-
全连接网络实现回归【房价预测的数据】
也是分为data,model,train,test
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- class FCNet(nn.Module):
- def __init__(self):
- super(FCNet,self).__init__()
- self.fc1 = nn.Linear(331,200)
- self.fc2 = nn.Linear(200,150)
- self.fc3 = nn.Linear(150,100)
- self.fc4 = nn.Linear(100,1)
- #因为是回归问题,所以输出是1
- def forward(self,x):
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = F.relu(self.fc3(x))
- x = self.fc4(x)
- return x
- class FCNet3(nn.Module):
- def __init__(self):
- super(FCNet3,self).__init__()
- self.fc1 = nn.Linear(331,200)
- self.fc2 = nn.Linear(200,100)
- self.fc3 = nn.Linear(100,1)
- def forward(self,x):
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
- # print(net)
- import pandas as pd
- import os
- import torch
- # my_device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- if torch.cuda.is_available():
- my_device = torch.device('cuda')
- else:
- my_device = torch.device('cpu')
- training_data = pd.read_csv('./kaggle_house_pred_train.csv')
- testing_data = pd.read_csv('./kaggle_house_pred_test.csv')
- #拼在一起,方便后面统一处理
- all_features = pd.concat(( training_data.iloc[:,1:-1], testing_data.iloc[:,1:]))
- # print("train_data.shape:",training_data.shape)
- # print("test_data.shape:",testing_data.shape)
- # print("all_features:",all_features.shape)
- # print(training_data.iloc[:5,:8])
- #处理:把一些不是数值的那些特征值进行转换,并且归一化,还有就是把空值填充为0
- numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
- # print(numeric_features)
- all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
- #all_features[numeric_features] = all_features[numeric_features]
- all_features[numeric_features] = all_features[numeric_features].fillna(0)
- all_features = pd.get_dummies(all_features, dummy_na = True)
- #df = all_features.to_csv('./newdata.csv')
- print("all_features:",all_features)
- #把数据分成训练数据和测试数据
- n_train = training_data.shape[0]
- #all_features = all_features.astype('float')
- train_features = torch.tensor(all_features[:n_train].values, dtype = torch.float32)
- test_features = torch.tensor(all_features[n_train:].values, dtype = torch.float32)
- train_labels = torch.tensor(training_data.SalePrice.values.reshape(-1, 1), dtype = torch.float32)
- print("train_features.shape:", train_features.shape)
- print("test_features.shape:", test_features.shape)
- print("train_labels:", train_labels.shape)
- #保存转换之后的数据
- new_train_data = pd.DataFrame(train_features.numpy()).to_csv('./train_data_normalization.csv')
- new_train_labels = pd.DataFrame(train_labels.numpy()).to_csv('./train_labels_normal.csv')
- train_dataset = torch.utils.data.TensorDataset(train_features,train_labels)
- train_dataloadr = torch.utils.data.DataLoader(train_dataset,batch_size=32,shuffle = True,num_workers = 0,pin_memory = True)
- #因为要测试 所有就没有真实标签了,dataloader也可以直接只放数据,后面测试时候就是inputs = data
- test_dataset = torch.utils.data.TensorDataset(test_features)
- test_dataloadr = torch.utils.data.DataLoader(test_dataset,batch_size=32,shuffle = True,num_workers = 0,pin_memory = True)
- #print(len(train_dataloadr))
- # print(len(test_dataloadr))
- #print(train_labels)
- import torch
- import torch.nn as nn
- import torch.functional as F
- import torch.optim as optim
- from Model import FCNet
- import data
- import matplotlib.pyplot as plt
- if torch.cuda.is_available():
- my_device = torch.device('cuda:0')
- else:
- my_device = torch.device('cpu')
- print(my_device)
- net = FCNet().to(my_device)
- #print(net)
- criterion = nn.MSELoss()
- optimizer = optim.Adam(net.parameters(),lr=0.0001)
- epochs = 2000
- def train(train_loader):
- train_loss = []
- for epoch in range(epochs):
- loss_sum = 0
- for i, data in enumerate(train_loader):
- inputs,labels = data
- print(data)
- inputs,labels = inputs.to(my_device),labels.to(my_device)
- optimizer.zero_grad()
- outputs = net(inputs)
- print('outputs=',outputs)
- print('labels=',labels)
- #因为是回归问题,所以直接放到loss中就可以了
- loss = criterion(outputs,labels)
- # print(loss.item())
- loss.backward()
- optimizer.step()
- loss_sum += loss.item()
- if i%32 == 31:
- print('Batch {}'.format(i+1),'Loss {}'.format(loss_sum/100))
- train_loss.append(loss_sum)
- torch.save(net.state_dict(),'./f4_weights_epoch2000.pth')
- plt.plot(range(epochs),train_loss)
- plt.show()
- train(data.train_dataloadr)
- import pandas as pd
- import data
- import torch
- from Model import FCNet
- if torch.cuda.is_available():
- my_device = torch.device('cuda:0')
- else:
- my_device = torch.device('cpu')
- test_data = data.testing_data
- test_features = data.test_features
- def test(test_features):
- test_features = test_features.to(my_device)
- preds = net(test_features).detach().to('cpu').numpy()
- print(preds.squeeze().shape)
- test_data['SalePrice'] = pd.Series(preds.squeeze())
- return pd.concat([test_data['Id'],test_data['SalePrice']],axis=1)
- net = FCNet().to(my_device)
- net.load_state_dict(torch.load('./f4_weights_epoch2000.pth'))
- res = test(test_features)
- res.to_csv('./f4_test_res.csv',index=False)
预测结果还挺接近的
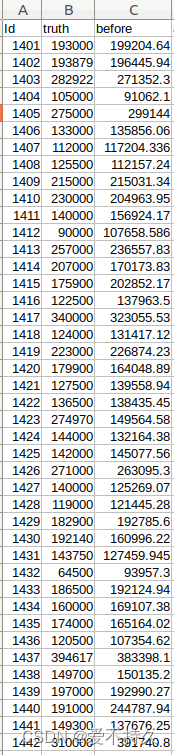
-
相关阅读:
307. Range Sum Query - Mutable
解决交叉编译的依赖问题
react中预览excel表格
卷积神经网络(CNN)原理与实现
KubeSphere v3.4.0 部署K8S Docker + Prometheus + grafana
多层全连接网络:实现手写数字识别50轮准确率92.1%
【小沐学NLP】AI辅助编程工具汇总
手机USB共享网络是个啥
Linux—进程管理
Vue2之防抖_debounce封装函数&v-debounce自定义指令(传参/不传)
- 原文地址:https://blog.csdn.net/wacebb/article/details/133470161
