-
深入篇【C++】总结<lambda表达式>与<包装器和bind>的使用与意义
深入篇【C++】总结<lambda表达式>与<包装器和bind>的使用与意义
一.lambda表达式
如果我们想对一个数组进行排序,怎么排序呢?
首先这里要分数组里的数据是什么类型,是内置类型呢?还是自定义类型呢?
如果是自定义类型,比如int类型,那么就可以直接利用大小进行比较。int main() { vector<int> v= { 4,1,8,5,3,7,0,9,2,6 }; //给内置类型进行排序,即就是用大小进行比较 sort(v.begin(), v.end()); //默认是升序 //如果向降序则需要传递仿函数对象 sort(v.begin(), v.end(), greater<int>()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
那如果数据是自定义类型呢?该如何进行比较呢?根据什么进行比较呢?
比如一个自定义类型商品,基本信息有名字价格和评价。struct Goods { string _name; //名称 double _price; // 价格 int _evaluate; // 评价 Goods(const char* str, double price, int evaluate) :_name(str) ,_price(price) ,_evaluate(evaluate) {} };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
那么当数组里都是商品数据时,我们想对这个数组进行排序呢?
int main() { vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } }; //怎么对这些商品进行排序呢? }- 1
- 2
- 3
- 4
- 5
- 6
- 7
首先直接将自定义类型放入sort里进行排序肯定是不行的,sort里的排序默认是根据int类型的大小进行比较的。所以这时如果想要对商品进行排序就需要使用仿函数。利用仿函数来进行比较。
//对应自定义类型的比较,就需要使用仿函数 struct ComparePriceLess { bool operator()(const Goods& gl, const Goods& gr) { return gl._price < gr._price; } }; struct ComparePriceGreater { bool operator()(const Goods& gl, const Goods& gr) { return gl._price > gr._price; } }; int main() { vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } }; sort(v.begin(), v.end(), ComparePriceLess());//通过价格比较--升序 sort(v.begin(), v.end(), ComparePriceGreater());//通过价格比较--降序 //按照价格进行比较,那我想要用评价进行比较呢?名称进行比较呢? }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
那如果我们想根据商品的评价进行比较呢?根据商品的名字进行比较呢?
这就需要再重写仿函数。struct Compare_eval_Greater { bool operator()(const Goods& gl, const Goods& gr) { return gl._evaluate > gr._evaluate; } }; struct Compare_eval_Less { bool operator()(const Goods& gl, const Goods& gr) { return gl._evaluate < gr._evaluate; } }; struct Compare_name_Greater { bool operator()(const Goods& gl, const Goods& gr) { return gl._name > gr._name; } }; struct Compare_name_Less { bool operator()(const Goods& gl, const Goods& gr) { return gl._name < gr._name; } }; int main() { vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } }; //按照价格进行比较,那我想要用评价进行比较呢?名称进行比较呢? sort(v.begin(), v.end(), Compare_eval_Greater());//通过评价比较--降序 sort(v.begin(), v.end(), Compare_eval_Less());//通过评价比较--升序 sort(v.begin(), v.end(), Compare_name_Greater());//通过名字比较--降序 sort(v.begin(), v.end(), Compare_name_Less());//通过名字比较--升序 //每次如果要按照不同的方式进行比较时,就需要再写一个类仿函数,太麻烦了。 //如果每次比较的逻辑不一样,还要去实现多个类, }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
这样写实在太复杂了,每次要按照不同的规则进行比较时就需要重写一个类。有没有更方便的方法呢?
C++11提供了lambda表达式:int main() { vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2, 3 }, { "菠萝", 1.5, 4 } }; sort(v.begin(), v.end(), [](const Goods& gl, const Goods& gr) {return gl._price > gr._price; }); sort(v.begin(), v.end(), [](const Goods& gl, const Goods& gr) {return gl._price < gr._price; }); sort(v.begin(), v.end(), [](const Goods& gl, const Goods& gr) {return gl._evaluate > gr._evaluate; }); sort(v.begin(), v.end(), [](const Goods& gl, const Goods& gr) {return gl._evaluate < gr._evaluate; }); //lambda表达式就是一个匿名对象 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
原本需要重写一个类,现在只要写一行类似表达式的东西就可以了。是不是很神奇。接下来我们就解析这行"表达式"。从上下面对比,这行"表达式"本质上就是一个匿名函数对象。
1.使用语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type {statement }- 1
1.[ ]:称为捕捉列表,在lambda表达式的开头。可以捕捉上下文的变量给lambda函数使用。
2.( ):参数列表,跟函数参数列表是一样的,用来接收函数的参数的,如果函数没有要接收的参数,这个()就可以省略不用写。
3.mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性,使用该修饰符时,参数列表不可以省略。
4.->return type:函数返回值类型。跟函数返回值是类似的,不过当函数没有返回值时,可以省略,但是当有返回值时,也可以省略,因为编译器会自动推到返回值类型。
5.{ }:函数体,跟正常的函数体使用即可,这里面不仅可以使用参数外,还可以使用捕捉列表捕捉的变量。
6.最简单的lambda函数就是[] { };该函数什么都不会做。int main() { int a = 1, b = 2; auto fun1 = [](int a, int b) {return a + b; };//lambda函数 cout << fun1(a, b) << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
lambda函数是不能直接调用的,因为它是一个匿名函数,我们也不知道它的名字是什么,但如果想要调用lambda函数,我们可以利用auto将其赋值给一个变量。(auto可以自动推导lambda函数的类型)
【捕捉列表细节】:捕捉列表描述了上下文里哪些数据可以被lambda函数使用,已经使用的方式是传值还是传引用。
1.[变量]:表示以值传递方式捕捉变量
2.[&变量]:表示以传引用方式捕捉变量
3.[=]:表示以值传递方式捕获父作用域里的所有变量。
4.[&]:表示以引用方式捕捉父作用域里的所有变量。
5.捕捉列表允许多个捕捉项,之间用逗号分割。
6.不允许重复捕捉,不然会报错。int main() { int a = 1, b = 2; double rate1 = 10.0,rate2=10.2; auto fun1 = [rate1](int a, int b) {return (a + b)*rate1; }; //捕捉列表,捕捉变量rate1后,函数体里就可以用该变量--->传值方式捕捉 auto fun2 = [&rate1](int a, int b) {return (a + b) * rate1; }; //捕捉列表,捕捉变量rate1后,函数体里就可以用该变量--->引用方式捕捉 auto fun3 = [=](int a, int b) {return (a + b) * rate1/rate2; }; //捕捉列表,捕捉全部变量,函数体里就可以用该作用域里的所有变量--->传值方式捕捉 auto fun4 = [&](int a, int b) {return (a + b) * rate1 / rate2; }; //捕捉列表,捕捉全部变量,函数体里就可以用该作用域里的所有变量--->引用方式捕捉 cout << fun1(a, b) << endl; cout << fun2(a, b) << endl; cout << fun3(a, b) << endl; cout << fun4(a, b) << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.底层本质
这么神奇的lambda表达式是如何搞出来的呢?其实lambda表达式并不神奇,它底层就是仿函数。实际在底层编译器对应lambda表达式的处理上,完全就和函数对象的方式处理进行的。函数对象是如何处理的呢?就是定义一个类,类里重载了()运算符重载。然后利用这个类定义个对象,该对象可以像函数一样被调用。所以如果定义了一个lambda表达式,编译器就会自动生成一个类,并在这个类里重载()运算符。

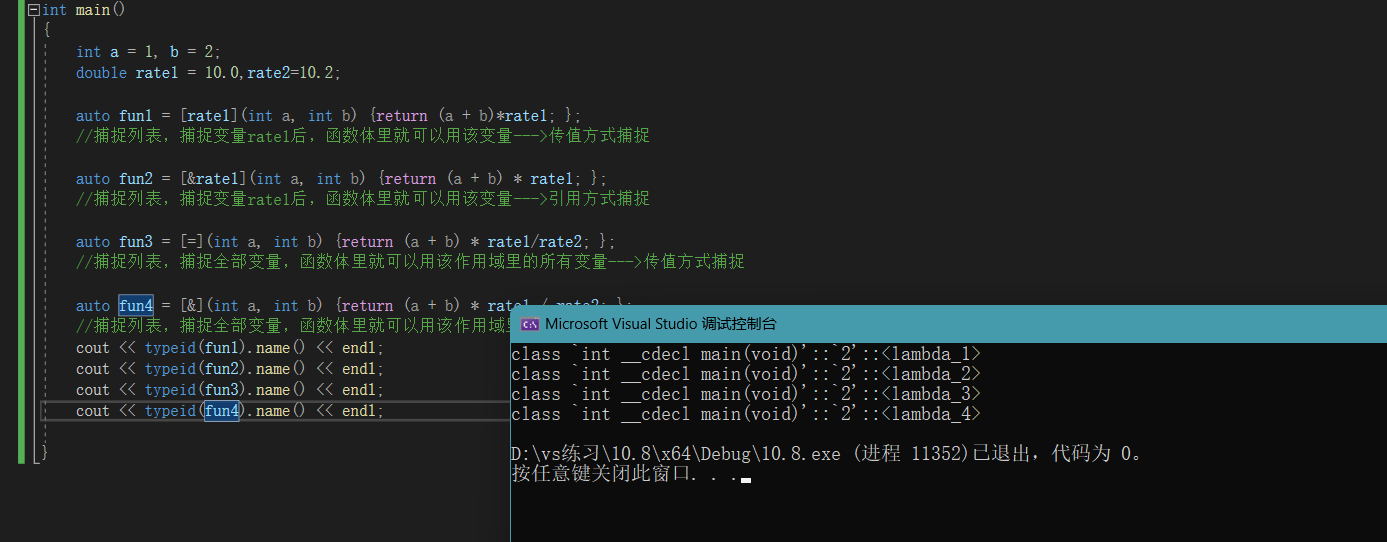
而且不同lambda函数的底层的创建的类名称是不一样的。
所以lambda函数之间是不可以互相赋值的(不同类型,无法赋值)。3.应用意义
lambda表达式用起来还是很香的。对于那些比较规则可能有很多种的情况,非常适合使用,主要是看起来很简便,并且不需要再重写一个类,就在函数体里更改即可。
二.包装器(适配器)
可调用对象都有哪些呢?
1.函数指针
2.函数对象
3.lambda函数1.使用语法
std::function在头文件< functional>
// 类模板原型如下
template function;
template
class function
模板参数说明:
Ret: 被调用函数的返回类型
Args…:被调用函数的形参也就是当引用头文件functional后,我们就可以使用包装器function。
function与其他模板有些区别:function<返回值(参数)>。2.解决问题①
可调用对象存在多种,当我们写一个需要传可调用对象参数的类时,使用模板,当传不同的可调用对象时就会实例化出不同的类模板,造成模板使用效率低效。
template<class F, class T> T useF(F f, T x) { static int count = 0; cout << "count:" << ++count << endl; cout << "count:" << &count << endl; return f(x); } //f函数指针 double f(double i) { return i / 2; } //functor()函数对象 struct Functor { double operator()(double d) { return d / 3; } }; int main() { // 函数名 cout << useF(f, 11.11) << endl; // 函数对象 cout << useF(Functor(), 11.11) << endl; // lamber表达式 cout << useF([](double d){ return d / 4; }, 11.11) << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

我们会发现useF函数模板实例化了三份。
当我们使用包装器时,将可调用对象:函数指针,函数对象,lambda函数,都可以封装在包装器里。
然后我们就可以统一调用不同的包装器(不同的包装器里包装着不同的可调用对象)。虽然是不同的包装器但是同一类型,所有最后只会实例化出一份。int main() { // 函数名 cout << useF(f, 11.11) << endl; // 函数对象 cout << useF(Functor(), 11.11) << endl; // lamber表达式 cout << useF([](double d){ return d / 4; }, 11.11) << endl; cout << endl; function<double(double)> f1 = f; function<double(double)> f2 = Functor(); function<double(double)> f3 = [](double d) { return d / 4; }; //将函数指针 /函数对象 /lambda函数包装到包装器里 //统一调用包装器f1,f2,f3.它们的类型都是一样的。 cout << useF(f1, 11.11) << endl; cout << useF(f2, 11.11) << endl; cout << useF(f3, 11.11) << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

3.解决问题②
问题:如何将可调用对象存储到容器里即:可调用对象类型问题
想要将可调用对象存储到容器里,首先我们得需要知道它的类型,函数指针的类型实在是太麻烦了,而仿函数类型我们是可以知道,但lambda的类型我们是不知道的,所以难道容器里只能存储仿函数吗?不能存储lambda函数。包装器就可以解决可调用对象的类型问题,它可以将函数指针,函数对象,lambda包装起来,并且这个包装的类型我们是知道的。那么我们就可以利用这个包装器将lambda包装起来,然后再存储这个包装器即可,这样lambda函数就被存储到容器里了。不仅是lambda函数被存储到容器里了,是所有的可调用对象都可以被存储到容器里了。
int main() { // 函数名 cout << useF(f, 11.11) << endl; // 函数对象 cout << useF(Functor(), 11.11) << endl; // lamber表达式 cout << useF([](double d){ return d / 4; }, 11.11) << endl; cout << endl; function<double(double)> f1 = f; //包装函数指针 function<double(double)> f2 = Functor(); //包装函数对象 function<double(double)> f3 = [](double d) { return d / 4; }; //包装lambda函数 //将函数指针 /函数对象 /lambda函数包装到包装器里 这样可调用对象的类型就统一为包装器类型 vector<function<double(double)>> v = { f1,f2,f3 }; //可调用对象(包装器)就可以存储到容器里面了 也可以直接这样写: //vector- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
4.应用场景:指令+操作
现实中有很多这样的场景:指令+操作。就是输入对应的命令,就会给你回应对应的操作。
比如游戏中,各种按键,会引起人物不同的动作,这就是指令+操作。这该如何实现呢?
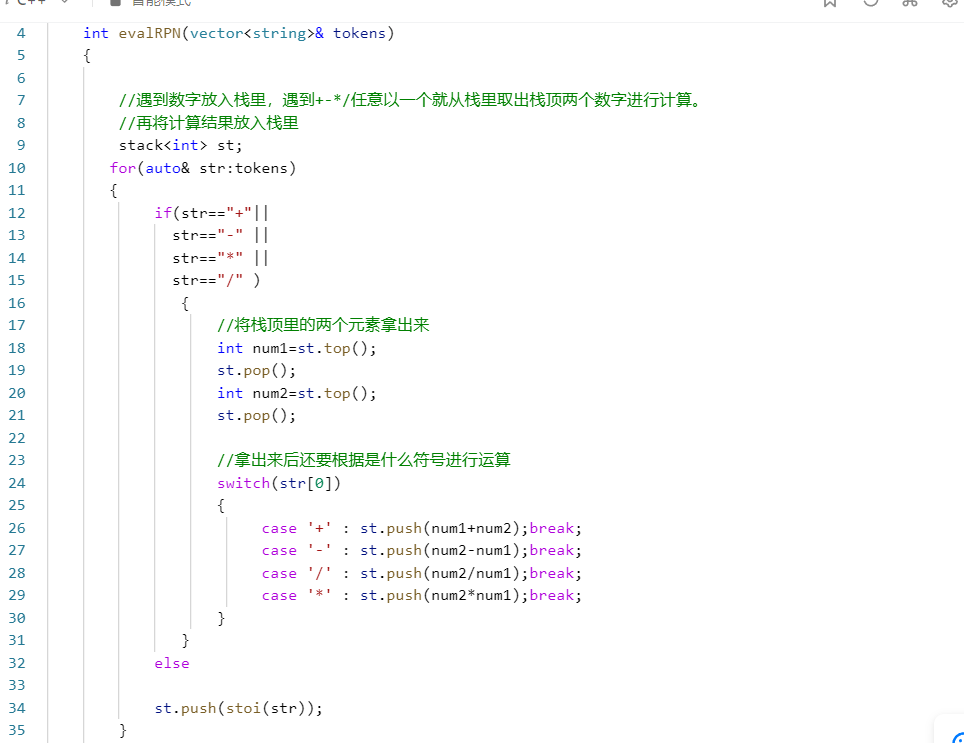
就是用容器map里面存储着指令,而指令对应着操作。操作也就是各种函数。也就是map里要存储"指令"和"函数操作".这个函数操作可以是函数指针,函数对象,lambda函数,反正是一个可调用的对象。这种情形应用很多。比如linux中的各种命令,也会对应着各种操作。比如cd,进入目录等待,也可以利用这里的原理设计出来。就比如下面这个逆波兰值的求解:

里面我们就可以将对应的+ -* /都直接对应成相应的函数。然后将函数存储在map里。
普通版本:
包装器版本:
三.bind (适配器)
bind是一个函数模板,它就类似一个包装器,可以将一个可调用对象,包装生成一个新的可调用对象来适应原对象的参数列表。也就是我们可以将一个原本有n个参数的函数,通过bind绑定一些参数,最后生成只需要传m个参数的新函数(m比n小)。并且bind还可以用来调整函数的参数位置。
1.调整参数位置
使用方法:
auto newfunc=bind(func,arg_list) 1.newfunc是一个可调用对象 2.func是要被包装的可调用对象 3.arg_list是这个可调用对象的参数列表。- 1
- 2
- 3
- 4
bind类似于一个包装器,是可以用来调整函数参数的位置。那么它是如何调整的呢?它是通过bind的占位符来实现的。当我们调用newfunc这个可调用对象时,newfunc会调用func,并且会将arg_list对应的参数传给func。
#includeusing namespace std; #include int Sub(int a, int b) { return a - b; } int main() { //包装器只是将函数包装起来,它也就相当于是一个可调用对象,直接调用包装器即可 function<int(int, int)> fsub = bind(Sub, placeholders::_1, placeholders::_2); //1.bind可以调整函数参数位置 cout << fsub(4, 3) << endl; function<int(int, int)> fsubreserve = bind(Sub, placeholders::_2, placeholders::_1); //第一个实参还是传给_1,第二个实参还是传给_2;而bind还是按照位置将参数传给函数形参 cout << fsubreserve(4, 3) << endl; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

通过调整bind的占位符顺序,就可以调整函数的参数位置了。因为第一个实参设定传给的就是占位符1,第二个实参设定传给的就是占位符2.而占位符则是按照顺序传给函数的形参。2.绑定参数
bind不仅可以调整可调用对象的参数位置。(通过包装可调用对象适配出想要的参数位置)。
还可以用来固定参数值。类似于缺省参数的功能。在包装这个可调用对象时就可以将对象的参数固定。而不需要去对象的内部。#includedouble Plus(int a, int b, double rate) { return (a + b) * rate; } double PPlus(int a, double rate, int b)//函数右多个参数时 { return rate * (a + b); } int main() { //2.bind可以绑定固定参数 //可以像缺省参数那样给定一个参数一个默认值,当传参时,就可以不需要传这个参数,使用默认值 function<double(int, int)> fplus1 = bind(Plus, placeholders::_1, placeholders::_2, 4.0); //将可调用对象Plus的第三个参数值固定为4.0 function<double(int, int)> fplus2 = bind(Plus, placeholders::_1, placeholders::_2, 4.2); //将可调用对象Plus的第三个参数值固定为4.2 function<double(int, int)> fplus3 = bind(Plus, placeholders::_1, placeholders::_2, 4.3); //将可调用对象Plus的第三个参数值固定为4.3 cout << fplus1(4, 3) << endl; cout << fplus2(4, 3) << endl; cout << fplus3(4, 3) << endl; //可以固定不同位置上的参数 function<double(int, int)> fpplus1 = bind(PPlus, placeholders::_1, 4.0, placeholders::_2); //绑定中间参数 function<double(int, int)> fpplus2 = bind(PPlus, placeholders::_1, 4.2, placeholders::_2); //要注意,这里面还是_1和_2两个指示数。虽然是pplus函数里的参数是第一个和第三个,固定的是第二个参数 //但还是用_1和_2来接收。这里决定是由函数要传几个参数决定是否要用_3的。如果要传3个参数,那么就会用到_3. - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
但它不像缺省参数,缺省参数是写死了,只能定义一种类型的函数。(因为缺省参数需要在函数内部写,一旦函数内部写完,外部就无法改动了)
但bind可以灵活的调整可调用对象参数的值,不需要到函数里面去改动,直接在函数外面调整就可以同时写出多个不同需求的函数。那bind如何绑定类里面的成员函数呢(公有的成员函数)?
class AB { public: int abfunc(int a, int b) { return a - b; } }; // //绑定类成员函数………… // //绑定类成员函数有些奇怪 // int main() { function<int(int, int)> fab = bind(&AB::abfunc,AB(), placeholders::_1, placeholders::_2); cout << fab(1, 1) << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
相关阅读:
关于最新版本Burp Suite可以在哪个基本类别中找到控制其更新行为的“更新”子类别
决策树与随机森林
Cadence IC618使用
设计模式之策略模式
Java学习----前端2
【Locust】模拟多用户并发与实战
【HMS core】【Ads Kit】华为广告——海外应用在国内测试正式广告无法展示
Java计算机毕业设计铜仁学院毕业就业管理系统源码+系统+数据库+lw文档
区块链论文速读A会-ISSTA 2023(1/2)法律协议如何变成智能合约代码?
商城免费搭建之java商城 java电子商务Spring Cloud+Spring Boot+mybatis+MQ+VR全景+b2b2c
- 原文地址:https://blog.csdn.net/Extreme_wei/article/details/133683642
