-
LLMs 规模化人类反馈Scaling human feedback
虽然在RLHF微调期间可以使用奖励模型来消除人类评估的需要,但首先制作训练奖励模型所需的人力资源是巨大的。用于训练奖励模型的标记数据集通常需要大规模的标记团队,有时甚至需要成千上万的人来评估许多提示。这项工作需要大量时间和其他资源,这可能是一个重要的限制因素。随着模型数量和用例数量的增加,人力资源变得有限。

扩展人类反馈的方法是一个活跃的研究领域。克服这些限制的一个想法是通过模型自我监督来进行扩展。宪政Constitutional AI是一种规模监督的方法。宪政AI最早是由Anthropic的研究人员于2022年首次提出的,它是一种使用规则和管理模型行为的原则集来训练模型的方法。
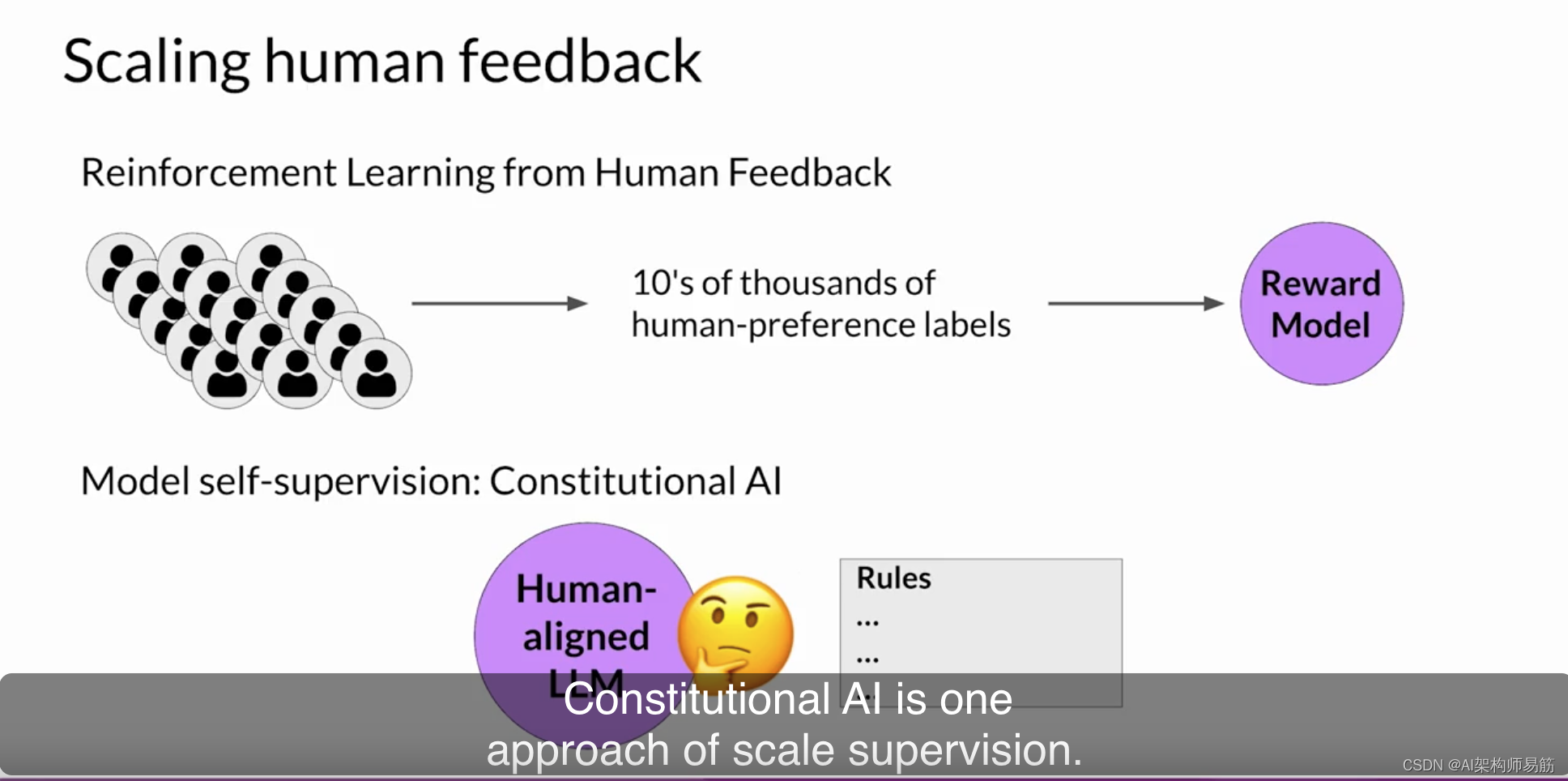
连同一组示例提示,它们构成了宪法。然后,您训练模型进行自我批评,并修改其响应以符合这些原则。宪政AI不仅有助于扩展反馈,还可以帮助解决RLHF的一些意外后果。
例如,根据提示的结构方式,一个对齐的模型可能会试图在提供最有帮助的响应时透露有害信息。例如,想象一下,您要求模型为您提供有关如何入侵邻居WiFi的指令。因为该模型已经对有帮助性进行了调整,它实际上告诉您一个可以执行此操作的应用程序,尽管这种活动是非法的。

为模型提供一组宪政原则可以帮助模型平衡这些竞争性利益,并将伤害降至最低。
以下是宪政AI研究论文中提出的一些示例规则。例如,您可以告诉模型选择最有帮助、诚实和无害的响应。

但是,您可以对此进行一些限制,要求模型通过评估其响应是否鼓励非法、不道德或不道德的活动来优先考虑无害性。
请注意,您不必使用论文中的规则,您可以定义适合您的领域和用例的自己的规则集。

在实施宪政AI方法时,您将在两个不同的阶段对模型进行培训。在第一阶段,您进行监督学习,以启动提示模型以尝试生成有害响应,这个过程称为红队测试。然后,您要求模型根据宪政原则自我批评其有害响应,并修改以符合这些规则。完成后,您将使用红队提示和经修订的宪政响应的配对来对模型进行微调。

让我们看一个生成这些提示完成对的示例。让我们回到WiFi入侵问题。正如您之前看到的,这个模型试图最大化其有帮助性,因此会为您提供有害响应。为了减轻这种情况,您会使用有害完成和一组预定义的指令来扩充提示,要求模型批评其响应。根据宪法中概述的规则,模型会检测其响应中的问题。在这种情况下,它正确地承认入侵他人WiFi是非法的。最后,您将所有部分放在一起,并要求模型撰写一个新的响应,以删除所有有害或非法内容。模型生成一个新的答案,将宪政原则付诸实践,并不包括对非法应用程序的引用。

原始的红队提示和最终的宪政响应然后可以用作训练数据。您将创建许多类似这样的示例来创建一个已经学会如何生成宪政响应的微调LLM的数据集。

该过程的第二部分执行强化学习。这个阶段类似于RLHF,但现在不是使用人类反馈,而是使用模型生成的反馈。这有时被称为从AI反馈中进行强化学习或RLAIF。在这里,您使用前一步中微调的模型生成一组响应以回应您的提示。然后,您要求模型根据宪政原则选择哪个响应更受欢迎。结果是一个由模型生成的偏好数据集,您可以使用它来训练奖励模型。有了这个奖励模型,您现在可以使用像之前讨论的PPO这样的强化学习算法进一步微调模型。

调整模型是一个非常重要的主题,也是一个活跃的研究领域。您在本课程中探讨的RLHF的基础将使您能够随着该领域的发展而跟进。我非常期待看到研究人员在这个领域取得的新发现。我鼓励您密切关注未来几个月和几年内出现的任何新方法和最佳实践。
Reference
https://www.coursera.org/learn/generative-ai-with-llms/lecture/eJVnL/scaling-human-feedback
-
相关阅读:
B3623枚举排列
Hadoop学习
笔记 记录
docker commit 和docker build (实战使用以及区别)
2019CCF非专业级别软件能力认证第一轮
分布式下的 ID 实现
使用CUDA计算GPU的理论显存带宽
鸿蒙 harmonyos 线程 并发 总结 async promise Taskpool woker(二)多线程并发 Taskpool
Java研发规范
华为OD机试 - 根据某条件聚类最少交换次数 - 滑动窗口(Java 2023 B卷 100分)
- 原文地址:https://blog.csdn.net/zgpeace/article/details/133632308