-
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成
目录
过去十年主要研究图像表示的方法:图像级别(图像分类/图像-文本检索/图像字幕)→区域级别(目标检测/短语定位)→像素级别(语义/实例/全景分割)
如何学习图像表示:两种方法(图像中挖掘出的监督信号/从Web上挖掘的图像-文本数据集的语言监督)、三种学习方式(监督预训练/CLIP/仅图像的自监督学习)
Figure 2.1: An overview of the structure of Chapter 2.
Table 2.1: Statistics of existing large-scale image classification datasets
2.3、Contrastive Language-Image Pre-training对比语言-图像预训练
2.3.1、Basics of CLIP Training-CLIP训练基础
语言数据+训练方式,如CLIP/ALIGN/Florence/BASIC/OpenCLIP等
固定数据集并设计不同的算法→DataComp提出转向→固定的CLIP训练方法来选择和排名数据集
Objective function.目标函数:细粒度监督、对比式描述生成、仅使用字幕损失、用于语言-图像预训练的Sigmoid损失
2.4、Image-Only Self-Supervised Learning仅图像自监督学习:三类(对比学习/非对比学习/遮蔽图像建模)
2.4.1、Contrastive and Non-contrastive Learning
Non-contrastive learning.非对比学习
2.4.2、Masked Image Modeling遮蔽图像建模
Figure 2.9: Illustration of Masked Autoencoder (MAE)
Targets目标:两类(低级像素特征【更细粒度图像理解】、高级特征),损失函数的选择取决于目标的性质,离散标记的目标(通常使用交叉熵损失)+像素值或连续值特征(选择是ℓ1、ℓ2或余弦相似度损失)
MIM for video pre-training视频预训练的MIM:将MIM扩展到视频预训练,如BEVT/VideoMAE/Feichtenhofer
Lack of learning global image representations全局图像表示的不足,如iBOT/DINO/BEiT等
Scaling properties of MIM—MIM的规模特性:尚不清楚探讨将MIM预训练扩展到十亿级仅图像数据的规模
2.5、Synergy Among Different Learning Approaches不同学习方法的协同作用
Combining CLIP with label supervision将CLIP与标签监督相结合,如UniCL、LiT、MOFI
Figure 2.11: Illustration of MVP (Wei et al., 2022b), EVA (Fang et al., 2023) and BEiTv2 (Peng
Combining CLIP with image-only (non-)contrastive learning将CLIP与图像仅(非)对比学习相结合:如SLIP、xCLIP
Combining CLIP with MIM将CLIP与MIM相结合
浅层交互:将CLIP提取的图像特征用作MIM训练的目标(CLIP图像特征可能捕捉了在MIM训练中缺失的语义),比如MVP/BEiTv2等
深度整合:BERT和BEiT的组合非常有前景,比如BEiT-3
2.6、Multimodal Fusion, Region-Level and Pixel-Level Pre-training多模态融合、区域级和像素级预训练
2.6.1、From Multimodal Fusion to Multimodal LLM从多模态融合到多模态LLM
基于双编码器的CLIP(图像和文本独立编码+仅通过两者特征向量的简单点乘实现模态交互):擅长图像分类/图像-文本检索,不擅长图像字幕/视觉问答
OD-based models基于OD的模型:使用共同注意力进行多模态融合(如ViLBERT/LXMERT)、将图像特征作为文本输入的软提示(如VisualBERT)
Figure 2.13: Illustration of UNITER (Chen et al., 2020d) and CoCa (Yu et al., 2022a),
2.6.2、Region-Level Pre-training区域级预训练
CLIP:通过对比预训练学习全局图像表示+不适合细粒度图像理解的任务(如目标检测【包含两个子任务=定位+识别】等)
基于图像-文本模型进行微调(如OVR-CNN)、只训练分类头(如Detic)、
2.6.3、Pixel-Level Pre-training像素级预训练(代表作SAE):
Figure 2.15: Overview of the Segment Anything project, which
Concurrent to SAM与SAM同时并行:OneFormer(一种通用的图像分割框架)、SegGPT(一种统一不同分割数据格式的通用上下文学习框架)、SEEM(扩展了单一分割模型)
VG的目的(生成高保真的内容),作用(支持创意应用+合成训练数据),关键(生成严格与人类意图对齐的视觉数据,比如文本条件)
3.1.1、Human Alignments in Visual Generation视觉生成中的人类对齐:核心(遵循人类意图来合成内容),四类探究
Figure 3.1: An overview of improving human intent alignments in T2I generation—T2I生成改善人类意向对齐的概述。
3.1.2、Text-to-Image Generation文本到图像生成
T2I的目的(视觉质量高+语义与输入文本相对应)、数据集(图像-文本对进行训练)
Stable Diffusion的详解:基于交叉注意力的图像-文本融合机制(如自回归T2I生成),三模块(图像VAE+去噪U-Net+条件编码器)
VAE:包含一对编码器E和解码器D,将RGB图像x编码为潜在随机变量z→对潜在变量解码重建图像
文本编码器:使用ViT-L/14 CLIP文本编码器将标记化的输入文本查询y编码为文本特征τ(y)
Figure 3.4: Overview of the ReCo model architecture. Image credit: Yang et al. (2023b).ReCo模型体系结构的概述
去噪U-Net:预测噪声λ (zt, t)与目标噪声λ之间的L2损失来训练
3.2、Spatial Controllable Generation空间可控生成
痛点:仅使用文本在某些描述方面是无效(比如空间引用),需额外空间输入条件来指导图像生成
Region-controlled T2I generation区域可控T2I生成:可显著提高生成高分辨率图像,但缺乏空间可控性,需开放性文本描述的额外输入条件,如ReCo/GLIGEN
GLIGEN:即插即用的方法,冻结原始的T2I模型+训练额外的门控自注意层
T2I generation with dense conditions—T2I生成与密集条件
ControlNet:基于稳定扩散+引入额外的可训练的ControlNet分支(额外的输入条件添加到文本提示中)
Uni-ControlNet(统一输入条件+使单一模型能够理解多种输入条件类型)、Disco(生成可控元素【人类主题/视频背景/动作姿势】人类跳舞视频=成功将背景和人体姿势条件分开;
ControlNet的两个不同分支【图像帧+姿势图】,人类主体、背景和舞蹈动作的任意组合性)
Inference-time spatial guidance推理时的空间指导:
文本到图像编辑:通过给定的图像和输入文本描述合成新的图像+保留大部分视觉内容+遵循人类意图
三个代表性方向:改变局部图像区域(删除或更高)、语言用作编辑指令、编辑系统集成不同的专业模块(如分割模型和大型语言模型)
Figure 3.8: Examples of text instruction editing. Image credit: Brooks et al. (2023).文本指令编辑的示例
3.4、Text Prompts Following文本提示跟随
采用图像-文本对鼓励但不强制完全遵循文本提示→当图像描述变得复时的两类研究=推断时操作+对齐调整
Summary and trends总结和趋势:目的(增强T2I模型更好地遵循文本提示能力),通过调整对齐来提升T2I模型根据文本提示生成图像的能力,未来(基于RL的方法更有潜力但需扩展)
3.5、Concept Customization概念定制:旨在使这些模型能够理解和生成与特定情况相关的视觉概念
语言的痛点:表达人类意图强大但全面描述细节效率较低,因此直接通过图像输入扩展T2I模型来理解视觉概念是更好的选择
三大研究(视觉概念自定义在T2I模型中的应用研究进展):单一概念定制、多概念定制、无Test-time微调的定制
Summary and trends摘要和趋势:早期(测试阶段微调嵌入)→近期(直接在冻结模型中执行上下文图像生成),两个应用=检索相关图像来促进生成+基于描述性文本指令的统一图像输入的不同用途
3.6、Trends: Unified Tuning for Human Alignments趋势:人类对齐的统一调整
调整T2I模型以更准确地符合人类意图的三大研究:提升空间可控性、编辑现有图像以改进匹配程度、个性化T2I模型以适应新的视觉概念
一个趋势:即朝着需要最小问题特定调整的整合性对齐解决方案转移
对齐调优阶段有两个主要目的:扩展了T2I的文本输入以合并交错的图像-文本输入,通过使用数据、损失和奖励来微调基本的T2I模型
Tuning with alignment-focused loss and rewards以对齐为焦点的损失和奖励的调整:
Closed-loop of multimodal content understanding and generation多模态内容理解和生成的闭环
相关文章
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之简介
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之视觉理解、视觉生成_一个处女座的程序猿的博客-CSDN博客
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之统一的视觉模型、加持LLMs的大型多模态模型
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之统一的视觉模型、加持LLMs的大型多模态模型-CSDN博客
AGI之MFM:《Multimodal Foundation Models: From Specialists to General-Purpose Assistants多模态基础模型:从专家到通用助手》翻译与解读之与LLM协同工作的多模态智能体、结论和研究趋势
AGI之MFM:《多模态基础模型:从专家到通用助手》翻译与解读之与LLM协同工作的多模态智能体、结论和研究趋势-CSDN博客
2、Visual Understanding视觉理解
过去十年主要研究图像表示的方法:图像级别(图像分类/图像-文本检索/图像字幕)→区域级别(目标检测/短语定位)→像素级别(语义/实例/全景分割)
Over the past decade, the research community has devoted significant efforts to study the acquisition of high-quality, general-purpose image representations. This is essential to build vision foundation models, as pre-training a strong vision backbone to learn image representations is fundamental to all types of computer vision downstream tasks, ranging from image-level (e.g., image classifica- tion (Krizhevsky et al., 2012), image-text retrieval (Frome et al., 2013), image captioning (Chen et al., 2015)), region-level (e.g., object detection (Girshick, 2015), phrase grounding (Plummer et al., 2015)), to pixel-level (e.g., semantic/instance/panoptic segmentation (Long et al., 2015; Hafiz and Bhat, 2020; Kirillov et al., 2019)) tasks.
在过去的十年里,研究界投入了大量的精力来研究高质量、通用性图像表示的方法。这对于构建视觉基础模型至关重要,因为预训练强大的视觉骨干来学习图像表示对于各种类型的计算机视觉下游任务都是基础的,包括从图像级别(例如图像分类(Krizhevsky et al., 2012)、图像-文本检索(Frome et al., 2013)、图像字幕(Chen et al., 2015)),到区域级别(例如目标检测(Girshick, 2015)、短语定位(Plummer et al., 2015)),再到像素级别(例如语义/实例/全景分割(Long et al., 2015; Hafiz and Bhat, 2020; Kirillov et al., 2019))的任务。
如何学习图像表示:两种方法(图像中挖掘出的监督信号/从Web上挖掘的图像-文本数据集的语言监督)、三种学习方式(监督预训练/CLIP/仅图像的自监督学习)
In this chapter, we present how image representations can be learned, either using supervision sig- nals mined inside the images, or through using language supervision of image-text datasets mined from the Web. Specifically, Section 2.1 presents an overview of different learning paradigms, in- cluding supervised pre-training, contrastive language-image pre-training (CLIP), and image-only self-supervised learning. Section 2.2 discusses supervised pre-training. Section 2.3 focuses on CLIP. Section 2.4 discusses image-only self-supervised learning, including contrastive learning, non-contrastive learning, and masked image modeling. Given the various learning approaches to training vision foundation models, Section 2.5 reviews how they can be incorporated for better per- formance. Lastly, Section 2.6 discusses how vision foundation models can be used for finer-grained visual understanding tasks, such as fusion-encoder-based pre-training for image captioning and vi- sual question answering that require multimodal fusion, region-level pre-training for grounding, and pixel-level pre-training for segmentation.
在本章中,我们将介绍如何学习图像表示,要么使用从图像中挖掘出的监督信号,要么通过使用从Web上挖掘的图像-文本数据集的语言监督。
具体而言,第2.1节概述了不同的学习范式,包括监督预训练、对比语言-图像预训练(CLIP)以及仅图像的自监督学习。第2.2节讨论了监督预训练。第2.3节重点讨论CLIP。第2.4节讨论了仅图像的自监督学习,包括对比学习、非对比学习和遮挡图像建模。鉴于训练视觉基础模型的各种学习方法,第2.5节回顾了如何将它们结合起来以获得更好的性能。最后,第2.6节讨论了视觉基础模型如何用于更精细的视觉理解任务,例如基于融合编码器的图像字幕预训练和需要多模态融合的视觉问题回答,区域级预训练的基础和像素级预训练的分割。
2.1、Overview概述
Figure 2.1: An overview of the structure of Chapter 2.
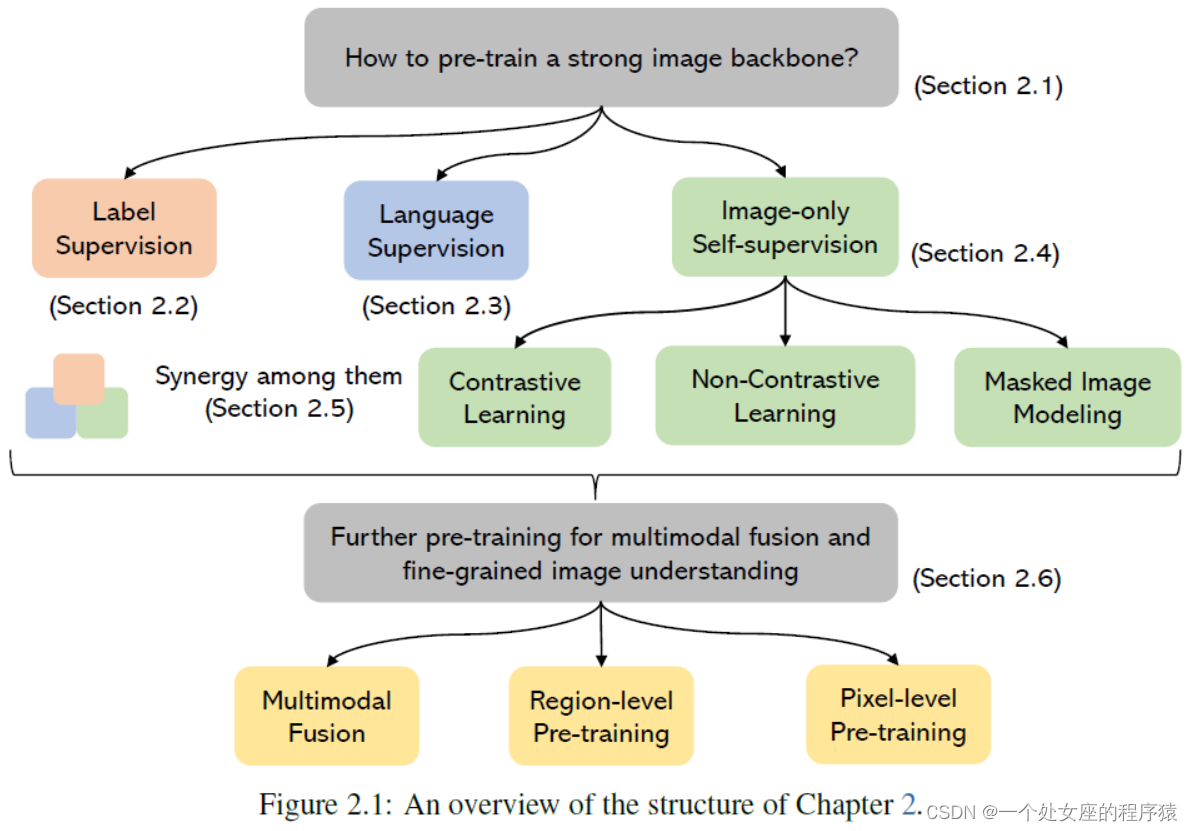
预训练图像骨干的三类方法:标签监督(研究得最充分+以图像分类的形式,如ImageNet/工业实验室)、语言监督(来自文本的弱监督信号+预训练上亿个图像-文本对+对比损失,如CLIP/ALIGN)、仅图像的自监督学习(监督信号来自图像本身+,如对比学习等)
There is a vast amount of literature on various methods of learning general-purpose vision back- bones. As illustrated in Figure 2.1, we group these methods into three categories, depending on the types of supervision signals used to train the models, including:
>> Label supervision: Arguably, the most well-studied image representation learning methods are based on label supervisions (typically in the form of image classification) (Sun et al., 2017), where datasets like ImageNet (Krizhevsky et al., 2012) and ImageNet21K (Ridnik et al., 2021) have been popular, and larger-scale proprietary datasets are also used in industrial labs (Sun et al., 2017; Singh et al., 2022b; Zhai et al., 2022a; Wu et al., 2023d).
>> Language supervision: Another popular approach to learning image representations leverages weakly supervised signals from text, which is easy to acquire in large scale. For instance, CLIP (Radford et al., 2021) and ALIGN (Jia et al., 2021) are pre-trained using a contrastive loss and billions of image-text pairs mined from the internet. The resultant models achieve strong zero-shot performance on image classification and image-text retrieval, and the learned image and text encoders have been widely used for various downstream tasks and allow traditional com- puter vision models to perform open-vocabulary CV tasks (Gu et al., 2021; Ghiasi et al., 2022a; Qian et al., 2022; Ding et al., 2022b; Liang et al., 2023a; Zhang et al., 2023e; Zou et al., 2023a; Minderer et al., 2022).
>> Image-only self-supervision: There is also a vast amount of literature on exploring image-only self-supervised learning methods to learn image representations. As the name indicates, the super- vision signals are mined from the images themselves, and popular methods range from contrastive learning (Chen et al., 2020a; He et al., 2020), non-contrastive learning (Grill et al., 2020; Chen and He, 2021; Caron et al., 2021), to masked image modeling (Bao et al., 2022; He et al., 2022a).
关于学习通用视觉骨干的方法有大量的文献。如图2.1所示,根据用于训练模型的监督信号类型,我们将这些方法分为三类,包括:
>>标签监督:可以说,研究得最充分的图像表示学习方法是基于标签监督(通常以图像分类的形式)(Sun et al., 2017),其中像ImageNet(Krizhevsky et al., 2012)和ImageNet21K(Ridnik et al., 2021)这样的数据集一直很受欢迎,工业实验室也使用规模更大的专有数据集(Sun et al., 2017; Singh et al., 2022b; Zhai et al., 2022a; Wu et al., 2023d)。
>>语言监督:另一种学习图像表示的常用方法是利用来自文本的弱监督信号,这在大规模情况下很容易获得。例如,CLIP(Radford et al., 2021)和ALIGN(Jia et al., 2021)是使用对比损失和从互联网上挖掘的数十亿个图像-文本对进行预训练的。由此产生的模型在图像分类和图像-文本检索方面表现出色,实现了强大的零样本性能,学习的图像和文本编码器已被广泛用于各种下游任务,并允许传统计算机视觉模型执行开放词汇的计算机视觉任务(Gu et al., 2021; Ghiasi et al., 2022a; Qian et al., 2022; Ding et al., 2022b; Liang et al., 2023a; Zhang et al., 2023e; Zou et al., 2023a; Minderer et al., 2022)。
>>仅图像的自监督学习:还有大量文献探讨了通过自监督学习方法学习图像表示。正如名称所示,监督信号来自图像本身,并且流行的方法从对比学习(Chen et al., 2020a; He et al., 2020)、非对比学习(Grill et al., 2020; Chen and He, 2021; Caron et al., 2021)到遮挡图像建模(Bao et al., 2022; He et al., 2022a)不一而足。
An illustration of these learning methods is shown in Figure 2.2. Besides the methods of pre- training image backbones, we will also discuss pre-training methods that allow multimodal fusion (e.g., CoCa (Yu et al., 2022a), Flamingo (Alayrac et al., 2022)), region-level and pixel-level image understanding (e.g., GLIP (Li et al., 2022e) and SAM (Kirillov et al., 2023)). These methods typi- cally rely on a pre-trained image encoder or a pre-trained image-text encoder pair. Figure 2.3 shows an overview of the topics covered in this chapter and some representative works in each topic.
这些学习方法的示意图如图2.2所示。除了预训练图像骨干的方法,我们还将讨论允许多模态融合(例如,CoCa(Yu et al., 2022a)、Flamingo(Alayrac et al., 2022))、区域级和像素级图像理解(例如,GLIP(Li et al., 2022e)和SAM(Kirillov et al., 2023))的预训练方法。这些方法通常依赖于预训练的图像编码器或预训练的图像-文本编码器对。图2.3显示了本章涵盖的主题概览以及每个主题中的一些代表性作品。
2.2、Supervised Pre-training监督预训练—依赖数据集的有效性和多样性+人工高成本性:基于ImageNet数据集,如AlexNet/ResNet/vision transformer/Swin transformer
Supervised pre-training on large-scale human-labeled datasets, such as ImageNet (Krizhevsky et al., 2012) and ImageNet21K (Ridnik et al., 2021), has emerged as a widely adopted approach to ac- quiring transferable visual representations. It aims to map an image to a discrete label, which is associated with a visual concept. This approach has greatly expedited progress in designing various vision backbone architectures (e.g., AlexNet (Krizhevsky et al., 2012), ResNet (He et al., 2016), vision transformer (Dosovitskiy et al., 2021), and Swin transformer (Liu et al., 2021)), and is the testbed for all the modern vision backbones. It also powered computer vision tasks across the whole spectrum, ranging from image classification, object detection/segmentation, visual question answer- ing, image captioning, to video action recognition. However, the effectiveness of learned represen- tations is often limited by the scale and diversity of supervisions in pre-training datasets, as human annotation is expensive.
在大规模人工标记的数据集上进行监督预训练,例如ImageNet(Krizhevsky et al., 2012)和ImageNet21K(Ridnik et al., 2021),已经成为一种广泛采用的获取可转移视觉表示的方法。它的目标是将图像映射到与视觉概念相关联的离散标签。这种方法极大地加速了各种视觉骨干架构的设计进程(例如AlexNet(Krizhevsky et al., 2012)、ResNet(He et al., 2016)、vision transformer(Dosovitskiy et al., 2021)和Swin transformer(Liu et al., 2021)),并成为所有现代视觉骨干的测试平台。它还推动了整个领域的计算机视觉任务,从图像分类、目标检测/分割、视觉问答、图像字幕到视频动作识别等任务。然而,学到的表示的有效性通常受到预训练数据集中监督规模和多样性的限制,因为人工标注很昂贵。
Large-scale datasets大规模数据集
Large-scale datasets. For larger-scale pre-training, noisy labels can be derived in large quantities from image-text pairs crawled from the Web. Using noisy labels, many industrial labs have suc- cessfully constructed comprehensive classification datasets using semi-automatic pipelines, such as JFT (Sun et al., 2017; Zhai et al., 2022a) and I2E (Wu et al., 2023d), or by leveraging proprietary data like Instagram hashtags (Singh et al., 2022b). The statistics of existing large-scale image clas-sification datasets are shown in Table 2.1. The labels are typically in the form of fine-grained image entities with a long-tailed distribution. Though classical, this approach has been very powerful for learning universal image representations. For example, JFT-300M (Sun et al., 2017) has been used for training the BiT (“Big Transfer”) models (Kolesnikov et al., 2020), and JFT-3B (Zhai et al., 2022a) has been used to scale up the training of a plain vision transformer (Dosovitskiy et al., 2021) to 22B in model size. LiT (Zhai et al., 2022b) proposes to first learn the image backbone on JFT- 3B (Zhai et al., 2022a), and keep it frozen and learn another text tower to align the image and text embedding space to make the model open-vocabulary and is capable of performing zero-shot image classification.
大规模数据集。对于更大规模的预训练,可以从Web上爬取的图像-文本对中获得大量的噪声标签。使用噪声标签,许多工业实验室成功地构建了全面的分类数据集,使用半自动流水线,如JFT(Sun et al., 2017; Zhai et al., 2022a)和I2E(Wu et al., 2023d),或通过利用专有数据,如Instagram标签(Singh et al., 2022b)。现有大规模图像分类数据集的统计数据如表2.1所示。标签通常采用长尾分布的形式呈现出细粒度的图像实体。尽管这是一种经典的方法,但它对于学习通用图像表示非常强大。例如,JFT-300M(Sun et al., 2017)已被用于训练BiT(“Big Transfer”)模型(Kolesnikov et al., 2020),而JFT-3B(Zhai et al., 2022a)已被用于将纯视觉transformers(Dosovitskiy et al., 2021)的模型规模扩展到22B。LiT(Zhai et al., 2022b)提出了在JFT-3B(Zhai et al., 2022a)上首先学习图像骨干,然后将其冻结并学习另一个文本塔对齐图像和文本嵌入空间,从而使模型能够执行零样本图像分类。
图2.2: 不同方法学习通用图像表示的高级概述
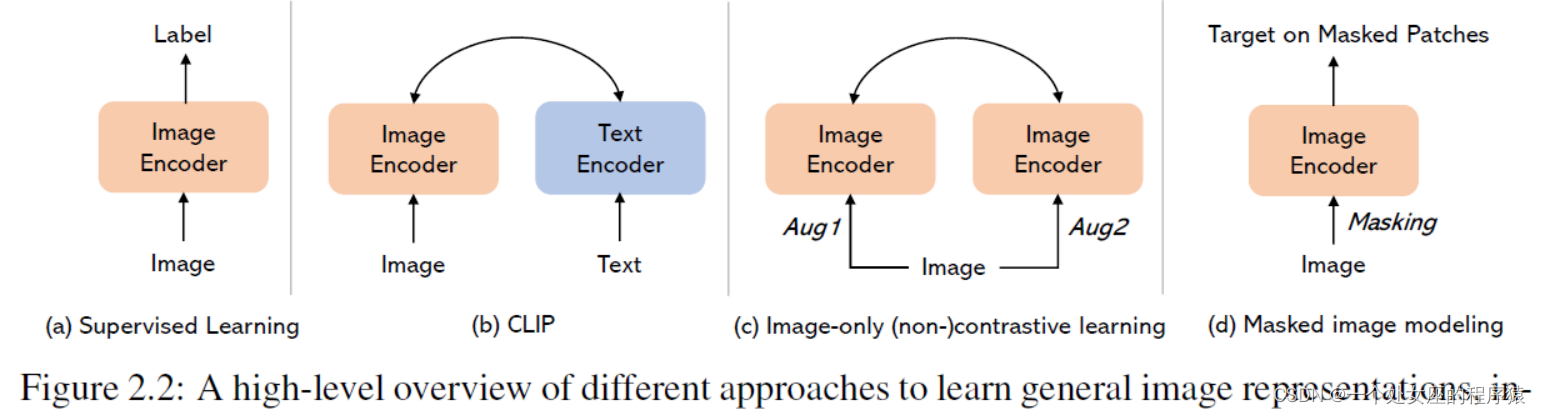
Figure 2.2: A high-level overview of different approaches to learn general image representations, in- cluding supervised learning (Krizhevsky et al., 2012), contrastive language-image pre-training (Rad- ford et al., 2021; Jia et al., 2021), and image-only self-supervised learning, including contrastive learning (Chen et al., 2020a; He et al., 2020), non-contrastive learning (Grill et al., 2020; Chen and He, 2021), and masked image modeling (Bao et al., 2022; He et al., 2022a).
图2.2: 不同方法学习通用图像表示的高级概述,包括监督学习(Krizhevsky et al., 2012)、对比语言-图像预训练(Radford et al., 2021; Jia et al., 2021)以及仅图像的自监督学习,包括对比学习(Chen et al., 2020a; He et al., 2020)、非对比学习(Grill et al., 2020; Chen and He, 2021)和遮挡图像建模(Bao et al., 2022; He et al., 2022a)。
图2.3: 本章涵盖的主题概述以及每个主题中的代表性作品

Figure 2.3: An overview of the topics covered in this chapter and representative works in each topic. We start from supervised learning and CLIP, and then move on to image-only self-supervised learn- ing, including contrastive learning, non-contrastive learning, and masked image modeling. Lastly, we discuss pre-training methods that empower multimodal fusion, region-level and pixel-level im- age understanding.
图2.3: 本章涵盖的主题概述以及每个主题中的代表性作品。我们从监督学习和CLIP开始,然后转向仅图像的自监督学习,包括对比学习、非对比学习和遮挡图像建模。最后,我们讨论了增强多模态融合、区域级和像素级图像理解的预训练方法。
Table 2.1: Statistics of existing large-scale image classification datasets

图2.4: 对比语言-图像预训练的示意图

Figure 2.4: Illustration of contrastive language-image pre-training, and how the learned model can be used for zero-shot image classification. Image credit: Radford et al. (2021).
图2.4: 对比语言-图像预训练的示意图,以及学到的模型如何用于零样本图像分类。图片来源: Radford等人 (2021)。
Model training模型训练:
Model training. There are many loss functions that can be used to promote embedding properties (e.g., separability) (Musgrave et al., 2020). For example, the large margin loss (Wang et al., 2018) is used for MOFI training (Wu et al., 2023d). Furthermore, if the datasets have an immense number of labels (can potentially be over 2 million as in MOFI (Wu et al., 2023d)), predicting all the labels in each batch becomes computationally costly. In this case, a fixed number of labels is typically used for each batch, similar to sampled softmax (Gutmann and Hyva¨rinen, 2010).
模型训练。有许多可以用于促进嵌入属性(例如,可分离性)的损失函数(Musgrave等人,2020)。例如,大间隔损失(Wang等人,2018)用于MOFI训练(Wu等人,2023d)。此外,如果数据集具有巨大数量的标签(可能会超过200万,如MOFI(Wu等人,2023d)),预测每批中的所有标签在计算上变得昂贵。在这种情况下,通常会为每个批次使用固定数量的标签,类似于采样的softmax(Gutmann和Hyva¨rinen,2010)。
2.3、Contrastive Language-Image Pre-training对比语言-图像预训练
2.3.1、Basics of CLIP Training-CLIP训练基础
语言数据+训练方式,如CLIP/ALIGN/Florence/BASIC/OpenCLIP等
Language is a richer form of supervision than classical closed-set labels. Rather than deriving noisy label supervision from web-crawled image-text datasets, the alt-text can be directly used for learning transferable image representations, which is the spirit of contrastive language-image pre-training (CLIP) (Radford et al., 2021). In particular, models trained in this way, such as ALIGN (Jia et al., 2021), Florence (Yuan et al., 2021), BASIC (Pham et al., 2021), and OpenCLIP (Ilharco et al., 2021), have showcased impressive zero-shot image classification and image-text retrieval capabilities by mapping images and text into a shared embedding space. Below, we discuss how the CLIP model is pre-trained and used for zero-shot prediction.
语言是比传统封闭集标签更丰富的监督形式。与从Web爬取的图像-文本数据集中获取嘈杂的标签监督不同,可以直接使用替换文本来学习可转移的图像表示,这是对比语言-图像预训练(CLIP)(Radford等人,2021)的精神。特别是,以这种方式训练的模型,如ALIGN(Jia等人,2021),Florence(Yuan等人,2021),BASIC(Pham等人,2021)和OpenCLIP(Ilharco等人,2021),通过将图像和文本映射到共享的嵌入空间,展示了令人印象深刻的零样本图像分类和图像-文本检索能力。接下来,我们将讨论CLIP模型如何进行预训练并用于零样本预测。
训练:对比学习+三维度扩展(批次大小+数据大小+模型大小)
Training: As shown in Figure 2.4(1), CLIP is trained via simple contrastive learning. CLIP is an outstanding example of “simple algorithms that scale well” (Li et al., 2023m). To achieve satisfac- tory performance, model training needs to be scaled along three dimensions: batch size, data size, and model size (Pham et al., 2021). Specifically, the typical batch size used for CLIP training can be 16k or 32k. The number of image-text pairs in the pre-training datasets is frequently measured in billions rather than millions. A vision transformer trained in this fashion can typically vary from 300M (Large) to 1B (giant) in model size.
训练:如图2.4(1)所示,CLIP通过简单的对比学习进行训练。CLIP是“扩展性良好的简单算法”的的一个杰出例子(Li et al., 2023m)。为了达到令人满意的性能,模型训练需要在三个维度上扩展:批次大小、数据大小和模型大小(Pham等人,2021)。
具体来说,CLIP训练中使用的典型批次大小可以为16k或32k。在预训练数据集中的图像-文本对数量通常以数十亿计而不是百万计。以这种方式训练的视觉transformers通常可以在模型大小上从300M(Large大型)变化到1B(giant巨型)。
零样本预测:零样本的图像分类+零样本的图像-文本检索
Zero-shot prediction: As shown in Figure 2.4 (2) and (3), CLIP empowers zero-shot image classification via reformatting it as a retrieval task and considering the semantics behind labels. It can also be used for zero-shot image-text retrieval by its design. Besides this, the aligned image- text embedding space makes it possible to make all the traditional vision models open vocabulary and has inspired a rich line of work on open-vocabulary object detection and segmentation (Li et al., 2022e; Zhang et al., 2022b; Zou et al., 2023a; Zhang et al., 2023e).
零样本预测:如图2.4(2)和(3)所示,CLIP通过将其重新格式化为检索任务并考虑标签背后的语义,提供了零样本图像分类的能力。它还可以用于零样本图像-文本检索,因为它的设计如此。除此之外,对齐的图像-文本嵌入空间使得所有传统视觉模型都能够进行开放式词汇学习,并且已经启发了许多关于开放式词汇目标检测和分割的工作(Li等人,2022e;Zhang等人,2022b;Zou等人,2023a;Zhang等人,2023e)。
Figure 2.5: ImageBind (Girdhar et al., 2023) proposes to link a total of six modalities into a common embedding space via leveraging pre-trained CLIP models, enabling new emergent alignments and capabilities. Image credit: Girdhar et al. (2023).图2.5: ImageBind(Girdhar等人,2023)提出通过利用预训练的CLIP模型将总共六种模态链接到共同的嵌入空间,从而实现新的紧密对齐和能力。图片来源: Girdhar等人(2023)。

2.3.2、CLIP Variants—CLIP变种
Since the birth of CLIP, there have been tons of follow-up works to improve CLIP models, as to be discussed below. We do not aim to provide a comprehensive literature review of all the methods, but focus on a selected set of topics.
自CLIP诞生以来,已经有大量后续研究来改进CLIP模型,如下所讨论。我们的目标不是提供所有方法的全面文献综述,而是专注于一组选定的主题。
Data scaling up数据规模扩大:CLIP(Web中挖掘400M图像-文本对)→ALIGN(1.8B图像-文本对)→BASIC探究关系,较小规模的图像-文本数据集(如SBU/RedCaps/WIT)→大规模图像-文本数据集(如Shutterstock/LAION-400M/COYO-700M/LAION-2B)
Data scaling up. Data is the fuel for CLIP training. For example, OpenAI’s CLIP was trained on 400M image-text pairs mined from the web, while ALIGN used a proprietary dataset consisting of 1.8B image-text pairs. In BASIC (Pham et al., 2021), the authors have carefully studied the scaling among three dimensions: batch size, data size, and model size. However, most of these large-scale datasets are not publicly available, and training such models requires massive computing resources.
In academic settings, researchers (Li et al., 2022b) have advocated the use of a few millions of image- text pairs for model pre-training, such as CC3M (Sharma et al., 2018), CC12M (Changpinyo et al., 2021), YFCC (Thomee et al., 2016). Relatively small-scale image-text datasets that are publicly available include SBU (Ordonez et al., 2011), RedCaps (Desai et al., 2021), and WIT (Srinivasan et al., 2021). Large-scale public available image-text datasets include Shutterstock (Nguyen et al., 2022), LAION-400M (Schuhmann et al., 2021), COYO-700M (Byeon et al., 2022), and LAION- 2B (Schuhmann et al., 2022), to name a few. For example, LAION-2B (Schuhmann et al., 2022) has been used by researchers to study the reproducible scaling laws for CLIP training (Cherti et al., 2023).
数据规模扩大。数据是CLIP训练的动力源。例如,OpenAI的CLIP是在从Web中挖掘的400M图像-文本对上进行训练的,而ALIGN则使用了包含1.8B图像-文本对的专有数据集。在BASIC(Pham等人,2021)中,作者仔细研究了批次大小、数据大小和模型大小之间的扩展。然而,大多数这些大规模数据集并不公开,训练这些模型需要大量计算资源。
在学术环境中,研究人员(Li等人,2022b)提倡使用数百万个图像-文本对进行模型预训练,例如CC3M(Sharma等人,2018)、CC12M(Changpinyo等人,2021)、YFCC(Thomee等人,2016)。
公开可用的相对较小规模的图像-文本数据集包括SBU(Ordonez等人,2011)、RedCaps(Desai等人,2021)和WIT(Srinivasan等人,2021)。公开可用的大规模图像-文本数据集包括Shutterstock(Nguyen等人,2022)、LAION-400M(Schuhmann等人,2021)、COYO-700M(Byeon等人,2022)和LAION-2B(Schuhmann等人,2022)等。例如,LAION-2B(Schuhmann等人,2022)已被研究人员用于研究CLIP训练的可复制的扩展定律(Cherti等人,2023)。
固定数据集并设计不同的算法→DataComp提出转向→固定的CLIP训练方法来选择和排名数据集
Interestingly, in search of the next-generation image-text datasets, in DataComp (Gadre et al., 2023), instead of fixing the dataset and designing different algorithms, the authors propose to se- lect and rank datasets using the fixed CLIP training method. Besides paired image-text data mined from the Web for CLIP training, inspired by the interleaved image-text dataset M3W introduced in Flamingo (Alayrac et al., 2022), there have been recent efforts of collecting interleaved image-text datasets, such as MMC4 (Zhu et al., 2023b) and OBELISC (Laurenc¸on et al., 2023).
有趣的是,在寻找下一代图像-文本数据集时,DataComp(Gadre等人,2023)中提到,与其固定数据集并设计不同的算法,不如使用固定的CLIP训练方法来选择和排名数据集。除了从Web中挖掘的成对图像-文本数据用于CLIP训练外,受Flamingo(Alayrac等人,2022)中引入的交错图像-文本数据集M3W的启发,最近还有一些收集交错图像-文本数据集的工作,如MMC4(Zhu等人,2023b)和OBELISC(Laurenc¸on等人,2023)。
Model design and training methods. 模型设计和训练方法:图像塔(如FLIP/MAE)、语言塔(如K-Lite/LaCLIP)、可解释性(如STAIR)、更多模态(如ImageBind/)
CLIP training has been significantly improved. Below, we review some representative works.
>> Image tower: On the image encoder side, FLIP (Li et al., 2023m) proposes to scale CLIP train- ing via masking. By randomly masking out image patches with a high masking ratio, and only encoding the visible patches as in MAE (He et al., 2022a), the authors demonstrate that masking can improve training efficiency without hurting the performance. The method can be adopted for all CLIP training. Cao et al. (2023) found that filtering out samples that contain text regions in the image improves CLIP training efficiency and robustness.
>> Language tower: On the language encoder side, K-Lite (Shen et al., 2022a) proposes to use external knowledge in the form of Wiki definition of entities together with the original alt-text for contrastive pre-training. Empirically, the use of enriched text descriptions improves the CLIP performance. LaCLIP (Fan et al., 2023a) shows that CLIP can be improved via rewriting the noisy and short alt-text using large language models such as ChatGPT.
>> Interpretability: The image representation is typically a dense feature vector. In order to im- prove the interpretability of the shared image-text embedding space, STAIR (Chen et al., 2023a) proposes to map images and text to a high-dimensional, sparse, embedding space, where each dimension in the sparse embedding is a (sub-)word in a large dictionary in which the predicted non-negative scalar corresponds to the weight associated with the token. The authors show that STAIR achieves better performance than the vanilla CLIP with improved interpretability.
>> More modalities: The idea of contrastive learning is general, and can go beyond just image and text modalities. For example, as shown in Figure 2.5, ImageBind (Girdhar et al., 2023) proposes to encode six modalities into a common embedding space, including images, text, audio, depth, thermal, and IMU modalities. In practice, a pre-trained CLIP model is used and kept frozen during training, which indicates that other modality encoders are learned to align to the CLIP embedding space, so that the trained model can be applied to new applications such as audio-to- image generation and multimodal LLMs (e.g., PandaGPT (Su et al., 2023)).
CLIP训练已经得到了显著改进。以下是一些代表性的工作。
>> 图像塔:在图像编码器方面,FLIP(Li等人,2023m)提出通过遮盖来扩展CLIP训练。通过随机遮盖高比例的图像区块,并仅对可见区块进行编码,如MAE(He等人,2022a)一样,作者证明了遮盖可以提高训练效率而不影响性能。该方法可以应用于所有CLIP训练。Cao等人(2023)发现,过滤掉包含图像中文本区域的样本可以提高CLIP的训练效率和鲁棒性。
>> 语言塔:在语言编码器方面,K-Lite(Shen等人,2022a)提出使用实体的Wiki定义与原始备用文本一起进行对比预训练。从经验上看,使用丰富的文本描述可以提高CLIP的性能。LaCLIP(Fan等人,2023a)表明,通过使用大型语言模型(例如ChatGPT)重写嘈杂且短的备用文本,可以改善CLIP的性能。
>> 可解释性:图像表示通常是稠密特征向量。为了提高共享图像-文本嵌入空间的可解释性,STAIR(Chen等人,2023a)提出将图像和文本映射到高维稀疏嵌入空间,其中稀疏嵌入中的每个维度是大字典中的一个(子)词,其中预测的非负标量对应于与该标记相关联的权值。作者表明,STAIR比vanilla CLIP实现了更好的性能,并提高了可解释性。
>> 更多模态:对比学习的思想是通用的,可以超越仅限于图像和文本模态。例如,如图2.5所示,ImageBind(Girdhar等人,2023)提出将六种模态编码到共同的嵌入空间中,包括图像、文本、音频、深度、热像和IMU模态。在实践中,使用预训练的CLIP模型,并在训练期间保持冻结,这意味着其他模态编码器被学习以与CLIP嵌入空间对齐,以便训练模型可以应用于新的应用,如音频到图像生成和多模态LLMs(例如PandaGPT(Su等人,2023))。
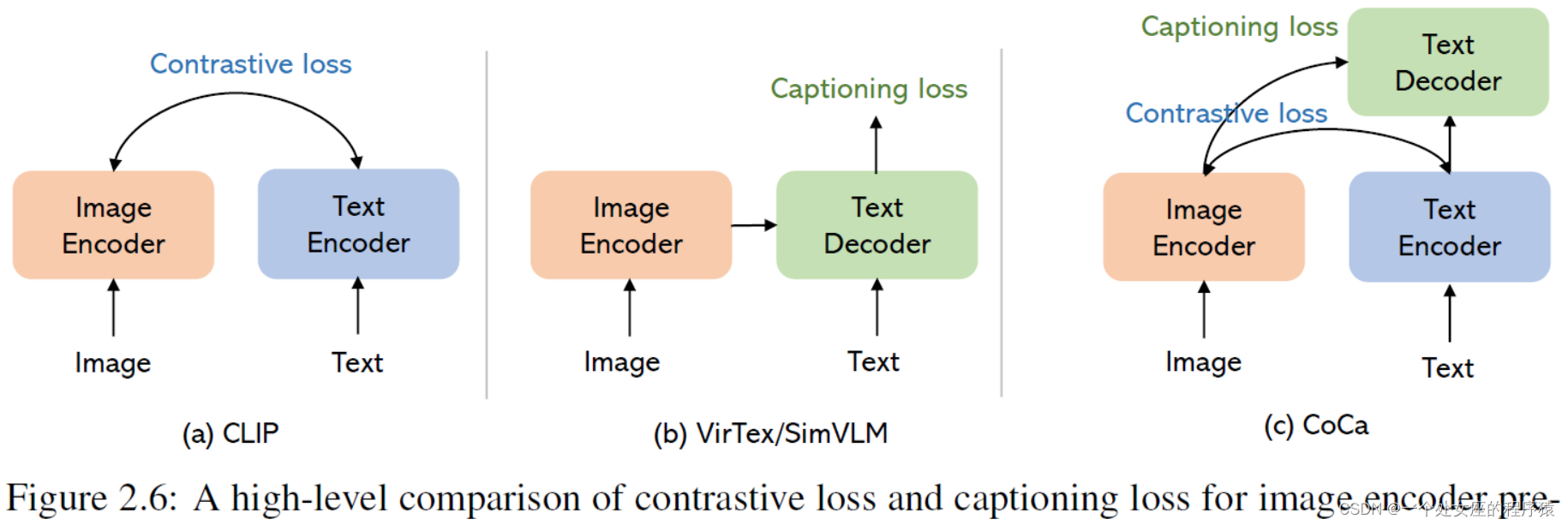
Figure 2.6: A high-level comparison of contrastive loss and captioning loss for image encoder pre-training. (a) CLIP (Radford et al., 2021) uses contrastive loss alone for pre-training, which enables zero-shot image classification and has demonstrated strong scaling behavior. (b) VirTex (Desai and Johnson, 2021) uses captioning loss alone for pre-training. SimVLM (Wang et al., 2022g) uses prefix language modeling for pre-training in a much larger scale. The model architecture is similar to multimodal language models (e.g., GIT (Wang et al., 2022a) and Flamingo (Alayrac et al., 2022)), but VirTex and SimVLM aim to pre-train the image encoder from scratch. (c) CoCa (Yu et al., 2022a) uses both contrastive and captioning losses for pre-training. The model architecture is similar to ALBEF (Li et al., 2021b), but CoCa aims to pre-train the image encoder from scratch, instead of using a pre-trained one. 图2.6:图像编码器预训练中对比度损失和字幕损失的高级对比。
(a) CLIP (Radford et al., 2021)仅使用对比损失进行预训练,实现了零射击图像分类,并表现出很强的缩放行为。
(b) VirTex (Desai and Johnson, 2021)仅使用字幕损失进行预训练。SimVLM (Wang et al., 2022g)在更大的范围内使用前缀语言建模进行预训练。模型架构类似于多模态语言模型(例如GIT (Wang et al., 2022a)和Flamingo (Alayrac et al., 2022)),但VirTex和SimVLM旨在从头开始预训练图像编码器。
(c) CoCa (Yu et al., 2022a)同时使用对比损失和字幕损失进行预训练。模型架构类似于ALBEF (Li et al., 2021b),但CoCa旨在从头开始预训练图像编码器,而不是使用预训练的图像编码器。
Figure 2.7: Overview of SimCLR (Chen et al., 2020a), SimSiam (Chen and He, 2021), and DINO (Caron et al., 2021) for self-supervised image representation learning. SimCLR uses con- trastive learning for model training, while SimSiam and DINO explores non-contrastive learning methods. Image credit: Chen et al. (2020a), Chen and He (2021), Caron et al. (2021).
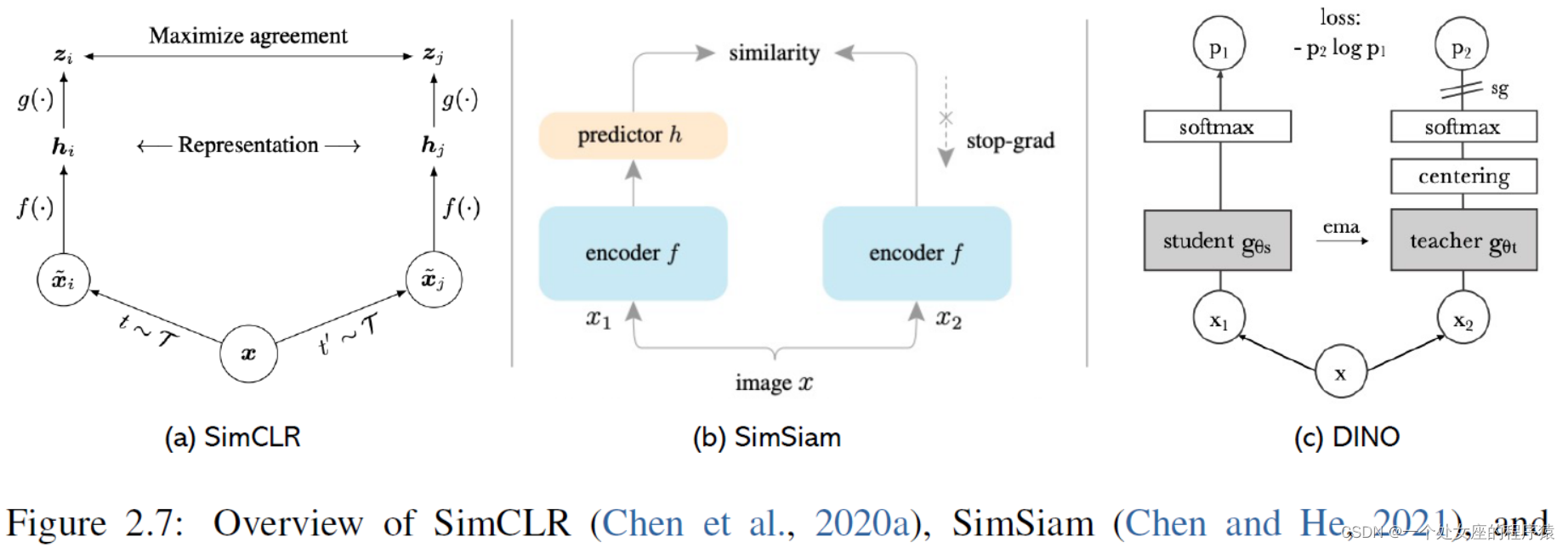
Figure 2.7: Overview of SimCLR (Chen et al., 2020a), SimSiam (Chen and He, 2021), and DINO (Caron et al., 2021) for self-supervised image representation learning. SimCLR uses con- trastive learning for model training, while SimSiam and DINO explores non-contrastive learning methods. Image credit: Chen et al. (2020a), Chen and He (2021), Caron et al. (2021).
图2.7:SimCLR(Chen等人,2020a)、SimSiam(Chen和He,2021)和DINO(Caron等人,2021)自监督图像表示学习的概述。SimCLR使用对比学习进行模型训练,而SimSiam和DINO探索非对比学习方法。图片来源:Chen等人(2020a),Chen和He(2021),Caron等人(2021)。
Objective function.目标函数:细粒度监督、对比式描述生成、仅使用字幕损失、用于语言-图像预训练的Sigmoid损失
The use of contrastive loss alone is powerful, especially when the model is scaled up. However, other objective functions can also be applied.
>> Fine-grained supervision: Instead of using a simple dot-product to calculate the similarity of an image-text pair, the supervision can be made more fine-grained via learning word-patch alignment. In FILIP (Yao et al., 2022b), the authors propose to first compute the loss by calculating the token- wise similarity, and then aggregating the matrix by max-pooling for word-patch alignment.
>> Contrastive captioner: Besides the contrastive learning branch, CoCa (Yu et al., 2022a) (shown in Figure 2.6(c)) adds a generative loss to improve performance and allow new capabilities that require multimodal fusion (e.g., image captioning and VQA). This is similar to many fusion- encoder-based vision-language models such as ALBEF (Li et al., 2021b), but with the key differ- ence in that CoCa aims to learn a better image encoder from scratch. A detailed discussion on multimodal fusion is in Section 2.6.1.
>> Captioning loss alone: How about using the captioning loss alone to pre-train an image encoder? Actually, before CLIP was invented, VirTex (Desai and Johnson, 2021) (shown in Figure 2.6(b)) and ICMLM (Sariyildiz et al., 2020) learn encoders using a single image captioning loss, but the scale is very small (restricted to COCO images) and the performance is poor. CLIP also shows that contrastive pre-training is a much better choice. In SimVLM (Wang et al., 2022g), the authors found that the learned image encoder was not as competitive as CLIP. However, in the recent work Cap/CapPa (Tschannen et al., 2023), the authors argue that image captioners are scalable vision learners, too. Captioning can exhibit the same or even better scaling behaviors.
>> Sigmoid loss for language-image pre-training: Unlike standard contrastive learning with soft- max normalization, Zhai et al. (2023) uses a simple pairwise sigmoid loss for image-text pre- training, which operates on image-text pairs and does not require a global view of the pairwise similarities for normalization. The authors show that the use of simple sigmoid loss can also achieve strong performance on zero-shot image classification.
仅使用对比损失本身非常强大,特别是当模型按比例放大时。然而,其他目标函数也可以应用。
>> 细粒度监督:与使用简单的点积来计算图像-文本对相似性不同,可以通过学习单词-区块对齐来使监督更细粒度。在FILIP(Yao等人,2022b)中,作者建议首先通过计算token之间的相似性来计算损失,然后通过最大池化来对词-区块对齐进行矩阵聚合矩阵以进行单词补丁对齐。
>> 对比式描述生成:除了对比学习分支外,CoCa(Yu等人,2022a)(图2.6(c)中显示)增加了生成损失以提高性能,并允许需要多模态融合的新功能(例如图像字幕和VQA)。这类似于许多基于融合编码器的视觉-语言模型,如ALBEF(Li等人,2021b),但关键区别在于CoCa旨在从头学习更好的图像编码器。多模态融合的详细讨论在第2.6.1节中。
>> 仅使用字幕损失:如何单独使用字幕损失来预训练图像编码器?实际上,在CLIP被发明之前,VirTex(Desai和Johnson,2021)(图2.6(b)中显示)和ICMLM(Sariyildiz等人,2020)使用单一图像字幕损失来学习编码器,但规模非常小(仅限于COCO图像)且性能较差。CLIP也表明对比式预训练是一个更好的选择。在SimVLM(Wang等人,2022g)中,作者发现学到的图像编码器不如CLIP具有竞争力。然而,在最近的工作Cap/CapPa(Tschannen等人,2023)中,作者认为图像字幕生成器也是可扩展的视觉学习者。字幕生成可以展现出相同或甚至更好的扩展行为。
>> 用于语言-图像预训练的Sigmoid损失:与标准的对比学习不同,标准对比学习使用softmax归一化,Zhai等人(2023)使用了一个简单的成对Sigmoid损失进行图像-文本预训练,该损失操作于图像-文本对,并且不需要对两两相似度进行归一化的全局视图。作者表明,使用简单的Sigmoid损失也可以在零样本图像分类上获得强大的性能。
2.4、Image-Only Self-Supervised Learning仅图像自监督学习:三类(对比学习/非对比学习/遮蔽图像建模)
Now, we shift our focus to image-only self-supervised learning, and divide the discussion into three parts: (i) contrastive learning, (ii) non-contrastive learning, and (iii) masked image modeling.
现在,我们将重点转向仅图像自监督学习,并将讨论分为三个部分:
(i)对比学习,
(ii)非对比学习,和
(iii)遮蔽图像建模。
2.4.1、Contrastive and Non-contrastive Learning
Contrastive learning.对比学习
The core idea of contrastive learning (Gutmann and Hyva¨rinen, 2010; Arora et al., 2019) is to promote the positive sample pairs and repulse the negative sample pairs. Besides being used in CLIP, contrastive learning has also been a popular concept in self-supervised image representation learning (Wu et al., 2018; Ye et al., 2019b; Tian et al., 2020a; Chen et al., 2020a; He et al., 2020; Misra and Maaten, 2020; Chen et al., 2020c). It has been shown that the contrastive objective, known as the InfoNCE loss (Oord et al., 2018), can be interpreted as max- imizing the lower bound of mutual information between different views of the data (Hjelm et al., 2018; Bachman et al., 2019; Henaff, 2020).
In a nutshell, all the image-only contrastive learning methods (e.g., SimCLR (Chen et al., 2020a), see Figure 2.7(a), MoCo (He et al., 2020), SimCLR-v2 (Chen et al., 2020b), MoCo-v2 (Chen et al., 2020c)) share the same high-level framework, detailed below.
>> Given one image, two separate data augmentations are applied;
>> A base encoder is followed by a project head, which is trained to maximize agreement using a contrastive loss (i.e., they are from the same image or not);
>> The project head is thrown away for downstream tasks.
However, a caveat of contrastive learning is the requirement of a large number of negative samples. These samples can be maintained in a memory bank (Wu et al., 2018), or directly from the current batch (Chen et al., 2020a), which suggests the requirement of a large batch size. MoCo (He et al., 2020) maintains a queue of negative samples and turns one branch into a momentum encoder to improve the consistency of the queue. Initially, contrastive learning was primarily studied for pre- training convolutional networks. However, with the rising popularity of vision transformers (ViT), researchers have also explored its application in the context of ViT. (Chen et al., 2021b; Li et al., 2021a; Xie et al., 2021).
对比学习的核心思想(Gutmann和Hyva¨rinen,2010;Arora等人,2019)是促进正样本对并排斥负样本对。除了用于CLIP之外,对比学习也是自监督图像表示学习中的一个流行概念(Wu等人,2018;Ye等人,2019b;Tian等人,2020a;Chen等人,2020a;He等人,2020;Misra和Maaten,2020;Chen等人,2020c)。研究表明,被称为InfoNCE损失的对比目标(Oord等人,2018)可以被解释为最大化不同数据视图之间互信息的下界(Hjelm等人,2018;Bachman et al., 2019;Henaff, 2020)。
简而言之,所有仅图像对比学习方法(例如SimCLR(Chen等人,2020a),见图2.7(a),MoCo(He等人,2020),SimCLR-v2(Chen等人,2020b),MoCo-v2(Chen等人,2020c))共享相同的高级框架,如下所述。
>> 给定一幅图像,应用两个单独的数据增强;
>> 一个基础编码器后跟一个项目头,该项目头经过对比损失进行训练,以最大程度地提高一致性(即它们来自同一图像或不来自同一图像);
>> 项目头被丢弃,用于下游任务。
然而,对比学习的一个缺点是需要大量的负样本。这这些样本可以保存在内存库中(Wu等人,2018),也可以直接保存在当前批次中(Chen等人,2020a),这表明需要更大的批次大小。MoCo(He等人,2020)维护了一个负样本队列,并将一个分支转换为动量编码器,以提高队列的一致性。最初,对比学习主要用于预训练卷积网络。然而,随着视觉transformers(ViT)的日益流行,研究人员也在探索其在ViT背景下的应用(Chen等人,2021b;Li等人,2021a;Xie等人,2021)。
Figure 2.8: Overview of BEiT pre-training for image transformers. Image credit: Bao et al. (2022).图像转换器的BEiT预训练概述

Non-contrastive learning.非对比学习
Recent self-supervised learning methods do not depend on negative samples. The use of negatives is replaced by asymmetric architectures (e.g., BYOL (Grill et al., 2020), SimSiam (Chen and He, 2021)), dimension de-correlation (e.g., Barlow twins (Zbontar et al., 2021), VICReg (Bardes et al., 2021), Whitening (Ermolov et al., 2021)), and clustering (e.g., SWaV (Caron et al., 2020), DINO (Caron et al., 2021), Caron et al. (2018); Amrani et al. (2022); Assran et al. (2022); Wang et al. (2023b)), etc.
For example, as illustrated in Figure 2.7(b), in SimSiam (Chen and He, 2021), two augmented views of a single image are processed by an identical encoder network. Subsequently, a prediction MLP is applied to one view, while a stop-gradient operation is employed on the other. The primary objective of this model is to maximize the similarity between the two views. It is noteworthy that SimSiam relies on neither negative pairs nor a momentum encoder.
Another noteworthy method, known as DINO (Caron et al., 2021) and illustrated in Figure 2.7(c), takes a distinct approach. DINO involves feeding two distinct random transformations of an input image into both the student and teacher networks. Both networks share the same architecture but have different parameters. The output of the teacher network is centered by computing the mean over the batch. Each network outputs a feature vector that is normalized with a temperature softmax applied to the feature dimension. The similarity between these features is quantified using a cross- entropy loss. Additionally, a stop-gradient operator is applied to the teacher network to ensure that gradients propagate exclusively through the student network. Moreover, DINO updates the teacher’s parameters using an exponential moving average of the student’s parameters.
最近的自监督学习方法不依赖于负样本。负样本的使用被不对称架构(例如BYOL(Grill等人,2020),SimSiam(Chen和He,2021)),维度去相关(例如Barlow twins(Zbontar等人,2021),VICReg(Bardes等人,2021),Whitening(Ermolov等人,2021))和聚类(例如SWaV(Caron等人,2020),DINO(Caron等人,2021),Caron等人(2018);Amrani等人(2022);Assran等人(2022);Wang等人(2023b))等方法所取代。
例如,如图2.7(b)所示,在SimSiam(Chen和He,2021)中,单个图像的两个增强视图经过相同的编码器网络处理。随后,在一个视图上应用预测MLP,而在另一个视图上使用stop-gradient停止梯度操作。该模型的主要目标是最大化两个视图之间的相似性。值得注意的是,SimSiam既不依赖于负对也不依赖于动量编码器。
另一个值得注意的方法,称为DINO(Caron等人,2021),如图2.7(c)所示,采用了一种独特的方法。DINO涉及将输入图像的两个不同的随机变换馈送到学生和教师网络中。两个网络共享相同的架构,但具有不同的参数。教师网络的输出通过计算批次的均值来居中。每个网络输出一个特征向量,该向量通过应用于特征维度的温度softmax进行归一化。这些特征之间的相似性使用交叉熵损失来量化。此外,stop-gradient运算符应用于教师网络,以确保梯度仅通过学生网络传播。此外,DINO使用学生参数的指数移动平均值来更新教师参数。
2.4.2、Masked Image Modeling遮蔽图像建模
Masked language modeling (Devlin et al., 2019) is a powerful pre-training task that has revolution- ized the NLP research. To mimic the success of BERT pre-training for NLP, the pioneering work BEiT (Bao et al., 2022), as illustrated in Figure 2.8, proposes to perform masked image modeling (MIM) to pre-train image transformers. Specifically,
>>Image tokenizer: In order to perform masked token prediction, an image tokenizer is required to tokenize an image into discrete visual tokens, so that these tokens can be treated just like an ad- ditional set of language tokens. Some well-known learning methods for image tokenziers include VQ-VAE (van den Oord et al., 2017), VQ-VAE-2 (Razavi et al., 2019), VQ-GAN (Esser et al., 2021), ViT-VQGAN (Yu et al., 2021), etc. These image tokenizers have also been widely used for autoregressive image generation, such as DALLE (Ramesh et al., 2021a), Make-A-Scene (Gafni et al., 2022), Parti (Yu et al., 2022b), to name a few.
>>Mask-then-predict: The idea of MIM is conceptually simple: models accept the corrupted input image (e.g., via random masking of image patches), and then predict the target of the masked con- tent (e.g., discrete visual tokens in BEiT). As discussed in iBOT (Zhou et al., 2021), this training procedure can be understood as knowledge distillation between the image tokenizer (which serves as the teacher) and the BEiT encoder (which serves as the student), while the student only sees partial of the image.
遮蔽语言建模(Devlin等人,2019)是一项强大的预训练任务,已经彻底改变了自然语言处理领域的研究。为了模仿BERT在自然语言处理领域的成功,开创性的工作BEiT(Bao等人,2022),如图2.8所示,提出了执行遮蔽图像建模(MIM)来预训练图像transformers。具体而言,
>> 图像标记器:为了执行遮蔽标记预测,需要一个图像标记器,将图像标记为离散的视觉标记,以便这些标记可以像额外的语言标记一样处理。一些知名的图像标记方法包括VQ-VAE(van den Oord等人,2017),VQ-VAE-2(Razavi等人,2019),VQ-GAN(Esser等人,2021),ViT-VQGAN(Yu等人,2021),等等。这些图像标记器也广泛用于自回归图像生成,如DALLE(Ramesh等人,2021a),Make-A-Scene(Gafni等人,2022),Parti(Yu等人,2022b),等等。
>> 掩码后预测:MIM的思想在概念上很简单:模型接受损坏的输入图像(例如,通过对图像块进行随机掩码),然后预测被掩码内容的目标(例如,BEiT中的离散视觉标记)。正如iBOT(Zhou等人,2021)中讨论的那样,这种训练过程可以理解为图像标记器(作为教师)和BEiT编码器(作为学生)之间的知识蒸馏,而学生只看到图像的部分。
Figure 2.9: Illustration of Masked Autoencoder (MAE)

Figure 2.9: Illustration of Masked Autoencoder (MAE) (He et al., 2022a) that uses raw pixel values for MIM training, and MaskFeat (Wei et al., 2021) that uses different features as the targets. HOG, a hand-crafted feature descriptor, was found to work particularly well in terms of both performance and efficiency. Image credit: He et al. (2022a) and Wei et al. (2021). 图2.9:使用原始像素值进行MIM训练的mask Autoencoder (MAE) (He et al., 2022a)和使用不同特征作为目标的MaskFeat (Wei et al., 2021)的说明。HOG是一个手工制作的特征描述符,在性能和效率方面都表现得特别好。图片来源:He et al. (2022a)和Wei et al.(2021)。 Targets目标:两类(低级像素特征【更细粒度图像理解】、高级特征),损失函数的选择取决于目标的性质,离散标记的目标(通常使用交叉熵损失)+像素值或连续值特征(选择是ℓ1、ℓ2或余弦相似度损失)
In Peng et al. (2022b), the authors have provided a unified view of MIM: a teacher model, a normalization layer, a student model, an MIM head, and a proper loss function. The most sig- nificant difference among all these models lies in the reconstruction targets, which can be pixels, discrete image tokens, features from pre-trained models, and outputs from the momentum updated teacher. Specifically, the targets can be roughly grouped into two categories.
>>Low-level pixels/features as targets: MAE (He et al., 2022a), SimMIM (Xie et al., 2022b), Con- vMAE (Gao et al., 2022), HiViT (Zhang et al., 2022d), and GreenMIM (Huang et al., 2022a) leverage either original or normalized pixel values as the target for MIM. These methods have typically explored the use of a plain Vision Transformer (Dosovitskiy et al., 2021) or the Swin Transformer (Liu et al., 2021) as the backbone architecture. MaskFeat (Wei et al., 2021) intro- duced the Histogram of Oriented Gradients (HOG) feature descriptor as the target for MIM (see Figure 2.9(b)). Meanwhile, Ge2-AE (Liu et al., 2023b) employed both pixel values and frequency information obtained from the 2D discrete Fourier transform as the target. Taking MAE (He et al., 2022a) as an example (Figure 2.9(a)), the authors show that using pixel values as targets works particularly well. Specifically, a large random subset of images (e.g., 75%) is masked out; then, the image encoder is only applied to visible patches, while mask tokens are introduced after the encoder. It was shown that such pre-training is especially effective for object detection and seg- mentation tasks, which require finer-grained image understanding.
>>High-level features as targets: BEiT (Bao et al., 2022), CAE (Chen et al., 2022g), SplitMask (El- Nouby et al., 2021), and PeCo (Dong et al., 2023) involve the prediction of discrete tokens using learned image tokenizers. MaskFeat (Wei et al., 2021) takes a different approach by proposing direct regression of high-level features extracted from models like DINO (Caron et al., 2021) and DeiT (Touvron et al., 2021). Expanding this idea, MVP (Wei et al., 2022b) and EVA (Fang et al., 2023) make feature prediction using image features from CLIP as target features. Additionally, other methods such as data2vec (Baevski et al., 2022), MSN (Assran et al., 2022), ConMIM (Yi et al., 2022), SIM (Tao et al., 2023), and BootMAE (Dong et al., 2022) propose to construct regression feature targets by leveraging momentum-updated teacher models to enhance online learning. The choice of loss functions depends on the nature of the targets: cross-entropy loss is typically used when the targets are discrete tokens, while ℓ1, ℓ2, or cosine similarity losses are common choices for pixel values or continuous-valued features.
在Peng等人(2022b)中,作者提供了对MIM的统一视图:教师模型、规范化层、学生模型、MIM头部和适当的损失函数。所有这些模型中最重要的区别在于重建目标,可以是像素、离散图像标记、来自预训练模型的特征以及来自动量更新的教师的输出。具体而言,这些目标可以粗略分为两类。
>> 低级像素/特征作为目标:MAE(He等人,2022a),SimMIM(Xie等人,2022b),ConvMAE(Gao等人,2022),HiViT(Zhang等人,2022d)和GreenMIM(Huang等人,2022a)使用原始或归一化的像素值作为MIM的目标。这些方法通常探讨了使用普通的Vision Transformer(Dosovitskiy等人,2021)或Swin Transformer(Liu等人,2021)作为骨干架构。MaskFeat(Wei等人,2021)引入了方向梯度直方图(HOG)特征描述符作为MIM的目标(见图2.9(b))。同时,Ge2-AE(Liu等人,2023b)将二维离散傅里叶变换得到的像素值和频率信息作为目标。以MAE(He等人,2022a)为例(图2.9(a)),作者表明使用像素值作为目标效果特别好。具体来说,一个大的随机图像子集(例如,75%)被屏蔽掉;然后,图像编码器仅应用于可见的patch补丁,而在编码器之后引入掩码标记。结果表明,这种预训练对需要更细粒度图像理解的目标检测和分割任务特别有效。
>> 高级特征作为目标:BEiT(Bao等人,2022),CAE(Chen等人,2022g),SplitMask(El-Nouby等人,2021)和PeCo(Dong等人,2023)通过使用学习的图像标记器来预测离散标记,采用了不同的方法。MaskFeat(Wei等人,2021)通过提出从DINO(Caron等人,2021)和DeiT(Touvron等人,2021)等模型中提取的高级特征的直接回归,提出了不同的方法。扩展这个思想,MVP(Wei等人,2022b)和EVA(Fang等人,2023)使用来自CLIP的图像特征作为目标特征进行特征预测。此外,其他方法,如data2vec(Baevski等人,2022),MSN(Assran等人,2022),ConMIM(Yi等人,2022),SIM(Tao等人,2023)和BootMAE(Dong等人,2022),提出利用动量更新的教师模型构建回归特征目标,以增强在线学习。损失函数的选择取决于目标的性质:对于离散标记的目标,通常使用交叉熵损失,而对于像素值或连续值特征,常见选择是ℓ1、ℓ2或余弦相似度损失。
Figure 2.10: Overview of UniCL (Yang et al., 2022a) that performs unified contrastive pre-training on image-text and image-label data. Image credit: Yang et al. (2022a).对图像-文本和图像-标签数据进行统一对比预训练的UniCL概述

MIM for video pre-training视频预训练的MIM:将MIM扩展到视频预训练,如BEVT/VideoMAE/Feichtenhofer
Naturally, there are recent works on extending MIM to video pre-training. Prominent examples include BEVT (Wang et al., 2022c), MAE as spatiotemporal learner (Feichtenhofer et al., 2022), VideoMAE (Tong et al., 2022), and VideoMAEv2 (Wang et al., 2023e). Taking Feichtenhofer et al. (2022) as an example. This paper studies a conceptually simple extension of MAE to video pre-training via randomly masking out space-time patches in videos and learns an autoencoder to reconstruct them in pixels. Interestingly, the authors found that MAE learns strong video representations with almost no inductive bias on space-time, and spacetime-agnostic random masking performs the best, with an optimal masking ratio as high as 90%.
自然地,有一些最近的工作将MIM扩展到视频预训练。突出的例子包括BEVT(Wang等人,2022c),MAE作为空间时间学习器(Feichtenhofer等人,2022),VideoMAE(Tong等人,2022)和VideoMAEv2(Wang等人,2023e)。以Feichtenhofer等人(2022)为例。本文研究了一种概念上简单的将MAE扩展到视频预训练的方法,通过随机屏蔽视频中的时空补丁,并学习一个自编码器以像素为单位重建它们。作者发现MAE在几乎没有时空上的归纳偏差的情况下学习了强大的视频表示,而与时空无关的随机掩蔽表现最好,其最佳掩蔽率高达90%。
Lack of learning global image representations全局图像表示的不足,如iBOT/DINO/BEiT等
MIM is an effective pre-training method that provides a good parameter initialization for further model finetuning. However, the vanilla MIM pre-trained model does not learn a global image representation. In iBOT (Zhou et al., 2021), the authors propose to enhance BEiT (Bao et al., 2022) with a DINO-like self-distillation loss (Caron et al., 2021) to force the [CLS] token to learn global image representations. The same idea has been extended to DINOv2 (Oquab et al., 2023).
MIM是一种有效的预训练方法,为进一步的模型微调提供了良好的参数初始化。然而,纯粹的MIM预训练模型并不学习全局图像表示。在iBOT(Zhou等人,2021)中,作者提出了使用类似于DINO的自我蒸馏损失(Caron等人,2021)增强BEiT(Bao等人,2022)的方法,以迫使[CLS]标记学习全局图像表示。相同的想法已经扩展到DINOv2(Oquab等人,2023)。
Scaling properties of MIM—MIM的规模特性:尚不清楚探讨将MIM预训练扩展到十亿级仅图像数据的规模
MIM is scalable in terms of model size. For example, we can per- form MIM pre-training of a vision transformer with billions of parameters. However, the scaling property with regard to data size is less clear. There are some recent works that aim to understand the data scaling of MIM (Xie et al., 2023b; Lu et al., 2023a); however, the data scale is limited to millions of images, rather than billions, except Singh et al. (2023) that studies the effectiveness of MAE as a so-called “pre-pretraining” method for billion-scale data. Generally, MIM can be con- sidered an effective regularization method that helps initialize a billion-scale vision transformer for downstream tasks; however, whether or not scaling the MIM pre-training to billion-scale image-only data requires further exploration.
MIM在模型大小方面是可扩展的。例如,我们可以对具有数十亿个参数的视觉transformer进行MIM预训练。然而,关于数据大小的规模属性不太明确。一些最近的工作旨在了解MIM的数据规模(Xie等人,2023b;Lu等人,2023a);然而,数据规模仅限于数百万张图像,而不是数十亿张,除了Singh等人(2023)研究了MAE作为所谓的“预-预训练”方法对十亿级数据的有效性。总的来说,MIM可以被视为一种有效的正则化方法,有助于初始化后续任务的十亿级视觉transformer ;然而,是否需要进一步探讨将MIM预训练扩展到十亿级仅图像数据的规模特性,目前尚不清楚。
2.5、Synergy Among Different Learning Approaches不同学习方法的协同作用
Till now, we have reviewed different approaches to pre-training image backbones, especially for vi- sion transformers. Below, we use CLIP as the anchor point, and discuss how CLIP can be combined with other learning methods.
到目前为止,我们已经回顾了不同的图像主干预训练方法,尤其是针对视觉transformers的方法。下面,我们以CLIP为锚点,讨论如何将CLIP与其他学习方法相结合。
Combining CLIP with label supervision将CLIP与标签监督相结合,如UniCL、LiT、MOFI
Noisy labels and text supervision can be jointly used for image backbone pre-training. Some representative works are discussed below.
>>UniCL (Yang et al., 2022a) proposes a principled way to use image-label and image-text data together in a joint image-text-label space for unified contrastive learning, and Florence (Yuan et al., 2021) is a scaled-up version of UniCL. See Figure 2.10 for an illustration of the framework.
>>LiT (Zhai et al., 2022b) uses a pre-trained ViT-g/14 image encoder learned from supervised pre- training on the JFT-3B dataset, and then makes the image encoder open-vocabulary by learning an additional text tower via contrastive pre-training on image-text data. Essentially, LiT teaches a text model to read out good representations from a pre-trained image model for new tasks.
>>MOFI (Wu et al., 2023d) proposes to learn image representations from 1 billion noisy entity- annotated images, and uses both image classification and contrastive losses for model training. For image classification, entities associated with each image are considered as labels, and supervised pre-training on a large number of entities is conducted; for constrastive pre-training, entity names are treated as free-form text, and are further enriched with entity descriptions.
噪声标签和文本监督可以共同用于图像主干预训练。下面讨论一些代表性的工作。
>> UniCL(Yang等人,2022a)提出了一种原则性的方法,将图像标签和图像-文本数据结合在一个联合图像-文本-标签空间中进行统一对比学习,而Florence(Yuan等人,2021)是UniCL的一个规模较大的版本。请参见图2.10,了解该框架的示意图。
>> LiT(Zhai等人,2022b)使用了从JFT-3B数据集的监督预训练中学到的预训练ViT-g/14图像编码器,然后通过在图像-文本数据上进行对比预训练来使图像编码器具备开放词汇的能力。从本质上讲,LiT教文本模型从预训练的图像模型中读出新的任务的良好表示。
>> MOFI(Wu等人,2023d)提出从10亿个带有噪声实体注释的图像中学习图像表示,并使用图像分类和对比损失进行模型训练。对于图像分类,将与每个图像相关联的实体视为标签,并进行大量实体的监督预训练;对于对比预训练,将实体名称视为自由形式的文本,并进一步丰富实体描述。
Figure 2.11: Illustration of MVP (Wei et al., 2022b), EVA (Fang et al., 2023) and BEiTv2 (Peng

Combining CLIP with image-only (non-)contrastive learning将CLIP与图像仅(非)对比学习相结合:如SLIP、xCLIP
CLIP can also be enhanced with image-only self-supervision. Specifically,
>>SLIP (Mu et al., 2021) proposes a conceptually simple idea to combine SimCLR (Chen et al., 2020a) and CLIP for model training, and shows that SLIP outperforms CLIP on both zero-shot transfer and linear probe settings. DeCLIP (Li et al., 2022g) mines self-supervised learning signals on each modality to make CLIP training data-efficient. In terms of image supervision, the SimSam framework (Chen and He, 2021) is used.
>>xCLIP (Zhou et al., 2023c) makes CLIP non-contrastive via introducing additional sharpness and smoothness regularization terms borrowed from the image-only non-contrastive learning litera- ture. However, the authors show that only non-contrastive pre-training (nCLIP) is not sufficient to achieve strong performance on zero-shot image classification, and it needs to be combined with the original CLIP for enhanced performance.
CLIP也可以通过图像仅自我监督进行增强。具体而言,
>> SLIP(Mu等人,2021)提出了一个概念上简单的思路,将SimCLR(Chen等人,2020a)与CLIP结合起来进行模型训练,并表明SLIP在零样本迁移和线性探测设置上优于CLIP。DeCLIP(Li等人,2022g)在每个模态上挖掘自监督学习信号,使CLIP训练数据高效。在图像监督方面,使用了SimSam框架(Chen和He,2021)。
>> xCLIP(Zhou等人,2023c)通过引入额外的锐度和平滑度正则项,借鉴了仅图像的非对比学习文献的方法,使CLIP成为非对比。然而,作者表明仅非对比预训练(nCLIP)不足以在零样本图像分类上获得较强的性能,需要与原始CLIP相结合以增强性能。
Combining CLIP with MIM将CLIP与MIM相结合
浅层交互:将CLIP提取的图像特征用作MIM训练的目标(CLIP图像特征可能捕捉了在MIM训练中缺失的语义),比如MVP/BEiTv2等
There are recent works that aim to combine CLIP and MIM for model training. We group them into two categories.
>>Shallow interaction. It turns out that image features extracted from CLIP are a good target for MIM training, as the CLIP image features potentially capture the semantics that are missing in MIM training. Along this line of work, as shown in Figure 2.11, MVP (Wei et al., 2022b)proposes to regress CLIP features directly, while BEiTv2 (Peng et al., 2022a) first compresses the information inside CLIP features into discrete visual tokens, and then performs regular BEiT train- ing. Similar use of CLIP features as MIM training target has also been investigated in EVA (Fang et al., 2023), CAEv2 (Zhang et al., 2022c), and MaskDistill (Peng et al., 2022b). In EVA-02 (Fang et al., 2023), the authors advocate alternative learning of MIM and CLIP representations. Specifi- cally, an off-the-shelf CLIP model is used to provide a feature target for MIM training; while the MIM pre-trained image backbone is used to initialize CLIP training. The MIM representations are used to finetune various downstream tasks while the learned frozen CLIP embedding enables zero-shot image classification and other applications.
最近有一些工作旨在将CLIP和MIM结合进行模型训练。我们将它们分为两类。
>> 浅层交互。事实证明,从CLIP提取的图像特征是MIM训练的良好目标,因为CLIP图像特征可能捕捉了在MIM训练中缺失的语义。沿着这一思路,如图2.11所示,MVP(Wei等人,2022b)提出直接回归CLIP特征,而BEiTv2(Peng等人,2022a)首先将CLIP特征中的信息压缩成离散的视觉标记,然后进行常规的BEiT训练。类似使用CLIP特征作为MIM训练目标的方法还在EVA(Fang等人,2023),CAEv2(Zhang等人,2022c)和MaskDistill(Peng等人,2022b)中进行了研究。在EVA-02(Fang等人,2023)中,作者提倡了MIM和CLIP表示的替代学习。具体来说,使用现成的CLIP模型为MIM训练提供特征目标;而使用MIM预训练的图像主干初始化CLIP训练。MIM表示用于微调各种下游任务,而学到的冻结CLIP嵌入使零样本图像分类和其他应用成为可能。
Figure 2.12: Overview of BEiT-3 that performs masked data modeling on both image/text and joint image-text data via a multiway transformer. Image credit: Wang et al. (2022d).通过多路转换器对图像/文本和联合图像-文本数据执行掩码数据建模的BEiT-3概述

深度整合:BERT和BEiT的组合非常有前景,比如BEiT-3
>>Deeper integration. However, instead of using CLIP as targets for MIM training, if one aims to combine CLIP and MIM for joint model training, MIM does not seem to improve a CLIP model at scale (Weers et al., 2023; Li et al., 2023m).
>>Although the combination of CLIP and MIM does not lead to a promising result at the current stage, the combination of BERT and BEiT is very promising, as evidenced in BEiT-3 (Wang et al., 2022d) (see Figure 2.12), where the authors show that masked data modeling can be performed on both image/text and joint image-text data via the design of a multiway transformer, and state- of-the-art performance can be achieved on a wide range of vision and vision-language tasks.
>> 深度整合。然而,如果有人的目标是将CLIP和MIM结合进行联合模型训练,而不是将CLIP用作MIM训练的目标,那么在大规模情况下,MIM似乎并不能改进CLIP模型(Weers等人,2023;Li等人,2023m)。
>> 尽管当前阶段CLIP和MIM的组合并没有取得令人满意的结果,但BERT和BEiT的组合非常有前景,正如BEiT-3(Wang等人,2022d)所证明的,该工作通过设计多向transformers在图像/文本和联合图像-文本数据上执行遮蔽数据建模,实现了在广泛的视觉和视觉-语言任务上实现了最新的性能。
2.6、Multimodal Fusion, Region-Level and Pixel-Level Pre-training多模态融合、区域级和像素级预训练
Till now, we have focused on the methods of pre-training image backbones from scratch, but not on pre-training methods that power multimodal fusion, region-level and pixel-level image under- standing. These methods typically use a pre-trained image encoder at the first hand to perform a second-stage pre-training. Below, we briefly discuss these topics.
到目前为止,我们关注了从头开始的图像主干预训练方法,但没有关注用于多模态融合、区域级和像素级图像理解的预训练方法。这些方法通常首先使用预训练的图像编码器进行第二阶段的预训练。以下,我们简要讨论这些主题。
2.6.1、From Multimodal Fusion to Multimodal LLM从多模态融合到多模态LLM
基于双编码器的CLIP(图像和文本独立编码+仅通过两者特征向量的简单点乘实现模态交互):擅长图像分类/图像-文本检索,不擅长图像字幕/视觉问答
For dual encoders such as CLIP (Radford et al., 2021), image and text are encoded separately, and modality interaction is only handled via a simple dot product of image and text feature vectors. This can be very effective for zero-shot image classification and image-text retrieval. However, due to the lack of deep multimodal fusion, CLIP alone performs poorly on the image captioning (Vinyals et al., 2015) and visual question answering (Antol et al., 2015) tasks. This requires the pre-training of a fusion encoder, where additional transformer layers are typically employed to model the deep interaction between image and text representations. Below, we review how these fusion-encoder pre-training methods are developed over time.
对于像CLIP(Radford等人,2021)这样的双编码器,图像和文本是分别编码的,而模态交互仅通过图像和文本特征向量的简单点乘来处理。这对于零样本图像分类和图像-文本检索非常有效。然而,由于缺乏深度多模态融合,仅使用CLIP在图像字幕(Vinyals等人,2015)和视觉问答(Antol等人,2015)任务上表现不佳。这需要对融合编码器进行预训练,其中通常使用额外的transformers层来模拟图像和文本表示之间的深层交互。下面,我们回顾了随着时间推移而发展的这些融合编码器预训练方法。
OD-based models基于OD的模型:使用共同注意力进行多模态融合(如ViLBERT/LXMERT)、将图像特征作为文本输入的软提示(如VisualBERT)
Most early methods use pre-trained object detectors (ODs) to extract visual features. Among them, ViLBERT (Lu et al., 2019) and LXMERT (Tan and Bansal, 2019) use co- attention for multimodal fusion, while methods like VisualBERT (Li et al., 2019b), Unicoder-VL (Li et al., 2020a), VL-BERT (Su et al., 2019), UNITER (Chen et al., 2020d), OSCAR (Li et al., 2020b),VILLA (Gan et al., 2020) and VinVL (Zhang et al., 2021) treat image features as soft prompts of the text input to be sent into a multimodal transformer.
大多数早期方法使用预训练的目标检测器(ODs)来提取视觉特征。其中,ViLBERT(Lu等人,2019)和LXMERT(Tan和Bansal,2019)使用共同注意力进行多模态融合,
而像VisualBERT(Li等人,2019b)、Unicoder-VL(Li等人,2020a)、VL-BERT(Su等人,2019)、UNITER(Chen等人,2020d)、OSCAR(Li等人,2020b)、VILLA(Gan等人,2020)和VinVL(Zhang等人,2021)等方法将图像特征作为文本输入发送到多模态transformer的软提示。
Figure 2.13: Illustration of UNITER (Chen et al., 2020d) and CoCa (Yu et al., 2022a),

Figure 2.13: Illustration of UNITER (Chen et al., 2020d) and CoCa (Yu et al., 2022a), which serve as a classical and a modern model that performs pre-training on multimodal fusion. CoCa also pre-trains the image backbone from scratch. Specifically, UNITER extracts image features via an off-the-shelf object detector and treat image features as soft prompts of the text input to be sent into a multimodal transformer. The model is pre-trained over a few millions of image-text pairs. For CoCa, an image encoder and a text encoder is used, with a multimodal transformer stacked on top. Both contrastive loss and captioning loss are used for model training, and the model is trained over billions of image-text pairs and JFT data. Image credit: Chen et al. (2020d), Yu et al. (2022a).
图2.13:UNITER (Chen et al., 2020d)和CoCa (Yu et al., 2022a)的示意图,分别作为经典模型和现代模型,对多模态融合进行预训练。CoCa还从头开始对图像主干进行预训练。具体来说,UNITER通过现成的对象检测器提取图像特征,并将图像特征作为文本输入的软提示发送到多模态变压器。该模型是在数百万图像-文本对上进行预训练的。对于CoCa,使用了一个图像编码器和一个文本编码器,并在顶部堆叠了一个多模态变压器。对比损失和字幕损失都用于模型训练,该模型是在数十亿的图像文本对和JFT数据上训练的。图片来源:Chen等人(2020d), Yu等人(2022a)。
End-to-end models端到端模型:早期基于CNN提取图像特征(如PixelBERT/SOHO/CLIP-ViL)→直接将图像块特征和文本token嵌入输入到多模态transformers(如ViLT/ViTCAP)→ViT(简单地使用ViT作为图像编码器,如Swintransformers/ALBEF/METER/VLMo/X-VLM/BLIP/SimVLM/FLAVA/CoCa/UNITER/CoCa)
Now, end-to-end pre-training methods become the mainstream. Some early methods use CNNs to extract image features, such as PixelBERT (Huang et al., 2020), SOHO (Huang et al., 2021), and CLIP-ViL (Shen et al., 2022b), while ViLT (Kim et al., 2021) and ViTCAP (Fang et al., 2022) directly feed image patch features and text token embeddings into a multimodal transformer. Due to the popularity of vision transformer (ViT), now most methods simply use ViT as the image encoder (e.g., plain ViT (Dosovitskiy et al., 2021) and Swin trans- former (Liu et al., 2021)). Prominent examples include ALBEF (Li et al., 2021b), METER (Dou et al., 2022b), VLMo (Wang et al., 2021b), X-VLM (Zeng et al., 2022), BLIP (Li et al., 2022d), SimVLM (Wang et al., 2022g), FLAVA (Singh et al., 2022a) and CoCa (Yu et al., 2022a).
An illustration of UNITER (Chen et al., 2020d) and CoCa (Yu et al., 2022a) is shown in Figure 2.13. They serve as two examples of a classical model and a modern model, respectively, which performs pre-training on multimodal fusion. CoCa also performs image backbone pre-training directly, as all the model components are trained from scratch. Please refer to Chapter 3 of Gan et al. (2022) for a comprehensive literature review.
现在,端到端预训练方法成为主流。一些早期方法使用CNN来提取图像特征,例如PixelBERT(Huang等人,2020)、SOHO(Huang等人,2021)和CLIP-ViL(Shen等人,2022b),而ViLT(Kim等人,2021)和ViTCAP(Fang等人,2022)直接将图像块特征和文本token嵌入输入到多模态transformers中。由于视觉transformers(ViT)的流行,现在大多数方法都简单地使用ViT作为图像编码器(例如,普通ViT(Dosovitskiy等人,2021)和Swintransformers(Liu等人,2021))。杰出的例子包括ALBEF(Li等人,2021b)、METER(Dou等人,2022b)、VLMo(Wang等人,2021b)、X-VLM(Zeng等人,2022)以及BLIP(Li等人,2022d)、SimVLM(Wang等人,2022g)、FLAVA(Singh等人,2022a)和CoCa(Yu等人,2022a)。UNITER(Chen等人,2020d)和CoCa(Yu等人,2022a)的示意图如图2.13所示。它们分别是经典模型和现代模型的两个示例,它们执行了多模态融合的预训练。CoCa还直接执行图像主干预训练,因为所有模型组件都是从头开始训练的。有关详细文献综述,请参见Gan等人(2022)的第3章。
Trend to multimodal LLM趋势是多模态LLM:早期模型(侧重于大规模预训练,如Flamingo/GIT/PaLI/PaLI-X)→近期工作(侧重于基于LLMs的指令调优,如LLaVA/MiniGPT-4)
Instead of using masked language modeling, image-text matching and image-text contrastive learning, SimVLM (Wang et al., 2022g) uses a simple PrefixLM loss for pre-training. Since then, multimodal language models have become popular. Early models focus on large-scale pre-training, such as Flamingo (Alayrac et al., 2022), GIT (Wang et al., 2022a), PaLI (Chen et al., 2022h), PaLI-X (Chen et al., 2023g), while recent works focus on using pre- trained LLMs for instruction tuning, such as LLaVA (Liu et al., 2023c) and MiniGPT-4 (Zhu et al., 2023a). A detailed discussion on this topic is provided in Chapter 5.
SimVLM (Wang et al., 2022g)使用简单的PrefixLM损失进行预训练,而不是使用掩码语言建模、图像-文本匹配和图像-文本对比学习。此后,多模态语言模型变得流行起来。早期模型侧重于大规模预训练,例如Flamingo(Alayrac等人,2022)、GIT(Wang等人,2022a)、PaLI(Chen等人,2022h)、PaLI-X(Chen等人,2023g),而最近的工作侧重于使用预训练的LLMs进行指令调优,例如LLaVA(Liu等人,2023c)和MiniGPT-4(Zhu等人,2023a)。有关此主题的详细讨论,请参见第5章。
Figure 2.14: Overview of GLIP that performs grounded language-image pre-training for open-set object detection. Image credit: Li et al. (2022f).

2.6.2、Region-Level Pre-training区域级预训练
CLIP:通过对比预训练学习全局图像表示+不适合细粒度图像理解的任务(如目标检测【包含两个子任务=定位+识别】等)
使用2阶段检测器从CLIP中提取知识(ViLD/RegionCLIP)、基于语言-图像的预训练(将检测重新定义为短语定位问题,如MDETR/GLIP)、视觉语言理解任务进行了统一的预训练(GLIPv2/FIBER)、
基于图像-文本模型进行微调(如OVR-CNN)、只训练分类头(如Detic)、
CLIP learns global image representations via contrastive pre-training. However, for tasks that re- quire fine-grained image understanding such as object detection, CLIP is not enough. Object detec- tion contains two sub-tasks: localization and recognition. (i) Localization aims to locate the pres- ence of objects in an image and indicate the position with a bounding box, while (ii) recognition determines what object categories are present in the bounding box. By following the reformulation that converts image classification to image retrieval used in CLIP, generic open-set object detection can be achieved.
Specifically, ViLD (Gu et al., 2021) and RegionCLIP (Zhong et al., 2022a) distill knowledge from CLIP with a two-stage detector for zero-shot object detection. In MDETR (Kamath et al., 2021) and GLIP (Li et al., 2022e) (as shown in Figure 2.14), the authors propose to reformulate detection as a phrase grounding problem, and perform grounded language-image pre-training. GLIPv2 (Zhang et al., 2022b) and FIBER (Dou et al., 2022a) further perform unified pre-training for both grounding and vision-language understanding tasks. OVR-CNN (Zareian et al., 2021) finetunes an image-text model to detection on a limited vocabulary and relies on image-text pre-training for generalization to an open vocabulary setting. Detic (Zhou et al., 2022b) improves long-tail detection performance with weak supervision by training only the classification head on the examples where only image- level annotations are available. Other works include OV-DETR (Zang et al., 2022), X-DETR (Cai et al., 2022), FindIT (Kuo et al., 2022), PromptDet (Feng et al., 2022a), OWL-ViT (Minderer et al., 2022), GRiT (Wu et al., 2022b), to name a few. Recently, Grounding DINO (Liu et al., 2023h) is proposed to marry DINO (Zhang et al., 2022a) with grounded pre-training for open-set object detection. Please refer to Section 4.2 for a detailed review of this topic.
CLIP通过对比预训练学习全局图像表示。对于需要细粒度图像理解的任务,如目标检测,CLIP是不够的。目标检测包含两个子任务:定位和识别。 (i)定位旨在在图像中定位物体的存在并用边界框指示位置,而
(ii)识别旨在确定边界框中存在哪些物体类别。
通过遵循将图像分类转换为在CLIP中使用的图像检索,可以实现通用开放集目标检测。
具体来说,ViLD(Gu等人,2021)和RegionCLIP(Zhong等人,2022a)使用2阶段检测器从CLIP中提取知识,用于零样本目标检测。在MDETR(Kamath等人,2021)和GLIP(Li等人,2022e)(如图2.14所示)中,作者提出将检测重新定义为短语定位问题,并执行基于语言-图像的预训练。GLIPv2(Zhang等人,2022b)和FIBER(Dou等人,2022a)进一步对基础和视觉语言理解任务进行了统一的预训练。OVR-CNN(Zareian等人,2021)对图像-文本模型进行微调,以在有限的词汇表上进行检测,并依靠图像-文本预训练将其泛化到开放的词汇表设置。Detic(Zhou等人,2022b)通过在只有图像级注释可用的示例上只训练分类头,提高了弱监督下的长尾检测性能。其他作品包括OV-DETR(Zang等人,2022)、X-DETR(Cai等人,2022)、FindIT(Kuo等人,2022)、PromptDet(Feng等人,2022a)、OWL-ViT(Minderer等人,2022)、GRiT(Wu等人,2022b)等等。最近,提出了Grounding DINO(Liu等人,2023h)以将DINO(Zhang等人,2022a)与基于定位的预训练相结合,用于开放式目标检测。有关此主题的详细评论,请参见第4.2节。
2.6.3、Pixel-Level Pre-training像素级预训练(代表作SAE):
The Segment Anything Model (SAM) (Kirillov et al., 2023) is a recent vision foundation model for image segmentation that aims to perform pixel-level pre-training. Since its birth, it has attracted wide attention and spurred tons of follow-up works and applications. Below, we briefly review SAM, as a representative work for pixel-level visual pre-training.
As depicted in Figure 2.15, the objective of the Segment Anything project is to develop a founda- tional vision model for segmentation. This model is designed to be readily adaptable to a wide range of both existing and novel segmentation tasks, such as edge detection, object proposal generation, instance segmentation, open-vocabulary segmentation, and more. This adaptability is seamlessly accomplished through a highly efficient and user-friendly approach, facilitated by the integration of three interconnected components. Specifically,
“Segment Anything Model”(SAM)(Kirillov等人,2023)是一种最新的用于图像分割的视觉基础模型,旨在执行像素级预训练。自诞生以来,它引起了广泛关注,并激发了大量的后续工作和应用。以下,我们简要回顾一下SAM作为像素级视觉预训练的代表工作。
如图2.15所示,Segment Anything项目的目标是开发一个用于分割的基础视觉模型。该模型旨在能够轻松适应各种现有和新型的分割任务,如边缘检测、对象提议生成、实例分割、开放式词汇分割等。这种适应性是通过高效和用户友好的方法无缝实现的,这得益于三个相互连接的组件的集成。具体来说,
>>Task. The authors propose the promptable segmentation task, where the goal is to return a valid segmentation mask given any segmentation prompt, such as a set of points, a rough box or mask, or free-form text.
>>Model. The architecture of SAM is conceptually simple. It is composed of three main com- ponents: (i) a powerful image encoder (MAE (He et al., 2022a) pre-trained ViT); (ii) a prompt encoder (for sparse input such as points, boxes, and free-form text, the CLIP text encoder is used; for dense input such as masks, a convolution operator is used); and (iii) a lightweight mask de- coder based on transformer.
>>Data. To acquire large-scale data for pre-training, the authors develop a data engine that performs model-in-the-loop dataset annotation.
>> 任务。作者提出了可提示的分割任务,目标是在给定任何分割提示的情况下返回有效的分割掩码,例如一组点、一个粗糙的框或掩码、或自由格式的文本。
>> 模型。SAM的架构在概念上很简单。它由三个主要组成部分组成:(i)一个强大的图像编码器(MAE(He等人,2022a)预训练的ViT);(ii)提示编码器(用于稀疏输入的CLIP文本编码器,例如点、框和自由文本,用于密集输入的掩码(如使用卷积算子);
(iii)基于transformers的轻量级掩码解码器。
>> 数据。为了获取大规模的预训练数据,作者开发了一个执行模型-数据集标注的数据引擎。
Figure 2.15: Overview of the Segment Anything project, which

Figure 2.15: Overview of the Segment Anything project, which aims to build a vision foundation model for segmentation by introducing three interconnected components: a promptable segmenta-tion task, a segmentation model, and a data engine. Image credit: Kirillov et al. (2023).
图2.15:Segment Anything项目概述,该项目旨在通过引入三个相互关联的组件:提示式分割任务、分割模型和数据引擎,构建一个分割的视觉基础模型。图片来源:Kirillov et al.(2023)。
Concurrent to SAM与SAM同时并行:OneFormer(一种通用的图像分割框架)、SegGPT(一种统一不同分割数据格式的通用上下文学习框架)、SEEM(扩展了单一分割模型)
Parallel to SAM, many efforts have been made to develop general-purpose segmentation models as well. For example, OneFormer (Jain et al., 2023) develops a universal im- age segmentation framework; SegGPT (Wang et al., 2023j) proposes a generalist in-context learning framework that unifies different segmentation data formats; SEEM (Zou et al., 2023b) further ex- pands the types of supported prompts that a single segmentation model can handle, including points, boxes, scribbles, masks, texts, and referred regions of another image.
与SAM同时并行,开发通用分割模型也做了很多努力。例如,OneFormer(Jain等人,2023)开发了一种通用的图像分割框架;SegGPT(Wang等人,2023j)提出了一种统一不同分割数据格式的通用上下文学习框架;SEEM(Zou等人,2023b)进一步扩展了单一分割模型可以处理的支持提示类型,包括点、框、涂鸦、掩码、文本和另一图像的相关区域等。
Extensions of SAM—SAM的扩展到应用中的模型:Inpaint Anything/Edit Everything/Any-to-Any Style Transfer/Caption Anything→Grounding DINO/Grounding-SAM1
Extensions of SAM. SAM has spurred tons of follow-up works that extend SAM to a wide range of applications, e.g., Inpaint Anything (Yu et al., 2023c), Edit Everything (Xie et al., 2023a), Any- to-Any Style Transfer (Liu et al., 2023g), Caption Anything (Wang et al., 2023g), Track Any- thing (Yang et al., 2023b), Recognize Anything (Zhang et al., 2023n; Li et al., 2023f), Count Anything (Ma et al., 2023), 3D reconstruction (Shen et al., 2023a), medical image analysis (Ma and Wang, 2023; Zhou et al., 2023d; Shi et al., 2023b; Zhang and Jiao, 2023), etc. Additionally, recent works have attempted to develop models for detecting and segmenting anything in the open- vocabulary scenarios, such as Grounding DINO (Liu et al., 2023h) and Grounding-SAM1. For a comprehensive review, please refer to Zhang et al. (2023a) and some GitHub repos.2
SAM已经激发了大量的后续工作,将SAM扩展到各种应用中,例如Inpaint Anything(Yu等人,2023c)、Edit Everything(Xie等人,2023a)、Any-to-Any Style Transfer(Liu等人,2023g)、Caption Anything(Wang等人,2023g)、Track Anything(Yang等人,2023b)、Recognize Anything(Zhang等人,2023n;Li等人,2023f)、Count Anything(Ma等人,2023)、3D重建(Shen等人,2023a)、医学图像分析(Ma和Wang,2023;Zhou等人,2023d;Shi等人,2023b;Zhang和Jiao,2023)等等。此外,最近的研究尝试开发用于在开放词汇情景中检测和分割任何物体的模型,例如Grounding DINO(Liu等人,2023h)和Grounding-SAM1。有关全面的综述,请参阅Zhang等人(2023a)和一些GitHub资源库。
3、Visual Generation视觉生成
VG的目的(生成高保真的内容),作用(支持创意应用+合成训练数据),关键(生成严格与人类意图对齐的视觉数据,比如文本条件)
Visual generation aims to generate high-fidelity visual content, including images, videos, neural ra- diance fields, 3D point clouds, etc.. This topic is at the core of recently popular artificial intelligence generated content (AIGC), and this ability is crucial in supporting creative applications such as de- sign, arts, and multimodal content creation. It is also instrumental in synthesizing training data to help understand models, leading to the closed loop of multimodal content understanding and gen- eration. To make use of visual generation, it is critical to produce visual data that is strictly aligned with human intents. These intentions are fed into the generation model as input conditions, such as class labels, texts, bounding boxes, layout masks, among others. Given the flexibility offered by open-ended text descriptions, text conditions (including text-to-image/video/3D) have emerged as a pivotal theme in conditional visual generation.
In this chapter, we describe how to align with human intents in visual generation, with a focus on image generation. We start with the overview of the current state of text-to-image (T2I) generation in Section 3.1, highlighting its limitations concerning alignment with human intents. The core of this chapter is dedicated to reviewing the literature on four targeted areas that aim at enhancing alignments in T2I generation, i.e., spatial controllable T2I generation in Section 3.2, text-based image editing in Section 3.3, better following text prompts in Section 3.4, and concept customization in T2I generation in Section 3.5. At the end of each subsection, we share our observations on the current research trends and short-term future research directions. These discussions coalesce in Section 3.6, where we conclude the chapter by considering future trends. Specifically, we envision the development of a generalist T2I generation model, which can better follow human intents, to unify and replace the four separate categories of alignment works.
视觉生成旨在生成高保真的视觉内容,包括图像、视频、神经辐射场、3D点云等。这个主题是最近流行的人工智能生成内容(AIGC)的核心,这种能力对支持创意应用,如设计、艺术和多模态内容创作至关重要。它还有助于合成训练数据,帮助理解模型,从而形成多模态内容理解和生成的闭环。要利用视觉生成,关键是生成严格与人类意图对齐的视觉数据。这些意图作为输入条件输入到生成模型中,例如类别标签、文本、边界框、布局掩码等。由于开放性文本描述提供的灵活性,文本条件(包括文本到图像/视频/3D等)已经成为条件视觉生成中的关键主题。
在本章中,我们将重点介绍视觉生成中与人类意图对齐的方法,重点关注图像生成。我们从第3.1节中的文本到图像(T2I)生成的当前状态概述开始,突出了其在与人类意图对齐方面的局限性。本章的核心部分致力于回顾四个目标领域的文献,这些领域旨在增强T2I生成中的对齐,即第3.2节中的空间可控的T2I生成,第3.3节中的基于文本的图像编辑,第3.4节中更好地遵循文本提示,以及第3.5节中的T2I生成中的概念定制。在每个子节结束时,我们分享了对当前研究趋势和短期未来研究方向的观察。这些讨论在第3.6节中汇总,我们在该节中通过考虑未来趋势来总结本章。具体来说,我们设想开发一个通用的T2I生成模型,它可以更好地遵循人类意图,以统一和替代四个独立的对齐工作类别。
3.1、Overview概述
3.1.1、Human Alignments in Visual Generation视觉生成中的人类对齐:核心(遵循人类意图来合成内容),四类探究
空间可控T2I生成(将文本输入与其他条件结合起来→更好的可控性)、基于文本的图像编辑(基于多功能编辑工具)、更好地遵循文本提示(因生成过程不一定严格遵循指令)、视觉概念定制(专门的token嵌入或条件图像来定制T2I模型)
AI Alignment research in the context of T2I generation is the field of study dedicated to developing image generation models that can easily follow human intents to synthesize the desired generated visual content. Current literature typically focuses on one particular weakness of vanilla T2I models that prevents them from accurately producing images that align with human intents. This chapter delves into four commonly studied issues, as summarized in Figure 3.1 (a) and follows.
>>Spatial controllable T2I generation. Text serves as a powerful medium for human-computer interaction, making it a focal point in conditional visual generation. However, text alone falls short in providing precise spatial references, such as specifying open-ended descriptions for arbi- trary image regions with precise spatial configurations. Spatial controllable T2I generation (Yang et al., 2023b; Li et al., 2023n; Zhang and Agrawala, 2023) aims to combine text inputs with other conditions for better controllability, thereby facilitating users to generate the desired images.
>>Text-based image editing. Editing is another important means for acquiring human-intended vi- sual content. Users might possess near-perfect images, whether generated by a model or naturally captured by a camera, but these might require specific adjustments to meet their intent. Editing has diverse objectives, ranging from locally modifying an object to globally adjusting the image style. Text-based image editing (Brooks et al., 2023) explores effective ways to create a versatile editing tool.
>>Better following text prompts. Despite T2I models being trained to reconstruct images con- ditioned on the paired text input, the training objective does not necessarily ensure or directly
optimize for a strict adherence to text prompts during image generation. Studies (Yu et al., 2022b; Rombach et al., 2022) have shown that vanilla T2I models might overlook certain text descriptions and generate images that do not fully correspond to the input text. Research (Feng et al., 2022b; Black et al., 2023) along this line explores improvements to have T2I models better following text prompts, thereby facilitating the easier use of T2I models.
>>Visual concept customization. Incorporating visual concepts into textual inputs is crucial for various applications, such as generating images of one’s pet dog or family members in diverse settings, or crafting visual narratives featuring a specific character. These visual elements often encompass intricate details that are difficult to articulate in words. Alternatively, studies (Ruiz et al., 2023; Chen et al., 2023f) explore if T2I models can be customized to draw those visual concepts with specialized token embeddings or conditioned images.
T2I生成背景下的AI对齐研究是一门致力于开发图像生成模型的研究领域,这些模型可以轻松地遵循人类意图来合成所需的生成视觉内容。当前文献通常集中在普通T2I模型的一个特定弱点上,这个弱点阻止了它们准确生成与人类意图一致的图像。本章探讨了四个通常研究的问题,如图3.1(a)所总结的那样,如下所述。
>> 空间可控T2I生成。文本在人机交互中充当强大的媒介,使其成为条件视觉生成的焦点。然而,仅文本不能提供精确的空间参考,比如为具有精确空间配置的任意图像区域指定开放式描述。空间可控的T2I生成(Yang等人,2023b;Li等人,2023n;Zhang和Agrawala,2023)旨在将文本输入与其他条件结合起来,以实现更好的可控性,从而使用户能够生成所需的图像。
>> 基于文本的图像编辑。编辑是获取人类意图的视觉内容的另一种重要手段。用户可能拥有近乎完美的图像,无论是由模型生成的还是由相机自然捕获的,但这些可能需要进行特定的调整以满足他们的意图。编辑具有多种目标,从局部修改对象到全局调整图像风格。基于文本的图像编辑(Brooks等人,2023)探索了创建多功能编辑工具的有效方法。
>> 更好地遵循文本提示。尽管T2I模型经过训练以在配对的文本输入条件下重构图像,但训练目标不一定确保或直接优化图像生成过程中严格遵循文本提示。研究(Yu等人,2022b;Rombach等人,2022)表明,普通T2I模型可能忽视某些文本描述,并生成与输入文本不完全对应的图像。在这方面的研究(Feng等人,2022b;Black等人,2023)探索了改进T2I模型更好地遵循文本提示的方法,从而使T2I模型更容易使用。
>> 视觉概念定制。将视觉概念纳入文本输入对于各种应用至关重要,比如在不同场景中生成宠物狗或家庭成员的图像,或制作以特定角色为特色的视觉叙事。有些视觉元素通常包含难以用文字表达的复杂细节。或者,研究(Ruiz等人,2023;Chen等人,2023f)探讨了是否可以通过专门的token嵌入或条件图像来定制T2I模型以绘制那些视觉概念。
Before introducing the alignment works in detail, we first review the basics of text-to-image gener- ation in the next section.
在详细介绍对齐工作之前,我们首先在下一节中回顾文本到图像生成的基础知识。
Figure 3.1: An overview of improving human intent alignments in T2I generation—T2I生成改善人类意向对齐的概述。

3.1.2、Text-to-Image Generation文本到图像生成
Figure 3.2: An overview of representative text-to-image generation models until July 2023.截至2023年7月的代表性文本到图像生成模型概述

T2I的目的(视觉质量高+语义与输入文本相对应)、数据集(图像-文本对进行训练)
T2I generation aims to generate images that are not only of high visual quality but also semantically correspond to the input text. T2I models are usually trained with image-text pairs, where text is taken as input conditions, with the paired image being the targeted output. Abstracted from the wide range of T2I models shown in Figure 3.2, we give a high-level overview of the representative image generation techniques.
T2I生成旨在生成不仅视觉质量高,而且在语义上与输入文本相对应的图像。T2I模型通常使用图像-文本对进行训练,其中文本被视为输入条件,配对图像是目标输出。从图3.2中显示的广泛的T2I模型范围中抽象出来,我们对代表性的图像生成技术进行了高层次的概述。
GAN(生成器和判别器+两者对抗试图区分真假→引导生成器改进生成能力)、VAE(概率模型+编码器和解码器→最小化重构误差+KL散度正则化)、离散图像token预测(成对图像标记器和解标记器的组合+令牌预测策略【自回归Transformer+按顺序生成视觉标记+左上角开始】)、扩散模型(采用随机微分方程将随机噪声逐渐演化成图像=随机图像初始化+多次迭代再细化+持续演变)、
>>Generative adversarial networks (GAN). GANs (Goodfellow et al., 2020; Creswell et al., 2018; Kang et al., 2023) consist of two key components: a generator and a discriminator. The generator is tasked with creating synthetic images from random noise inputs, and it is trained to adjust these noise inputs based on input text conditions to generate semantically relevant images. In this adversarial process, the discriminator competes with the generator, attempting to differentiate between the synthetically generated images and real ones, thus guiding the generator to improve its image creation capabilities.
>>Variational autoencoder (VAE) Variational Autoencoder (VAE) (Kingma and Welling, 2013; van den Oord et al., 2017; Vahdat and Kautz, 2020) is a probabilistic model that can generate im- ages by employing paired encoder and decoder network modules. The encoder network optimizes the encoding of an image into a latent representation, while the decoder refines the process of converting the sampled latent representations back into a new image. VAEs are trained by min- imizing the reconstruction error between the original and decoded images, whileregularizing the encoded latent space using the Kullback-Leibler (KL) divergence. Vector Quantised-VAE (VQ- VAE) (van den Oord et al., 2017) further improves VAEs by leveraging the discrete latent space through vector quantization, enabling improved reconstruction quality and generative capabilities.
>>Discrete image token prediction. At the core of this approach lies a combination of a paired image tokenizer and detokenizer, like Vector Quantized Generative Adversarial Networks (VQ- GAN) (Esser et al., 2021), which efficiently transform continuous visual signals into a finite set of discrete tokens. In this way, the image generation problem is converted to a discrete token pre- diction task. A widely employed strategy for token prediction is to use an auto-regressive Transformer (Ramesh et al., 2021b; Yu et al., 2022b) to sequentially generates visual tokens, typically starting from the top left corner and moving row-by-row towards the bottom right, conditioned on the text inputs. Alternatively, studies (Chang et al., 2022, 2023) also explore the parallel decoding to speed up the token prediction process. Finally, the predicted visual tokens are detokenized, culminating in the final image prediction.
>>Diffusion model. Diffusion models (Sohl-Dickstein et al., 2015; Song and Ermon, 2020; Ho et al., 2020) employ stochastic differential equations to evolve random noises into images. A diffusion model works by initiating the process with a completely random image, and then gradually re- fining it over multiple iterations in a denoising process. Each iteration predicts and subsequently removes an element of noise, leading to a continuous evolution of the image, conditioned on the input texts.
>> 生成对抗网络(GAN)。GANs(Goodfellow等人,2020;Creswell等人,2018;Kang等人,2023)包括两个关键组件:生成器和判别器。生成器的任务是从随机噪声输入创建合成图像,并训练它根据输入文本条件调整这些噪声输入以生成语义相关的图像。在这个对抗过程中,判别器与生成器竞争,试图区分合成生成的图像和真实图像,从而引导生成器改进其图像生成能力。
>> 变分自编码器(VAE)。变分自编码器(VAE)(Kingma和Welling,2013;van den Oord等人,2017;Vahdat和Kautz,2020)是一种概率模型,可以通过使用成对的编码器和解码器网络模块生成图像。编码器网络优化将图像编码为潜在表示,而解码器则对将采样的潜在表示转换回新图像的过程进行细化。VAE通过最小化原始图像和解码图像之间的重构误差来训练,同时使用Kullback-Leibler(KL散度)散度来正则化编码的潜在空间。矢量量化-VAE(VQ-VAE)(van den Oord等人,2017)通过矢量量化利用离散潜在空间进一步改进了VAE,提高了重建质量和生成能力。
>> 离散图像token预测。这种方法的核心是一种成对图像标记器和解标记器的组合,例如矢量量化生成对抗网络(VQ-GAN)(Esser等人,2021),它有效地将连续视觉信号转换为有限的离散标记集。通过这种方法,将图像生成问题转化为离散标记预测任务。一种广泛使用的令牌预测策略是使用自回归Transformer (Ramesh et al., 2021b;Yu et al., 2022b)按顺序生成视觉标记,通常从左上角开始,逐行向右下角移动,这取决于文本输入。此外,研究(Chang等人,2022,2023)还探讨了并行解码以加速token预测过程。最后,预测的视觉token被解标记化,最终生成最终图像。
>> 扩散模型。扩散模型(Sohl-Dickstein等人,2015;Song和Ermon,2020;Ho等人,2020)采用随机微分方程将随机噪声逐渐演化成图像。扩散模型通过使用完全随机的图像初始化过程,然后在多次迭代中逐渐对其进行再细化,以去噪的方式进行演化。每个迭代预测并随后移除噪声元素,导致图像的持续演变,以输入文本为条件。
Figure 3.3: An overview of the latent diffusion model architecture. Image credit: Rombach et al. (2022).:潜在扩散模型架构的概述

Stable Diffusion的详解:基于交叉注意力的图像-文本融合机制(如自回归T2I生成),三模块(图像VAE+去噪U-Net+条件编码器)
We use Stable Diffusion (SD) (Rombach et al., 2022) as an example to explain in detail how T2I models work. We choose this model for a variety of reasons. Firstly, SD is one of the most widely used open-source T2I models, which makes it a solid foundation for many alignment techniques we discuss in this chapter. Additionally, as a diffusion-based generation model, it serves as an excellent case study for introducing diffusion models. Finally, its cross-attention-based image-text fusion mechanism is a classic example of various text-conditioned methods, such as auto-regressive T2I generation (Yu et al., 2022b), helping us gain an in-depth understand of the image-text interaction in T2I generation.
Stable Diffusion (SD)1, and its academic version latent diffusion (Rombach et al., 2022), contains mainly three modules, i.e., an image VAE, a denoising U-Net, and a condition encoder, as shown in the left, center, and right part of Figure 3.3, respectively. We will introduce each module and the inference flow for image generation, following the notations in the original latent diffusion pa- per (Rombach et al., 2022).
我们选择稳定扩散(SD)(Rombach等人,2022)作为详细解释T2I模型工作原理的示例。我们选择这个模型有多种原因。首先,SD是最广泛使用的开源T2I模型之一,这使它成为我们讨论本章中许多对齐技术的坚实基础。此外,作为一个基于扩散的生成模型,它为引入扩散模型提供了一个很好的案例研究。最后,它的基于交叉注意力的图像-文本融合机制是各种文本条件方法的经典示例,如自回归T2I生成(Yu等人,2022b),帮助我们深入了解T2I生成中的图像-文本交互。
Stable Diffusion(SD)1及其学术版本latent diffusion(Rombach等人,2022)主要包含三个模块,即图像VAE、去噪U-Net和条件编码器,如图3.3的左侧、中心和右侧所示。我们将介绍每个模块和图像生成的推断流程,遵循原始latent diffusion论文(Rombach等人,2022)中的符号表示。
VAE:包含一对编码器E和解码器D,将RGB图像x编码为潜在随机变量z→对潜在变量解码重建图像
>>VAE. As introduced in the image generation technique overview, the VAE module contains a paired encoder E and decoder D, trained to encode RGB image x into a latent random variable z and then decode the latent to best reconstruct the image. Given an RGB image x ∈ RH×W ×3, the encoder E encodes it into a continuous latent representation z ∈ Rh×w×c. With the parameters of H = W = 512, h = w = 64, and c = 4 in SD, latent z is 48 times smaller than image x, thereby significantly improving the computational efficiency by performing the denoising process in this compressed compact latent space.
>> VAE。正如在图像生成技术概述中所介绍的,VAE模块包含一对编码器E和解码器D,经过训练将RGB图像x编码为潜在随机变量z,然后对潜在变量进行解码以最佳地重建图像。给定RGB图像x∈RH×W ×3,编码器E将其编码为连续的潜在表示z∈Rh×w×c。在SD中H = W = 512, H = W = 64, c = 4的参数下,潜在变量z比图像x小48倍,在压缩的紧凑潜在空间中进行去噪处理,显著提高了计算效率。
文本编码器:使用ViT-L/14 CLIP文本编码器将标记化的输入文本查询y编码为文本特征τ(y)
>>Text encoder. SD is a conditional image generation model, where the input text condition is en- coded using a condition encoder τ . Specifically, SD uses the ViT-L/14 CLIP text encoder (Radford et al., 2021) that encodes the tokenized input text query y into text feature τ (y) ∈ RN ×dτ , where the maximum length N is 77 and text feature dimension dτ is 768.
>> 文本编码器。SD是一个条件图像生成模型,其中输入文本条件使用条件编码器τ进行编码。具体而言,SD使用ViT-L/14 CLIP文本编码器(Radford等人,2021)来将标记化的输入文本查询y编码为文本特征τ(y) ∈ RN ×dτ,其中最大长度N为77,文本特征维度dτ为768。
Figure 3.4: Overview of the ReCo model architecture. Image credit: Yang et al. (2023b).ReCo模型体系结构的概述

去噪U-Net:预测噪声λ (zt, t)与目标噪声λ之间的L2损失来训练
>>Denoising U-Net. The denoising U-Net is the core module for the diffusion image generation process. The module is trained to predict the noise ϵˆ(zt, t) to subtract in the latent space at each denoising timestep t, such that it can step-by-step evolve the initial random noise into a meaningful image latent. The module is trained with the L2 loss between the predicted noise ϵˆ(zt, t) and the target noise ϵ, which is added to the target image latent encoded by VAE encoder E . At inference, the iteratively denoised latent z, started from the random noise, is sent through the VAE decoder D for the final generated image.
In each denoising step, the U-Net takes the text condition as input to generate images that are semantically relevant to the text query. We next detail how the visual stream z ∈ Rh×w×c interacts with the text stream τ (y) ∈ RN ×dτ . The denoising U-Net, similar to a classic U-Net (Ronneberger et al., 2015; Long et al., 2015), consists of a series of spatial downsampling and upsampling blocks
with skip connections in between. In SD’s U-Net, each down/upsampling block has a cross- attention layer and a 2D convolutional down/upsampling layer. Each block takes the visual latent feature, text feature, and denoising step as input and generates the next visual latent feature. The image-text interaction happens in the image-text cross-attention layer.
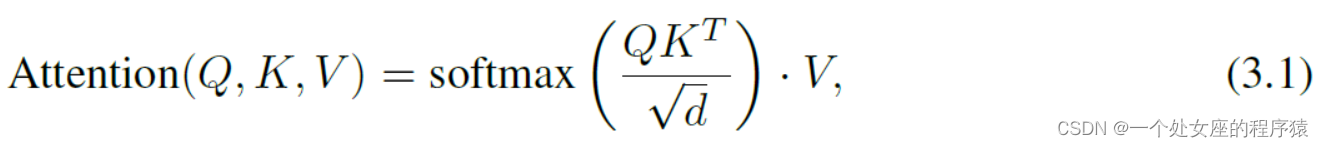
where K, V are projected from the text stream τ (y) and Q is projected from the visual stream z to share the same hidden dimension d. Therefore, the softmax between Q and K produces an attention map M of size (hw × d) · (N × d)T = hw × N . The cross-attention map M indicates the fine-grained image-text interaction among each one of the N text words in all spatial positions hw. The attention map M then products V to yield the output of a down/upsampling block.
>> 去噪U-Net。去噪U-Net是扩散图像生成过程的核心模块。该模块被训练来预测在每个去噪时间步长t的潜在空间中要减去的噪声λ (zt, t),这样它就可以逐步将初始随机噪声演变成有意义的图像潜在。该模块使用预测噪声λ (zt, t)与目标噪声λ之间的L2损失进行训练,并将其添加到由VAE编码器E编码的目标图像潜函数中。在推理时,从随机噪声开始,迭代去噪的潜函数z通过VAE解码器D发送到最终生成的图像。
在每个去噪步骤中,U-Net将文本条件作为输入,生成与文本查询在语义上相关的图像。接下来,我们将详细介绍视觉流z ∈ Rh×w×c如何与文本流τ(y) ∈ RN ×dτ相互作用。与经典U-Net(Ronneberger等人,2015;Long等人,2015)类似,去噪U-Net,由一系列空间下采样和上采样块组成,其中间有跳跃连接。
在SD的U-Net中,每个下/上采样块都有一个交叉注意层和一个二维卷积下/上采样层。每个块以视觉潜特征、文本特征和去噪步骤为输入,生成下一个视觉潜特征。图像-文本交互发生在图像-文本交叉注意层。
其中,K、V从文本流τ(y)投影出来,Q从视觉流z投影出来,以共享相同的隐藏维度d。因此,Q和K之间的softmax产生大小为(hw × d) · (N × d)T = hw × N的注意力图M。交叉注意图M表示N个文本单词在所有空间位置hw中每个单词之间的细粒度图像-文本交互。然后,注意力图M与V相乘,产生下/上采样块的输出。
3.2、Spatial Controllable Generation空间可控生成
痛点:仅使用文本在某些描述方面是无效(比如空间引用),需额外空间输入条件来指导图像生成
T2I generation takes open-ended text for users to describe their intended images. However, text alone is ineffective in certain descriptions, such as spatial referring. Studies in spatial controllable T2I generation explore extending T2I models to take extra spatial input conditions to guide image generation process.
T2I生成允许用户使用开放性文本来描述他们想要的图像。然而,仅仅使用文本在某些描述方面是无效的,比如空间引用。在空间可控T2I生成研究中,研究探索扩展T2I模型,以额外的空间输入条件来指导图像生成过程。
三个主题:
We categorize related studies into three topics. (i) We start with works (Yang et al., 2023b; Li et al., 2023n; Avrahami et al., 2023b; Cho et al., 2023) that extend the image-level text description in vanilla T2I models to the region-grounded text description, such that open-ended text descriptions can precisely operate on a particularly spatial region. (ii) We then extend from boxes to dense spatial conditions represented as 2D arrays, such as segmentation masks, edge maps, depth maps, key points. We review representative works ControlNet (Zhang and Agrawala, 2023) and many others (Mou et al., 2023; Zeng et al., 2023; Zhao et al., 2023b; Qin et al., 2023a). (iii)The previous two threads of work require finetuning T2I models to understand the extended spatial condition. We next review techniques of inference-time guidance (Bansal et al., 2023; Chen et al., 2023e) that achieve spatial control without model finetuning.
我们将相关研究分为三个主题。
(i)我们首先从扩展普通T2I模型中的图像级文本描述到基于区域文本描述的作品开始(Yang等人,2023b;Li等人,2023n;Avrahami等人,2023b;Cho等人,2023),这样开放式文本描述可以在特定的空间区域上精确操作。
(ii)然后,我们从方框扩展到表示为2D数组的密集空间条件,如分割掩码、边缘图、深度图、关键点。我们回顾了代表性的作品ControlNet(Zhang和Agrawala,2023)以及许多其他作品(Mou等人,2023;Zeng等人,2023;Zhao等人,2023b;Qin等人,2023a)。
(iii)前两个研究方向需要对T2I模型进行微调以理解扩展的空间条件。接下来,我们将回顾推理时引导技术(Bansal等人,2023;Chen等人,2023e),这些技术可以实现空间控制而无需模型微调。
Region-controlled T2I generation区域可控T2I生成:可显著提高生成高分辨率图像,但缺乏空间可控性,需开放性文本描述的额外输入条件,如ReCo/GLIGEN
Region-controlled T2I generation. Large-scale T2I models have demonstrated remarkable efficacy in generating high-resolution images. However, the models lack spatial controllability, e.g., precisely specifying content in a specified area using a free-form text description. This limitation motivates the studies on region-controlled T2I generation. As shown in the left side of Figure 3.4, these studies explore the extra input condition of open-ended text descriptions on arbitrary regions (i.e., region-controlled text), augmenting the global image description in T2I models. This new input condition requires T2I models to understand spatial inputs, and associate them with grounded texts.
区域可控T2I生成。大规模T2I模型已经证明在生成高分辨率图像方面具有显著的效果。然而,这些模型缺乏空间可控性,例如,使用自由形式的文本描述精确指定指定区域中的内容。这一限制促使了区域可控T2I生成的研究。如图3.4的左侧所示,这些研究探索了开放性文本描述在任意区域上的额外输入条件(即区域控制文本),扩充了T2I模型中的全局图像描述。这种新的输入条件要求T2I模型理解空间输入,并将其与基础文本联系起来。
ReCo:核思想是扩展文本编码器E的词汇表+采用额外的位置标记来增强→区域可控T2I生成关于提高人类意图对齐的三大优点(可以更准确地反映人的意图+更好地生成图像的正确对象数量、空间关系和区域属性+可以提高图片生成质量)
“区域可控T2I生成”的三大优点是:
(i)提供了额外的输入条件,使用户能够轻松指定所需的图像,即在特定位置精确描述自由格式的区域,从而使扩展易于使用;
(ii)额外的区域级可控文本有助于更好地生成具有正确对象计数、空间关系和区域属性(如颜色/大小)的图像,而这可能会使普通的T2I模型混淆;
(iii)研究还观察到图像生成质量更高,推测是因为基于区域的文本提供了对象级别的图像-文本关联,从而简化了学习过程。
ReCo (Yang et al., 2023b) is among the most representative works along this direction. The core idea is to extend the text vocabulary of the text encoder E and arrange different tokens to represent the grounded text inputs. The study augments text tokens understood using pre-trained T2I models with an extra set of position tokens, which represent the quantized spatial coordinates. As shown in Figure 3.4, the position tokens (e.g., <687>, <204>, <999>, <833>) are seamlessly mixed with the text tokens and operate as a spatial modifier, indicating that the text to follow only operates on the specified spatial region, such as the “baseball player . . . jersey.” The pre-trained T2I model is then finetuned to support such a new input interface, thereby facilitating region-controlled T2I generation.
Shared by other approaches along this direction, ReCo discusses several advantages of region- controlled T2I generation in improving the alignment with human intents. (i) The grounded texts provide an extra input condition that allows users to specify the desired image easily, i.e., having a free-form regional description precisely at a specific location. The box token and the input sequence design allow users to generate grounded text with the same user interface as query a T2I model with text, making the extension easy to use. (ii) The additional region-level controlled texts help better generate images with correct object count, spatial relationship, and region attributes such as color/size, which may otherwise confuse the vanilla T2I model (Rombach et al., 2022). (iii) Studies also observe a better image generation quality, with the conjecture that the grounded text provides object-level image-text association and therefore simplifies the learning process.
ReCo(Yang等人,2023b)是这个方向上最具代表性的作品之一。其核心思想是扩展文本编码器E的文本词汇表,并安排不同的token来表示基础文本输入。该研究用一组额外的位置标记(表示量化的空间坐标)增强了使用预训练的T2I模型所理解的文本标记。如图3.4所示,位置token(例如,<687>,<204>,<999>,<833>)与文本token无缝无缝混合,并作为空间修饰符操作,表明后面的文本仅在指定的空间区域上操作,例如“棒球运动员...球衣”。然后,对经过预训练的T2I模型进行微调,以支持这种新的输入接口,从而促进区域可控T2I生成。
与这个方向的其他方法共享,ReCo讨论了区域可控T2I生成在提高与人类意图的一致性方面的一些优点。
(i)基础文本提供了额外的输入条件,允许用户轻松指定所需的图像,即在特定位置精确地具有自由形式的区域描述。框token和输入序列设计允许用户以与查询T2I模型相同的用户接口生成基础文本,使扩展易于使用。
(ii)额外的区域级受控文本有助于更好地生成具有正确的对象计数、空间关系和区域属性(如颜色/大小)的图像,否则这可能会使普通T2I模型(Rombach等人,2022)感到困惑。
(iii)研究还观察到更好的图像生成质量,认为基础文本提供了对象级别的图像-文本关联,因此简化了学习过程。
GLIGEN:即插即用的方法,冻结原始的T2I模型+训练额外的门控自注意层
GLIGEN (Li et al., 2023n) is another representative work. Alternate to generating grounded de- scriptions through the expansion of input tokens and finetuning the entire T2I model, GLIGEN uses a plug-and-play recipe: freezing the original T2I model and training extra gated self-attention layers to learn the new grounding skills. The grounding tokens carry two types of information: the seman- tic representation of text words that need to be grounded in and their spatial configurations. These grounding tokens are then added to the pre-trained T2I model via a newly added gated self-attention layer, with all remaining pre-trained parameters frozen. This layer is equipped with a gating pa- rameter, which is initialized to zero, allowing the pre-trained model to incrementally incorporate the grounded text inputs. GLIGEN facilitates various types of grounded controls, including bounding box grounding, keypoint grounding, image prompting, as well as other types of spatially-aligned dense conditions.
GLIGEN(Li等人,2023n)是另一个代表性的作品。与通过扩展输入token并微调整个T2I模型来生成基本的描述不同,GLIGEN使用了一种即插即用的方法:冻结原始的T2I模型,并训练额外的门控自注意层来学习新的基准技能。基准token携带两种类型的信息:需要在其中进行基准的文本词的语义表示以及它们的空间配置。然后,这些基准token通过新添加的门控自注意层添加到经过预训练的T2I模型中,并冻结所有剩余的预训练参数。该层配备了一个门控参数,该参数初始化为零,允许预训练模型逐渐将基础文本输入融入其中。GLIGEN支持各种类型的基准控制,包括边界框基准、关键点基准、图像提示,以及其他类型的空间对齐的密集条件。
T2I generation with dense conditions—T2I生成与密集条件
ControlNet:基于稳定扩散+引入额外的可训练的ControlNet分支(额外的输入条件添加到文本提示中)
In addition to spatial coordinates, there exist other spatial conditions often represented as 2D arrays, such as segmentation masks, edge maps and depth maps. ControlNet (Zhang and Agrawala, 2023) is a prominent example of incorporating these dense spatial controls into T2I models. ControlNet is built upon Stable Diffusion, and introduces an additional trainable ControlNet branch that adds an extra input condition to the text prompt. This extra con- dition can be a canny edge map, hough line, HED boundary, under sketching, human pose maps, segmentation masks, depth images, normal maps, or line drawing, each enabled with its distinct model copy. The added branch is initialized from the pre-trained downsampling blocks in the SD’s U-Net. This branch takes the added visual latent and the extra dense condition as input. Before com- bining input dense conditions with visual latent in the input and merging the ControlNet branch’s output back to SD’s upsampling blocks, there is a unique zero-initialized 1 × 1 convolutional layer.This layer serves as a gated connector to gradually inject the extra condition into the pre-trained Stable Diffusion model. With the extra dense spatial control, ControlNet provides an effective channel of generation controllability.
除了空间坐标,还存在其他经常表示为2D数组的空间条件,例如分割掩码、边缘图和深度图。ControlNet(Zhang和Agrawala,2023)是将这些密集空间控制集成到T2I模型中的突出示例。ControlNet建立在稳定扩散的基础上,并引入了一个额外的可训练的ControlNet分支,将额外的输入条件添加到文本提示中。这个额外的条件可以是一个精细边缘图、霍夫线、HED边界、草图、人体姿势图、分割掩码、深度图、法线图或线条绘图,每种类型都启用了其自身的独特的模型副本。添加的分支是从SD的U-Net中的预训练下采样块初始化的。该分支接受添加的视觉潜在和额外的密集条件作为输入。在将输入密集条件与视觉潜在的输入相结合并将ControlNet分支的输出合并回SD的上采样块之前,还有一个独特的零初始化1×1卷积层。该层充当了一个门控连接器,逐渐将额外的条件注入预训练的稳定扩散模型。通过额外的密集空间控制,ControlNet提供了一种有效的生成可控性渠道。
Uni-ControlNet(统一输入条件+使单一模型能够理解多种输入条件类型)、Disco(生成可控元素【人类主题/视频背景/动作姿势】人类跳舞视频=成功将背景和人体姿势条件分开;
ControlNet的两个不同分支【图像帧+姿势图】,人类主体、背景和舞蹈动作的任意组合性)
Follow-up studies such as Uni-ControlNet (Zhao et al., 2023b) and UniControl (Qin et al., 2023a) further improve ControlNet by unifying the input condition, such that a single model can under- stand multiple input condition types or even take a combination of two conditions. Examples of the dense controls and the corresponding generated images are shown in Figure 3.5.
后续研究,如Uni-ControlNet(Zhao等人,2023b)和UniControl(Qin等人,2023a),通过统一输入条件进一步改进了ControlNet,使单一模型能够理解多种输入条件类型,甚至可以接受两种条件的组合。密集控制的示例以及相应的生成图像显示在图3.5中。
Moreover, Disco (Wang et al., 2023f) exemplifies the efficiency of ControlNet in the generation of human dancing videos, which aims to generate videos with controllable elements such as human subjects, video backgrounds, and motion pose sequences. The study successfully separates the background and human pose conditions, which are fed into two distinct branches of ControlNet, which condition on image frames and pose maps, respectively. This disentanglement of control from all three con- ditions allows Disco to accomplish high fidelity in both the human foregrounds and backgrounds.More importantly, it enables the arbitrary compositionality of human subjects, backgrounds, and dance movements.
此外,Disco(Wang等人,2023f)展示了ControlNet在生成具有可控元素的人类跳舞视频方面的效率,该视频旨在生成具有可控元素的视频,例如人类主题、视频背景和动作姿势序列。该研究成功地将背景和人体姿势条件分开,它们被馈送到ControlNet的两个不同分支中,这两个分支分别在图像帧和姿势图上进行条件控制。这种从所有三个条件中分离控制的方法允许Disco在人类前景和背景中实现高保真度。更重要的是,它实现了人类主体、背景和舞蹈动作的任意组合性。
Figure 3.5: Examples of the dense controls and the corresponding generated images. Image credit: Zhao et al. (2023b).
Figure 3.6: Qualitative results of inference-time spatial guidance. Image credit: Bansal et al. (2023).

Inference-time spatial guidance推理时的空间指导:
The aforementioned works require model training, either the T2I models or additional modules to understand the extra spatial conditions. Alternatively, stud- ies (Bansal et al., 2023; Chen et al., 2023e) explore providing the inference-time spatial guidance to T2I models without extra model training. The core idea is similar to classifier guidance (Dhariwal and Nichol, 2021), which takes a discriminator loss to guide the diffusion process as follows:
Taking spatial control as an example, the discriminator can be a Faster-RCNN object detector (Ren et al., 2015) indicated by f , which operates on the intermediate estimated image zˆ0, and compute the object detection loss ℓ with the desired layout c, to guide the generation ϵˆ(zt, t). s(t) is the guidance strength. This approach enables the spatial control in T2I generation without extra training, with qualitative results shown in Figure 3.6. However, it may not yield results as precise as those from finetuning methods (Yang et al., 2023b; Li et al., 2023n; Zhang and Agrawala, 2023).
上述工作需要模型训练,无论是T2I模型还是附加模块,以了解额外的空间条件。另外,研究表明(Bansal等人,2023;Chen et al., 2023e)探索在不进行额外模型训练的情况下为T2I模型提供推理时间空间指导。其核心思想类似于分类器指导(Dhariwal和Nichol,2021),该方法采用判别器损失来指导扩散过程,如下所示:
以空间控制为例,判别器可以是一个由f指示的Faster-RCNN目标检测器(Ren等人,2015),它在中间估计的图像zˆ0上运行,并使用所需的布局c计算目标检测损失ℓ,以指导生成ϵˆ(zt, t)。s(t)为引导强度。该方法无需额外训练即可实现T2I代的空间控制,定性结果如图3.6所示。然而,它可能不会产生与微调方法一样精确的结果(Yang等人,2023b;Li等人,2023n;Zhang和Agrawala,2023)。
Summary and trends总结和趋势:早期-空间可控生成的研究(如layout-to-image/mask-to-image)→近期-将空间条件与文本条件相结合的研究(2个主要趋势=区域可控T2I生成【如ReCo】+整合额外类图像的条件)→未来(引入微调阶段来理解图像和文本输入)
Early research on spatial controllable generation, such as layout-to-image and mask-to-image generation, was often treated in parallel with T2I generation. However, with the emergence of advanced large-scale T2I models, recent studies, as discussed in this subsection, are now leaning towards integrating spatial conditions with textual conditions. We identify two primary trends in integrating spatial conditions into T2I models. First, region-controllable T2I generation, such as ReCo, merges spatial coordinate control into text inputs by enlarging the text vocabulary with position tokens. Second, studies extended from ControlNet integrate an additional “image- like” condition to T2I frameworks, thereby capturing a broad spectrum of dense conditions. Moving forward, T2I models may have a finetuning stage that allows them to comprehend both image and text inputs. In such a scenario, box coordinates could be incorporated through text, while dense controls could be provided as image inputs. We will explore and elaborate on this idea in Section 3.5.
早期对空间可控生成的研究,如布局到图像和掩码到图像生成,通常与T2I生成并行处理。然而,随着先进大规模T2I模型的出现,最近的研究,如本小节所讨论的,现在更倾向于将空间条件与文本条件相结合。我们确定了将空间条件整合到T2I模型中的两个主要趋势。
首先,区域可控T2I生成,如ReCo,通过使用位置标记扩大文本词汇表,将空间坐标控制合并到文本输入中。
其次,从ControlNet扩展到T2I框架的研究整合了一个额外的“类图像”条件,从而捕获了广泛的密集条件。
在未来,T2I模型可能会有一个微调阶段,使它们能够理解图像和文本输入。在这种情况下,可以通过文本合并框坐标,而密集控件可以作为图像输入提供。我们将在第3.5节探讨和详细阐述这个想法。
3.3、Text-based Editing基于文本的编辑
文本到图像编辑:通过给定的图像和输入文本描述合成新的图像+保留大部分视觉内容+遵循人类意图
Text-to-image editing synthesizes new images from an given image and input text descriptions. Instead of producing an image entirely from scratch, users might already possess a satisfactory starting point; this could be an image previously generated from a T2I model or a natural image. The objective is to retain the majority of the visual content, only modifying specific components. This could involve altering a local object or the overall image style to precisely match the user’s intentions. This text-based editing approach offers users a tool to generate fresh images based on a predecessor, playing a crucial role in creating visual content that accurately follows human intent.
文本到图像编辑是通过给定的图像和输入文本描述合成新的图像。与完全从头开始生成图像不同,用户可能已经拥有一个令人满意的起点;这可以是之前从T2I模型生成的图像或自然图像。其目标是保留大部分视觉内容,只修改特定组件。这可能涉及到修改局部对象或整体图像风格,以精确匹配用户的意图。这种基于文本的编辑方法为用户提供了一个工具—基于前身生成新的图像的工具,在创建准确遵循人类意图的视觉内容方面发挥着至关重要的作用。
Figure 3.7: Three types of editing (word swap, adding new phrases, attention re-weighting) on synthetically generated images, enabled by attention map manipulation. Image credit: Hertz et al.(2022).通过注意图操作,对合成图像进行三种编辑(换词、添加新短语、注意力重加权)

三个代表性方向:改变局部图像区域(删除或更高)、语言用作编辑指令、编辑系统集成不同的专业模块(如分割模型和大型语言模型)
There are various definitions and task setups in text-based editing. We introduce the following repre- sentative threads. (i) One classic editing scenario is to change a local image region, such as remov-ing or changing an object or adding an object in a certain region. Spatially manipulating the latent in image generation according to the user-generated masks is a simple but effective method (Avra- hami et al., 2022b,a; Meng et al., 2021). Studies (Balaji et al., 2022; Hertz et al., 2022) also show that manipulating the image-text cross-attention mask is effective for spatial editing. (ii) Extended from spatial editing where the language inputs describe the desired appearance in the spatial region, language can also be used as editing instruction to tell the machine what to do (Kawar et al., 2023; Brooks et al., 2023), such as “change object A in the image to object B.” (iii) Instead of extending a single T2I model for editing, editing systems (Wu et al., 2023a) integrate different specialized modules such as segmentation models (Kirillov et al., 2023; Zou et al., 2023b) and large language models (Brown et al., 2020; OpenAI, 2023a).
基于文本的编辑有不同的定义和任务设置。我们介绍以下代表性的方向。
(i)一个经典的编辑场景是改变局部图像区域,例如删除或更改某个区域的对象或在某个区域添加对象。根据用户生成的掩码对图像生成进行空间操作是一种简单但有效的方法(Avra- hami等人,2022b,a;Meng等人,2021)。研究还表明,操纵图像-文本交叉注意力掩码对于空间编辑是有效的(Balaji等人,2022;Hertz等人,2022)。
(ii)从空间编辑扩展到语言输入描述了空间区域中所需外观的情况,语言也可以用作编辑指令,告诉机器要做什么(Kawar等人,2023;Brooks等人,2023),例如“将图像中的对象A更改为对象B”。
(iii)编辑系统(Wu等人,2023a)不是扩展单一T2I模型用于编辑,而是集成了不同的专业模块,如分割模型(Kirillov等人,2023;Zou等人,2023b)和大型语言模型(Brown等人,2020;OpenAI,2023a)。
Diffusion process manipulations扩散过程操作:编辑合成生成的图像(如SDEdit/混合潜在扩散/Prompt2Prompt)→编辑真实的自然图像(待编辑的图像表示为文本嵌入,如Imagic)
The multi-step denoising process in diffusion image generation naturally supports a certain extent of image editing. Stochastic Differential Editing (SDEdit) (Meng et al., 2021) shows that first adding noises to the input image to edit and then subsequently denoising the sample, could produce a meaningful edit. Blended Latent Diffusion (Avrahami et al., 2022a) shows that the diffusion process manipulation can achieve local object editing with a user-generated object mask mlatent. In each diffusion step, the latent z is a spatial blend of the foreground and background latent: z = zf g ⊙ mlatent + zbg ⊙ (1 − mlatent), where zf g is the edited object generated from the text description and zbg is the original backgrund image with noises added.
However, there are certain limitations on blending spatial latents. Firstly, it may not always be feasible to require human-generated masks. Secondly, the generation process can sometimes result in artifacts at the edges. Instead of simply blending the latent in a spatial manner, re- searchers delve into image-text cross-attention maps to unearth clues for object editing. Specifi- cally, Prompt2Prompt (Hertz et al., 2022) discovers that cross-attention layers control the interaction among visual regions and text words. Based on this observation, the study enables three types of editing for images generated by a diffusion T2I model, including word swap, adding new phrases, and attention re-weighting, each of which is enabled with corresponding manipulation on the image- text cross-attention map. Specifically, the Prompt2Prompt tracks both cross-attention maps genertated by the original prompt (namely Mt) and the edited prompt (namely M ∗), and merges the attention maps with pre-defined rules into the new attention maps M�t, which is used for latent com- puting. For example, while adding a new phrase, attention map M�t remains unaltered for words present in the original prompt. It only incorporates the modified attention maps M ∗ for words that did not exist in the original prompt. Qualitative results of the edits are shown in Figure 3.7.
Going beyond editing synthetically generated images, Imagic (Kawar et al., 2023) explores editing real natural images. The core idea is to represent the image to be edited as text embedding, and blend this embedding with the target text embedding describing the desired image. This blend ensures that the resulting image retains elements from the original while aligning with the aesthetics detailed in the target textual prompt. In practice, test-time finetuning is needed to generate high-quality images.
扩散图像生成中的多步去噪过程自然地在一定程度上支持图像编辑。随机差分编辑(SDEdit)(Meng等人,2021)显示,首先对要编辑的输入图像添加噪声,然后对样本进行去噪,可以产生有意义的编辑。混合潜在扩散(Avrahami等人,2022a)显示,扩散过程操作可以使用用户生成的对象掩码mlatent进行局部对象编辑。在每个扩散步骤中,潜在z是前景和背景潜在的空间混合:
z = zf g ⊙ mlatent + zbg ⊙ (1 − mlatent),其中zf g是从文本描述生成的编辑对象,zbg是添加噪声的原始背景图像。
然而,混合空间潜在存在一定的局限性。首先,要求人工生成的掩码并不总是可行的。其次,生成过程有时会在边缘产生伪影。研究人员不仅仅是以空间方式混合潜在,还深入研究图像-文本交叉注意力映射,以挖掘对象编辑的线索。具体来说,Prompt2Prompt(Hertz等人,2022)发现跨注意力层控制视觉区域和文本词之间的交互。基于这一观察,本研究对扩散T2I模型生成的图像进行了三种类型的编辑,包括单词替换、添加新短语和注意力重新加权,每种编辑都通过对图像-文本交叉注意地图的相应操作来实现。具体而言,Prompt2Prompt跟踪由原始提示(即Mt)和编辑提示(即M *)生成的交叉注意映射,并将具有预定义规则的注意映射合并到用于潜在计算的新注意图M *中。例如,当添加一个新短语时,注意力映射M�t对于原始提示中存在的单词保持不变。它仅针对原始提示中不存在的单词合并了修改过的注意图M *。编辑结果的定性结果显示在图3.7中。
除了编辑合成生成的图像,Imagic(Kawar等人,2023)探索编辑真实的自然图像。其核心思想是将待编辑的图像表示为文本嵌入,并将该嵌入与描述所需图像的目标文本嵌入进行相融合。这种混合确保了最终图像保留了原始图像的元素,同时与目标文本提示中的美学细节保持一致。在实践中,需要对Test-time进行微调以生成高质量的图像。
Text instruction editing文本指令编辑:直接使用语言指定编辑指令,如InstructPix2Pix(接受图像和文本编辑指令,以生成输入图像的编辑版本)、Prompt2Prompt(将原始和编辑后的字幕对转换为编辑前后的一对图像)、CM3Leon
Instead of repeating the visual contents of the image to edit in the text prompts, it might be more efficient for users to directly specify editing instructions using language, such as “swap sunflowers with roses” in Figure 3.8. The desired text instruction editing model should work on both model-generated and natural images, and across different types of editing instructions.
InstructPix2Pix (Brooks et al., 2023) is designed to accept an image and a text editing instruction to produce an edited version of the input image. The goal is to train an image-to-image model that can understand such editing text instructions. To achieve this, T2I models can be adapted to ac- cept the additional image input by incorporating more input channels into the SD’s convolutional layer. The main challenge is how to generate paired editing data. As shown in Figure 3.9, Instruct- Pix2Pix (Brooks et al., 2023) proposes to use a LMM (Brown et al., 2020) to generate a pair of an editing instruction and an edited caption from the original input caption, e.g., “have her ride a dragon,” “photograph of a girl riding a dragon,” and “photograph of a girl riding a horse.” The study then uses Prompt2Prompt (Hertz et al., 2022) to convert the original and edited caption pair to a pair of images before and after editing, corresponding to the GPT-generated editing instruction. The study generates over 450K samples to train the editing model. This data generation method has also been adopted in subsequent research, such as CM3Leon (Ge et al., 2023) for training general- purpose image-text-to-image models.
与在文本提示中重复要编辑的图像的视觉内容不同,用户直接使用语言指定编辑指令可能更有效,例如在图3.8中的“将向日葵与玫瑰交换swap sunflowers with roses”。所需的文本指令编辑模型应该适用于模型生成的图像和自然图像,并且可以跨不同类型的编辑指令。
InstructPix2Pix(Brooks等人,2023)设计用于接受图像和文本编辑指令,以生成输入图像的编辑版本。目标是训练一个图像到图像的模型,它可以理解这样的编辑文本指令。为了实现这一目标,T2I模型可以通过在SD的卷积层中加入更多的输入通道来适应接收额外的图像输入。主要挑战在于如何生成配对的编辑数据。如图3.9所示,Instruct-Pix2Pix(Brooks等人,2023)提出使用LMM(Brown等人,2020)从原始输入标题生成编辑指令和编辑说明的一对,例如“让她骑龙”,“一张女孩骑龙的照片”和“一张女孩骑马的照片”。然后,该研究使用Prompt2Prompt(Hertz等人,2022)将原始和编辑后的字幕对转换为编辑前后的一对图像,与GPT生成的编辑指令相对应。该研究生成了超过45万个样本来训练编辑模型。这种数据生成方法还被采用到后续的研究中,如CM3Leon (Ge et al., 2023)用于训练通用的图像-文本-图像模型。
Figure 3.8: Examples of text instruction editing. Image credit: Brooks et al. (2023).文本指令编辑的示例
Figure 3.9: The editing data generation pipeline proposed in InstructPix2Pix. Image credit: Brooks et al. (2023).在InstructPix2Pix中提出的编辑数据生成管道

Editing with external pre-trained models使用外部预训练模型进行编辑:两个趋势=将外部语言和视觉模型纳入编辑(如SAM/SEEM/Instruct X-Decoder)+通过LMM为各种生成和编辑工具分配任务(如VisualChatGPT)
Furthermore, recent studies show the efficacy of incor- porating external language and vision models for editing, as opposed to relying solely on a single model. Advancements in generalist segmentation models, such as SAM (Kirillov et al., 2023) and SEEM (Zou et al., 2023b), have paved the way for using segmentation models to ground the re- gion for text-based editing. Representative works include Instruct X-Decoder (Zou et al., 2023a), Grounded SAM inpainting (Liu et al., 2023h), Inpaint anything (Yu et al., 2023c), etc.. Another emerging trend is the allocation of various generation and editing tools through LMM. Studies such as VisualChatGPT (Wu et al., 2023a) can solve complicated visual editing that requires the collabo- ration of multiple generation and editing models in multiple steps.
此外,最近的研究显示,与仅依赖于单一模型相比,将外部语言和视觉模型纳入编辑是有效的。通用分割模型的进步,如SAM(Kirillov等人,2023)和SEEM(Zou等人,2023b)),为使用分割模型来基于文本编辑铺平了道路。代表性的研究包括Instruct X-Decoder(Zou等人,2023a)、Grounded SAM inpainting(Liu等人,2023h)、Inpaint anything(Yu等人,2023c)等。另一个新兴趋势是通过LMM为各种生成和编辑工具分配任务。如VisualChatGPT(Wu等人,2023a)可以解决需要多个生成和编辑模型在多个步骤中协作的复杂视觉编辑问题。
Summary and trends总结和趋势:早期(需要用户生成的对象掩码进行对象编辑)→近期(在没有掩码输入的情况下处理合成生成的图像)→未来(期待一个基于编辑指令的能够处理图像和文本输入的全方位生成基础模型)
Text-based editing models have made significant progress in their capa- bilities, leading to improved editing quality, expanded domain coverage, and more flexible user interface. For example, early studies require user-generated masks for object editing, while recent models can work on synthetically generated images without mask inputs, or even directly under- stand general text editing instructions. As we look to the future, we anticipate an all-encompassing generative foundation model that is capable of processing both image and text inputs. Within this framework, editing instructions would be a specialized form of text input, seamlessly integrated with the image description in T2I generation.
基于文本的编辑模型在其功能方面取得了显著的进展,提高了编辑质量,扩展了领域覆盖范围,并提供了更灵活的用户接口。例如,早期的研究需要用户生成的对象掩码进行对象编辑,而最近的模型可以在没有掩码输入的情况下处理合成生成的图像,甚至可以直接理解一般的文本编辑指令。展望未来,我们期待一个能够处理图像和文本输入的全方位生成基础模型。在这个框架内,编辑指令将是一种特殊形式的文本输入,与T2I生成中的图像描述无缝集成。
3.4、Text Prompts Following文本提示跟随
采用图像-文本对鼓励但不强制完全遵循文本提示→当图像描述变得复时的两类研究=推断时操作+对齐调整
Training with image-text pairs encourages T2I models to generate images that semantically corre- spond to the input text condition. However, the image generation training objective does not directly enforce generated images to exactly follow text prompts. Studies (Feng et al., 2022b; Chefer et al.,2023) show that T2I models may fail to follow text prompts, especially when the image description becomes complicated. For example, certain noun phrases may get omitted, attributes may apply to incorrect objects, and generated images may have the wrong object count, relationship, styles, etc.. These limitations motivate work on improving T2I models to better follow text prompts.
The related literature can be broadly categorized into two main groups. (i) Inference-time manip- ulation. In the inference stage, the latent and attention adjustment (Liu et al., 2022a; Feng et al., 2022b; Chefer et al., 2023; Agarwal et al., 2023) design various methods to redistribute the visual latent or image-text cross-attention, such that all noun phrases in the text prompts are represented in the generated image. (ii) Alignment tuning. An extra model learning stage is learned (Black et al., 2023; Fan et al., 2023b), typically with the image-text similarity as rewards, such that the tuned T2I model can better follow text prompts.
使用图像-文本对进行训练可以鼓励T2I模型生成语义上与输入文本条件相对应的图像。然而,图像生成训练目标并不直接强制生成的图像完全遵循文本提示。研究(Feng等人,2022b;Chefer等人,2023)表明,T2I模型可能无法遵循文本提示,特别是当图像描述变得复杂时。例如,某些名词短语可能被省略,属性可能应用于不正确的对象,生成的图像可能具有错误的对象数量、关系、样式等。这些限制促使进行改进T2I模型以更好地遵循文本提示的工作。
相关文献可以广泛分为两个主要组。 (i)推断时操作。在推断阶段,潜在和注意力调整(Liu等人,2022a;Feng等人,2022b;Chefer等人,2023;Agarwal等人,2023)设计了各种方法,以重新分配视觉潜在或图像-文本交叉注意力,使文本提示中的所有名词短语都在生成的图像中表示。
(ii)对齐调整。学习一个额外的模型学习阶段(Black等人,2023;Fan等人,2023b),通常以图像-文本相似度作为奖励,以便调整的T2I模型可以更好地遵循文本提示。
Figure 3.10: Failure cases of vanilla T2I model in text prompt following. Image credit: Feng et al. (2022b). 如下文本提示的普通型T2I模型失败案例
Figure 3.11: Inference time guidance proposed in Attend-and-Excite. Image credit: Chefer et al.(2023).——Attend-and-Excite中提出的推理时间指导

Figure 3.12: DDPO with vision-language-model-based reward function for image-text alignment tuning. Image credit: Black et al. (2023).带有基于视觉语言模型的奖励函数的DDPO,用于图像-文本对齐调优。

Inference-time manipulation推断时操作:StructureDiffusion(利用解析树来提取名词和结构+强制模型查看所有名词短语)、Attend-and-Excite(操纵了注意力映射+使T2I模型更关注文本提示中描述的对象)
Training with image-text pairs does not guarantee that T2I models consistently adhere to the text prompts. There can be multiple discrepancies, particularly when the text descriptions are lengthy and intricate. For instance, T2I models may apply attributes to the wrong entity or miss certain objects, as shown in Figure 3.10. Intuitively, parsing the text query at inference time and explicitly enforcing T2I models to pay closer attention to each noun phrase may generate images that better follow text prompts.
Building upon this intuition, StructureDiffusion (Feng et al., 2022b) employs a parsing tree to extract noun phrases and the text prompt’s linguistic structure. The study then enforces the model to “look at” all extracted noun phrases. This is implemented by modifying SD’s cross-attention mechanism introduced in (3.1), written as O = M · V where M is the softmax cross-attention map. Instead of producing M with the sentence feature V , which may result in words getting overlooked, the study
where V0 is the sentence feature V , and Vi, i = 1, . . . , k is the phrase feature in the parsing tree. This approach ensures that the visual stream maintains a balanced attention across all identified noun phrases, fostering more accurate image generation.
Motivated by the same objective to ensure that no object is overlooked, Attend-and-Excite (Chefer et al., 2023) manipulates the attention map. As shown in the right side equations in Figure 3.11, a regularization loss ℓ is computed to amplify the maximal attention towards the most neglected subject token:

where G is a Gaussian kernel to smooth the attention map and Nsub is the number of subject tokens. The loss is then used to update the latent zt at inference time:
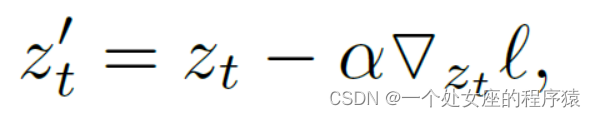
where α is a scalar for the step size. Results show that this inference-time guidance enables T2I models to focus more on objects described in the text prompt, resulting in superior image genera- tion. Follow-up studies (Agarwal et al., 2023) further refine the guidance loss to optimize prompt- following performance.
使用图像-文本对进行训练并不保证T2I模型始终遵循文本提示。特别是当文本描述冗长且复杂时,可能存在多个不一致之处。例如,如图3.10所示,T2I模型可能会将属性应用于错误的实体或遗漏某些对象。直观地说,在推断时解析文本查询,并明确要求T2I模型更仔细地关注每个名词短语可能会生成更好地遵循文本提示的图像。
基于这一直觉,StructureDiffusion(Feng等人,2022b)使用解析树来提取名词短语和文本提示的语言结构。然后,该研究强制模型“查看”所有提取的名词短语。这是通过修改(3.1)中引入的SD的交叉注意力机制来实现的,写为
O = M · V,其中M是softmax交叉注意力映射。
该研究不是使用句子特征V生成M,因为这可能导致忽略单词,而是将M生成为以下形式:
其中V0是句子特征V,Vi,i = 1,...,k是解析树中的短语特征。
这种方法确保视觉流在所有已识别的名词短语之间保持平衡的注意力,从而促进更准确的图像生成。
受相同的目标启发,Attend-and-Excite(Chefer等人,2023)操纵了注意力映射。如图3.11右侧的方程所示,计算了正则化损失ℓ以增强对最容易被忽视的主题标记的最大关注度:
其中G是用于平滑注意力映射的高斯核,Nsub是主题token的数量。然后,损失用于在推断时更新潜在z_t:
其中α是步长的标量。
结果表明,这种推断时引导使T2I模型更关注文本提示中描述的对象,从而实现了更出色的图像生成。随后的研究(Agarwal等人,2023)
进一步细化了导引损失,以优化遵循提示跟随性能。
Model tuning to follow text prompt模型调整以遵循文本提示:强化学习(使用图像-文本相似度作为奖励)、DDPO(利用视觉语言模型转换为文本描述+BERTScore获得相似性奖励来微调预训练T2I模型更好的遵循文本提示)、、
Instead of inference-time manipulation, one may wonder if we can refine a pre-trained T2I model to better follow text prompts. One promising way to achieve this is via reinforcement learning, using image-text similarity as reward instead of the image generation objective used in the main T2I training. This allows the model to be optimized towards a better image-text alignment.
One work along this direction is the denoising diffusion policy optimization (DDPO) (Black et al., 2023), with the tuning framework shown in Figure 3.12. Specifically, a vision-language model (Li et al., 2023e) is used to convert the generated image into a text description. This generated caption is compared with the input text prompt, deriving a similarity reward through the use of BERTScore (Zhang et al., 2019). The similarity reward is then used to finetune the pre-trained T2I model, such that the model can better follow the text prompts. The bottom of Figure 3.12 shows the progression of the generated sample during this similarity-based training. Further, it is worth noting that other human intent may also be formatted as rewards for model tuning, such as compressibility, aesthetic quality, etc.
与推断时操作不同,人们可能想知道是否可以调整预训练的T2I模型以更好地遵循文本提示。实现这一目标的一种有前途的方法是通过强化学习,使用图像-文本相似度作为奖励,而不是主要T2I训练中使用的图像生成目标。这允许模型优化以更好地对齐图像和文本。
沿着这个方向的一项工作是去噪扩散策略优化(DDPO)(Black等人,2023),其调整框架如图3.12所示。具体来说,使用视觉语言模型(Li等人,2023e)将生成的图像转换为文本描述。然后,将生成的标题与输入的文本提示进行比较,通过使用BERTScore(Zhang等人,2019)来获得相似性奖励。然后,相似性奖励用于微调预训练的T2I模型,使模型能够更好地遵循文本提示。图3.12底部显示了这种基于相似性的训练过程中生成样本的进展。此外,值得注意的是,还可以将其他人类意图格式化为模型调优的奖励,例如可压缩性、美学质量等。
Summary and trends总结和趋势:目的(增强T2I模型更好地遵循文本提示能力),通过调整对齐来提升T2I模型根据文本提示生成图像的能力,未来(基于RL的方法更有潜力但需扩展)
In this section, we present studies aimed at enhancing the capability of T2I models to better adhere to text prompts. Despite the good performance achieved by the inference- time manipulation, the alignment tuning provides a more intuitive user experience, eliminating the need for extra modifications. In parallel to instruction tuning in LLMs to align human intent for text generation, the TI2 model tuning shares a similar goal, but focuses on image generation. We foresee a similar paradigm emerging in the near future for generative T2I foundational model devel- opment. Specifically, the initial training phase still relies on the existing image generation objective on large-scale data, while the subsequent alignment-tuning phase enhances the model’s prompt ad- herence and other aspects of human intent, such as diminishing harmful content. Current RL-based methods show potentials, but they typically zero in on a single optimization goal. Future research could extend these methods for more adaptable alignment tuning, amalgamated with features like accommodating diverse image and text scenarios.
在本节中,我们介绍了旨在增强T2I模型更好地遵循文本提示能力的研究。尽管推断时操作取得了良好的性能,但对齐调整提供了更直观的用户体验,消除了对额外修改的需要。与LLMs中的指导调整并行,以对齐人类意图进行文本生成,TI2模型调优具有类似的目标,但重点是图像生成。我们预见未来在生成性T2I基础模型开发方面将出现类似的范式。
具体而言,初始训练阶段仍然依赖于大规模数据上的现有图像生成目标,而随后的对齐调整阶段将增强模型的提示遵循性以及人类意图的其他方面,如减少有害内容。目前基于RL的方法显示出潜力,但它们通常专注于单一的优化目标。未来的研究可以扩展这些方法,使其具有更强的适应性,并结合适应各种图像和文本场景的特征。
Figure 3.13: The problem setup and result visualization of the visual concept customization task. Image credit: Ruiz et al. (2023).可视化概念定制任务的问题设置和结果可视化

3.5、Concept Customization概念定制:旨在使这些模型能够理解和生成与特定情况相关的视觉概念
语言的痛点:表达人类意图强大但全面描述细节效率较低,因此直接通过图像输入扩展T2I模型来理解视觉概念是更好的选择
三大研究(视觉概念自定义在T2I模型中的应用研究进展):单一概念定制、多概念定制、无Test-time微调的定制
Though language is an powerful medium to express human intent, it is inefficient in comprehensively describing all details of a visual concept for reconstruction. For example, it is challenging to use texts to describe my pet dog or family members with sufficient details, so that they can be generated in different visual scenes. In such applications, directly extending T2I models to understand visual concepts via image inputs is a better option.
We examine relevant research on visual concept customization, which offers users the ability to generate these personalized concepts. (i) Pioneer studies (Gal et al., 2022; Ruiz et al., 2023; Wei et al., 2023) start with single-concept customization that involves test-time finetuning to encode multiple images of the visual concept into a new token embedding, such that the learned embedding can be used to refer to the concept during T2I generation. (ii) Multi-concept customization (Kumari et al., 2023; Avrahami et al., 2023a) allows multiple concept tokens to be expanded from the T2I model’s token vocabulary, enabling multiple concepts to interact with each other and the remaining visual scene during generation. (iii) Test-time finetuning requires users to tune T2I models for each new concept to customize. To simplify the usage, studies (Chen et al., 2022f; Shi et al., 2023a; Chen et al., 2023f; Yang et al., 2023a) explore customization without test-time finetuning and uses a unified finetuning stage to extend T2I models for accepting image condition inputs. The models take images of the visual concept as an extra input condition, and generate images with the visual concept following the text descriptions.
尽管语言是表达人类意图的强大媒介,但它在全面描述视觉概念的所有细节方面效率较低。例如,使用文本来足够详细地描述我的宠物狗或家庭成员,以便它们可以在不同的视觉场景中生成,是具有挑战性的。在这些应用中,通过图像输入直接扩展T2I模型来理解视觉概念是一个更好的选择。
我们考察了关于视觉概念定制的相关研究,这为用户提供了生成这些个性化概念的能力。
(i)先驱研究(Gal等人,2022;Ruiz等人,2023;Wei等人,2023)从单一概念定制开始,其中涉及Test-time微调,将视觉概念的多个图像编码为新的token嵌入,这样学习到的嵌入可以用于在T2I生成期间引用该概念。
(ii)多概念定制(Kumari等人,2023;Avrahami等人,2023a)允许从T2I模型的token词汇表中扩展多个概念token,使多个概念可以在生成过程中相互交互并与剩余视觉场景进行互动。
(iii)Test-time微调要求用户为每个新概念进行T2I模型调整以进行定制。为了简化使用,研究(Chen等人,2022f;Shi等人,2023a;Chen等人,2023f;Yang等人,2023a)探索了在没有Test-time微调的情况下进行定制,并使用统一的微调阶段来扩展T2I模型以接受图像条件输入。这些模型将视觉概念的图像作为额外的输入条件,并根据文本描述生成具有视觉概念的图像。
Single-concept customization单一概念定制(比如Textual Inversion/Dreambooth)—需要在Test-time进行微调:针对单个视觉概念进行自定义、通过测试期间微调将多个概念图像编码为新token、该token可以在T2I生成中代表这个特定概念
The goal of visual concept customization is to enable T2I models to comprehend additional visual concepts tailored to very specific cases. The problem setup, studied in Textual Inversion (Gal et al., 2022), involves translating visual concepts from a handful of images into unique token embeddings. As illustrated in the left side of Figure 3.13, the T2I model processes four images of a distinct dog breed, subsequently learning the embedding for a new token, denoted as [V]. This [V] token can be used as a text token to represent this specific dog. The [V] token can be seamlessly integrated with other textual descriptions to render the specific dog in various contexts, such as swimming, in a bucket, and getting a haircut.
Textual Inversion (Gal et al., 2022) learns the [V] token embedding via prefix tuning, i.e., freezing all T2I model’s parameters and training the [V] token embedding to generate the input images. Later studies observe that tuning more model parameters leads to significantly better image generation quality. However, adjusting only the input image may lead to the risk of overfitting the T2I model for a particular concept, and losing the capablity to generate diverse images. For instance, the model might become unable to generate various dog types. To address this, Dreambooth (Ruiz et al., 2023) proposes the class-specific prior preservation loss. Central to this approach is using the pre- trained T2I model to produce images of the same class as the targeted customization concept. The model is then jointly finetuned on both the input image (with the [V] token) and the model-generated images (without the [V] token). This ensures that the model can differentiate between the unique “[V] dog” and other general dogs it was initially trained, thus maintaining its overall T2I capability. Dreambooth then finetunes all T2I model parameters and achieves better image generation quality.
视觉概念定制的目标是使T2I模型能够理解针对非常具体情况量身定制的额外视觉概念。在Textual Inversion(Gal等人,2022)中研究的问题设置涉及将少数图像的视觉概念转换为唯一的token嵌入。如图3.13左侧所示,T2I模型处理四种不同犬种的图像,随后学习新token的嵌入,表示为[V]。这个[V]token可以作为文本token来表示这只特定的狗。[V]token可以与其他文本描述无缝集成,以在不同上下文中呈现特定的狗,例如在游泳,在桶里,理发等情况下。
Textual Inversion(Gal等人,2022)通过前缀微调来学习[V]token嵌入,即冻结所有T2I模型的参数,并训练[V]token嵌入以生成输入的图像。后来的研究观察到微调更多模型参数会显著提高图像生成质量。然而,仅调整输入图像可能会导致过拟合T2I模型适用于特定概念的风险,并且失去了生成多样化图像的能力。例如,模型可能无法生成各种类型的狗。为了解决这个问题,Dreambooth(Ruiz等人,2023)提出了特定类别的先验保留损失。这种方法的核心是使用预训练的T2I模型生成与目标定制概念相同类别的图像。然后,在输入图像(带有[V]token)和模型生成的图像(不带[V]token)上联合微调模型。这确保了模型可以区分唯一的“[V]狗”和其他最初训练的普通狗,从而保持了其整体T2I能力。Dreambooth然后微调了所有T2I模型参数,并实现了更好的图像生成质量。
Multi-concept customization多概念定制(比如Custom Diffusion)—多个概念整合:支持多个视觉概念token、允许多概念在生成图像过程中交互、可以将多个自定义视觉概念整合在一个文本提示中
Building on studies that focused on learning a single visual concept [V], recent research has delved into the possibility of integrating multiple visual concepts into a single Text-to-Image (T2I) model, represented as [V1], [V2], and so on. Custom Diffusion (Kumari et al., 2023) employs a selective subset of model weights, specifically the key and value mappings from text to latent features in the cross-attention layers for concept customization, learned from multiple sets of concept images. The study facilitates the ability to embed multiple customized visual concepts in a single text prompt. Instead of learning from multiple sets of input images, Break-A-Scene (Avrahami et al., 2023a) explores extracting multiple visual concepts in a single image. The study augments input images with segmentation masks to pinpoint the intended target concepts and subsequently transforms them into a series of concept embeddings denoted as [Vi].
在专注于学习单一视觉概念[V]的研究基础上,最近的研究探讨了将多个视觉概念集成到单个文本到图像(T2I)模型中的可能性,表示为[V1],[V2]等等。Custom Diffusion(Kumari等人,2023)从多组概念图像中学习,使用了模型权重的选择性子集,特别是从文本到跨注意层中潜在特征的键和值映射,用于概念定制该研究促进了在单个文本提示符中嵌入多个自定义视觉概念的能力。Break-A-Scene(Avrahami等人,2023a)不是从多组输入图像中学习,而是探索从单个图像中提取多个视觉概念的可能性。该研究通过分割掩码增强输入图像以精确定位所需的目标概念,然后将其转换为一系列概念嵌入,表示为[Vi]。
Figure 3.14: Illustration of in-context concept customization without test-time finetuning. 没有测试时间调整的上下文概念定制的说明。

Customization without test-time finetuning无Test-time微调的定制(如SuTI/InstantBooth)—避免微调:不需要在测试时间进行微调(而是使用统一的微调阶段来扩展T2I模型)、避免测试时微调带来的计算资源需求和使用难度问题、将视觉概念图像作为额外输入条件、在训练过程中改变条件图像+模型能广泛学习不同上下文、可扩展至未见概念和描述
While the concept customization studies, as de- scribed above, have achieved good visual quality, the necessity for test-time finetuning hinders its application in real-world settings. Most end users and application platforms lack the compute resources required for finetuning, not to mention the complexities of finetuning process. This nat- urally leads to the question: can we take concept images as input conditions, and achieve concept customization without finetuning?
The input/output format of the imagined system is similar to the retrieval-augmented genera- tion (Chen et al., 2022f), which aims to ease the image generation by conditioning on a retrieved similar image. The system supports extra image inputs that contain relevant information for the generation process. By altering the conditioning images during the training phase, the model can potentially achieve a broad in-context learning capability, producing images that align with the given input examples. In line with this framework, SuTI (Chen et al., 2023f) trains a single model to imitate the finetuned subject-specific experts, and generates images conditioning on both text and subject input images, as shown in Figure 3.14. As a result, the trained model can perform in-context concept customization without test-time finetuning, and generalize to unseen subjects and descriptions. An- other concurrent work, InstantBooth (Shi et al., 2023a), also shows remarkable results in generating images that are not only aligned with language but also preserve identities, with a single forward pass.
虽然如上所述的概念定制研究已经获得了良好的视觉质量,但Test-time微调的必要性阻碍了其在现实世界中的应用。大多数终端用户和应用平台缺乏进行微调所需的计算资源,更不用说微调过程的复杂性了。这自然引发了一个问题:我们是否可以将概念图像作为输入条件,并在没有微调的情况下实现概念定制?
所设想的系统的输入/输出格式类似于检索增强生成(Chen等人,2022f),其目的是通过对检索到的相似图像进行条件反射来简化图像生成。该系统支持包含生成过程相关信息的额外图像输入。通过在训练阶段改变条件图像,模型可以潜在地实现广泛的上下文学习能力,生成与给定输入示例相符的图像。与这个框架一致,SuTI(Chen等人,2023f)训练了一个单一模型来模仿经过微调的特定主题专家,并生成在文本和主题输入图像的条件下的图像,如图3.14所示。因此,经过训练的模型可以在没有测试时微调的情况下执行上下文概念定制,并泛化到未见的主题和描述。另一项同时进行的工作,InstantBooth(Shi等人,2023a),生成图像方面也显示出显著的结果,这些图像不仅与语言一致,而且还保留了身份,只需一次向前传递。
Summary and trends摘要和趋势:早期(测试阶段微调嵌入)→近期(直接在冻结模型中执行上下文图像生成),两个应用=检索相关图像来促进生成+基于描述性文本指令的统一图像输入的不同用途The field of visual concept customization has advanced from finetuning em- beddings during the testing stage, to directly performing in-context image generation with a frozen model. The in-context generation pipeline, which incorporates additional image inputs, shows re- markable potentials in real-world applications. In this subsection, we have explored two applications of this approach: facilitating generation through the retrieval of pertinent images (Chen et al., 2022f), and personalizing visual concepts by conditioning them on subject images (Chen et al., 2023f; Shi et al., 2023a). An intriguing direction is to unify the diverse uses of image inputs, directed by descriptive textual instructions. We elaborate on this idea in the following sub-section.
视觉概念定制领域已经从测试阶段微调嵌入发展到直接在冻结模型中执行上下文图像生成。在上下文生成流程中,包括额外的图像输入,显示出在现实世界应用中具有显著潜力。在本小节中,我们探讨了这种方法的两个应用:通过检索相关图像来促进生成(Chen等人,2022f),并通过在主题图像上进行条件设置来个性化视觉概念(Chen等人,2023f;Shi等人,2023a)。一个有趣的方向是统一图像输入的不同用途,由描述性文本指令引导。我们将在下一小节详细阐述这个想法。
Figure 3.15: Overview of the unified image and text input interface for human alignments, and its connection to previous sub-sections.人类对齐的统一图像和文本输入界面的概述,以及它与前面子节的联系。

3.6、Trends: Unified Tuning for Human Alignments趋势:人类对齐的统一调整
调整T2I模型以更准确地符合人类意图的三大研究:提升空间可控性、编辑现有图像以改进匹配程度、个性化T2I模型以适应新的视觉概念
一个趋势:即朝着需要最小问题特定调整的整合性对齐解决方案转移
对齐调优阶段有两个主要目的:扩展了T2I的文本输入以合并交错的图像-文本输入,通过使用数据、损失和奖励来微调基本的T2I模型
In previous subsections, we presented the literature related to tuning T2I models to more accurately align with human intent. This includes enhancing spatial controllability, editing existing images for improved alignment, more effectively following text prompts, and personalizing T2I models for new visual concepts. A trend observed across these subtopics is the shift towards integrated alignment solutions that require minimal problem-specific adjustments. Along this direction, we envision a future T2I model having a unified alignment tuning stage, which transforms a pre-trained T2I model into one that resonates more intimately with human intent. Such a model would seamlessly process both text and image inputs, generating the intended visual content without the need for multiple models tailored to different alignment challenges.
在前面的小节中,我们介绍了与调整T2I模型以更准确地与人类意图对齐相关的文献。这包括增强空间可控性,编辑现有图像以改善对齐,更有效地遵循文本提示,以及为新的视觉概念个性化T2I模型。在这些子主题中观察到的趋势是朝着需要最少问题特定调整的集成对齐解决方案的转变。沿着这个方向,我们展望未来的T2I模型将具有统一的对齐调整阶段,将经过预训练的T2I模型转化为更贴近人类意图的模型。这样的模型将无缝处理文本和图像输入,生成所期望的视觉内容,而不需要为不同的对齐挑战量身定制多个模型。
Drawing parallels to the established practice of human-alignment tuning in LLM development, we anticipate that the techniques reviewed in this section will merge into a holistic second-stage tun- ing for generative foundation model development. This alignment tuning phase serves two primary purposes. First, it extends the T2I’s text inputs to incorporate interleaved image-text inputs, as illus- trated in Figure 3.15. Second, it finetunes the base T2I model, which has been trained using image generation loss, by the employing data, loss, and rewards that aim to align with human expectations.
与LLM开发中人类对齐调整的既定实践相似,我们预计本节中回顾的技术将合并为生成基础模型开发的整体第二阶段调整。这个对齐调优阶段有两个主要目的。首先,它扩展了T2I的文本输入,以合并交错的图像-文本输入,如图3.15所示。其次,它通过使用与人类期望对齐的数据、损失和奖励来微调基础T2I模型,该模型是通过图像生成损失进行训练的。
Unified image and text inputs统一的图像和文本输入:三种类型输入(内容文本输入+图像输入+指令文本输入),与之前模型相比,该模型可以通过不同文本指令完成空间控制、编辑、自定义等任务,实现不同模式的混合处理
We begin with the discussion on interface unification. Specifically, we aim to evolve the textual inputs of T2I models into a multimodal interface that seamlessly in- tegrates both image and text inputs. As shown in Figure 3.15, we consider three types of inputs to begin with: ”content text input” characterizes the visual scene to be produced; the ”image input” ac- commodates dense 2D inputs such as images and dense conditions; and the ”instruction text input” explains how the input content texts and images should be collectively composed as the condition for generation.
Vanilla T2I models, as shown in the first row of Figure 3.15, take the “content text input” of the image description and generate the corresponding image. For the spatial controllable generation in Section 3.2, the extra spatial condition can be specified via text inputs by expanding text words with extra box tokens, or via image input by feeding the dense spatial conditions as an image input. For the text-based editing in Section 3.3, we examine the efficacy of text instruction editing, a task that finetunes the T2I model to comprehend editing instruction texts that manipulate the image input, altering its pixel values accordingly. For visual concept customization in Section 3.5, the training-free models can now understand customization instructions to extract visual concepts from the image inputs, and combine the concept with context text inputs for image generation.
Incorporating the three elements of the input interface, the envisioned alignment-tuned T2I model can handle all previous tasks described in Section 3.2-3.5. Its behavior is steered by specific text instructions that dictate how the image and text inputs should be jointly processed as the genera- tion condition. Given the same image input, different text instructions can invoke different tasks: “generate a cat image with the same layout” for spatial control, “change the dog’s color” for editing, “generate the same dog sleeping” for concept customization, and the arbitrary mixture of the exist- ing modes. Achieving such a unified interface in generative foundational models may be possible through training on a consolidated dataset encompassing data from various tasks, drawing similar- ities to the success of supervised instruction tuning observed in LLMs. Furthermore, transitioning from processing a single image-text pair to handling interleaved image-text pairs could enable more intriguing capabilities like in-context visual demonstrations (Sun et al., 2023b). Another interest- ing direction is to build a generative model that is capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities, as demonstrated in Composable Diffusion (CoDi) (Tang et al., 2023b).
我们从接口统一开始讨论。具体来说,我们的目标是将T2I模型的文本输入发展成一个多模态接口,无缝集成图像和文本输入。如图3.15所示,我们首先考虑三种类型的输入:“内容文本输入”描述要生成的视觉场景;“图像输入”容纳密集的二维输入,如图像和密集条件;“指令文本输入”解释了输入内容文本和图像应如何共同组成,作为生成的条件。
如图3.15的第一行所示,普通的T2I模型接受图像描述的“内容文本输入”并生成相应的图像。对于第3.2节中的空间可控生成,可以通过文本输入来指定额外的空间条件,方法是通过扩展文本词汇以包含额外的框token,或通过图像输入,将密集的空间条件作为图像输入进行馈送。对于第3.3节中的基于文本的编辑,我们研究了文本指令编辑的有效性,这是一项任务,通过微调T2I模型来理解编辑指令文本,从而操纵图像输入,相应地改变其像素值。对于第3.5节中的视觉概念定制,无需训练的模型现在可以理解定制指令,从图像输入中提取视觉概念,并将该概念与上下文文本输入结合起来进行图像生成。
通过结合输入接口的这三个元素,所设想中的经过对齐调整的T2I模型可以处理第3.2-3.5节中描述的所有先前任务。其行为由特定的文本指令引导,这些指令指示图像和文本输入应如何联合处理作为生成条件。在相同的图像输入情况下,不同的文本指令可以调用不同的任务:
对于空间控制,“生成具有相同布局的猫图像”;
对于编辑,“更改狗的颜色”;
对于概念定制,“生成相同的睡狗”;以及现有模式的任意混合。通过在综合任务数据集上进行训练,可以实现在生成基础模型中实现这样的统一接口,从而类似于在LLM中观察到的监督指令调优的成功。此外,从处理单个图像-文本对到处理交错的图像-文本对的过渡可以实现更有趣的功能,如上下文视觉演示(Sun等人,2023b)。另一个有趣的方向是构建一个能够从任何组合的输入模态生成任何组合的输出模态的生成模型,例如语言、图像、视频或音频,如Composable Diffusion可组合扩散(CoDi)(Tang等人,2023b)所示。
Tuning with alignment-focused loss and rewards以对齐为焦点的损失和奖励的调整:
In addition to the unified input interface, an- other noteworthy element deserving consideration is the alignment-focused loss and rewards. As mentioned in Section 3.4, the image generation loss based on image-text pairs enables models to produce images that match the target data distribution. Yet, it doesn’t always perfectly align with human intent. This is reminiscent of the language model loss in LLM training, which necessitates a separate alignment tuning phase (Ouyang et al., 2022). The recent success in supervised instruction tuning and reinforcement learning from human feedback methods (Black et al., 2023) on image gen- eration provides effective tools for similar alignment tuning in generative foundation models. An intriguing topic left for future exploration is how to balance the different target losses and rewards, such as jointly optimizing for higher aesthetic scores, better image-text alignment, fewer harmful contents, stronger instruction adherence, along with many other desired properties.
除了统一的输入接口之外,值得考虑的另一个值得注意的元素是以对齐为重点的损失和奖励。如第3.4节所述,基于图像-文本对的图像生成损失使模型能够生成与目标数据分布匹配的图像。然而,它并不总是完全与人类意图对齐。这让人想起了LLM训练中的语言模型损失,这需要一个单独的对齐调整阶段(Ouyang等人,2022)。最近在图像生成方面,人类反馈方法(Black et al., 2023)在监督指令调优和强化学习方面的成功为生成基础模型中的类似对齐调整提供了有效的工具。未来探索的一个有趣的话题是如何平衡不同的目标损失和回报,例如联合优化更高的美学分数、更好的图像-文本对齐、更少的有害内容、更强的指令遵循,以及许多其他期望的属性。
Closed-loop of multimodal content understanding and generation多模态内容理解和生成的闭环
As we look ahead, one promising avenue of research is the closed-loop integration of multimodal content understanding and generation. Preliminary studies have shown the benefit of using synthesized data to benefit gen- eration from understanding (Li et al., 2023a; He et al., 2022b), and vice versa. An exciting prospect would be the development of an image-text-input, image-text-output foundational model for both understanding and generation tasks. The ideal balance in combining these two dimensions, and the most efficient approach to achieve it, are left for future explorations.
展望未来,一个有前途的研究方向是多模态内容理解和生成的闭环集成。初步研究已经显示,使用合成数据有利于从理解中生成(Li et al., 2023a;他等人,2022b),反之亦然。一个令人兴奋的前景是为理解和生成任务开发图像-文本输入、图像-文本输出基础模型。如何平衡这两个维度的理想平衡,以及实现这一平衡的最有效方法,留待未来探讨。
-
相关阅读:
Technology strategy Pattern 学习笔记1-Context: Architecture and Strategy
Hikvison对接iSecure Center时获取Appkey和Secert、不显示API网关、预览时提示网络请求失败
base64转为blob,然后转成file文件,具体步骤以及注释说明,以及使用案例
公司新来的阿里P7大咖,只用十分钟就教会了我实现高层次的复用
2023年tiktok入门运营技巧看这里!
录制完成的长视频如何快速分割为3个相同的视频片段
在Android项目中使用SpringBoot框架
HarmonyOS非线性容器特性及使用场景
C/C++统计满足条件的4位数个数 2023年5月电子学会青少年软件编程(C/C++)等级考试一级真题答案解析
持续集成与部署之CI/CD简介
- 原文地址:https://blog.csdn.net/qq_41185868/article/details/133594554