-
MybatisPlus 从零开始 全面学习!
引入
本文以下将mybatisPlus简称为mp
首先注意: mybatisPlus不是mybatis 的替代品,而是增强mybatis的技术.
只做增强不做改变, 引入他不会对现有工程产生影响.


快速入门
基本步骤



以下为mapper例子:
要继承这个BaseMapper类, 并在泛型括号中 标注好要操作的类
- public interface UserMapper extends BaseMapper
{ - void saveUser(User user);
- void deleteUser(Long id);
- void updateUser(User user);
- User queryUserById(@Param("id") Long id);
- List
queryUserByIds(@Param("ids") List ids) ; - }

常用注解
注意:mp遵守的约定如下,如不符合则使用右图注解来标记
mp要操作, 表中必须有一个主键, 否则它无法进行自动操作


举例使用如下;
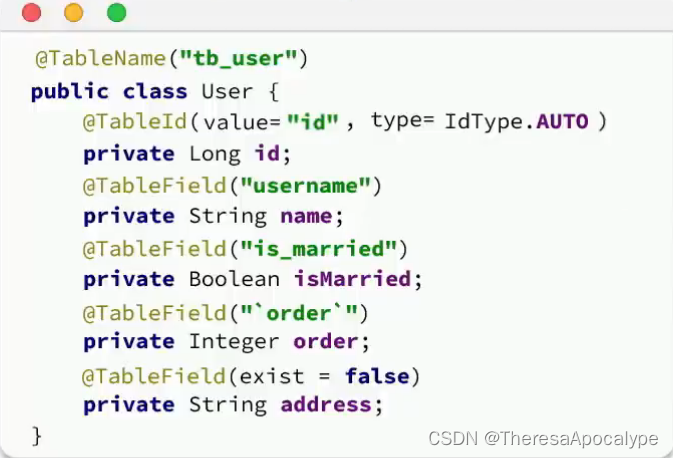
注意:如果不指定主键的设置方法 ,默认为雪花算法自动生成


常用配置

附带了全局配置,但是配置优先级不如局部配置
使用的完整流程

核心功能
条件构造器


 案例
案例基于以下原始sql设计mp语句

- QueryWrapper
wrapper = new QueryWrapper () - .select("id","username","info")
- .like("username","o")
- .ge("balance","1000");
- void testUpdateById() {
- /*要更新的数据*/
- User user = new User();
- user.setBalance(2000);
- /*更新条件*/
- QueryWrapper
wrapper = new QueryWrapper () - .eq("username","jack");
- userMapper.update(user,wrapper);
- }
IService(核心)


新增用户操作: 不需要写service代码,只需要在mapper层注入service并调用相应方法即可
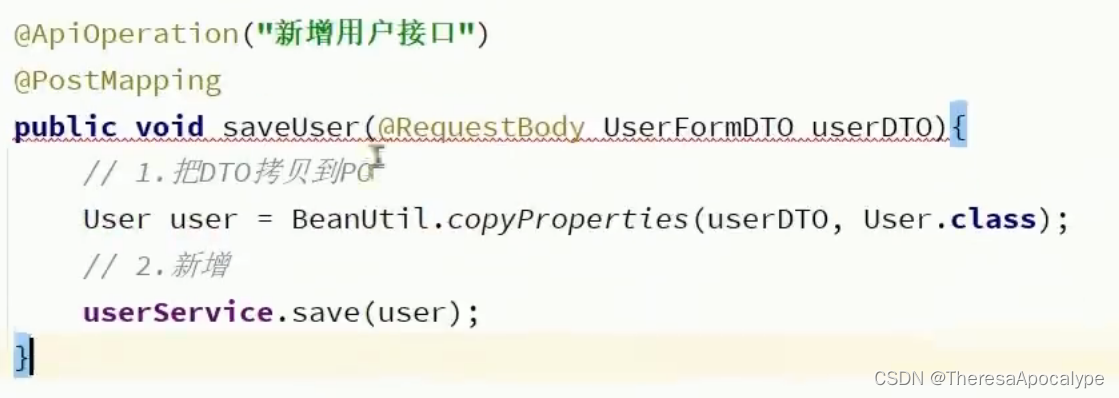
删除用户操作: 也不需要写service代码,只需要在mapper层注入service并调用相应方法即可

查询(批量)用户操作同理

复杂的业务逻辑, 我们可以在service层中, 通过条件判断 规避掉复杂的语句, 如下使用if. 再用mapper执行简单的sql语句


批量新增

首先修改批处理配置 设置为true

一次插入要多少 就准备多大的集合, 然后通过循环把每一条数据装载到list中, 每当达到上限时 就使用service的方法执行sql. 然后清空list 继续装载下一批.

扩展功能
1.代码生成器
使用步骤


此处可能会有时区错误,尝试输入以下url:
jdbc:mysql://localhost/mp?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC

然后点击提交,这个插件便会帮你自动生成对应的代码框架,大大简化了重复代码的劳动
2.静态工具(待完善)
3.逻辑删除


4.枚举处理器(待完善)
插件功能(待完善)
分页查询插件
总结
学完mp以后, 我认为他最大的优势在于写简单crud方面很便捷, 但在写复杂sql语句时不如使用mybatis来的快, xml的可读性甚至比这更高一些,复用也更强.
同时,使用Iservice虽然便捷, 但是对于service层的侵入 是好是坏还有待考究.
-
相关阅读:
MySQL - 深入解析MySQL索引数据结构
(操作系统开发)从实模式---->保护模式---->IA-32e模式( 64位模式)
maven(一):是否有必要使用maven
Java字符串(String类)
vue 如何依次请求多个 axios 请求,同步请求多个,按次序请求
网络安全等级保护测评师定义以及主要工作任务是什么?
Node.js 2022.11.3
kettle 使用动态变量名定义变量
中秋节学习腾讯云轻量应用服务器
jquery的使用
- 原文地址:https://blog.csdn.net/TheresaApocaly/article/details/133708310