-
《Operating Systems: Three Easy Pieces》 操作系统【一】 虚拟化 CPU
(一)操作系统介绍
1.虚拟化 CPU
书上代码 :
#include#include #include #include #include "common.h" int main(int argc, char *argv[]) { if (argc != 2) { fprintf(stderr, "usage: cpu \n" ); exit(1); } char *str = argv[1]; while (1) { Spin(1); printf("%s\n", str); } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
运行 程序是死循环
prompt> ./cpu A & ; ./cpu B & ; ./cpu C & ; ./cpu D & [1] 7353 [2] 7354 [3] 7355 [4] 7356 A B D C A B D C A C B D ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
当同时执行运行
4个程序的命令时,打印几乎是同时运行的,而不是等待第一个程序运行结束才运行下个程序
对应单核的处理器,同时运行4个进程是不可能的,所有这里就要介绍CPU的虚拟化
事实证明,在硬件的一些帮助下,操作系统负责提供这种假象(illusion),即系统拥有非常多的虚拟CPU的假象。将单个CPU(或其中一小部分)转换为看似无限数量的CPU,从而让许多程序看似同时运行,这就是所谓的虚拟化 CPU(virtualizing the CPU)
当然运行不同进程时的策略,如优先级等也是需要讨论的
知识点:时分共享,上下文切换2.虚拟化内存
#include#include #include #include "common.h" int main(int argc, char *argv[]) { int *p = malloc(sizeof(int)); // a1 assert(p != NULL); printf("(%d) memory address of p: %08x\n", getpid(), (unsigned)p); // a2 *p = 0; // a3 while (1) { Spin(1); *p = *p + 1; printf("(%d) p: %d\n", getpid(), *p); // a4 } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这是一个访问内存的程序(
mem.c)
该程序做了几件事。首先,它分配了一些内存(a1行)。然后,打印出内存的地址(a2行),然后将数字0放入新分配的内存的第一个空位中(a3行)。最后,程序循环,延迟一秒钟并递增p中保存的值。在每个打印语句中,它还会打印出所谓的正在运行程序的进程标识符(PID)(a4行)。该PID对每个运行进程是唯一的。
该程序的输出如下:prompt> ./mem (2134) memory address of p: 00200000 (2134) p: 1 (2134) p: 2 (2134) p: 3 (2134) p: 4 (2134) p: 5 ˆC- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 当只运行一个程序时,p 递增,一切正常
prompt> ./mem &; ./mem & [1] 24113 [2] 24114 (24113) memory address of p: 00200000 (24114) memory address of p: 00200000 (24113) p: 1 (24114) p: 1 (24114) p: 2 (24113) p: 2 (24113) p: 3 (24114) p: 3 (24113) p: 4 (24114) p: 4 ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
当同时运行多个相同的程序时,分配的内存地址竟然是相同的,先抛开虚拟化的概念,以物理内存的角度看待,这几个程序分配的内存指针指向了同一块内存空间,也就是修改其中一个程序修改内存也会导致另一个程序中的值改变
但是从结果来看这两块内存相互独立,并不影响,就好像每个正在运行的程序都有自己的私有内存,而不是与其他正在运行的程序共享相同的物理内存
实际上,这正是操作系统虚拟化内存(virtualizing memory)时发生的情况。每个进程访问自己的私有虚拟地址空间(virtual address space)(有时称为地址空间,address space),操作系统以某种方式映射到机器的物理内存上。一个正在运行的程序中的内存引用不会影响其他进程(或操作系统本身)的地址空间。对于正在运行的程序,它完全拥有自己的物理内存。但实际情况是,物理内存是由操作系统管理的共享资源。
知识点:(等待补充)3.并发
#include#include #include "common.h" volatile int counter = 0; int loops; void *worker(void *arg) { int i; for (i = 0; i < loops; i++) { counter++; } return NULL; } int main(int argc, char *argv[]) { if (argc != 2) { fprintf(stderr, "usage: threads \n" ); exit(1); } loops = atoi(argv[1]); pthread_t p1, p2; printf("Initial value : %d\n", counter); Pthread_create(&p1, NULL, worker, NULL); Pthread_create(&p2, NULL, worker, NULL); Pthread_join(p1, NULL); Pthread_join(p2, NULL); printf("Final value : %d\n", counter); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
主程序利用
Pthread_create()创建了两个线程(thread),每个线程中循环了loops次来递增全局变量counter。
理想情况下,counter最终的值应该为2xloops,因为两个线程各把counter递增了loops次prompt> ./thread 100000 Initial value : 0 Final value : 143012 // huh?? prompt> ./thread 100000 Initial value : 0 Final value : 137298 // what the??- 1
- 2
- 3
- 4
- 5
- 6
当运行时,发现值每次各不相同,且小于
2xloops。
事实证明,这些奇怪的、不寻常的结果与指令如何执行有关,指令每一执行一条。遗憾的是,上面的程序中的关键部分是增加共享计数器的地方,它需要3条指令:- 一条将计数器的值从内存加载到寄存器
- 一条将其递增
- 一条将其保存回内存。
因为这
3条指令甚不是以原子方式(atomically)执行(所有的指令一一性执行)的,所以奇怪的事情可能会发生。
知识点:原子操作。4.持久性
操作系统中管理磁盘的软件通常称为文件系统(
file system)。因此它负责以可靠和高效的方式,将用户创建的任何文件(file)存储在系统的磁盘上。#include#include #include #include #include int main(int argc, char *argv[]) { int fd = open("/tmp/file", O_WRONLY | O_CREAT | O_TRUNC, S_IRWXU); assert(fd > -1); int rc = write(fd, "hello world\n", 13); assert(rc == 13); close(fd); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
为了完成这个任务,该程序向操作系统发出
3个调用。第一个是对open()的调用,它打开文件并创建它。第二个是write(),将一些数据写入文件。第三个是close(),只是简单地关闭文件,从而表明程序不会再向它写入更多的数据。这些系统调用(system call)被转到称为文件系统(file system)的操作系统部分,然后该系统处理这些请求,并向用户返回某种错误代码。
首先确定新数据将驻留在磁盘上的哪个位置,然后在文件系统所维护的各种结构中对其进行记录。这样做需要向底层存储设备发出I/O请求,以读取现有结构或更新(写入)它们。所有写过设备驱动程序(device driver)的人都知道,让设备现表你执行某项操作是一个复杂而详细的过程。它需要深入了解低级别设备接口及其确切的语义。幸运的是,操作系统提供了一种通过系统调用来访问设备的标准和简单的方法。因此,OS有时被视为标准库(standard library)。
出于性能方面的原因,大多数文件系统首先会延迟这些写操作一段时间,希望将其批量分组为较大的组。为了处理写入期间系统崩溃的问题,大多数文件系统都包含某种复杂的写入协议,如日志(journaling)或写时复制(copy-on-write),仔细排序写入磁盘的操作,以确保如果在写入序列期间发生故障,系统可以在之后恢复到合理的状态。为了使不同的通用操作更高效,文件系统采用了许多不同的数据结构和访问方法,从简单的列表到复杂的B 树。5.设计目标
- 抽象(
abstraction),让系统方便和易于使用。抽象对我们在计算机科学中做的每件事都很有帮助。抽象使得编写一个大型程序成为可能,将其划分为小而且容易理解的部分 - 高性能(
performance)。换言之,我们的目标是最小化操作系统的开销(minimize the overhead)。但是虚拟化的设计是为了易于使用,无形之中会增大开销,比如虚拟页的切换,cpu 的调度等等,所以尽可能的保持易用性与性能的平衡至关重要 - 应用程序之间以及在 OS 和应用程序之间提供保护(
protection)。因为我们希望让许多程序同时运行,所以要确保一个程序的恶意或偶然的不良行为不会损害其他程序。保护是操作系统基本原理之一的核心,这就是隔离(isolation)。让进程彼此隔离是保护的关键,因此决定了 OS 必须执行的大部分任务 - 操作系统也必须不间断运行。当它失效时,系统上运行的所有应用程序也会失效。由于这种
依赖性,操作系统往往力求提供高度的可靠性(reliability)
(二) 抽象 : 进程
1.什么是进程 ?
- 操作系统为正在运行的程序提供的抽象
- 进程可以访问的内存(称为地址空间,
address space) 是该进程的一部分。 - 进程的机器状态的另一部分是寄存器。
- 例如,程序计数器(
Program Counter,PC)(有时称为指令指针,Instruction Pointer 或 IP)告诉我们程序当前 正在执行哪个指令;类似地,栈指针(stack pointer)和相关的帧指针(frame pointer)用于 管理函数参数栈、局部变量和返回地址。
2.进程API :
\ 创建(
create):操作系统必须包含一些创建新进程的方法。在 shell 中键入命令 或双击应用程序图标时,会调用操作系统来创建新进程,运行指定的程序。
\ 销毁(destroy):由于存在创建进程的接口,因此系统还提供了一个强制销毁进 程的接口。当然,很多进程会在运行完成后自行退出。但是,如果它们不退出, 用户可能希望终止它们,因此停止失控进程的接口非常有用。
\ 等待(wait):有时等待进程停止运行是有用的,因此经常提供某种等待接口。 \ 其他控制(miscellaneous control):除了杀死或等待进程外,有时还可能有其他4.3 进程创建:更多细节 21
控制。例如,大多数操作系统提供某种方法来暂停进程(停止运行一段时间), 然后恢复(继续运行)。
\ 状态(statu):通常也有一些接口可以获得有关进程的状态信息,例如运行了多 长时间,或者处于什么状态。
\ 其他控制(miscellaneous control):除了杀死或等待进程外,有时还可能有其他控制。例如,大多数操作系统提供某种方法来暂停进程(停止运行一段时间), 然后恢复(继续运行)3. 进程创建:更多细节
- 操作系统如何启动并运 行一个程序?进程创建实际如何进行 ?

- 为栈分配空间 : 将代码和静态数据加载到内存后,必须为程序的运行时栈(
run-time stack或stack)分配一些内存。C 程序使用栈存放局部变量、函数参数和返回地址。操作系统也可能会用参数初始化栈。具体来说,它会将参数填入main( )函数,即argc和argv数组。 - 为堆分配空间 : 操作系统也可能为程序的堆(
heap)分配一些内存。程序通过调用 malloc()来请求这样的空间,并通过调用 free()来明确地释放它。数据结构(如链表、散列表、树和其他有趣的数据结构)需要堆。 I/O初始化:操作系统还将执行一些其他初始化任务,特别是与输入/输出(I/O)相关的任务。例如,在UNIX系统中,默认情况下每个进程都有 3 个打开的文件描述符(file descriptor),用于标准输入、输出和错误。这些描述符让程序轻松读取来自终端的输入以及打印输出到屏幕。- 运行程序入口:通过将代码和静态数据加载到内存中,通过创建和初始化栈以及执行与
I/O设置相关的其他工作,完成准备后,接下来就是启动程序,在入口处运行,即main()。
4 进程状态
\ 运行(
running):在运行状态下,进程正在处理器上运行。这意味着它正在执行 指令。
\ 就绪(ready):在就绪状态下,进程已准备好运行,但由于某种原因,操作系统 选择不在此时运行。
\ 阻塞(blocked):在阻塞状态下,一个进程执行了某种操作,直到发生其他事件 时才会准备运行。一个常见的例子是,当进程向磁盘发起 I/O 请求时,它会被阻塞, 因此其他进程可以使用处理器。

- 有IO 会造成进程的堵塞

- 操作系统必须作出许多决定来让CPU繁忙来繁忙来提高资源利用率。
5 数据结构
为了跟踪每个进程的状态,操作系统可能会为所有就绪的进程保留某种
进程列表(process list),以及跟踪当前正在运行的进程的一些附加信息。操作系统还必须以某种方式跟踪被阻塞的进程。当I/O 事件完成时,操作系统应确保唤醒正确的进程,让它准备好再次运行。// the registers xv6 will save and restore // to stop and subsequently restart a process struct context { int eip; int esp; int ebx; int ecx; int edx; int esi; int edi; int ebp; }; // the different states a process can be in // 可以看到实际操作系统对于进程状态的定义远不止上面介绍的3种 enum proc_state { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE }; // the information xv6 tracks about each process // including its register context and state struct proc { char *mem; // Start of process memory uint sz; // Size of process memory char *kstack; // Bottom of kernel stack // for this process enum proc_state state; // Process state int pid; // Process ID struct proc *parent; // Parent process void *chan; // If non-zero, sleeping on chan int killed; // If non-zero, have been killed struct file *ofile[NOFILE]; // Open files struct inode *cwd; // Current directory struct context context; // Switch here to run process struct trapframe *tf; // Trap frame for the // current interrupt };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 对于停止的进程,寄存器上下文将保存其寄存器的内容。
除了
运行、就绪和阻塞之外,还有其他一些进程可以处于的状态:初始(initial)状态有时候系统会有一个初始(initial)状态,表示进程在创建时处于的状态。最终(final)状态另外,一个进程可以处于已退出但尚未清理的最终(final)状态(在基于UNIX的系统中,这称为僵尸状态)。这个最终状态非常有用,因为它允许其他进程(通常是创建进程的父进程)检查进程的返回代码,并查看刚刚完成的进程是否成功执行(通常,在基于UNIX的系统中,程序成功完成任务时返回零,否则返回非零)。完成后,父进程将进行最后一次调用(例如,wait()),以等待子进程的完成,并告诉操作系统它可以清理这个正在结束的进程的所有相关数据结构
(三)插叙:进程 API
1.fork()系统调用
系统调用fork()用于创建新进程
#include#include #include int main(int argc, char *argv[]) { printf("hello world (pid:%d)\n", (int) getpid()); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) printf("hello, I am child (pid:%d)\n", (int) getpid()); } else { // parent goes down this path (original process) printf("hello, I am parent of %d (pid:%d)\n", rc, (int) getpid()); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
prompt> ./p1 hello world (pid:29146) hello, I am parent of 29147 (pid:29146) hello, I am child (pid:29147) prompt>- 1
- 2
- 3
- 4
- 5
- 子进程并不是完全拷贝了父进程。具体来说,虽然它拥有自己的
地址空间(即拥有自己的私有内存)、寄存器、程序计数器等,但是它从fork()返回的值是不同的。父进程获得的返回值是新创建子进程的PID,而子进程获得的返回值是0。 - 在其他情况下,子进程可能先运行 , 会有不同的情况 , 取决于
CPU调度
2.wait()系统调用
- wait()函数用于使父进程(也就是调用
wait()的进程)阻塞,直到一个子进程结束或者该进程接收到了一个指定的信号为止。
#include#include #include #include int main(int argc, char *argv[]) { printf("hello world (pid:%d)\n", (int) getpid()); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) printf("hello, I am child (pid:%d)\n", (int) getpid()); sleep(1); } else { // parent goes down this path (original process) int wc = wait(NULL); printf("hello, I am parent of %d (wc:%d) (pid:%d)\n", rc, wc, (int) getpid()); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

- 该系统调用会谁子进程运行结束后才返回①。因此,即使父进程先运 行,它也会礼貌地等待子进程运行完毕,然后 wait()返回,接着父进程才输出自己的信息。
3. exec()系统调用
- exec()这个系统调用可以让子进程执行与父进程不同的程序
- exec()有几种变体:execl()、execle()、execlp()、execv()和 execvp()。请阅读 man 手册以了解更多信息。
- Linux多任务编程(三)—exec函数族及其基础实验_玖零大壮的博客-CSDN博客
#include#include #include #include #include int main(int argc, char *argv[]) { printf("hello world (pid:%d)\n", (int) getpid()); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) printf("hello, I am child (pid:%d)\n", (int) getpid()); char *myargs[3]; myargs[0] = strdup("wc"); // program: "wc" (word count) myargs[1] = strdup("p3.c"); // argument: file to count myargs[2] = NULL; // marks end of array execvp(myargs[0], myargs); // runs word count printf("this shouldn't print out"); } else { // parent goes down this path (original process) int wc = wait(NULL); printf("hello, I am parent of %d (wc:%d) (pid:%d)\n", rc, wc, (int) getpid()); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 用 fork()、wait( ) 和 exec( )(p3.c)
prompt> ./p3 hello world (pid:29383) hello, I am child (pid:29384) 29 107 1030 p3.c hello, I am parent of 29384 (wc:29384) (pid:29383) prompt>- 1
- 2
- 3
- 4
- 5
- 6
子进程调用 execvp()来运行字符计数程序
wc。实际上,它针对源代码文件 p3.c 运行 wc,从而告诉我们该文件有多少行、多少单词,以及多少字节。
给定可执行程序的名称(如wc)及需要的参数(如p3.c)后,exec()会从可 执行程序中加载代码和静态数据,并用它覆写自己的代码段(以及静态数据),堆、栈及其他内存空间也会被重新初始化。然后操作系统就执行该程序,将参数通过argv传递给该进程。因此,它并没有创建新进程,而是直接将当前运行的程序(以前的p3)替换为不同的运行程序(wc)。子进程执行exec()之后,几乎就像p3.c从未运行过一样。对exec()的成功调用永远不会返回。如果exec函数执行失败, 它会返回失败的信息, 而且进程继续执行后面的代码。
注意:此时子进程的pid号并没有变,且还是该父进程的子进程,所以并不会影响wait( )操作,等待该进程的操作(统计字节)完成后,wait()才会返回,父进程同时退出阻塞状态4.为什么这样设计 API。

- fork()和 exec()的分离,让 shell 可以方便地实现很多有用的功能。
#include#include #include #include #include #include #include int main(int argc, char *argv[]) { int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child: redirect standard output to a file close(STDOUT_FILENO); open("./p4.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU); // now exec "wc"... char *myargs[3]; myargs[0] = strdup("wc"); // program: "wc" (word count) myargs[1] = strdup("p4.c"); // argument: file to count myargs[2] = NULL; // marks end of array execvp(myargs[0], myargs); // runs word count } else { // parent goes down this path (original process) int wc = wait(NULL); assert(wc >= 0); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
prompt> wc p3.c > newfile.txt prompt> ./p4 prompt> cat p4.output 32 109 846 p4.c -- p4 我实调用了 fork 来创建新的子进程,之后调用 execvp()来执行 wc。 -- 屏幕上谁有看到输出, 是由于结果被重我向到文件 p4.output。- 1
- 2
- 3
- 4
- 5
- 6
- 7
要看懂上面的例子,首先要补充点Unix文件描述符的知识
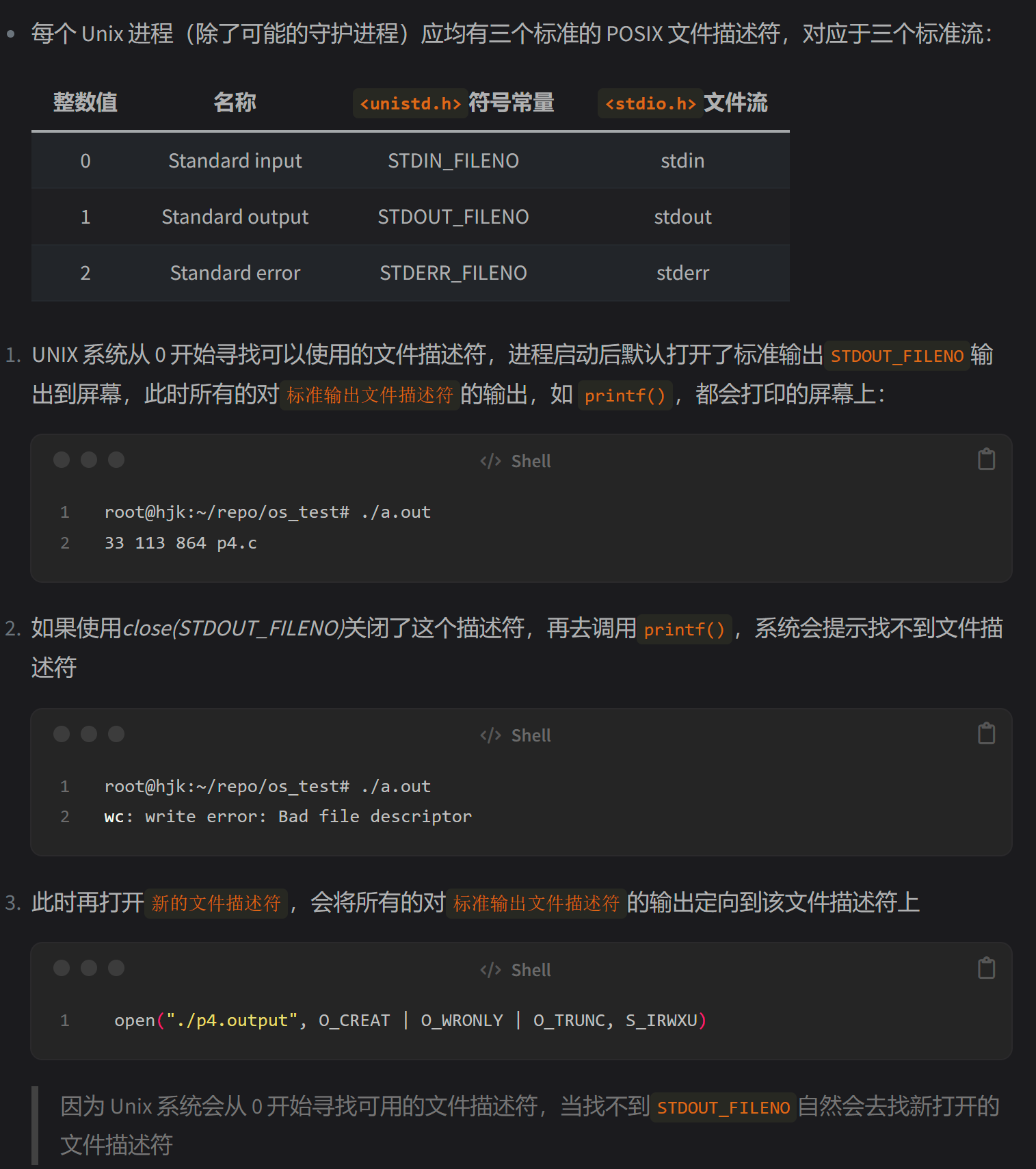
作业
- 编写一个调用
fork()的程序。在调用fork()之前,让主进程访问一个变量(例如 x)并将其值设置为某个值(例如 100)。子进程中的变量有什么值?当子进程和父进程都改变 x 的值时,变量会发生什么?
答:父进程在 fork 之前修改的值会同步到子进程中(fork 前子进程并不存在),当 fork 完成后,两个进程相互独立,修改 fork 前定义的变量时也是独立的。
#include#include #include int main(int argc, char *argv[]) { int x = 1; printf("hello world (pid:%d)\n", (int)getpid()); x = 3; int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child (new process) x=4; printf("hello, I am child (pid:%d),x:%d\n", (int)getpid(),x); } else { // parent goes down this path (main) wait(NULL); printf("hello, I am parent of %d (pid:%d),x:%d\n", rc, (int)getpid(),x); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
root@hjk:~/repo/os_test# ./a.out hello world (pid:17699) hello, I am child (pid:17700),x:4 hello, I am parent of 17700 (pid:17699),x:3- 1
- 2
- 3
- 4
2.编写一个打开文件的程序(使用 open()系统调用),然后调用 fork()创建一个新进程。子进程和父进程都可以访问 open()返回的文件描述符吗?当它们并发(即同时)写入文件时,会发生什么?
答:都可以访问。并发时无影响。#include#include #include #include #include #include int main(int argc, char *argv[]) { close(STDOUT_FILENO); int fd = open("./p4.output", O_CREAT | O_WRONLY | O_TRUNC, S_IRWXU); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child: redirect standard output to a file // now exec "wc"... printf("child\n"); } else { // parent goes down this path (main) // int wc = wait(NULL); printf("father\n"); } // if(fd>=0) // { // close(fd); // } return 0; } p4.output 文件输出如下: father child - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
3.使用 fork()编写另一个程序。子进程应打印“hello”,父进程应打印“goodbye”。你应该尝试确保子进程始终先打印。你能否不在父进程调用 wait()而做到这一点呢?
答:使用 sleep 函数时父进程休眠一段时间4.现在编写一个程序,在父进程中使用 wait(),等待子进程完成。wait()返回什么?如果你在子进程中使用 wait()会发生什么?
答:wait()返回子进程的 pid,子进程中调用无影响,返回值为-1。#include#include #include #include #include #include int main(int argc, char *argv[]) { close(STDOUT_FILENO); int fd = open("./p4.output", O_CREAT | O_WRONLY | O_TRUNC, S_IRWXU); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child: redirect standard output to a file // now exec "wc"... int wc=wait(NULL); printf("child,pid:%d,wc:%d\n",getpid(),wc); } else { // parent goes down this path (main) int wc = wait(NULL); // sleep(1); printf("father,pid:%d,wc:%d\n",getpid(),wc); } // if(fd>=0) // { // close(fd); // } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
5.对前一个程序稍作修改,这次使用 waitpid()而不是 wait()。什么时候 waitpid()会有用?
waitpid()参数值 说明 pid<-1 等待进程组号为 pid 绝对值的任何子进程。 pid=-1 等待任何子进程,此时的 waitpid()函数就退化成了普通的 wait()函数。 pid=0 等待进程组号与目前进程相同的任何子进程,也就是说任何和调用 waitpid()函数的进程在同一个进程组的进程。 pid>0 等待进程号为 pid 的子进程。 使用getpgrp()获取当前进程组号
答:当 pid 为0(pid=0),-1(pid=-1),child_pid(pid>0),getpgrp()*-1(pid<-1)时,waitpid()有用6.编写一个创建子进程的程序,然后在子进程中关闭标准输出(STDOUT_FILENO)。如果子进程在关闭描述符后调用 printf()打印输出,会发生什么?
答:子进程无法打印,父进程无影响#include#include #include #include #include #include int main(int argc, char *argv[]) { // close(STDOUT_FILENO); // int fd = open("./p4.output", O_CREAT | O_WRONLY | O_TRUNC, S_IRWXU); int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child: redirect standard output to a file // now exec "wc"... // int wc=wait(NULL); close(STDOUT_FILENO); printf("child,pid:%d,wc:%d\n",getpid()); } else { // parent goes down this path (main) // int wc = waitpid(getpgrp(),NULL,0); // sleep(1); printf("father,pid:%d,wc:%d\n",getpid()); } // if(fd>=0) // { // close(fd); // } return 0; } 输出 root@hjk:~/repo/os_test# ./a.out father,pid:11189,wc:0 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
7.编写一个程序,创建两个子进程,并使用 pipe()系统调用,将一个子进程的标准输出连接到另一个子进程的标准输入。
答:该程序将子进程2中的输出通过管道连接到子进程1的输入中#include#include #include #include #include #include int main(int argc, char *argv[]) { int fds[2]; if(pipe(fds)==-1) { fprintf(stderr, "open pipe failed\n"); exit(1); } int rc = fork(); if (rc < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // child: redirect standard output to a file // int wc=wait(NULL); printf("child1,pid:%d\n",getpid()); int len; char buf[10]; // 从pipe中读取 if((len=read(fds[0],buf,6))==-1) { perror("read from pipe"); exit(1); } printf("buf:%s\n",buf); exit(0); } else { // parent goes down this path (main) // wait(NULL); //创建第二个子进程 int rc2 = fork(); if (rc2 < 0) { // fork failed; exit fprintf(stderr, "fork failed\n"); exit(1); } else if (rc2 == 0) { // child: redirect standard output to a file // int wc=wait(NULL); printf("child2,pid:%d\n",getpid()); char buf[]= "12345"; // 写入pipe if(write(fds[1],buf,sizeof(buf))!=sizeof(buf)) { perror("write to pipe"); exit(1); } exit(0); } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
(四) 机制:受限直接执行
- 操作系统需要以某种方式让许多任务共享物理
CPU - 运行一个进程一段时间,然后运行另一个进程,如此轮换。通过以这种方式时分共享(
time sharing)CPU,就实现了虚拟化 。 然而存在问题是性能(不增加额外开销)与控制权(权限)。
基本技巧:受限直接执行
- 为了使程序尽可能快地运行的技术 称之为受限的 直接执行
(limited direct execution) LDE, 只需直接在CPU上运行程序即可 - 使用正常的调用并返回跳转到程序的
main(),并在稍后回到内核。

- 实际并没有怎么简单 ,如果对运行程序没有限制,
操作系统将无法控制任何事情,因此会成为“仅仅是一个库” 。
问题 1:受限制的操作(特权问题 )
- 硬件与操作系统存在的问题 : 关键问题:如何执行受限制的操作??
提示:采用受保护的控制权转移
硬件通过提供不同的执行模式来协助操作系统。在用户模式(user mode)下,应用程序不能完全访问硬件资源。在内核模式(kernel mode)下,操作系统可以访问机器的全部资源。还提供了陷入(trap)内核和从陷阱返回(return-from-trap)到用户模式程序的特别说明,以及一些指令,让操作系统告诉硬件陷阱表(trap table)在内存中的位置。我们采用的方法是引入新的处理器模式:
用户模式(user mode)
在用户模式下运行的代码会
受到限制。例如,在用户模式下运行时,进程不能发出 I/O 请求。这样做会导致处理器引发异常,操作系统可能会终止进程。内核模式(kernel mode)
操作系统(或内核)就以这种模式运行。在此模式下,运行的代码可以做它喜欢的事,包括
特权操作,如发出 I/O 请求和执行所有类型的受限指令。系统调用 (system call)
系统调用允许内核小心地向用户程序暴露某些关键功能,例如访问文件系统、创建和销毁进程、与其他进程通信,以及分配更多内存。。
如果用户希望执行某种特权操作(如从磁盘读取),可以借助硬件提供的系统调用功能。
要执行系统调用,程序必须执行特殊的陷阱(trap)指令。该指令同时跳入内核并将特权级别提升到内核模式。一旦进入内核,系统就可以执行任何需要的特权操作(如果允许),从而为调用进程执行所需的工作。完成后,操作系统调用一个特殊的从陷阱返回(return-from-trap)指令,如你期望的那样,该指令返回到发起调用的用户程序中,同时将特权级别降低,回到用户模式。
执行陷阱时,硬件需要小心,因为它必须确保存储足够的调用者寄存器,以便在操作系统发出从陷阱返回指令时能够正确返回。陷阱如何知道在
OS内运行哪些代码? 内核通过在启动时设置陷阱表(trap table)来实现.陷阱表(trap table)
内核通过在启动时设置
陷阱表(trap table)来实现陷阱地址的初始化。
当机器启动时,系统在特权(内核)模式下执行,因此可以根据需要自由配置机器硬件。操作系统做的第一件事,就是告诉硬件在发生某些异常事件时要运行哪些代码。例如,当发生硬盘中断,发生键盘中断或程序进行系统调用时,应该运行哪些代码?
操作系统通常通过某种特殊的指令,通知硬件这些陷阱处理程序的位置。一旦硬件被通知,它就会记住这些处理程序的位置,直到下一次重新启动机器,并且硬件知道在发生系统调用和其他异常事件时要做什么(即跳转到哪段代码)。 提高安全性!!

问题 2:在进程之间切换
关键问题:如何重获
CPU的控制权, 操作系统如何重新获得CPU的控制权(regain control),以便它可以在进程之间切换?协作方式:等待系统调用
- 运行时间过长的进程被假定会定期放弃
CPU - 系统调用
- eg、
yield
非协作方式:时钟中断
时钟中断(timer interrupt)。时钟设备可以编程为每隔几毫秒产生一次中断。产生中断时,当前正在运行的进程停止,操作系统中预先配置的中断处理程序(interrupt handler)会运行。此时,操作系统重新获得 CPU 的控制权,因此可以做它想做的事:停止当前进程,并启动另一个进程。
请注意,硬件在发生中断时有一定的责任,尤其是在中断发生时,要为正在运行的程序保存足够的状态,以便随后从陷阱返回指令能够正确恢复正在运行的程序。该操作可以视为隐式的操作,与显式的系统调用很相似。保存和恢复上下文
- 当操作系统通过上述两种方式获取控制权后,就可以决定是否切换进程,这个决定是由
调度程序做出 - 当操作系统决定切换进程时,需要首先进行
上下文切换(context switch),就是为当前正在执行的进程保存一些寄存器的值(例如,到它的内核栈),并为即将执行的进程恢复一些寄存器的值(从它的内核栈)。这样一来,操作系统就可以确保最后执行从陷阱返回指令时,不是返回到之前运行的进程,而是继续执行另一个进程。
上下文切换并不仅仅保存和恢复寄存器,还包含了其他操作,如页表的切换等。
-
操作系统决定从正在运行的进程 A 切换到进程 B。此时,它调用
switch()例程, 该例程仔细保存当前寄存器的值(保存到A的进程结构),恢复寄存器进程 B(从它的进程 结构),然后切换上下文(switch context),具体来说是通过改变栈指针来使用 B的内核栈(而 不是A的)。最后,操作系统从陷阱返回,恢复 B 的寄存器并开始运行它。

-
xv6 的上下文切换代码 :
OS_CPU_PendSVHandler: CPSID I @ Prevent interruption during context switch MRS R0, PSP @ PSP is process stack pointer CMP R0, #0 BEQ OS_CPU_PendSVHandler_nosave @ equivalent code to CBZ from M3 arch to M0 arch @ Except that it does not change the condition code flags SUBS R0, R0, #0x10 @ Adjust stack pointer to where memory needs to be stored to avoid overwriting STM R0!, {R4-R7} @ Stores 4 4-byte registers, default increments SP after each storing SUBS R0, R0, #0x10 @ STM does not automatically call back the SP to initial location so we must do this manually LDR R1, =OSTCBCur @ OSTCBCur->OSTCBStkPtr = SP; LDR R1, [R1] STR R0, [R1] @ R0 is SP of process being switched out @ At this point, entire context of process has been saved- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
问题原因:
代码优化时将 rbuf_len 保存在了寄存器 r8 上,在进行上下文切换时,r8 寄存器没有被保存,导致 r8 寄存器的值被其他进程修改,切换回本进程后,r8 的值也无法恢复。思考:并发对中断的影响
处理一个中断时发生另一个中断,会发生什么?
一种方法是,在中断处理期间禁止中断(disable interrupt)。这样做可以确保在处理一个中断时,不会将其他中断交给 CPU。当然,操作系统这样做必须小心。禁用中断时间过长可能导致丢失中断,这(在技术上)是不好的。提示:重新启动是有用的 , 重启后 OS 首先(在启动时)设置陷阱处理程序并启动时钟中断,然后仅在受限 模式下运行进程.操作系统能确信进程可以高效运行, 只在执行特权操作,或者当它们独占CPU时间过长并因此需要切换时,才需要操作系统干预。
思考:上下文切换的消耗
你可能有一个很自然的问题:上下文切换需要多长时间?甚至系统调用要多长时间?如果感到好奇,有一种称为 lmbench的工具,可以准确衡量这些事情,并提供其他一些可能相关的性能指标。随着时间的推移,结果有了很大的提高,大致跟上了处理器的性能提高。例如,1996 年在 200-MHz P6 CPU 上运行 Linux 1.3.37,
系统调用花费了大约 4μs,上下文切换时间大约为 6μs。现代系统的性能几乎可以提高一个数量级,在具有2 GHz 或 3 GHz 处理器的系统上的性能可以达到亚微秒级。应该注意的是,并非所有的操作系统操作都会跟踪CPU的性能。正如Ousterhout所说的,许多操作系统操作都是内存密集型的,而随着时间的推移,内存带宽并没有像处理器速度那样显著提高。因此,根据你的工作负载,购买最新、性能好的处理器可能不会像你希望的那样加速操作系统。(五) 进程调度:介绍
假设
关键问题:如何开发调度策略
我们该如何开发一个考虑调度策略的基本框架?什么是关键假设?哪些指标非常重要?哪些基本 方法已经在早期的系统中使用?工作负载
- 每一个工作运行相同的时间。
- 所有的工作同时到达。
- 一旦开始,每个工作保持运行直到完成。
- 所有的工作只是用 CPU(即它们不执行 IO 操作)。
- 每个工作的运行时间是已知的。
调度指标
任务的周转时间定义为任务完成时间减去任务到达系统的时间。更正式的周转时间定义 T_{周转时间} 是:
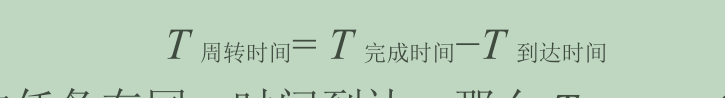
x因为我们假设所有的任务在同一时间到达,那么 T_{到达时间} = 0,因此 T_{周转时间}= T_{完成时间}。随着我们放宽上述假设,这个情况将改变先进先出(FIFO)
先进先出(First In First Out 或 FIFO)调度,有时候也称为先到先服务(First Come First Served 或 FCFS)。
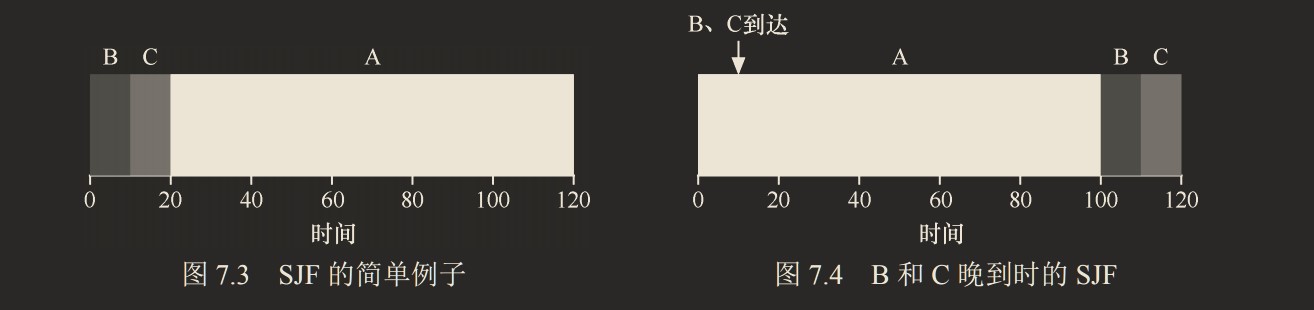
假设有三个几乎同时到达的进程,到达顺序为 A,B,C,B 和 C 执行 10s,A 有执行 10s 和执行 100s 的情况,调度结果如下图:
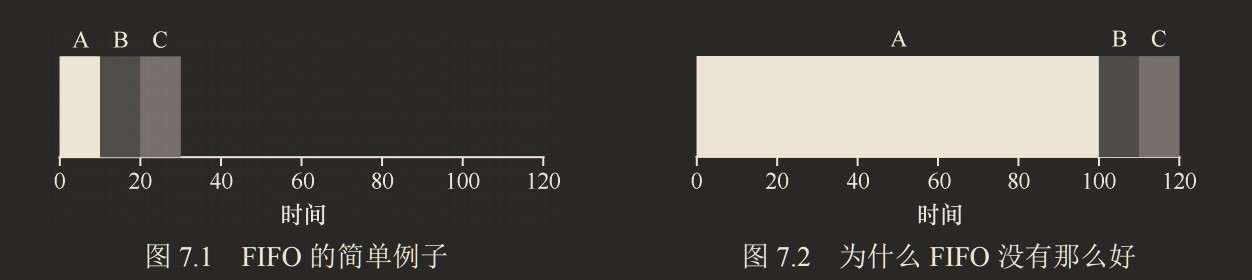
两者的平均周转周期- 左:(10 + 20 + 30)/3 = 20
- 右:(100 + 110 + 120)/3 = 110
这个时候就产生了一个问题被称为护航效应(convoy effect),一些耗时较少的潜在资源消费者被排在重量级的资源消费者之后。
最短任务优先(SJF)
最短任务优先(
Shortest Job First,SJF):先运行最短的任务,然后是次短的任务,如此下去
左图是在上一节条件下使用SJF策略时的表现,右图是在到达时间间隔10s条件下使用SJF策略时的表现:
两者的平均周转周期- 左:
(10 + 20 + 120)/3 = 50 - 右:
(100+(110−10)+(120−10))/3 = 103.33
从图中可以看出,当
ABC几乎同时到达时,SJF相较于FIFO有较好的表现,但当 B 和 C 在 A 之后不久到达,由于SJF无法抢占,它们仍然被迫等到 A 完成,从而遭遇同样的护航问题。补充:抢占式调度程序 : 几乎所有现代化的调度程序都是抢占式的(
preemptive),非常愿意 停止一个进程以运行另一个进程。调度程序可以 进行上下文切换,临时停止一个运行进程,并恢复(或启动)另一个进程。最短完成时间优先(STCF)
我们放宽第一节提出的假设条件 3(工作必须保持运行直到完成),也就是允许抢占
向 SJF 添加抢占,称为最短完成时间优先(Shortest Time-to-Completion First,STCF)OR 抢占式最短作业优先(Preemptive Shortest Job First ,PSJF)调度程序
每当新工作进入系统时,它就会确定剩余工作和新工作中,谁的剩余时间最少,然后调度该工作:
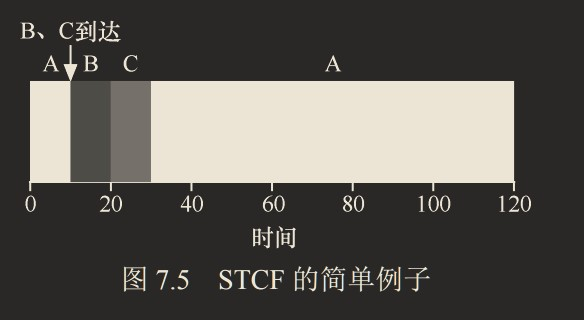
平均周转周期为:(120 + 10 + 20)/3 = 50新度量指标:响应时间
轮转(
Round-Robin,RR)调度:在一个时间片(time slice,有时称为调度量子,scheduling quantum)内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直到结束。它反复执行,直到所有任务完成。因此,RR 有时被称为时间切片(time-slicing)。
请注意,时间片长度必须是时钟中断周期的倍数。因此,如果时钟中断是每10ms中断一次,则时间片可以是 10ms、20ms 或 10ms 的任何其他倍数。
来看一个例子:假设 3 个任务 A、B 和 C 在系统中同时到达,并且它们都希望运行 5s。

平均响应时间:- SJF:(0 + 5 + 10)/ 3 = 5
- RR:(0 + 1 + 2)/3 = 1
SJF 调度程序必须运行完当前任务才可运行下一个任务。相比之下,1s 时间片的 RR 可以快速地循环工作
时间片长度
时间片长度对于 RR 是至关重要的。时间片长度越短,RR 在响应时间上表现越好。然而,时间片太短是有问题的:突然上下文切换的成本将影响整体性能。因此,系统设计者需要权衡时间片的长度,使其足够长,以便摊销(amortize)上下文切换成本,而又不会使系统不及时响应
请注意,上下文切换的成本不仅仅来自保存和恢复少量寄存器的操作系统操作。程序运行时,它们在CPU 高速缓存、TLB、分支预测器和其他片上硬件中建立了大量的状态。切换到另一个工作会导致此状态被刷新,且与当前运行的作业相关的新状态被引入,这可能导致显著的性能成本。结合 I/O
现在有俩项工作A,B , 当A在执行IO操作的时候, 执行B
首先,我们将放宽假设4:所有程序都不执行 I/O。
一种常见的方法是将A的每个10ms的子工作视为一项独立的工作。因此,当系统启动时,它的选择是调度10ms的A,还是 50ms 的 B。对于 最短完成时间优先(STCF),选择是明确的:选择较短的一个,在这种情况下是 A。然后,A 的工作已完成,只剩下 B,并开始运行。然后提交 A 的一个新子工作,它抢占 B 并运行10ms。这样做可以实现重叠(overlap),一个进程在等待另一个进程的I/O完成时使用 CPU,系统因此得到更好的利用

小结结我们开发了两种调度程序。
- 第一种类型(
SJF、STCF)优化周转时间,但对响应时间不利。 - 第二种类型(RR)优化响应时间,但对周转时间不利。
问题
1.使用 SJF 和 FIFO 调度程序运行长度为 200 的 3 个作业时,计算响应时间和周转
时间。2.现在做同样的事情,但有不同长度的作业,即 100、200 和 300。
3.现在做同样的事情,但采用 RR调度程序,时间片为 1。
4.对于什么类型的工作负载,SJF 提供与 FIFO 相同的周转时间?
5.对于什么类型的工作负载和量子长度,SJF 与 RR提供相同的响应时间?
6.随着工作长度的增加,SJF 的响应时间会怎样?你能使用模拟程序来展示趋势吗?
7.随着量子长度的增加,RR 的响应时间会怎样?你能写出一个方程,计算给定 N个 工作时,最坏情况的响应时间吗?
(六) 调度:多级反馈队列 (Multi-level Feedback Queue,MLFQ)
多级反馈队列需要解决两方面的问题。首先,它要优化周转时间。
提示:从历史中学习
多级反馈队列是用历史经验预测未来的一个典型的例子,操作系统中有很多地方采用了这种技术(同样存在于计算机科学领域的很多其他地方,比如硬件的分支预测及缓存算法)。如果工作有明显的阶段性行为,因此可以预测,那么这种方式会很有效。当然,必须十分小心地使用这种技术,因为它可能出错,让系统做出比一无所知的时候更糟的决定。MLFQ:基本规则
MLFQ中有许多独立的队列(queue),每个队列有不同的优先级(priority level)。任何时刻,一个工作只能存在于一个队列中。MLFQ总是优先执行较高优先级的工作(即在较高级队列中的工作)。对于同一个队列中的任务,采用轮转调度。
MLFQ中工作优先级并不是固定的,而是会根据进程的行为动态调整优先级。例如,如果一个工作不断放弃CPU去等待键盘输入,这是交互型进程的可能行为,MLFQ因此会让它保持高优先级。相反,如果一个工作长时间地占用CPU,MLFQ会降低其优先级。
MLFQ的两条基本规则:- 规则 1:如果
A的优先级> B的优先级,运行A(不运行B)。 - 规则 2:如果
A的优先级= B的优先级,轮转运行A和B。

尝试 1:如何改变优先级
我们必须决定,在一个工作的生命周期中,MLFQ 如何改变其优先级(在哪个队列中)。要做到这一点,我们必须记得工作负载:既有运行时间很短、频繁放弃 CPU 的交互型工作,也有需要很多 CPU 时间、响应时间却不重要的长时间计算密集型工作。下面是我们第一次尝试优先级调整算法。
- 规则 3 :工作进入系统时,放在最高优先级(最上层队列)。
- 规则 4a:工作用完整个时间片后,降低其优先级(移入下一个队列)。
- 规则 4b:如果工作在其时间片以内主动释放 CPU,则优先级不变。
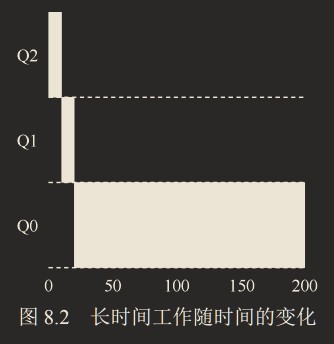
实例 1:单个长工作

从这个例子可以看出,该工作首先进入最高优先级(Q2)。执行一个10ms的时间片后,调度程序将工作的优先级减1,因此进入Q1。在Q1执行一个时间片后,最终降低优先级进入系统的最低优先级(Q0),并一直留在那里。实例 2:加入一个短工作

B 在 T=100 时到达
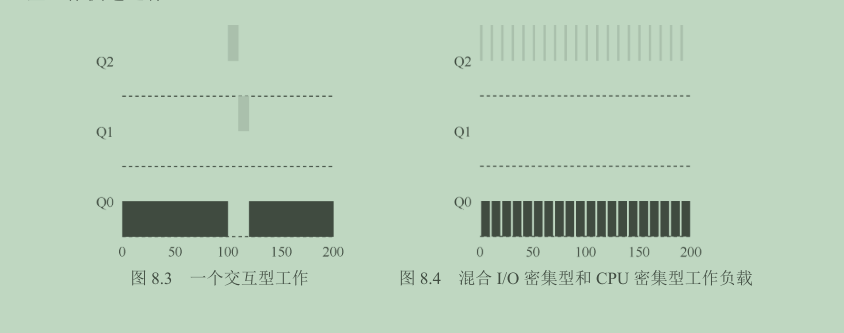
如果不知道工作是短工作还是长工作,那么就在开始的时候假设其是短工作,并赋予最高优先级。如果确实是短工作,则很快会执行完毕,否则将被慢慢移入低优先级队列,而这时该工作也被认为是长工作了。通过这种方式,MLFQ 近似于 SJF(最短任务优先)。实例 3:如果有 I/O 呢
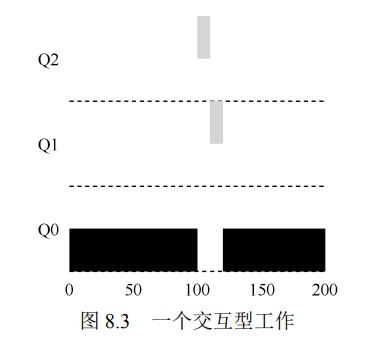
交互型工作 B(用灰色表示)每执行 1ms 便需要进行 I/O 操作,它与长时间运行的工作 A(用黑色表示)竞争 CPU。MLFQ 算法保持 B 在最高优先级,因为 B 总是让出 CPU。如果 B 是交互型工作,MLFQ 就进一步实现了它的目标,让交互型工作快速运行 。 (这样做容易出现饥饿)
当前 MLFQ 的一些问题 BUG
- 饥饿(starvation)问题。如果系统有“太多”交互型工作,就会不断占用 CPU,导致长工作永远无法得到 CPU(它们饿死了)。
- 愚弄调度程序(game the scheduler)。愚弄调度程序指的是用一些卑鄙的手段欺骗调度程序,让它给你远超公平的资源。上述算法对如下的攻击束手无策:进程在时间片用完之前,调用一个 I/O 操作(比如访问一个无关的文件),从而主动释放 CPU。如此便可以保持在高优先级,占用更多的 CPU 时间。
- 一个程序可能在不同时间表现不同。一个计算密集的进程可能在某段时间需要作为一个交互型的进程。用我们目前的方法,它不会享受系统中其他交互型工作的待遇。因为优先级一旦下降就无法提升
尝试 2:提升优先级
为解决[1]饥饿问题
- 规则 5:经过一段时间
S,就将系统中所有工作重新加入最高优先级队列。
eg :
- 左边没有优先级提升,长工作在两个短工作到达后被饿死。
- 右边每 50ms 就有一次优先级提升(这里只是举例,这个值可能过小),因此至少保证长工作会有一些进展,每过 50ms 就被提升到最高优先级,从而定期获得执行。
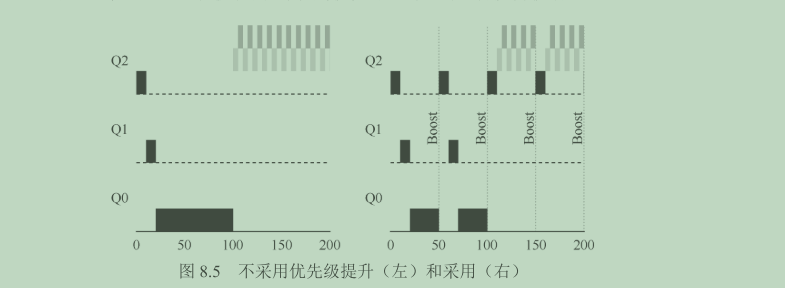
添加时间段 S 导致了明显的问题:S 的值应该如何设置?德高望重的系统研究员 John Ousterhout 曾将这种值称为“巫毒常量(voo-doo constant)”,因为似乎需要一些黑魔法才能正确设置。如果 S 设置得太高,长工作会饥饿;如果设置得太低,交互型工作又得不到合适的 CPU 时间比例。尝试 3:更好的计时方式
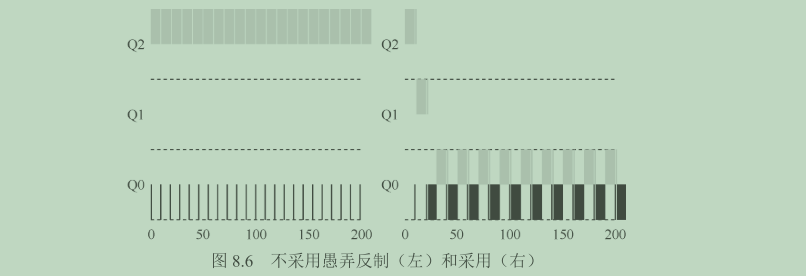
为解决[2]愚弄调度程序问题
起因是规则 4a 和 4b 不合理,调度程序应该记录一个进程在某一层中消耗的总时间,而不是在调度时重新计时。
重写规则 4:- 规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级(移入低一级队列)。
没有规则 4的保护时,进程可以在每个时间片结束前发起一次 I/O 操作,从而垄断 CPU 时间。有了这样的保护后,不论进程的 I/O 行为如何,都会慢慢地降低优先级,因而无法获得超过公平的 CPU 时间比例。同时由于规则 5的存在,原来的交互性进程还是可以在之后提升优先级。
MLFQ 调优及其他问题
关于 MLFQ 调度算法还有一些问题。其中一个大问题是如何配置一个调度程序,例如:- 配置多少队列?
- 每一层队列的时间片配置多大?
- 为了避免饥饿问题以及进程行为改变,应该多久提升一次进程的优先级?
这些问题都没有显而易见的答案,因此只有利用对工作负载的经验,以及后续对调度程序的调优,才会导致令人满意的平衡。
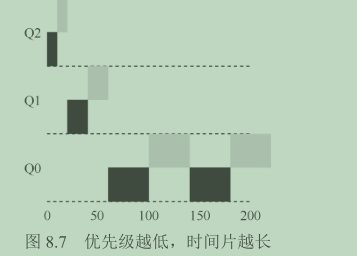
例如,大多数的MLFQ变体都支持不同队列可变的时间片长度。**高优先级队列**通常只有较短的时间片(比如10ms或者更少),因而这一层的交互工作可以更快地切换。相反,**低优先级队列**中更多的是CPU密集型工作,配置更长的时间片会取得更好的效果。图 8.7 展示了一个例子,两个长工作在高优先级队列执行 10ms,中间队列执行20ms,最后在最低优先级队列执行40ms。
Solaris 的 MLFQ 实现(时分调度类 TS)很容易配置。它提供了一组表来决定进程在其生命周期中如何调整优先级,每层的时间片多大,以及多久提升一个工作的优先级。管理员可以通过这些表,让调度程序的行为方式不同。该表默认有 60 层队列,时间片长度从 20ms(最高优先级),到几百 ms(最低优先级),每一秒左右提升一次进程的优先级。
最后,许多调度程序有一些我们没有提到的特征。例如,有些调度程序将最高优先级队列留给操作系统使用,因此通常的用户工作是无法得到系统的最高优先级的。有些系统允许用户给出优先级设置的建议(advice),比如通过命令行工具 nice,可以增加或降低工作的优先级(稍微),从而增加或降低它在某个时刻运行的机会。更多信息请查看 man 手册。
提示:尽可能多地使用建议
操作系统很少知道什么策略对系统中的单个进程和每个进程算是好的,因此提供接口并允许用户或管理员给操作系统一些提示(hint)常常很有用。我们通常称之为建议(advice),因为操作系统不一定要关注它,但是可能会将建议考虑在内,以便做出更好的决定。这种用户建议的方式在操作系统中的各个领域经常十分有用,包括调度程序(通过nice)、内存管理(madvise),以及文件系统(通知预取和缓存[P+95])MLFQ:小结
本章介绍了一种调度方式,名为多级反馈队列(MLFQ)。
本章包含了一组优化的 MLFQ 规则。为了方便查阅,我们重新列在这里。- 规则 1:如果 A 的优先级 > B 的优先级,运行 A(不运行 B)。
- 规则 2:如果 A 的优先级 = B 的优先级,轮转运行 A 和 B。
- 规则 3:工作进入系统时,放在最高优先级(最上层队列)。
- 规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级(移入低一级队列)。
- 规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
MLFQ 有趣的原因是:它不需要对工作的运行方式有先验知识,而是通过观察工作的运行来给出对应的优先级。通过这种方式,MLFQ 可以同时满足各种工作的需求:对于短时间运行的交互型工作,获得类似于 SJF/STCF 的很好的全局性能,同时对长时间运行的 CPU 密集型负载也可以公平地、不断地稳步向前。因此,许多系统使用某种类型的 MLFQ 作为自己的基础调度程序,包括类 BSD UNIX 系统、Solaris以及 Windows NT 和其后的 Window 系列操作系统。
作业
程序 mlfq.py 允许你查看本章介绍的 MLFQ 调度程序的行为。详情请参阅 README 文件。
- 只用两个工作和两个队列运行几个随机生成的问题。针对每个工作计算 MLFQ 的执行记录。限制每项作业的长度并关闭 I/O,让你的生活更轻松。
- 如何运行调度程序来重现本章中的每个实例?
- 将如何配置调度程序参数,像轮转调度程序那样工作?
- 设计两个工作的负载和调度程序参数,以便一个工作利用较早的规则 4a 和 4b(用-S 标志打开)来“愚弄”调度程序,在特定的时间间隔内获得 99%的 CPU。
- 给定一个系统,其最高队列中的时间片长度为 10ms,你需要如何频繁地将工作推回到最高优先级级别(带有-B 标志),以保证一个长时间运行(并可能饥饿)的工作得到至少 5%的 CPU?
- 调度中有一个问题,即刚完成 I/O 的作业添加在队列的哪一端。-I 标志改变了这个调度模拟器的这方面行为。尝试一些工作负载,看看你是否能看到这个标志的效果。
学习笔记(七) 调度:比例份额
本章将介绍一种不同的调度方法–比例份额(proportional-share)调度,有时也称为公平份额(fair-share)调度程序。比例份额算法基于一个简单的想法:调 度程序的最终目标,是确保每个工作获得一定比例的 CPU 时间,而不是优化周转时间和响 应时间。
比例份额调度程序有一个非常优秀的现代例子,由 Waldspurger 和 Weihl 发现,名为彩票调度(lottery scheduling)。基本思想很简 单:每隔一段时间,都会举行一次彩票抽奖,以确定接下来应该运行哪个进程。越是应该频繁运行的进程,越是应该拥有更多地赢得彩票的机会。基本概念:彩票数表示份额
彩票调度背后是一个非常基本的概念:彩票数(ticket)代表了进程(或用户或其他)占有某个资源的份额。一个进程拥有的彩票数占总彩票数的百分比,就是它占有资源的份额。
下面来看一个例子。假设有两个进程 A 和 B,A 拥有 75 张彩票,B 拥有 25 张。因此我们希望 A 占用 75%的 CPU 时间,而 B 占用 25%。
通过不断定时地(比如,每个时间片)抽取彩票,彩票调度从概率上(但不是确定的) 获得这种份额比例。抽取彩票的过程很简单:调度程序知道总共的彩票数(在我们的例子中,有 100 张)。调度程序随机抽取中奖彩票,这是从 0 和 99 之间的一个数,拥有这个数对应 的彩票的进程中奖。假设进程 A 拥有 0 到 74 共 75 张彩票,进程 B 拥有 75 到 99 的 25 张,中奖的彩票就决定了运行 A 或 B。调度程序然后加载中奖进程的状态,并运行它。
随机性决策优势:- 避免最差情况
- 轻量,不需要记录过多状态,传统公平调度需要记录进程的大量状态
- 随机方法很快,决策也快
下面是彩票调度程序输出的中奖彩票和对应的调度结果:
63 85 70 39 76 17 29 41 36 39 10 99 68 83 63 62 43 0 49 49 A A A A A A A A A A A A A A A A B B B B 从这个例子中可以看出,彩票调度中利用了随机性,这导致了从概率上满足期望的比例,但并不能确保。在上面的例子中,工作 B 运行了 20 个时间片中的 4 个,只是占了20%,而不是期望的25%。但是,这两个工作运行得时间越长,它们得到的 CPU 时间比例就会越接近期望。
彩票机制
彩票调度还提供了一些机制,以不同且有效的方式来调度彩票。一种方式是利用彩票货币(ticket currency)的概念。这种方式允许拥有一组彩票的用户以他们喜欢的某种货币, 将彩票分给自己的不同工作。之后操作系统再自动将这种货币兑换为正确的全局彩票。
比如,假设用户 A 和用户 B 每人拥有 100 张彩票。用户 A 有两个工作 A1 和 A2,他以自己的货币,给每个工作 500 张彩票货币(共 1000 张)。用户 B 只运行一个工作,给它 10 张彩票货币(总共 10 张)。操作系统将进行兑换,将 A1 和 A2 拥有的 A 的彩票货币 500 张,兑换成彩票 50 张。类似地,兑换给 B1 的 10 张彩票货币兑换成彩票 100 张。然后会对全局彩票货币(共 200 张)举行抽奖,决定哪个工作运行。User A -> 500 (A's ticket currency) to A1 -> 50 (global currency) -> 500 (A's ticket currency) to A2 -> 50 (global currency) User B -> 10 (B's ticket currency) to B1 -> 100 (global currency)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
另一个有用的机制是彩票转让(ticket transfer)。通过转让,一个进程可以临时将自己的彩票交给另一个进程。这种机制在客户端/服务端交互的场景中尤其有用,在这种场景中,客户端进程向服务端发送消息,请求其按自己的需求执行工作,为了加速服务端的执行,客户端可以将自己的彩票转让给服务端,从而尽可能加速服务端执行自己请求的速度。服务端执行结束后会将这部分彩票归还给客户端。这在客户端和服务端在同一台机器上运行时有用。
最后,彩票通胀(ticket inflation)有时也很有用。利用通胀,一个进程可以临时提升降低自己拥有的彩票数量。当然在竞争环境中,进程之间互相不信任,这种机制就没什么意义。一个贪婪的进程可能给自己非常多的彩票,从而接管机器。但是,通胀可以用于进程之间相互信任的环境。在这种情况下,如果一个进程知道它需要更多 CPU 时间,就可以增加自己的彩票,从而将自己的需求告知操作系统,这一切不需要与任何其他进程通信。实现
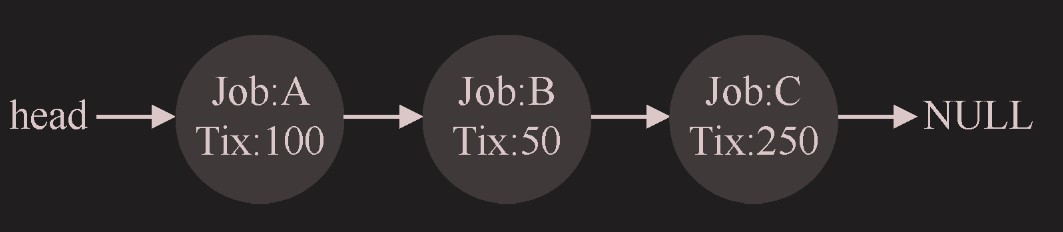
假定我们用列表记录进程。下面的例子中有 A、B、C 这 3 个进程,每个进程有一定数 量的彩票。
在做出调度决策之前,首先要从彩票总数 400 中选2021择一个随机数(中奖号码)。假设 选择了 300。然后,遍历链表,用一个简单的计数器帮助我们找到中奖者// counter: used to track if we've found the winner yet int counter = 0; // winner: use some call to a random number generator to get a value, between 0 and the total # of tickets int winner = getrandom(0, totaltickets); // current: use this to walk through the list of jobs node_t *current = head; // loop until the sum of ticket values is > the winner while (current) { counter = counter + current->tickets; if (counter > winner) break; // found the winner current = current->next; } // 'current' is the winner: schedule it...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这段代码从前向后遍历进程列表,将每张票的值加到 counter 上,直到值超过 winner。
A:100,B:50,C:250,总计 400 票,按照 A、B、C 的方式排序,如果摇到 1-100,则 A 中奖,101-150 则 B 中奖,151-400 则 C 中奖,符合概率分布。也就是 counter 递增的原理
要让这个过程更有效率,建议将列表项按照彩票数递减排序。这个顺序并不会影响算法的正确性,但能保证用最小的迭代次数找到需要的结点,尤其当大多数彩票被少数进程掌握时。评估方法
公平性
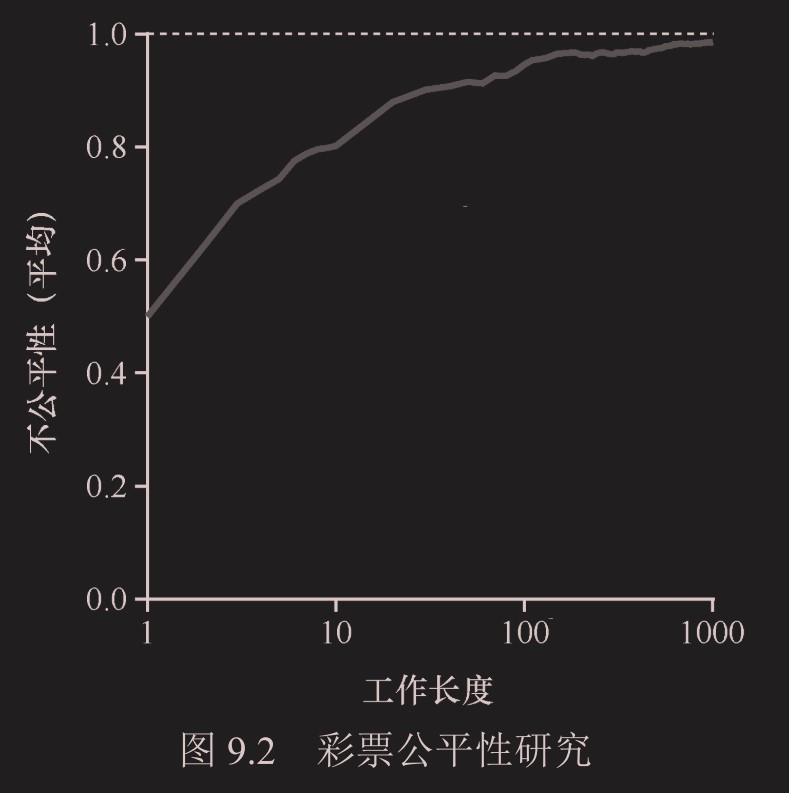
我们定义了一个简单的不公平指标U(unfairness metric),将两个工作完成时刻相除得到 U 的值。比如,运行时间 R 为 10,第一个工作在时刻 10 完成,另一个在 20,U=10/20=0.5。如果两个工作几乎同时完成,U 的值将很接近于 1。在这种情况下,我们的目标是:完美的公平调度程序可以做到U=1。
当工作执行时间很短时,平均不公平度非常糟糕。只有当工作执行非常多的时间片时,彩票调度算法才能得到期望的结果。步长调度
假设,A:100,B:50,C:250,总计 400 票,使用 10000 除以票数,得到步长A:100,B:200,C:40。每次程序被调度,每个工作对应的计数器累加得到行程值。
规则是总是调度行程值最低的工作,初始都是 0,则按顺序 A 执行,A 的行程值变为 100,BC 还为 0,则 B 运行,然后 C 运行,此时行程是 A:100,B:200,C:40,C 最小,则 C 再运行,直到 120,此时 A 为 100 最小,调度 A。
这种调度可以保证每个周期内绝对公平,但无法处理新进程插入后的情况小结
不能很好适应 I/O,票数分配规则没有好的方案
学习笔记(八) 多处理器调度(高级)
学习笔记(九) 抽象:地址空间
早期系统
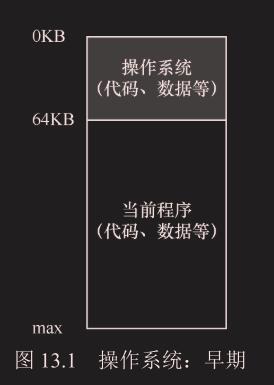
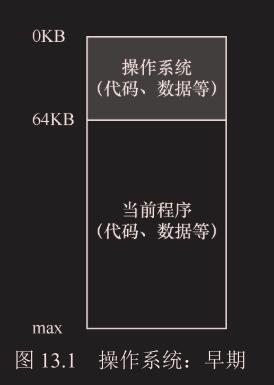
操作系统曾经是一组函数(实际上是一个库),在内存中(在本例中,从物理地址
0开始),然后有一个正在运行的程序(进程),
目前在物理内存中(在本例中,从物理地址64KB开始), 并使用剩余的内存。这里几乎没有抽象。
多道程序和时分共享

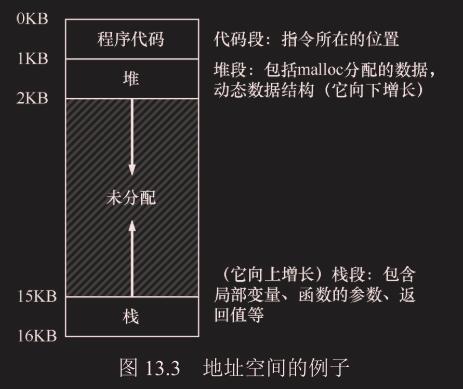
3 个进程(A、B、C),每个进程拥有从512KB物理内存中切出来给它们的一小部分内存。假定只有一 个CPU,操作系统 选择运行其中一个进程(比如A),同时其 他进程(B和C)则在队列中等待运行。地址空间
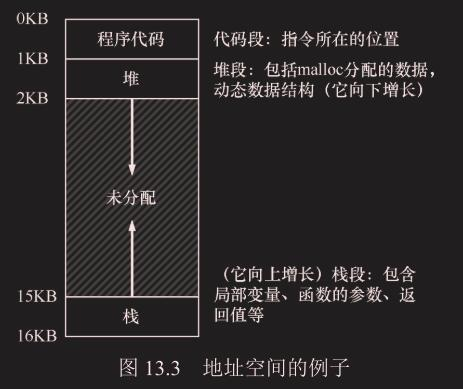
- **代码 : **程序代码位置,静态的
- **栈 : **向上增长,不一定放在底部
- **堆 :**向下增长,不一定放在代码段下
这个 0-16KB 的地址空间是虚拟的,不是实际的物理地址(0 物理地址一般是 boot 程序,不可能给一个用户程序用)
内存虚拟化也保证了隔离性和安全性。目标
- 透明:进程不知道自己运行在虚拟内存环境下,就好像地址都是物理地址一样
- 效率:虚拟化时不应该拖慢调度和运行时间,不应该占用更多内存
- 保护:不会影响操作系统和其他进程的内存空间
-
相关阅读:
当下社会和经济形势概述
基于51单片机的温度报警系统
Spring的RestTemplate、RPC和HTTP
docker
【语音去噪】谱减法+维纳滤波语音去噪(带面板+信噪比)【含GUI Matlab源码 1661期】
logrotate:日志分割、压缩、删除
数据结构笔记 4 树和二叉树
LLM探索:环境搭建与模型本地部署
HR坦言:不敢招聘5年开发经验的程序员?怎么回事?
2022亚太杯数学建模比赛准备
- 原文地址:https://blog.csdn.net/weixin_49486457/article/details/133438298