺序插入
- 大批量插入: load data local infile
主键优化
- 主键长度尽量短,顺序插入(否则会造成页分裂) AUTO_INCREMENT
UUID主键不使用uuid
order by 优化
- using index:直接通过索引返回数据,性能高
- using filesort:需要将返回的结果在排序缓冲区排序
group by 优化
- 使用索引,多字段分组满足最左前缀法则
limit 优化
- 覆盖索引+子查询
count 优化
- 性能:count(字段)
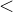 count(主键id)count(1)
count(主键id)count(1) count(*)
count(*)
update 优化
- 尽量根据主键/索引字段进行数据更新
END
学习自:黑马程序员——MySQL数据库课程
-
相关阅读:
ROS2/DDS/QoS/主题的记录
Unity基础01——3D数学
业内首份!博睿数据入选中国信通院《中国AIOps现状调查报告(2022)》
234 基于matlab的萤火虫算法多变量寻优
低代码与无代码平台的选型建议
极智AI | 输入图片BatchSize和分辨率对模型计算量和参数量的影响
#机器学习--补充数学基础--概率论
扩散模型(Diffusion Model)详解:直观理解、数学原理、PyTorch 实现
DNS 系列(二):DNS 记录及工作方式,你了解吗?
二叉树、二叉搜索树,平衡二叉树(旋转)红黑树(红黑规则)
- 原文地址:https://blog.csdn.net/li13437542099/article/details/133691799