-
《机器学习实战》学习记录-ch2
PS: 个人笔记,抄书系列,建议不看
原书资料:https://github.com/ageron/handson-ml22.1数据获取
import pandas as pd data = pd.read_csv(r"C:\Users\cyan\Desktop\AI\ML\handson-ml2\datasets\housing\housing.csv")- 1
- 2
data.head() data.info()- 1
- 2
RangeIndex: 20640 entries, 0 to 20639 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 longitude 20640 non-null float64 1 latitude 20640 non-null float64 2 housing_median_age 20640 non-null float64 3 total_rooms 20640 non-null float64 4 total_bedrooms 20433 non-null float64 5 population 20640 non-null float64 6 households 20640 non-null float64 7 median_income 20640 non-null float64 8 median_house_value 20640 non-null float64 9 ocean_proximity 20640 non-null object dtypes: float64(9), object(1) memory usage: 1.6+ MB - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
data.columns- 1
Index(['longitude', 'latitude', 'housing_median_age', 'total_rooms', 'total_bedrooms', 'population', 'households', 'median_income', 'median_house_value', 'ocean_proximity'], dtype='object')- 1
- 2
- 3
- 4
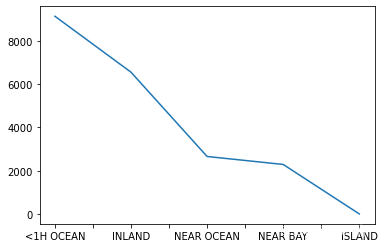
data['ocean_proximity'].value_counts().plot()- 1
data.describe()- 1
longitude latitude housing_median_age total_rooms total_bedrooms population households median_income median_house_value count 20640.000000 20640.000000 20640.000000 20640.000000 20433.000000 20640.000000 20640.000000 20640.000000 20640.000000 mean -119.569704 35.631861 28.639486 2635.763081 537.870553 1425.476744 499.539680 3.870671 206855.816909 std 2.003532 2.135952 12.585558 2181.615252 421.385070 1132.462122 382.329753 1.899822 115395.615874 min -124.350000 32.540000 1.000000 2.000000 1.000000 3.000000 1.000000 0.499900 14999.000000 25% -121.800000 33.930000 18.000000 1447.750000 296.000000 787.000000 280.000000 2.563400 119600.000000 50% -118.490000 34.260000 29.000000 2127.000000 435.000000 1166.000000 409.000000 3.534800 179700.000000 75% -118.010000 37.710000 37.000000 3148.000000 647.000000 1725.000000 605.000000 4.743250 264725.000000 max -114.310000 41.950000 52.000000 39320.000000 6445.000000 35682.000000 6082.000000 15.000100 500001.000000 import matplotlib.pyplot as plt- 1
%matplotlib inline # 这是IPython的内置绘图命令,PyCharm用不了,可以省略plt.show() #data.hist(bins=100,figsize=(20,15),column = 'longitude') # 选一列 # 绘制直方图 data.hist(bins=50,figsize=(20,15)) # bins 代表柱子的数目,高度为覆盖宽度内取值数目之和 # plt.show()- 1
- 2
- 3
- 4
- 5
- 6

# 划分数据集与测试集 import numpy as np # 自定义划分函数 def split_train_test(data, test_ratio): shuffled_indices = np.random.permutation(len(data)) # 将 0 ~ len(data) 随机打乱 test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data.iloc[train_indices], data.iloc[test_indices]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
train_data,test_data = my_split_train_test(data,.2) len(train_data),len(test_data)- 1
- 2
(16512, 4128)
from sklearn.model_selection import train_test_split # 利用 sklean的包 切分数据集,random_state 类似 np.random.seed(42), 保证了每次运行切分出的测试集相同 train_set, test_set = train_test_split(data, test_size=0.2, random_state=42) len(train_set),len(test_set)- 1
- 2
- 3
- 4
(16512, 4128)- 1
# 但是仅仅随机抽取作为测试集是不合理的,要保证测试集的数据分布跟样本一致 # 创建收入类别属性,为了服从房价中位数的分布对数据进行划分 data["income_cat"] = pd.cut(data["median_income"], bins=[0., 1.5, 3.0, 4.5, 6., np.inf], labels=[1, 2, 3, 4, 5])- 1
- 2
- 3
- 4
- 5
# 分层抽样 from sklearn.model_selection import StratifiedShuffleSplit split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) # for train_index, test_index in split.split(data, data["income_cat"]): strat_train_set = data.loc[train_index] strat_test_set = data.loc[test_index]- 1
- 2
- 3
- 4
- 5
- 6
# 查看测试集数据分布比例 strat_test_set["income_cat"].value_counts() / len(strat_test_set),data["income_cat"].value_counts() / len(data)- 1
- 2
(3 0.350533 2 0.318798 4 0.176357 5 0.114341 1 0.039971 Name: income_cat, dtype: float64, 3 0.350581 2 0.318847 4 0.176308 5 0.114438 1 0.039826 Name: income_cat, dtype: float64)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
# 删除添加的 income_cat 属性 strat_test_set.drop("income_cat",axis=1,inplace=True) strat_train_set.drop("income_cat",axis=1,inplace=True) # 或者如此删除,可能效率更高,或者更美观吧 for set_ in (strat_train_set, strat_test_set): set_.drop("income_cat", axis=1, inplace=True)- 1
- 2
- 3
- 4
- 5
- 6
2.2 数据探索与可视化
2.2.1 绘制散点图
housing = strat_train_set.copy() # 对训练集进行备份- 1
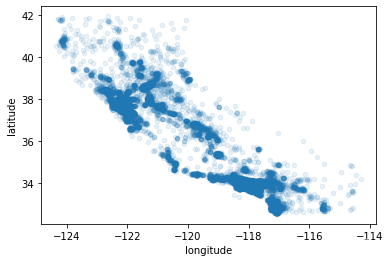
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1) # 绘制经纬度散点图 # alpha 设置透明度,可以凸显高密度区域- 1
- 2
DataFrame.plot() 函数参数
DataFrame.plot(x=None, y=None, kind=‘line’, ax=None, subplots=False,
sharex=None, sharey=False, layout=None,figsize=None,
use_index=True, title=None, grid=None, legend=True,
style=None, logx=False, logy=False, loglog=False,
xticks=None, yticks=None, xlim=None, ylim=None, rot=None,
xerr=None,secondary_y=False, sort_columns=False, **kwds)参数详解
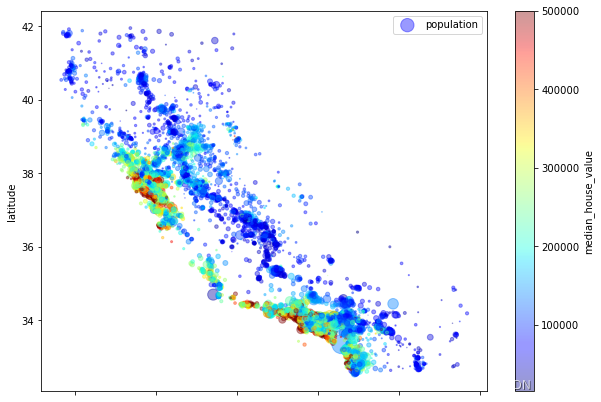
DataFrame.plot()#现在,再来看看房价。每个圆的半径大小代表了每个区域的人口数量(选项s),颜色代表价格(选项c)。 #我们使用一个名叫jet的预定义颜色表(选项cmap)来进行可视化,颜色范围从蓝(低)到红(高) housing.plot(kind="scatter", x="longitude", y="latitude", alpha=.4, s=housing["population"]/100, label="population", figsize=(10,7), c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True, ) plt.legend() # s=housing["population"]/100 意思是每个点的size由其决定 # c="median_house_value" 意思是每个点的color由由其决定 # cmap="jet" 意思是颜色风格采用这个系列,也可以用‘viridis’等 # colorbar 意思是显示颜色条- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.2.2 寻找每对属性之间两两相关性(pearson相关系数)
corr_matrix = housing.corr() corr_matrix # 必然是对称阵- 1
- 2
longitude latitude housing_median_age total_rooms total_bedrooms population households median_income median_house_value longitude 1.000000 -0.924478 -0.105823 0.048909 0.076686 0.108071 0.063146 -0.019615 -0.047466 latitude -0.924478 1.000000 0.005737 -0.039245 -0.072550 -0.115290 -0.077765 -0.075146 -0.142673 housing_median_age -0.105823 0.005737 1.000000 -0.364535 -0.325101 -0.298737 -0.306473 -0.111315 0.114146 total_rooms 0.048909 -0.039245 -0.364535 1.000000 0.929391 0.855103 0.918396 0.200133 0.135140 total_bedrooms 0.076686 -0.072550 -0.325101 0.929391 1.000000 0.876324 0.980167 -0.009643 0.047781 population 0.108071 -0.115290 -0.298737 0.855103 0.876324 1.000000 0.904639 0.002421 -0.026882 households 0.063146 -0.077765 -0.306473 0.918396 0.980167 0.904639 1.000000 0.010869 0.064590 median_income -0.019615 -0.075146 -0.111315 0.200133 -0.009643 0.002421 0.010869 1.000000 0.687151 median_house_value -0.047466 -0.142673 0.114146 0.135140 0.047781 -0.026882 0.064590 0.687151 1.000000 # 把相关系数矩阵中 median_house_value 的那列拎出来 corr_matrix["median_house_value"]- 1
- 2
longitude -0.047466 latitude -0.142673 housing_median_age 0.114146 total_rooms 0.135140 total_bedrooms 0.047781 population -0.026882 households 0.064590 median_income 0.687151 median_house_value 1.000000 Name: median_house_value, dtype: float64- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
相关系数的范围从-1变化到1。越接近1,表示有越强的正相关。例如,当收入中位数上升时,房价中位数也趋于上升。当系数接近于-1时,表示有较强的负相关。我们可以看到纬度和房价中位数之间呈现出轻微的负相关(也就是说,越往北走,房价倾向于下降)。最后,系数靠近0则说明二者之间没有线性相关性(不代表没有其他相关性,可能有非线性相关性)。
2.2.3 利用pandas内置的散点图矩阵函数进行描述性统计
还有一种方法可以检测属性之间的相关性,就是使用pandas的scatter_matrix函数,它会绘制出每个数值属性相对于其他数值属性的相关性。现在我们有11个数值属性,可以得到11^2=121个图像,篇幅原因无法完全展示,这里我们仅关注那些与房价中位数属性最相关的,可算作是最有潜力的属性
from pandas.plotting import scatter_matrix attributes = ["median_house_value", "median_income", "total_rooms", "housing_median_age"] scatter_matrix(housing[attributes], figsize=(12, 8)) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
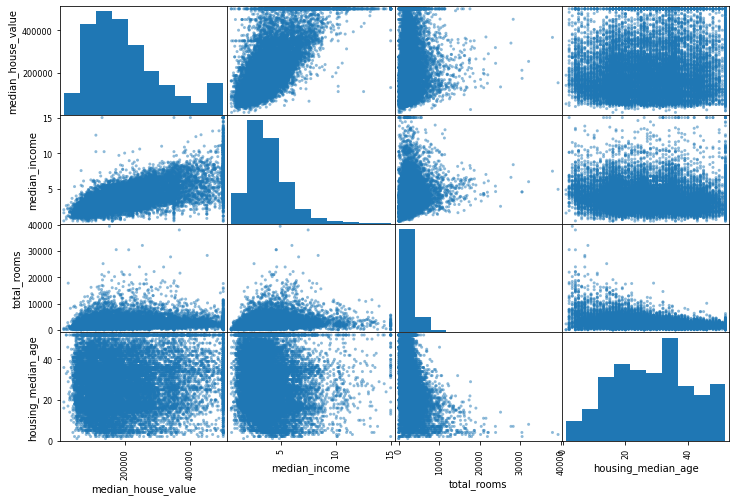
如果pandas绘制每个变量对自身的图像,那么主对角线(从左上到右下)将全都是直线,这样毫无意义。所以取而代之的方法是,pandas在这几个图中显示了每个属性的直方图(还有其他选项可选,详情请参考pandas文档)。
从图中可以粗略看出相关性,比如(1,0)号图# 挑出最有潜力能够预测房价中位数的属性——收入中位数 housing.plot(kind="scatter", x="median_income", y="median_house_value", alpha=0.1)- 1
- 2
- 3
图说明了几个问题。首先,二者的相关性确实很强,你可以清楚地看到上升的趋势,并且点也不是太分散。其次,前面我们提到过50万美元的价格上限在图中是一条清晰的水平线,不过除此之外,图还显示出几条不那么明显的直线:45万美元附近有一条水平线,35万美元附近也有一条,28万美元附近似乎隐约也有一条,再往下可能还有一些。为了避免你的算法学习之后重现这些怪异数据,你可能会尝试删除这些相应区域。
在准备给机器学习算法输入数据之前,你要做的最后一件事应该是尝试各种属性的组合。例如,如果你不知道一个区域有多少个家庭,那么知道一个区域的“房间总数”也没什么用。你真正想要知道的是一个家庭的房间数量。同样,单看“卧室总数”这个属性本身也没什么意义,你可能想拿它和“房间总数”来对比,或者拿来同“每个家庭的人口数”这个属性组合似乎也挺有意思。我们来试着创建这些新属性:
# 说白了就是组合一下属性,看看新得到的属性的相关性 housing["rooms_per_household"] = housing["total_rooms"]/housing["households"] housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"] housing["population_per_household"]=housing["population"]/housing["households"]- 1
- 2
- 3
- 4
# 重新看一下 corr_matrix = housing.corr() corr_matrix["median_house_value"].sort_values(ascending=False) # 很显然 'bedrooms_per_room' 要比单纯的'population' 和 'households'相关性要高- 1
- 2
- 3
- 4
median_house_value 1.000000 median_income 0.687151 rooms_per_household 0.146255 total_rooms 0.135140 housing_median_age 0.114146 households 0.064590 total_bedrooms 0.047781 population_per_household -0.021991 population -0.026882 longitude -0.047466 latitude -0.142673 bedrooms_per_room -0.259952 Name: median_house_value, dtype: float64- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.3 机器学习算法的数据准备
# 数据备份 housing = strat_train_set.drop("median_house_value", axis=1) housing_labels = strat_train_set["median_house_value"].copy()- 1
- 2
- 3
2.3.1 数据清理
大部分的机器学习算法无法在缺失的特征上工作,所以我们要创建一些函数来辅助它。前面我们已经注意到total_bedrooms属性有部分值缺失,所以我们要解决它。有以下三种选择:1.放弃这些相应的区域。2.放弃整个属性。3.将缺失的值设置为某个值(0、平均数或者中位数等)。
(1)手撸代码
housing.dropna(subset=['total_bedrooms']) # 1.删除'total_bedrooms'属性缺失的行 housing.drop('total_bedrooms',axis=1) # 2. 直接删除该列 median = housing['total_bedrooms'].median housing['total_bedrooms'].fillna(median,inplace=True) # 3. 中位数填充- 1
- 2
- 3
- 4
(2)使用Scikit-Learn 中的 SimpleImputer
housing['ocean_proximity'].head() # 查看 ocean_proximity 属性列,其类型为文本- 1
- 2
12655 INLAND 15502 NEAR OCEAN 2908 INLAND 14053 NEAR OCEAN 20496 <1H OCEAN Name: ocean_proximity, dtype: object- 1
- 2
- 3
- 4
- 5
- 6
from sklearn.impute import SimpleImputer housing_num = housing.drop('ocean_proximity',axis=1) # 不要文本列 imputer = SimpleImputer(strategy="median") # 估算策略为中位数 imputer.fit(housing_num) # 将 imputer 适配到 housing_num上 imputer.statistics_ # 这个内置对象保存了每列的中位数- 1
- 2
- 3
- 4
- 5
array([-118.51 , 34.26 , 29. , 2119. , 433. , 1164. , 408. , 3.54155])- 1
- 2
X = imputer.transform(housing_num) # 填充缺失值, X是一个NumPy数组 X[:5] # fit, transform 可以合成一个效率更高的函数 # X = imputer.fit_transform(housing_num)- 1
- 2
- 3
- 4
array([[-1.2146e+02, 3.8520e+01, 2.9000e+01, 3.8730e+03, 7.9700e+02, 2.2370e+03, 7.0600e+02, 2.1736e+00], [-1.1723e+02, 3.3090e+01, 7.0000e+00, 5.3200e+03, 8.5500e+02, 2.0150e+03, 7.6800e+02, 6.3373e+00], [-1.1904e+02, 3.5370e+01, 4.4000e+01, 1.6180e+03, 3.1000e+02, 6.6700e+02, 3.0000e+02, 2.8750e+00], [-1.1713e+02, 3.2750e+01, 2.4000e+01, 1.8770e+03, 5.1900e+02, 8.9800e+02, 4.8300e+02, 2.2264e+00], [-1.1870e+02, 3.4280e+01, 2.7000e+01, 3.5360e+03, 6.4600e+02, 1.8370e+03, 5.8000e+02, 4.4964e+00]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# 转换回 DataFrame housing_tr = pd.DataFrame(X,columns=housing_num.columns,index=housing_num.index) housing_tr.head()- 1
- 2
- 3
longitude latitude housing_median_age total_rooms total_bedrooms population households median_income 12655 -121.46 38.52 29.0 3873.0 797.0 2237.0 706.0 2.1736 15502 -117.23 33.09 7.0 5320.0 855.0 2015.0 768.0 6.3373 2908 -119.04 35.37 44.0 1618.0 310.0 667.0 300.0 2.8750 14053 -117.13 32.75 24.0 1877.0 519.0 898.0 483.0 2.2264 20496 -118.70 34.28 27.0 3536.0 646.0 1837.0 580.0 4.4964 2.3.2 处理文本和分类属性
在此数据集中,只有一个:ocean_proximity属性。我们看看前10个实例的值:- 1
housing_cat = housing['ocean_proximity'] housing_cat.head(10)- 1
- 2
12655 INLAND 15502 NEAR OCEAN 2908 INLAND 14053 NEAR OCEAN 20496 <1H OCEAN 1481 NEAR BAY 18125 <1H OCEAN 5830 <1H OCEAN 17989 <1H OCEAN 4861 <1H OCEAN Name: ocean_proximity, dtype: object- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(1)OrdinalEncoder 有序编码器
ocean_proximity不是任意文本,而是有限个可能的取值,每个值代表一个类别。因此,此属性是分类属性。大多数机器学习算法更喜欢使用数字,因此让我们将这些类别从文本转到数字。为此,我们可以使用Scikit-Learn的OrdinalEncoder类:
from sklearn.preprocessing import OrdinalEncoder ordinal_encoder = OrdinalEncoder() # 有序编码器 housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat) housing_cat_encoded[:10] # 第三行报错:ValueError: Expected 2D array, got 1D array instead: # 注意:fit_transform() 函数必须传递二维数组 # 这里涉及到 Dataframe的[] ,[[]], 单中括号提取的是Series不存在列的概念, 双则是df对象- 1
- 2
- 3
- 4
- 5
- 6
- 7
s = pd.Series([1,2,3]) s.shape # out: (3,) d = pd.DataFrame(s) d.shape # out: (3,1)- 1
- 2
- 3
- 4
- 5
- 6
housing_cat = housing[['ocean_proximity']] ordinal_encoder = OrdinalEncoder() # 有序编码器 housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat) housing_cat_encoded[:10]- 1
- 2
- 3
- 4
array([[1.], [4.], [1.], [4.], [0.], [3.], [0.], [0.], [0.], [0.]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# 查看所有类别 ordinal_encoder.categories_- 1
- 2
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'], dtype=object)]- 1
- 2
(2)OneHotEncoder 独热编码器
这种表征方式产生的一个问题是,机器学习算法会认为两个相近的值比两个离得较远的值更为相似一些。在某些情况下这是对的(对一些有序类别,像“坏”“平均”“好”“优秀”),但是,对ocean_proximity而言情况并非如此(例如,类别0和类别4之间就比类别0和类别1之间的相似度更高)。为了解决这个问题,常见的解决方案是给每个类别创建一个二进制的属性:当类别是“<1H OCEAN”时,一个属性为1(其他为0),当类别是“INLAND”时,另一个属性为1(其他为0),以此类推。这就是独热编码,因为只有一个属性为1(热),其他均为0(冷)。新的属性有时候称为哑(dummy)属性。Scikit-Learn提供了一个OneHotEncoder编码器,可以将整数类别值转换为独热向量。我们用它来将类别编码为独热向量。
from sklearn.preprocessing import OneHotEncoder cat_encoder = OneHotEncoder() housing_cat_1hot = cat_encoder.fit_transform(housing_cat) housing_cat_1hot- 1
- 2
- 3
- 4
<16512x5 sparse matrix of type '' with 16512 stored elements in Compressed Sparse Row format> - 1
- 2
注意到这里的输出是一个SciPy稀疏矩阵,而不是一个NumPy数组。当你有成千上万个类别属性时,这个函数会非常有用。因为在独热编码完成之后,我们会得到一个几千列的矩阵,并且全是0,每行仅有一个1。占用大量内存来存储0是一件非常浪费的事情,因此稀疏矩阵选择仅存储非零元素的位置。而你依旧可以像使用一个普通的二维数组那样来使用它,当然如果你实在想把它转换成一个(密集的)NumPy数组,只需要调用toarray()方法即可:
housing_cat_1hot.toarray()- 1
array([[0., 1., 0., 0., 0.], [0., 0., 0., 0., 1.], [0., 1., 0., 0., 0.], ..., [1., 0., 0., 0., 0.], [1., 0., 0., 0., 0.], [0., 1., 0., 0., 0.]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
cat_encoder.categories_- 1
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'], dtype=object)]- 1
- 2
2.3.3 特征缩放
- 归一化: x ’ = x − m i n m a x − m i n x^{’} = \frac{x - min}{max - min} x’=max−minx−min
- 标准化(Z-score):
x
′
=
x
−
均值
σ
x^{'} = \frac{x - 均值}{\sigma}
x′=σx−均值
标准化对异常值不敏感,归一化特别敏感。Scikit-Learn提供了一个标准化的转换器StandadScaler。正如你所见,许多数据转换的步骤需要以正确的顺序来执行。而Scikit-Learn正好提供了Pipeline类来支持这样的转换。下面是一个数值属性的流水线示例:
2.3.4 转换流水线
from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler # 创建一个管道流水线,最后一个元组必须是估算器(带fit()方法), # 前面必须是转换器,也就是带fit_transform()方法的对象 num_pipeline = Pipeline([ ('imputer', SimpleImputer(strategy="median")), ('std_scaler', StandardScaler()), ]) housing_num_tr = num_pipeline.fit_transform(housing_num) housing_num_tr # 整个流程是先填充缺失值,然后标准化数据,不包括文本列- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
array([[-0.94135046, 1.34743822, 0.02756357, ..., 0.73260236, 0.55628602, -0.8936472 ], [ 1.17178212, -1.19243966, -1.72201763, ..., 0.53361152, 0.72131799, 1.292168 ], [ 0.26758118, -0.1259716 , 1.22045984, ..., -0.67467519, -0.52440722, -0.52543365], ..., [-1.5707942 , 1.31001828, 1.53856552, ..., -0.86201341, -0.86511838, -0.36547546], [-1.56080303, 1.2492109 , -1.1653327 , ..., -0.18974707, 0.01061579, 0.16826095], [-1.28105026, 2.02567448, -0.13148926, ..., -0.71232211, -0.79857323, -0.390569 ]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
当调用流水线的fit()方法时,会在所有转换器上按照顺序依次调用fit_transform(),将一个调用的输出作为参数传递给下一个调用方法,直到传递到最终的估算器,则只会调用fit()方法。所以最后还要调用一次管道的转换方法。
ColumnTransformer
同时对数值类型和类别类型转换
from sklearn.compose import ColumnTransformer num_attribs = list(housing_num) cat_attribs = ["ocean_proximity"] # 每个元组的三个参数分别代表:处理的名字,转换器,转换器可作用的列名的列表 full_pipeline = ColumnTransformer([ ("num", num_pipeline, num_attribs), ("cat", OneHotEncoder(), cat_attribs), ]) # 调用转换器, 返回结果根据密度阈值判定返回的矩阵类型,可通过toarray等转换 housing_prepared = full_pipeline.fit_transform(housing) # 这里返回的是array pd.DataFrame(housing_prepared).head() # 8,9,10,11,12是 onehot编码值- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
0 1 2 3 4 5 6 7 8 9 10 11 12 0 -0.941350 1.347438 0.027564 0.584777 0.640371 0.732602 0.556286 -0.893647 0.0 1.0 0.0 0.0 0.0 1 1.171782 -1.192440 -1.722018 1.261467 0.781561 0.533612 0.721318 1.292168 0.0 0.0 0.0 0.0 1.0 2 0.267581 -0.125972 1.220460 -0.469773 -0.545138 -0.674675 -0.524407 -0.525434 0.0 1.0 0.0 0.0 0.0 3 1.221738 -1.351474 -0.370069 -0.348652 -0.036367 -0.467617 -0.037297 -0.865929 0.0 0.0 0.0 0.0 1.0 4 0.437431 -0.635818 -0.131489 0.427179 0.272790 0.374060 0.220898 0.325752 1.0 0.0 0.0 0.0 0.0 2.4 选择和训练模型
# 数据备份 housing = strat_train_set.drop("median_house_value", axis=1) housing_labels = strat_train_set["median_house_value"].copy()- 1
- 2
- 3
2.4.1 LinearRegressin 线性回归
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(housing_prepared,housing_labels) # 第一个参数作为输入,第二个作为输出。进行拟合- 1
- 2
- 3
some_data = housing.iloc[:5] some_labels = housing_labels.iloc[:5] some_data_prepared = full_pipeline.transform(some_data) print("Predictions:",lin_reg.predict(some_data_prepared)) print("Lanels:",list(some_labels))- 1
- 2
- 3
- 4
- 5
Predictions: [ 88983.14806384 305351.35385026 153334.71183453 184302.55162102 246840.18988841] Lanels: [72100.0, 279600.0, 82700.0, 112500.0, 238300.0]- 1
- 2
- 3
# 均方根误差RMSE from sklearn.metrics import mean_squared_error housing_predictions = lin_reg.predict(housing_prepared) lin_mse = mean_squared_error(housing_labels, housing_predictions) lin_rmse = np.sqrt(lin_mse) lin_rmse- 1
- 2
- 3
- 4
- 5
- 6
69050.56219504567- 1
# 重新查看一下数据分布 strat_train_set.hist(bins=50,figsize=(10,5),column='median_house_value') plt.show()- 1
- 2
- 3
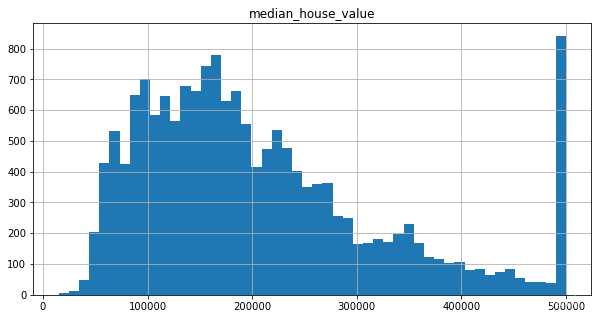
大多数区域的median_housing_values分布在120 000~265000美元之间,所以典型的预测误差达到68628美元只能算是差强人意。这就是一个典型的模型对训练数据欠拟合的案例。这种情况发生时,通常意味着这些特征可能无法提供足够的信息来做出更好的预测,或者是模型本身不够强大。我们这个模型不是一个正则化的模型,所以就排除了最后那个选项。
2.4.2 DecisionTreeRegressor 决策树回归
from sklearn.tree import DecisionTreeRegressor tree_reg = DecisionTreeRegressor() tree_reg.fit(housing_prepared, housing_labels)- 1
- 2
- 3
- 4
DecisionTreeRegressor()- 1
# 重新计算准确率 housing_predictions = tree_reg.predict(housing_prepared) tree_mse = mean_squared_error(housing_labels,housing_predictions) tree_rmse = np.sqrt(tree_mse) tree_rmse- 1
- 2
- 3
- 4
- 5
0.0- 1
等等,什么!完全没有错误?这个模型真的可以做到绝对完美吗?当然,更有可能的是这个模型对数据严重过拟合了。我们怎么确认呢?前面提到过,在你有信心启动模型之前,都不要触碰测试集,所以这里,你需要拿训练集中的一部分用于训练,另一部分用于模型验证。
2.4.3 k-折交叉验证
一个不错的选择是使用Scikit-Learn的K-折交叉验证功能。以下是执行K-折交叉验证的代码:它将训练集随机分割成10个不同的子集,每个子集称为一个折叠,然后对决策树模型进行10次训练和评估——每次挑选1个折叠进行评估,使用另外的9个折叠进行训练。产生的结果是一个包含10次评估分数的数组:
from sklearn.model_selection import cross_val_score scores = cross_val_score(tree_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10) tree_rmse_scores = np.sqrt(-scores)- 1
- 2
- 3
- 4
Scikit-Learn的交叉验证功能更倾向于使用效用函数(越大越好)而不是成本函数(越小越好),所以计算分数的函数实际上是负的MSE(一个负值)函数,这就是为什么上面的代码在计算平方根之前会先计算出-scores。让我们看看结果:
def display_scores(scores): print("Scores:", scores) print("Mean:", scores.mean()) print("Standard deviation:", scores.std()) display_scores(tree_rmse_scores)- 1
- 2
- 3
- 4
- 5
Scores: [70083.4628457 67839.00949397 64383.21422305 69766.08416254 67506.92472305 68775.68142935 73182.42944981 69050.33596809 66241.2960529 72688.08699725] Mean: 68951.6525345718 Standard deviation: 2557.0938065802684- 1
- 2
- 3
- 4
- 5
效果好像不怎么样,再看看线性回归呢?也用交叉验证
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10) lin_rmse_scores = np.sqrt(-lin_scores) display_scores(lin_rmse_scores)- 1
- 2
- 3
- 4
Scores: [72229.03469752 65318.2240289 67706.39604745 69368.53738998 66767.61061621 73003.75273869 70522.24414582 69440.77896541 66930.32945876 70756.31946074] Mean: 69204.32275494763 Standard deviation: 2372.0707910559245- 1
- 2
- 3
- 4
- 5
俩模型半斤八两,决策树确实过拟合了。不用交叉验证之前,我们是对所有训练数据进行预测。用了之后我们是对训练数据的一部分即验证集进行预测。
2.4.4 RandomForestRegressor 随机森林回归
from sklearn.ensemble import RandomForestRegressor forest_reg = RandomForestRegressor() forest_reg.fit(housing_prepared, housing_labels) # 这句话就是在训练模型了 housing_predictions = forest_reg.predict(housing_prepared) forest_rmse = np.sqrt(mean_squared_error(housing_labels,housing_predictions)) forest_rmse- 1
- 2
- 3
- 4
- 5
- 6
18631.59917120775- 1
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10) forest_rmse_scores = np.sqrt(-forest_scores) display_scores(forest_rmse_scores)- 1
- 2
- 3
- 4
Scores: [50638.50863541 49399.32471253 45940.7831844 50418.32533903 47449.22724055 49197.8943328 51578.78457127 48648.30024491 47562.16332906 52949.88360578] Mean: 49378.31951957429 Standard deviation: 1991.7380392592863- 1
- 2
- 3
- 4
- 5
哇,这个就好多了:随机森林看起来很有戏。但是,请注意,训练集上的分数仍然远低于验证集,这意味着该模型仍然对训练集过拟合。过拟合的可能解决方案包括简化模型、约束模型(即使其正规化),或获得更多的训练数据。不过在深入探索随机森林之前,你应该先尝试一遍各种机器学习算法的其他模型(几种具有不同内核的支持向量机,比如神经网络模型等),但是记住,别花太多时间去调整超参数。我们的目的是筛选出几个(2~5个)有效的模型。
2.4.5 joblib 模块保存训练后的模型
import joblib joblib.dump(forest_reg, "housing_model_forest.pkl") # 这样在本地生成一个文件- 1
- 2
- 3
['housing_model_forest.pkl']- 1
# 加载该模型 # 再次运行时就不必训练了 model = joblib.load("housing_model_forest.pkl") # 直接进行预测 housing_predictions = model.predict(housing_prepared) forest_rmse = np.sqrt(mean_squared_error(housing_labels,housing_predictions)) forest_rmse- 1
- 2
- 3
- 4
- 5
- 6
- 7
18577.552776621567- 1
2.5 模型微调
假设你现在有了一个有效模型的候选列表。现在你需要对它们进行微调。我们来看几个可行的方法。
2.5.1 网格搜索
你所要做的只是告诉它你要进行实验的超参数是什么,以及需要尝试的值,它将会使用交叉验证来评估超参数值的所有可能组合
from sklearn.model_selection import GridSearchCV # Grid Search Cross Validation param_grid = [ {'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]}, {'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]}, ] forest_reg = RandomForestRegressor() grid_search = GridSearchCV(forest_reg, param_grid, cv=5, scoring='neg_mean_squared_error', return_train_score=True) # 将 forest_reg 和 CV 包起来 grid_search.fit(housing_prepared, housing_labels) # 拟合调参,开始训练- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
GridSearchCV(cv=5, estimator=RandomForestRegressor(), param_grid=[{'max_features': [2, 4, 6, 8], 'n_estimators': [3, 10, 30]}, {'bootstrap': [False], 'max_features': [2, 3, 4], 'n_estimators': [3, 10]}], return_train_score=True, scoring='neg_mean_squared_error')- 1
- 2
- 3
- 4
- 5
- 6
当你不知道超参数应该赋什么值时,一个简单的方法是尝试10的连续幂次方(如果你想要得到更细粒度的搜索,可以使用更小的数,参考这个示例中所示的n_estimators超参数)。这个param_grid告诉Scikit-Learn,首先评估第一个dict中的n_estimator和max_features的所有3×4=12种超参数值组合(先不要担心这些超参数现在意味着什么,我们将在第7章中进行解释);接着,尝试第二个dict中超参数值的所有2×3=6种组合,但这次超参数bootstrap需要设置为False而不是True(True是该超参数的默认值)。总而言之,网格搜索将探索RandomForestRegressor超参数值的12+6=18种组合,并对每个模型进行5次训练(因为我们使用的是5-折交叉验证)。换句话说,总共会完成18×5=90次训练!这可能需要相当长的时间,但是完成后你就可以获得最佳的参数组合:
# 最佳参数 grid_search.best_params_- 1
- 2
{'max_features': 6, 'n_estimators': 30}- 1
# 最佳模型 grid_search.best_estimator_ # forest_reg = RandomForestRegressor(max_features=6, n_estimators=30) # 重新训练即可,或者在初始化GridSearchCV时将 refit属性设置为True。- 1
- 2
- 3
- 4
RandomForestRegressor(max_features=6, n_estimators=30)- 1
# 查看各参数组合的CV得分 cvres = grid_search.cv_results_ for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]): print(np.sqrt(-mean_score), params)- 1
- 2
- 3
- 4
- 5
63921.21802334897 {'max_features': 2, 'n_estimators': 3} 55143.54967749173 {'max_features': 2, 'n_estimators': 10} 52502.04191392476 {'max_features': 2, 'n_estimators': 30} 59558.82925306709 {'max_features': 4, 'n_estimators': 3} 52723.110122583676 {'max_features': 4, 'n_estimators': 10} 50361.65312255114 {'max_features': 4, 'n_estimators': 30} 58341.62415261087 {'max_features': 6, 'n_estimators': 3} 52401.849175489806 {'max_features': 6, 'n_estimators': 10} 49907.16348917855 {'max_features': 6, 'n_estimators': 30} 58675.747821680394 {'max_features': 8, 'n_estimators': 3} 52150.642776898014 {'max_features': 8, 'n_estimators': 10} 50208.716163729216 {'max_features': 8, 'n_estimators': 30} 62938.60891692598 {'bootstrap': False, 'max_features': 2, 'n_estimators': 3} 54035.847075374615 {'bootstrap': False, 'max_features': 2, 'n_estimators': 10} 60506.668704813084 {'bootstrap': False, 'max_features': 3, 'n_estimators': 3} 52347.53629533465 {'bootstrap': False, 'max_features': 3, 'n_estimators': 10} 58021.07825355124 {'bootstrap': False, 'max_features': 4, 'n_estimators': 3} 51687.259207216666 {'bootstrap': False, 'max_features': 4, 'n_estimators': 10}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.5.2 随机搜索
如果探索的组合数量较少(例如上一个示例),那么网格搜索是一种不错的方法。但是当超参数的搜索范围较大时,通常会优先选择使用RandomizedSearchCV。这个类用起来与GridSearchCV类大致相同,但它不会尝试所有可能的组合,而是在每次迭代中为每个超参数选择一个随机值,然后对一定数量的随机组合进行评估。这种方法有两个显著好处:
- 如果运行随机搜索1000个迭代,那么将会探索每个超参数的1000个不同的值(而不是像网格搜索方法那样每个超参数仅探索少量几个值)。
- 通过简单地设置迭代次数,可以更好地控制要分配给超参数搜索的计算预算。
2.5.3 集成方法
还有一种微调系统的方法是将表现最优的模型组合起来。组合(或“集成”)方法通常比最佳的单一模型更好(就像随机森林比其所依赖的任何单个决策树模型更好一样),特别是当单一模型会产生不同类型误差时更是如此。我们将在第7章中更详细地介绍这个主题。
2.5.4 分析最佳模型及其误差
通过检查最佳模型,你总是可以得到一些好的洞见。例如在进行准确预测时,RandomForestRegressor可以指出每个属性的相对重要程度:
feature_importances = grid_search.best_estimator_.feature_importances_ feature_importances- 1
- 2
在旁边做标注:
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"] cat_encoder = full_pipeline.named_transformers_["cat"] # OneHotEncoder() 对象 cat_one_hot_attribs = list(cat_encoder.categories_[0]) attributes = num_attribs + extra_attribs + cat_one_hot_attribs sorted(zip(feature_importances, attributes), reverse=True)- 1
- 2
- 3
- 4
- 5
[(0.3055083587670521, 'median_income'), (0.16413914516937833, 'INLAND'), (0.10606381377040103, 'pop_per_hhold'), (0.0773574328493946, 'longitude'), (0.07483537888507266, 'bedrooms_per_room'), (0.07200904995622023, 'rooms_per_hhold'), (0.06785220186458425, 'latitude'), (0.04341695035478412, 'housing_median_age'), (0.01880442808398482, 'total_rooms'), (0.017543601583434865, 'population'), (0.016867980615110308, 'total_bedrooms'), (0.01590853507335186, 'households'), (0.011320299556462278, '<1H OCEAN'), (0.005632366461757674, 'NEAR OCEAN'), (0.002680486697949481, 'NEAR BAY'), (5.9970311061396994e-05, 'ISLAND')]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
有了这些信息,你可以尝试删除一些不太有用的特征(例如,本例中只有一个ocean_proximity是有用的,我们可以试着删除其他所有特征)。
2.5.5 通过测试集评估系统
final_model = grid_search.best_estimator_ # 调参得到最优模型 X_test = strat_test_set.drop("median_house_value", axis=1) # 待测数据 y_test = strat_test_set["median_house_value"].copy() # 测试集标签 X_test_prepared = full_pipeline.transform(X_test) # 这里不用 fit_transform(),已经在第一行fit过了 final_predictions = final_model.predict(X_test_prepared) final_mse = mean_squared_error(y_test, final_predictions) final_rmse = np.sqrt(final_mse) final_rmse- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
47910.881005627576- 1
在某些情况下,泛化误差的这种点估计将不足以说服你启动生产环境:如果它仅比当前生产环境中的模型好0.1%?你可能想知道这个估计的精确度。为此,你可以使用scipy.stats.t.interval()计算泛化误差的95%置信区间:
from scipy import stats confidence = 0.95 squared_errors = (final_predictions - y_test) ** 2 np.sqrt(stats.t.interval(confidence, len(squared_errors) - 1, loc=squared_errors.mean(), scale=stats.sem(squared_errors)))- 1
- 2
- 3
- 4
- 5
- 6
array([45933.06570715, 49810.22497654])- 1
如果之前进行过大量的超参数调整,这时的评估结果通常会略逊于你之前使用交叉验证时的表现结果(因为通过不断调整,系统在验证数据上终于表现良好,在未知数据集上可能达不到这么好的效果)。在本例中,结果虽然并非如此,但是当这种情况发生时,你一定不要继续调整超参数,不要试图再努力让测试集的结果变得好看一些,因为这些改进在泛化到新的数据集时又会变成无用功。现在进入项目预启动阶段:你将要展示你的解决方案(强调学习了什么,什么有用,什么没有用,基于什么假设,以及系统的限制有哪些),记录所有事情,通过清晰的可视化和易于记忆的陈述方式制作漂亮的演示文稿(例如,“收入中位数是预测房价的首要指标”)。在这个加州住房的示例里,系统的最终性能并不比专家估算的效果好,通常会下降20%左右,但这仍然是一个不错的选择,因为这为专家腾出了一些时间以便他们可以投入更有趣和更有生产力的任务上。
-
相关阅读:
不用入耳就有好音质,南卡OE Pro 0压开放式耳机
Feign Client端redis缓存设计与实现
网络安全(黑客)自学
Unity的碰撞检测(总结篇)
双线路捆绑
【开发指南】AR Foundation 开发环境部署
kubernetes(3)
(六)Vue之MVVC
多线程快速入门
CodeForces-1324F Maximum White Subtree(换根dp 联通子图信息查询)
- 原文地址:https://blog.csdn.net/qq_61832249/article/details/133563121
