-
【实验记录】一些小疑问
个人实验记录,只是为了记录思路和踩坑,网页方便多端同步,不要看,很多是错误的
1.为什么要选择基于“外观”这一特性来作为回环检测的方案?
朴素思路复杂度高,不利于实时性;基于“里程计”的方案需要知道相机处于何位置下才能发生检测,这与我们需要知道的准确位置相矛盾
基于“外观”的方案与前端和后端均无关,是一个独立的模块。
这也为其过程可以加入除去视觉、惯性第三者数据提供了条件。2.为什么不能直接用两张图像“相减”来计算相似度?
1.相机运动过程中受光照影响很大,即使两张同位置的图像,在不同光照下,其矩阵也就是计算机能读懂的信息相差也很大
2.相机在高速拍摄的过程中,同一位置相机视角肯定有微小变动,这对于计算机视觉来说影响是巨大的3.解释准确率/召回率的理解
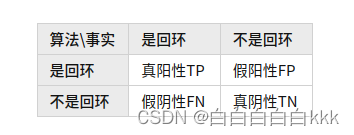
回环检测中更看重的是准确率,就是要将假阳性FP控制到最低!简而言之:漏判可以,错判不行在算法中通过阈值来体现我们的“容忍度”。当提高某个阈值,算法会变的更加“严苛”,很多位置很难被判定为回环帧,于是准确率肯定会有所上升,同时由于检测到回环变少,难免会将现实中是回环的位置漏掉,因此召回率有所下降。反之,当降低了某个阈值,算法会更加“宽容”,其中将一些“模棱两可”的位置判断为回环帧,这样难免准确率会下降,但是召回率会上升。
为了评价算法的好坏,我们会测试它在各种配置下的P和R值,然后做Precision-Recall曲线。当召回率为X轴,用准确率为Y轴时,我们会关心整条曲线偏向右上方的程度。通常,100%准确率下召回率或者50%召回率时的准确率,作为评价的指标。
不过请注意,除了一些“天壤之别”的算法,通常不能一概而论地说算法A就是优于算法B的。我们可能会说A在准确率较高时还有很好的召回率,而B在70%召回率的情况下还能保证较好的准确率,诸如此类。
4.TF-IDF是什么?
词频-逆向文本概率,根据权重来区分单词的。前者是在图片中存在的数量,后者是在字典中存在的数量
词频(TF):某个单词在一张图片中出现的概率很高,是这张图片中的丰富元素,说明该单词区分度高
例如:一张图片中有100辆轿车,则含有50辆以下的图片很明显不是与之相似,80辆以上的图片存在更多相似的可能性逆向文本概率(IDF):某个单词在一整本字典中出现次数很少,说明更“罕见、独特”。当这个单词在第一张图片和第十张图片中同时存在时,我们更可能觉得这两张图片更可能是相似的
补充:
字典有所有单词信息,将图片中描述子比对后,获得词袋模型Va中包含单词和权重
5.PR曲线中详细步骤解算
看到两篇不错的博客:
终于搞懂了PR曲线:https://zhuanlan.zhihu.com/p/404798546
从两个例子解析sklearn.metrics.precision_recall_curve:https://zhuanlan.zhihu.com/p/619388859
PR曲线视频讲解:
二分类PR曲线(1)PR曲线的绘制
在做Python练习的时候会发现,最左上方一个点总是(0,1)
第二篇博客中写到是阈值取了一个无穷(或者是1)这一原因造成的,这是由于precision_recall_curve函数会按阈值从大到小开始去重、排序,在从大到小排序后首先会取到无穷(或者是1)这一个阈值情况。
这样能够保证曲线是自左上角(0,1)开始绘制。
注意:在函数计算第一个无穷阈值下P和R的时候,遇见0/(0+0)这一情况,会默认p=1。下面是绘制PR曲线的Matlab代码,在function函数中我们可以看出什么样条件下具体会执行哪一步,再结合第一篇博客,自己对比一下确实是这样:
fact = load("fact/Fact.txt"); score = load("score/Score.txt"); [sorted_score, index] = sort(score, "descend"); threshold = sorted_score(1:100); P = zeros(length(threshold), 1); R = zeros(length(threshold), 1); for i = 1 : length(threshold) [P(i), R(i)] = PRCalculate(fact, score, threshold(i)); end plot(R, P, '-r'); xlabel('Recall'); ylabel('Precision'); legend('Random'); grid on; % 输入事实、分数和置信度阈值,返回准确率和召回率 function [P,R] = PRCalculate(Fact, Score, threshold) TP = 0; FP = 0; FN = 0; for i = 1 : length(Score) % 大于或等于阈值时,算法认为该回环为真 if Score(i) >= threshold if Fact(i) == 1 TP = TP + 1; else FP = FP + 1; end % 小于阈值时,算法认为该回环为假 elseif Score(i) < threshold && Fact(i) == 1 FN = FN + 1; end end P = TP / (TP + FP); R = TP / (TP + FN); end- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
下面还有Python的代码,不过Python代码是调用封装好的函数,可能看起来没有那么直观:
from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np score = np.array([0.9, 0.8, 0.7, 0.6, 0.3, 0.2, 0.1]) label = np.array([0, 1, 1, 1, 0, 0, 0]) precision, recall, thres = precision_recall_curve(label, score) re_thres = np.sort(thres)[::-1] print(re_thres) plt.plot(recall, precision,label="PR_Curve") plt.plot((0,1.0),(0.9,0.6),label="thresholds") plt.xlabel('Recall') plt.ylabel('Precision') plt.legend() plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
总结:
1.Matlab函数中function是自己定义的,更加直观的看到TP、FP、FN每一次for循环调整阈值时的变化2.Python是调用专门来绘制PR曲线的函数接口,对于阈值这个点,函数是用score这个数据从大到小来排序
以上面的代码为例:我打印输出了re_thres = [0.9 0.8 0.7 0.6]
首先声明一点,score大于threshold的部分被算法认为真,小于threshold的部分被算法认为假
##伪代码 if(score>=thres) #算法认为真 if(label[i]= 1) #label=1 or 0是现实真或者假 TP=TP+1 if(label[i]= 0) FP=FP+1 else if(score<thres) #算法认为假 if(label[i]=1) FN=FN+1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6.记录如何绘制Oxford New College和City Center数据集的PR曲线
由5可以看出,无论是Matlab还是Python绘制PR曲线都需要数据,这包括,:
- 现实标准(Fact):简单来说就是判断这一对匹配帧是不是回环帧,是赋值为1,不是赋值为0
- 得分(Score):通过词袋模型来给相似帧打分,这个分数越高说明两帧越相似
- 阈值(Threshold):通过阈值调节来画出连续的PR曲线
数据集:https://www.robots.ox.ac.uk/~mobile/IJRR_2008_Dataset/data.html
由于city center数据集中回环场景更简洁,所以用cc为例:
里面包含了2474张图片,这些图片是双目的,然后下载GroundTruth这个真值标注文件
因为图片是成对保存,所以需要将图片按照left、right分开
(https://github.com/introlab/rtabmap/wiki/Benchmark#commands-for-all-datasets这里作者是将两张图片合并,我觉得也行)回到刚才的真值文件,用Matlab查看发现正如官网介绍所说:
Entry (i,j) of the mask matrix is 0 if image i and image j were taken at the different places.
When entry (i,j) of the mask matrix is 1, image i and image j are accepted as a potential true positive, subject to visual inspection.
翻译:
如果图像i和图像j在不同位置拍摄,则矩阵的条目 ( i , j ) 为 0。
当矩阵的条目 ( i , j ) 为 1 时,图像i和图像j被接受为潜在的真阳性,需要进行目视检查。但是去观察给的矩阵会发现里面的内容很奇怪,如果用黑白图像表示,大概是这样子的:
白色的内容为1,就是被标注的真值;黑色部分都是0

一些疑惑:
1.真值矩阵中只有左下角有“1”,可能只是一个下三角矩阵(只有左下角有loop信息);可是这是一个完整的矩阵,包含左右双目的信息,“1”的分布很奇怪(左目检测到回环,右目难道不是嘛?)
2.在接受第1点的前提下,矩阵的纬度是2474×2474,说明任意两张图片都遍历过了;可是检查标注为1的两张图片,有一些很明显不是在同一个位置;可是有一些标注为“0”,但是又是很相近的位置分离图像:这里用Python脚本来处理一下,得到两个文件夹,里面分别保存了1237张左目和1237张右目的图像
import os import shutil def split_images(source_folder, target_folder1, target_folder2): img_names = sorted(os.listdir(source_folder)) # 将写入的图片转为list列表形式, eg:0001.png,0002.png,..... for i,file_name in enumerate(img_names): source_path = os.path.join(source_folder, file_name) # 组合完成后:***/image/00001.png if i%2== 0: target_path = os.path.join(target_folder1, file_name) else: target_path = os.path.join(target_folder2, file_name) shutil.copyfile(source_path, target_path) # 将源文件复制过去 source_folder = "/home/h/slam_pub_Datasets/Oxford/citycenter/citycenter/Images" target_folder1 = "/home/h/slam_pub_Datasets/Oxford/citycenter/citycenter/left_img" target_folder2 = "/home/h/slam_pub_Datasets/Oxford/citycenter/citycenter/right_img" split_images(source_folder, target_folder1, target_folder2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
提取对应的左右目的真值标注:这里用MATLAB脚本(MATLAB用的有点low…)
source_data = load("CityCentreTextFormat.txt"); [row, col] = size(source_data); result_matrix = []; for i = 1:2:row for j = 1:2:col result_matrix((i+1)/2, (j+1)/2) = source_data(i,j); end end transpose_result_matrix = transpose(result_matrix); [row, col] = size(transpose_result_matrix); fact = zeros([], 1); index = 1; for i= 1 : row for j = i+1 : col fact(index) = transpose_result_matrix(i , j); index = index+1 ; end end transpose_fact = transpose(fact); file_name = "fact.csv"; csvwrite(file_name, transpose_fact);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
处理完成后获得了fact.csv真值标注文件(单目),利用DBoW字典模型和loop_close进行打分,将其保存为score.csv
将这俩文件读入5中的PR曲线绘制matlab代码中,设置合理的阈值(0.02, 0.001, 100)
贴一张右目的PR曲线图:
先不说正确性如何,起码画出来了…下面分析一下图像的问题:
前面分析过slam的回环检测过程中,表格中四个参数最被看重的是假阳性(FP),因为被算法漏掉不可怕,顶多出现一些误差,但是被算法检测到是回环,但是实际不是回环这就很可怕了,这可能导致整个mapping过程出现错乱。
在这张图中,可以看出准确率甚至没有突破0.1这个范围,根据准确率公式:TP/(TP+FP),准确率很小说明假阳性(FP)特别大
再结合真值文件和打分情况来看,阈值给到了0.02(这基本上比绝大多数的score要大了)的情况下,即算法认为是回环但是太多实际标注给到“0”导致了太多的假阳性。真值文件中“0”确实占到了大部分,所以这张PR图也“合理”。
其实上面的操作是不合理的,在正常slam中都是对关键帧KF进行回环检索的,否则相近的两帧会被误匹配。所以后面还应该加入delta来对图片进行选取,例如每隔50张图片选择一张,这样能避免很多相近的相似图片进行匹配,但是truth给到0这一情况。
留个位置
7.TUM数据集图像时间戳和groundtruth.txt时间戳不对齐?&&记录绘制TUM数据集的PR曲线
slam14讲ch11的课后习题2中,需要对一系列轨迹运动找到相似的两帧图片(30hz),可是运行代码后发现,图片的时间戳和groundtruth.txt的时间戳完全不对齐,而且TUM数据集的外部真值采集设备的频率很高(应该是100hz),所以在测试之前是要将数据进行一个预处理对齐。
详情查看下面这个博客:
https://www.cnblogs.com/gaoxiang12/p/5175118.html
数据集和工具包:
https://cvg.cit.tum.de/data/datasets/rgbd-dataset/download#freiburg1_room
https://cvg.cit.tum.de/data/datasets/rgbd-dataset/tools选择的这个数据集构成了一个回环,且场景较小适合练习。
除此之外要解决第一个时间不对齐的问题,在TUM官网上提供了一个脚本文件:associate.py,具体用法参考上面博客
不研究深度信息,直接终端运行:
python associate.py rgb.txt groundtruth.txt > match_time.txt- 1
生成了一个match_time.txt文件,之间的对齐匹配根据默认参数max_difference,即时间戳小于0.02来配对的
先根据数据集训练字典模型,才能追踪打分
由于这次数据集没有给出提前人工标注的真值,需要根据真实位姿进行判定匹配,下面是c++的代码:
#include#include #include #include #include #include using namespace std; using namespace Eigen; int main(int argc, char **argv) { string groundtruth_file = "/home/h/slam_pub_Datasets/TUM/rgbd_dataset_freiburg1_room/match_time.txt"; // txt文件中数据格式为: image_infomation | pose_information int delta = 50;//寻找“KF”的间隔 double threshold = 0.8; // 齐次变换矩阵差的范数,小于该值时认为位姿非常接近 ifstream fin(groundtruth_file); if(!fin) { cout << "cannot find trajectory" << endl; return 1; } vector<string> img_path; vector<string> KF_img_path; vector<Isometry3d, Eigen::aligned_allocator<Isometry3d>> KF_poses; vector<string> KF_img_times; int count = 0;//判定“KF”的计数器 int num = 0; fstream f; f.open("/home/h/slam_pub_Datasets/TUM/rgbd_dataset_freiburg1_room/KF_rgb/selected_KF.txt", ios::out | ios::trunc); while (!fin.eof()) { string img_time, img_name, pose_time; double tx, ty, tz, qx, qy, qz, qw; // tum格式 fin >> img_time >> img_name >> pose_time >> tx >> ty >> tz >> qx >> qy >> qz >> qw; Isometry3d T = Isometry3d::Identity();// 定义4*4的变换矩阵 T.rotate(Quaterniond(qw, qx, qy, qz)); T.pretranslate(Vector3d(tx, ty, tz));// refer:slambook2/ch3/useGeometry.cpp img_path.push_back(img_name); if(count % delta == 0) { // 判定成功的话被选为“KF“ KF_img_path.push_back(img_name); KF_poses.push_back(T); KF_img_times.push_back(img_time); cout << KF_img_times[num] << endl; f << KF_img_times[num] << endl; num++; } count++; } f.close(); fin.close(); cout << "-------------------------" << endl; cout << "Total images numbers: " << img_path.size() << endl; cout << "selected key frame pose numbers: " << KF_poses.size() << endl; cout << "-----Detection Start-----" << endl; cout << "-------------------------" << endl; // 创建真值文件Fact.txt fstream fact; fact.open("/home/h/slam_pub_Datasets/TUM/rgbd_dataset_freiburg1_room/fact/Fact.txt", ios::out | ios::trunc); for (int i = 0; i < KF_poses.size(); i++) { for (int j = i+1; j < KF_poses.size(); j++) { Matrix4d Error = Error.Zero(); Error = (KF_poses[i].inverse() * KF_poses[j]).matrix() - Matrix4d::Identity(); double n = Error.norm(); if (n < threshold) { fact << 1 << endl; cout << "第" << i << "张关键帧与第" << j << "张关键帧构成回环" << endl; cout << "位姿误差为" << n << endl; cout << "第" << i << "张关键帧的时间戳为" << endl << KF_img_times[i] << endl; cout << "第" << j << - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
-
相关阅读:
底层概念的重要意义
JS教程之Electron.js设计强大的多平台桌面应用程序的好工具
【FAQ】关于华为地图服务定位存在偏差的原因及解决办法
Java学习笔记(二十四)
[AIGC] Java序列化利器 gson
R语言 地理加权随机森林(GWRFC )
babel
弱监督点云分割(论文解读:CVPR2020)
数据大航海时代,奇安信如何构筑数据安全的“天盾”?
gitlab-runner配置与注册
- 原文地址:https://blog.csdn.net/qq_45306739/article/details/133469025
