-
9.2.5.2 【MySQL】XDES 类型
每一个 XDES Entry 结构对应表空间的一个区,虽然一个 XDES Entry 结构只占用40字节,但你抵不住表空间的区的数量也多啊。在区的数量非常多时,一个单独的页可能就不够存放足够多的 XDES Entry 结构,所以我们把表空间的区分为了若干个组,每组开头的一个页面记录着本组内所有的区对应的 XDES Entry 结构。由于第一个组的第一个页面有些特殊,因为它也是整个表空间的第一个页面,所以除了记录本组中的所有区对应的 XDES Entry 结构以外,还记录着表空间的一些整体属性,这个页面的类型就是我们刚刚说完的 FSP_HDR 类型,整个表空间里只有一个这个类型的页面。除去第一个分组以外,之后的每个分组的第一个页面只需要记录本组内所有的区对应的 XDES Entry 结构即可,不需要再记录表空间的属性了,为了和 FSP_HDR 类型做区别,我们把之后每个分组的第一个页面的类型定义为 XDES ,它的结构和 FSP_HDR 类型是非常相似的:
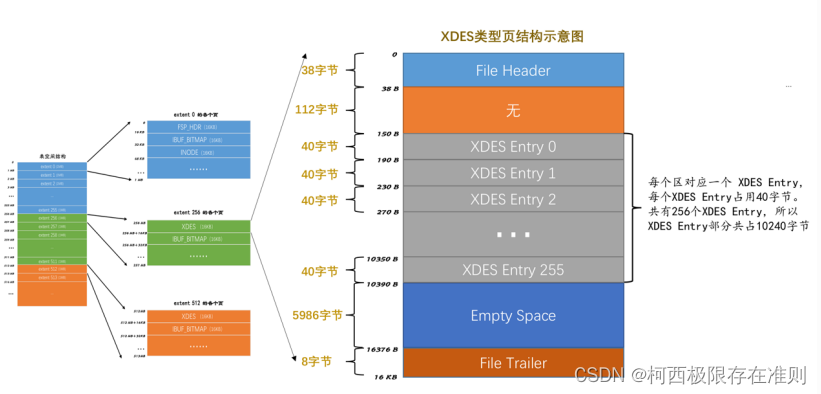
与 FSP_HDR 类型的页面对比,除了少了 File Space Header 部分之外,也就是除了少了记录表空间整体属性的部分之外,其余的部分是一样的。
9.2.5.3 IBUF_BITMAP 类型
根据表空间的图,每个分组的第二个页面的类型都是IBUF_BITMAP,这种类型的页里面记录了Change buffer。
9.2.5.4 INDODE 类型
一个INODE类型的页面是由这几部分构成的:
名称
中文名
占用空间大小
简单描述
File Header
文件头部
38字节
页的一些通用信息
List Node for INODE Page List
通用链表节点
12 字节
存储上一个INODE页面和下一个INODE页面的指针
INODE Entry
段描述信息
16128 字节
Empty Space
尚未使用空间
6 字节
用于页结构的填充,没啥实际意义
File Trailer
文件尾部
8 字节
校验页是否完整
每个 INODE Entry 结构占用192字节,一个页面里可以存储 85 个这样的结构。
一个表空间中可能存在超过85个段,所以可能一个 INODE 类型的页面不足以存储所有的段对应的 INODE Entry 结构,所以就需要额外的 INODE 类型的页面来存储这些结构。还是为了方便管理这些 INODE 类型的页面,于是这些INODE类型的页面串联成两个不同的链表:
SEG_INODES_FULL 链表:该链表中的 INODE 类型的页面中已经没有空闲空间来存储额外的 INODE Entry 结构了。
SEG_INODES_FREE 链表:该链表中的 INODE 类型的页面中还有空闲空间来存储额外的 INODE Entry 结构了。
每当我们新创建一个段(创建索引时就会创建段)时,都会创建一个 INODE Entry 结构与之对应,存储 INODE Entry 的大致过程就是这样的:
- 先看看 SEG_INODES_FREE 链表是否为空,如果不为空,直接从该链表中获取一个节点,也就相当于获取到一个仍有空闲空间的 INODE 类型的页面,然后把该 INODE Entry 结构防到该页面中。当该页面中无剩余空间时,就把该页放到 SEG_INODES_FULL 链表中。
- 如果 SEG_INODES_FREE 链表为空,则需要从表空间的 FREE_FRAG 链表中申请一个页面,修改该页面的类型为 INODE ,把该页面放到 SEG_INODES_FREE 链表中,与此同时把该 INODE Entry 结构放入该页面。
9.2.6 Segment Header结构的运用
一个索引会产生两个段,分别是叶子节点和非叶子节点段,每个段都会对应一个INODE Entry结构。
Page Header部分
名称
占用空间大小
描述
PAGE_BTR_SEG_LEAF
10 字节
B+树叶子段的头部信息,仅在B+树的根页定义
PAGE_BTR_SEG_TOP
10 字节
B+树非叶子段的头部信息,仅在B+树的根页定义
其中的 PAGE_BTR_SEG_LEAF 和 PAGE_BTR_SEG_TOP 都占用10个字节,它们其实对应一个叫 Segment Header 的结构,该结构图示如下:

各个部分的具体释义如下:
名称
占用字节数
描述
Space ID of the INODE Entry
4
INODE Entry结构所在的表空间ID
Page Number of the INODE Entry
4
INODE Entry结构所在的页面页号
Byte Offset of the INODE Ent
2
INODE Entry结构在该页面中的偏移量
PAGE_BTR_SEG_LEAF 记录着叶子节点段对应的 INODE Entry 结构的地址是哪个表空间的哪个页面的哪个偏移量, PAGE_BTR_SEG_TOP 记录着非叶子节点段对应的 INODE Entry 结构的地址是哪个表空间的哪个页面的哪个偏移量。这样子索引和其对应的段的关系就建立起来了。不过需要注意的一点是,因为一个索引只对应两个段,所以只需要在索引的根页面中记录这两个结构即可。
-
相关阅读:
打破内卷宿命,电商只能出海,必须出海!
【ACM】前言(1)
能ping通但无法上网的问题
《rust学习一》 fleet 配置rust环境
Word | 添加图题/图注、插入题注、设置插入题注快捷键...
商城项目10_JSR303常用注解、在项目中如何使用、统一处理异常、分组校验功能、自定义校验注解
基于Python的大区域SPI标准降水指数自动批量化处理
redis + AOP + 自定义注解实现接口限流
ThreadPoolExecutor 类
【Proteus仿真】【STM32单片机】蔬菜大棚温湿度控制系统设计
- 原文地址:https://blog.csdn.net/qq_43714918/article/details/133633567