-
自我监督学习日志
学习日志
10.12
一天学不了一分钟,不知道为什么也就是了
今天一定要学一个小时!机器学习就是机器帮我们找一个函数
语音辨识,语音,声音讯号 转化为文字
帮我们找一个人类写不出来的复杂函数
类神经网络
输入
一张图片用一个矩阵来表示
输入是一个序列
各式各样的输出
输出是一个数值的任务,叫regression
输出是一个类别,机器选择其中的类别,叫分类classification
机器写一段文字,制图,动漫人脸的生成
怎么用类神经网络制造函数,来制造各式各样的输入输出https://www.kaggle.com/
机器学习两大类任务
regression
classification
不仅如此,还有 structured learning
机器产生一个有结构的物件,机器创造一件事情model就是带有未知参数的function
loss是函数,输入为model中的未知参数
输出,假设未知参数为某个值的时候,结果是好还是不好
比对函数预估的结果和真实值的差距,取绝对值
label就是正确的数值
训练资料,已知的准确的数据
每一天的误差都可以得出,最后L代表loss,L越小,代表参数越好

计算估测值和真实值之间差距的方法
MAE
error surface ,2D差值の等高线图- Function with Unknown Parameters
- Define Loss from Training Data
- Optimization
gradient decent 这个方法
微分值(斜率 ^ _ ^ )
先看正负,决定未知参数往大了取还是往小了取,才能使得loss更小
再看绝对值大小,决定位置参数改变的跨度
跨度的决定因素
1、斜率,斜率大跨度大,
2、learning rate 自己设定,更大,参数的update量大,学习得更快
机器学习中由自己设定的东西,hyperparameterloss的function由自己设定,可以是负值
未知参数更新结束,有两种状况,一、自己决定的更新次数上限,二、调整参数刚好得到loss为0
gradient decent 这个方法,会出现local minimal ,我们最好的是global minimal
local minimal是假问题,不是训练network时真正的难题,真正的难题是什么呢??发现,YouTube观看人数每七天是一个循环
对模型的修改通常来自于你对这个问题的理解,也就是domain knowledgefeature * weight +bias ===> linear models
10.13
很好,今天美学一分钟
好像很忙,一直没停,但不知道到底干了些什么正事玩手机:你要心酸中谨记当走到最尾,哪处风景最优美
奢华悠闲早餐、社保卡、午睡、洗头、开会、交表、和英语表达殊死抗争到怀疑自我10.14、10.15
拧螺丝
润色论文,学会翻墙用poe,grammarly,Quillbot10.16
放飞大半天
Linear models 太过简单,存在 model biasAll Piecewise Linear Curves
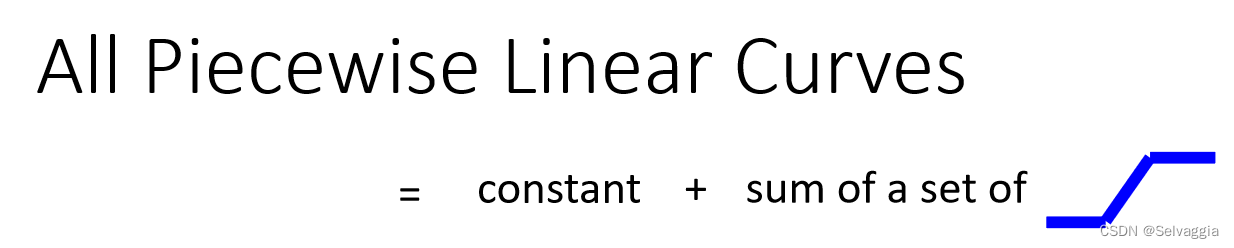
piecewise linear curves,可以由 一堆蓝色function 构成
曲线beyond piecewise linear
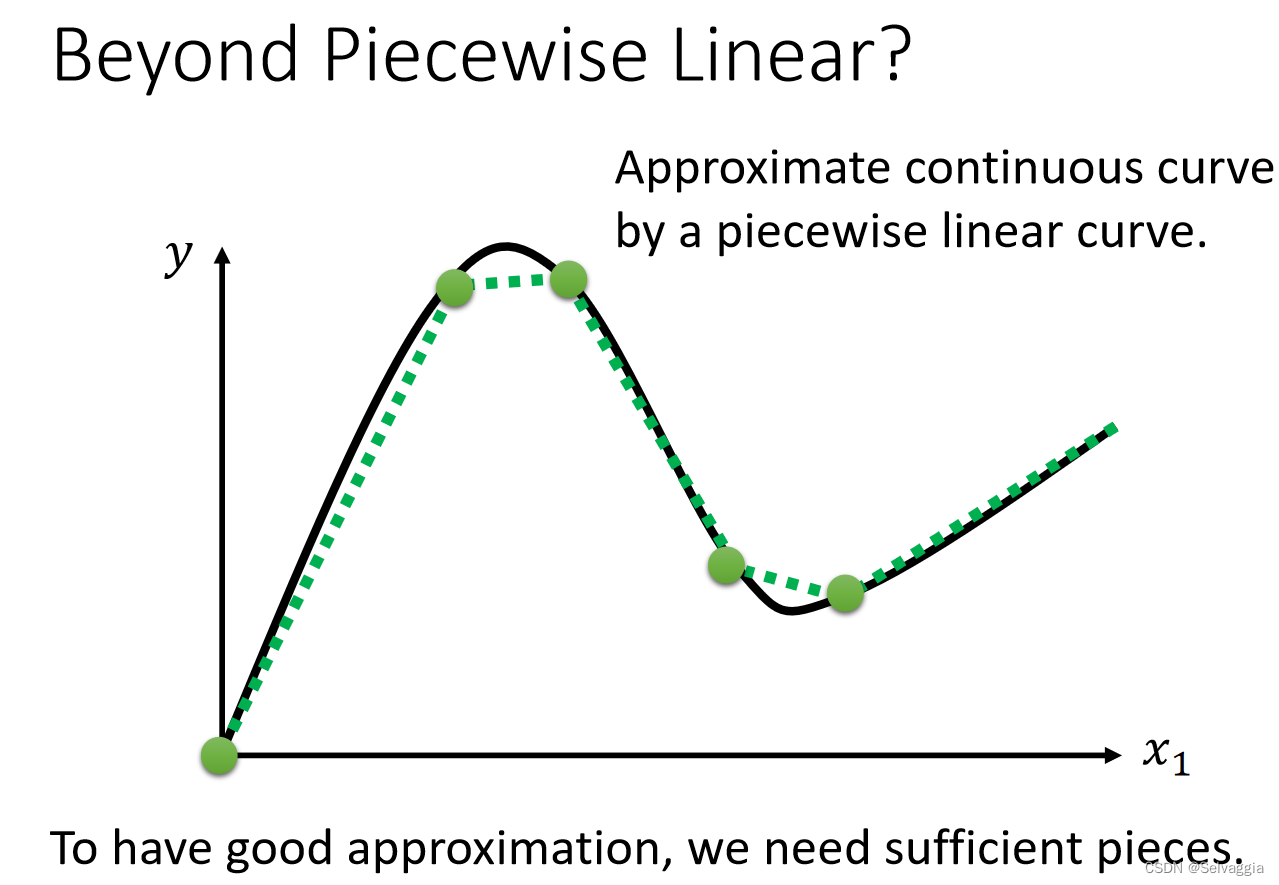
可以用若干piecewise linear curves逼近任何连续的曲线continues function
比linear model,更有弹性的有未知参数的模型
如何表示蓝色function? hard sigmoid function 稍微难以表示,soft sigmoid function稍微好表示
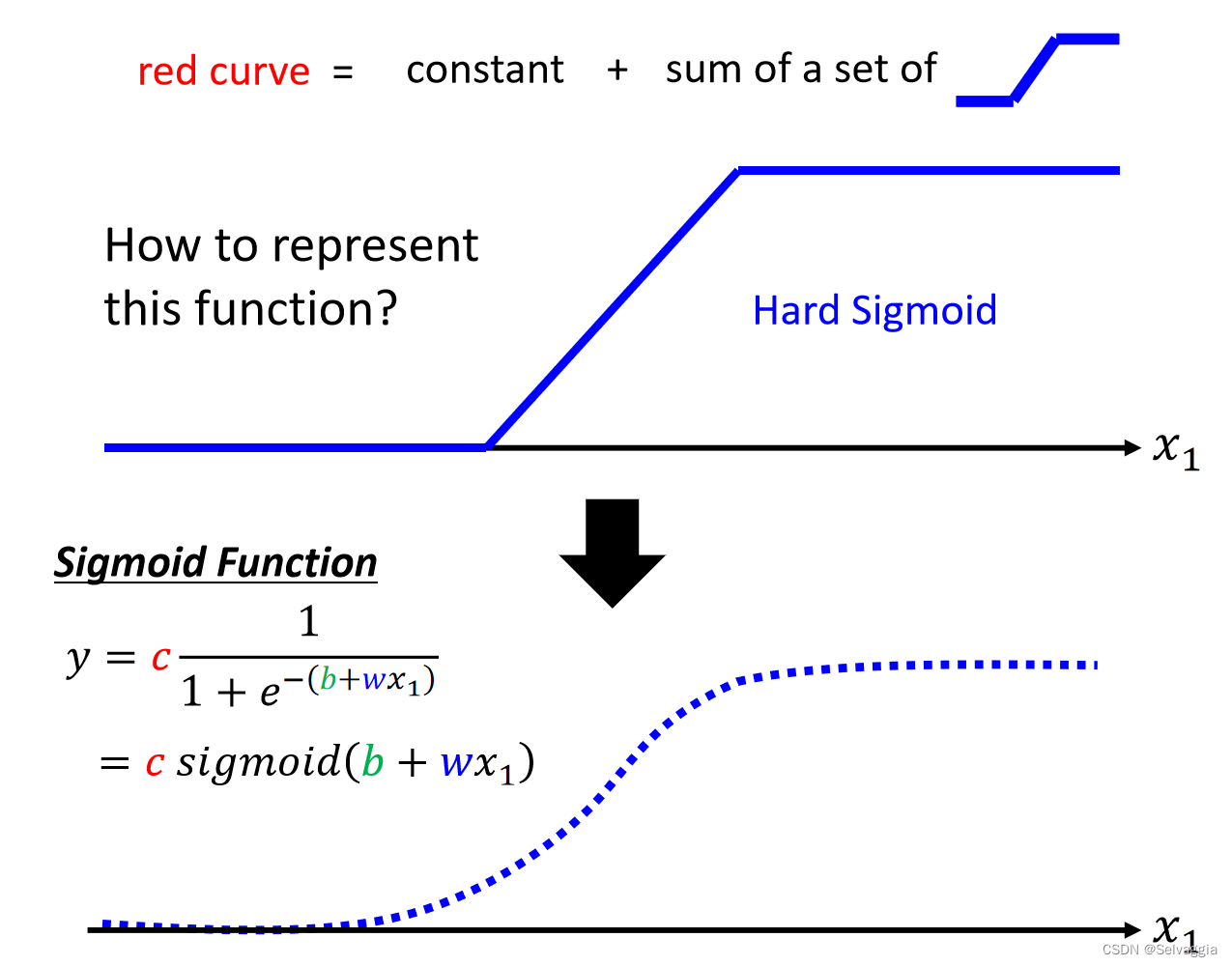
sigmoid function
x1趋近无穷大,趋近于1
趋近于负无穷,趋近于0
调整w b c,逼近不同的蓝色function soft sigmoid function两个折点的三段式折线

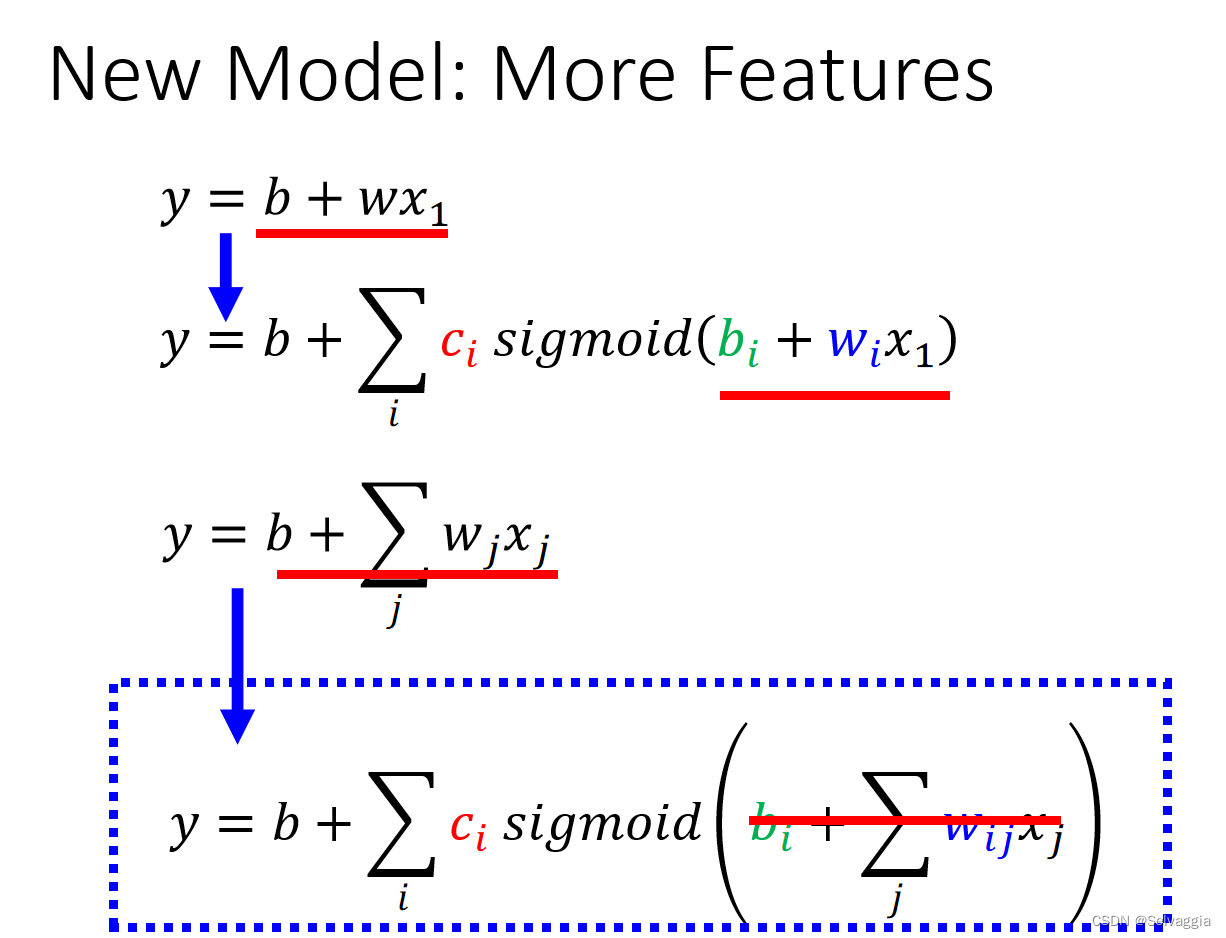
扩展成一个更具有弹性的function,多个feature(就是最初介绍的linear model,对不同的feature乘上weight,更具弹性)改成线性代数常用的表现方式

暴搜所有参数可能的值,参数很少
要用到gradient decent找出能让loss最低的参数希望这样有回答到他的问题
sigmoid 数量越多,可以逼近构成越复杂的函数,数量自己决定
loss函数
参数太多,用theta来统摄所有的未知参数
可以让loss最小的那组theta叫做theta的start,如何找出,随机选一个出事的数值(找更好的初始值的方法)
直到不想做了
或者gradient是零向量,zero vector,导致没有办法再继续更新参数,实做上不太可能出现后者情况实做上做gradient decent的时候,随机分成B个batch
几个sigmoid,batch size也是hyper perameter
把两个relu叠起来,变成表示一个 hard sigmoid
activation function100个relu降低loss,制造比较复杂的曲线
继续改我们的模型
同样的sigmoid function或者relufunction多做几遍,多层layer
sigmoid和relu反复用惨掉了
overfitting在训练的资料上变好,在没看过的资料上没有变好
预测未知的资料怎么选模型 多少层
在没有看过的资料上表现为好的模型 -
相关阅读:
java计算机毕业设计基于安卓Android的掌上酒店预订APP
HDU 6514 - Monitor(前缀和与差分)
C++入门基础(下篇)
Java:实现使用快速傅里叶变换非常有效地乘2个复多项式算法(附完整源码)
JavaWeb:Maven常识性总结
<C++>深度学习多态
Linux教程
解决pycharm安装opencv没有函数提醒的问题
liteide 找不到 go 路径错误修复
SpringBoot2.0
- 原文地址:https://blog.csdn.net/qq_51070956/article/details/133798307