-
轻量自高斯注意力(LSGA)机制
light(轻量)Self-Gaussian-Attention vision transformer(高斯自注意力视觉transformer) for hyperspectral image classification(高光谱图像分类)
论文:Light Self-Gaussian-Attention Vision Transformer for Hyperspectral Image Classification
目录
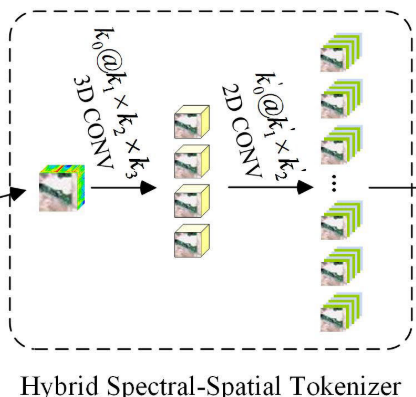
1. Hybrid Spectral–Spatial Tokenizer(混合谱-空间标记器)
2. Light Self-Attention Mechanism(轻量的自注意机制)
3. Gaussian Absolute Position Bias(高斯绝对位置偏差)
一、摘要
研究现状:近年来,卷积神经网络(convolutional neural networks,CNNs)由于其在局部特征提取方面的优异性能,在高光谱图像分类中得到了广泛的应用。然而,由于卷积核的局部连接和权值共享特性,cnn在长距离关系建模(远程依赖关系)方面存在局限性,而更深层次的网络往往会增加计算成本。
主要工作:针对这些问题,本文提出了一种基于轻量自高斯注意(light self-gauss-attention, LSGA)机制的视觉转换器(vision Transformer, VIT),提取全局深度语义特征。
1. 首先,空间-光谱混合标记器模块提取浅层空间-光谱特征,扩展图像小块生成标记。
2. 其次,轻自注意使用Q(查询)、X(原点输入),而不是Q、K(键)和V(值)来减少计算量和参数。
3. 此外,为了避免位置信息的缺乏导致中心特征和邻域特征混叠,我们设计了高斯绝对位置偏差来模拟HSI数据分布,使关注权值更接近中心查询块。
研究成果:多个实验验证了该方法的有效性,在4个数据集上的性能优于目前最先进的方法。具体来说,我们观察到A2S2K的准确率提高了0.62%,SSFTT 的准确率提高了 0.11%。综上所述,LSGA-VIT方法在HSI 分类中具有良好的应用前景,在解决位置感知远程建模和计算成本等问题上具有一定的潜力。
二、创新点
1) 作者使用混合空间-频谱标记器来代替patch嵌入,以保持输入图像patch的完整关系,并获得局部特征关系,使后续的VIT块,以实现全局特征提取。
2) LSGA-VIT模块被设计为联合收割机高斯位置信息和轻SA(LSA)机制,模拟场的中心位置和局部位置之间的关系。通过提高中心位置的谱特征权重,有效地减少了计算量和参数个数。
3) 该方法融合了全局和局部特征表达,有效地提高了HSI分类的准确率。烧蚀实验和对比实验均验证了该方法的有效性和优越性。
三、Method
LSGA-VIT框架,主要由混合谱-空间标记器、LSGA模块(轻量自高斯注意力模块)构成,如下图。
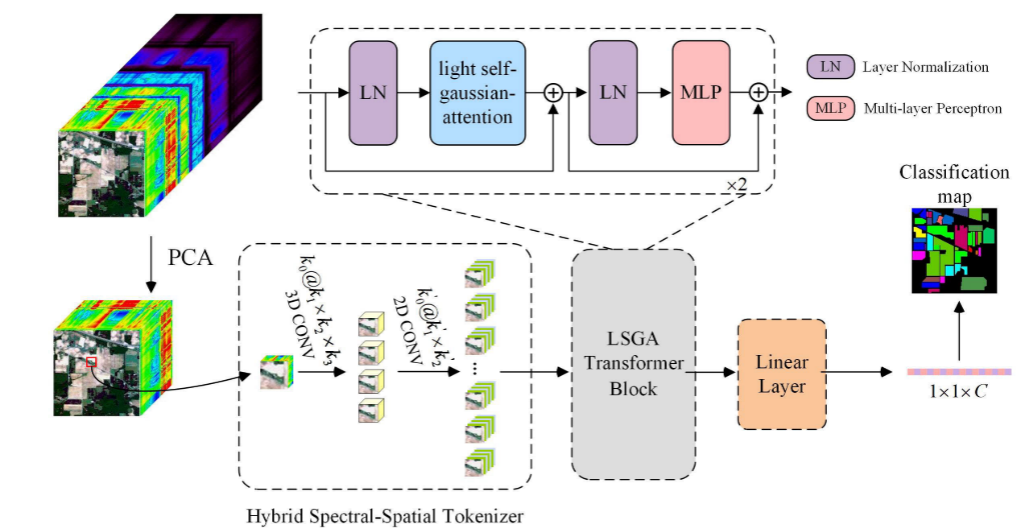
1. Hybrid Spectral–Spatial Tokenizer(混合谱-空间标记器)
输入:高光谱图像
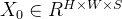 经过PCA(主成分分析法)降维后得到的
经过PCA(主成分分析法)降维后得到的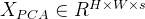 ,s代表图像的bands(图像的bands也叫通道)。
,s代表图像的bands(图像的bands也叫通道)。输入样本:再输入之前还要把图像裁剪为n个大小为h×w的样本
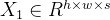 。
。过程:混合空间-频谱标记化模块,首先,将
 重塑为
重塑为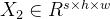 作为卷积层的输入。再利用3-D卷积层来提取空间-频谱特征。
作为卷积层的输入。再利用3-D卷积层来提取空间-频谱特征。第一层,3-D卷积层,从卷积到激活的定义如下:
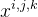 表示为在第m个卷积层的第n个特征图的像素位置
表示为在第m个卷积层的第n个特征图的像素位置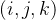 的激活值。
的激活值。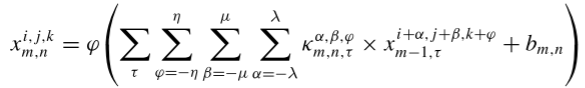
其中,
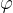 表示激活函数,
表示激活函数,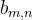 是偏置参数,
是偏置参数,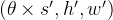 、
、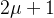 和
和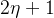 分别代表卷积核的通道数、高度和宽度,κ表示卷积核。为输入的3-D数据块数量,这里我们设= 1。 通过3-D卷积层后,合并前两个维度后,输出大小为,再输入到2-D卷积层中。
分别代表卷积核的通道数、高度和宽度,κ表示卷积核。为输入的3-D数据块数量,这里我们设= 1。 通过3-D卷积层后,合并前两个维度后,输出大小为,再输入到2-D卷积层中。第二层,2-D卷积层,从卷积到激活的定义如下:
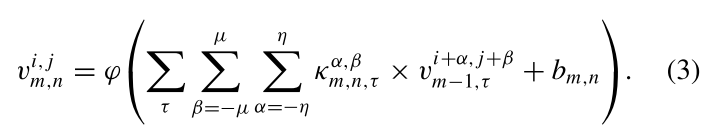
通过2-D卷积层后,输出空间的大小还原为原大小,输出大小为
。其中,其中 c′ 为线性投影输出通道数和patch嵌入维数。最后,将后两个维度展平并转置,获得
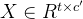 ,其中
,其中 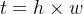 (
(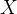 由t个token向量组成)。将向量长度为 c' 的 t 个token输入到LSGA Transformer模块。
由t个token向量组成)。将向量长度为 c' 的 t 个token输入到LSGA Transformer模块。Q:线性投影输出通道数?
接下来的LSGA模块中,包含线性的残差连接,也就是说输入、输出通道数是一致的,所以c′ 也可以说是接下来线性投影输出通道数。
Q:patch嵌入维数是什么?
transformer的patch embedding(嵌入)是指在模型中将图像分成固定大小的patchs,并通过线性变换得到每个patch的embedding(经过嵌入层的维度),嵌入维数也就是这个embedding的维度。
Q:token的作用?
将每个像素的直接展开作为token可以保持图像上每个点的空间相关性。
代码:
- class PatchEmbed(nn.Module):
- def __init__(self, img_size, patch_size, conv_embed_dim=4, in_chans=3, embed_dim=96, norm_layer=None):
- super().__init__()
- img_size = to_2tuple(img_size)
- patch_size = to_2tuple(patch_size)
- patches_resolution = [img_size[0], img_size[1]]
- self.img_size = img_size
- self.patch_size = patch_size
- self.patches_resolution = patches_resolution
- self.num_patches = patches_resolution[0] * patches_resolution[1]
- self.conv_embed_dim = conv_embed_dim
- self.in_chans = in_chans
- self.embed_dim = embed_dim
- self.conv3d_features = nn.Sequential(
- nn.Conv3d(1, out_channels=conv_embed_dim, kernel_size=(3, 3, 3), padding=1, stride=1),
- nn.BatchNorm3d(conv_embed_dim),
- nn.ReLU(),
- )
- self.conv2d_features = nn.Sequential(
- nn.Conv2d(in_channels=in_chans * conv_embed_dim, out_channels=embed_dim, kernel_size=(3, 3), padding=1,
- stride=1),
- nn.BatchNorm2d(embed_dim),
- nn.ReLU(),
- )
- self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, padding=1, stride=1)
- if norm_layer is not None:
- self.norm = norm_layer(embed_dim)
- else:
- self.norm = None
- def forward(self, x):
- B, C, H, W = x.shape
- # FIXME look at relaxing size constraints
- assert H == self.img_size[0] and W == self.img_size[1], \
- f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
- x = x.unsqueeze(1) # 扩展维度, [b, 1, 36, w, h]
- x = self.conv3d_features(x) # 3-D卷积层, [b, 4, 36, w, h]
- x = x.view(B, -1, H, W) # 合并前两个维度,方便输入2-D卷积层, [b, 144, w, h]
- x = self.conv2d_features(x) # 2-D卷积层, [b, 96, w, h]
- x = x.flatten(2).transpose(1, 2) # 将后两个维度展平并转置,得到长度为96的w*h个token向量, [b, w*h, 96]
- # x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
- if self.norm is not None:
- x = self.norm(x) # 归一化,来减少样本不平衡对分类精度的影响, [b, w*h, 96]
- return x
- def flops(self):
- Ho, Wo = self.patches_resolution
- flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
- if self.norm is not None:
- flops += Ho * Wo * self.embed_dim
- return flops
2. Light Self-Attention Mechanism(轻量的自注意机制)
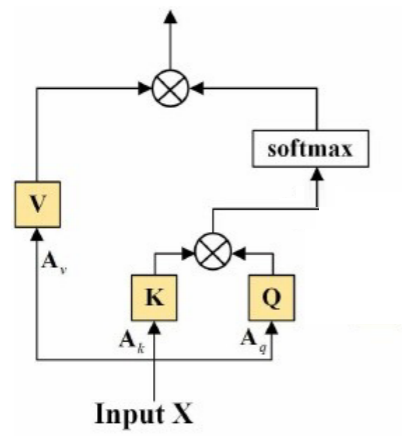
传统自注意力机制:
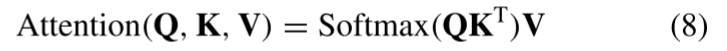
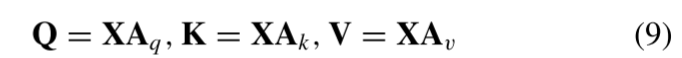
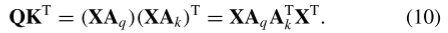
其中,
是权重矩阵(没错,就是权重矩阵,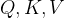 也可以通过线性层获得)。
也可以通过线性层获得)。 简化过程推导:
令
,A是一个权重矩阵。公式10简化为: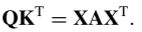
令
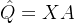 ,则
,则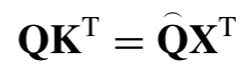
由于
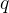 和
和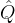 都是由X变换得到的,因此我们直接把看作,则
都是由X变换得到的,因此我们直接把看作,则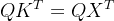
-----------------------------------------(简化掉了权重矩阵
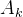 ,分支头
,分支头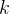 只输入一个X,不再进行操作)------------------------------------
只输入一个X,不再进行操作)------------------------------------再令
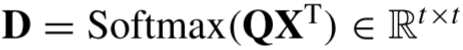 ,则
,则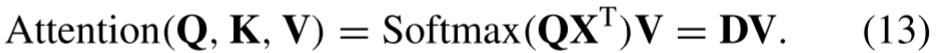
根据公式9,可得
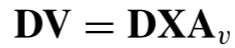
作者在注意力框架末尾多增加了一个线性层
 ,
,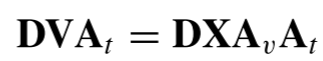
令
,则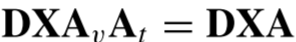
令
,也就是说末尾的线性操作和分支头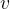 的线性操作
的线性操作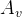 可进行合并,作者使用线性操作代替,换句话说,线性层移到了框架末尾(框架末尾不属于计算式之内),因此分支头不再进行操作,最终得到下面的定义。
可进行合并,作者使用线性操作代替,换句话说,线性层移到了框架末尾(框架末尾不属于计算式之内),因此分支头不再进行操作,最终得到下面的定义。 -----------------------------------(将线性层
转移到了框架末尾,分支头只输入一个X,不再进行操作)-------------------------------最终,将线性层
移到了框架末尾,轻量的自注意机制定义如下: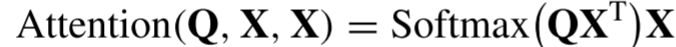
总结:经过公式推导简化,简化掉了
和,两个权重矩阵。3. Gaussian Absolute Position Bias(高斯绝对位置偏差)
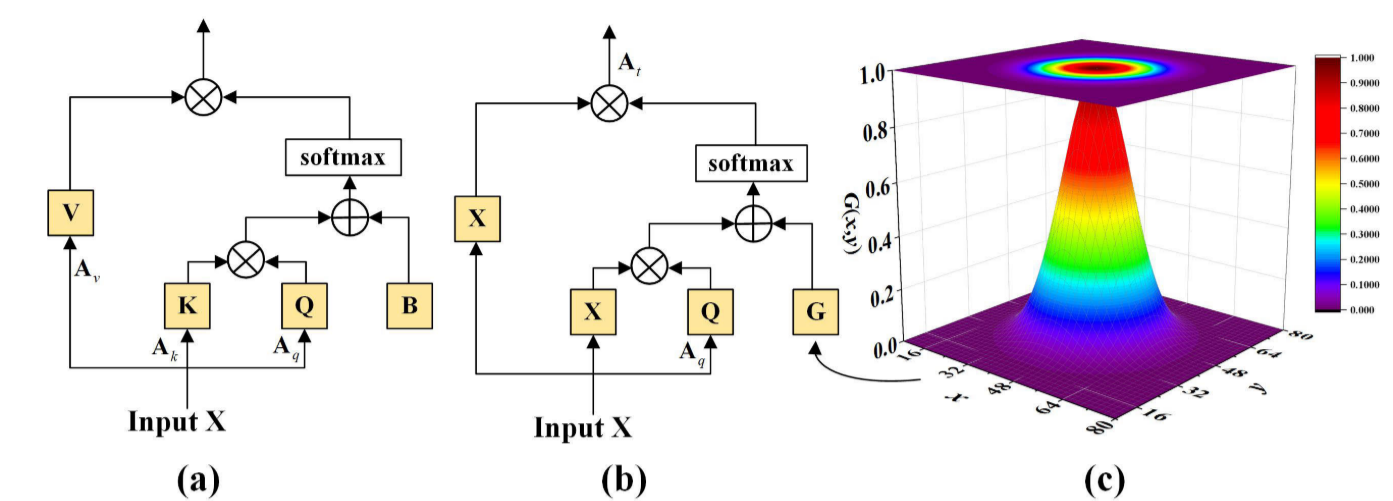
目的:由于Transform模型无法捕获标记(token)的位置信息,因此有必要添加表示相对或绝对位置的模块。
方法:在多头自注意力机制中,对每个头引入相对位置偏差参数。表示如下:
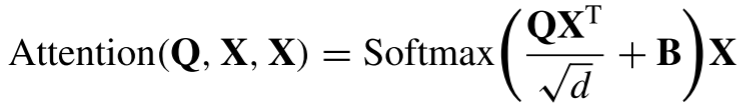
其中,d是多头注意机制中每个头的维度,
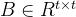 是相对位置偏差参数。
是相对位置偏差参数。因为,在本文中,不是从图像patch生成token,而是每个像素作为一个token,可以保留图像的空间关系。为了计算每一个像素的空间关系,采用2-D高斯函数来表示图像的空间关系,获取高斯绝对位置信息,以高斯绝对位置代替相对位置偏差,2-D高斯函数定义如下:
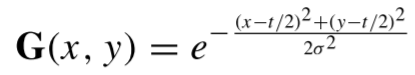
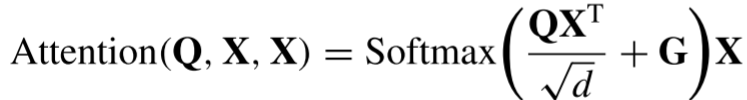
其中,σ是标准偏差,(x,y)表示空间位置坐标,G是高斯位置矩阵。
代码:
- ## 获取轻量的自高斯注意力
- class LSGAttention(nn.Module):
- def __init__(self, dim, att_inputsize, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
- super().__init__()
- self.dim = dim
- self.att_inputsize = att_inputsize[0]
- self.num_heads = num_heads
- head_dim = dim // num_heads
- self.scale = qk_scale or head_dim ** -0.5
- self.qkv = nn.Linear(dim, dim, bias=qkv_bias) # 线性层
- self.attn_drop = nn.Dropout(attn_drop) # 随机丢弃一些线性神经元,防止过拟合
- self.proj = nn.Linear(dim, dim) # 线性层
- self.proj_drop = nn.Dropout(proj_drop)
- self.softmax = nn.Softmax(dim=-1)
- totalpixel = self.att_inputsize * self.att_inputsize
- gauss_coords_h = torch.arange(totalpixel) - int((totalpixel - 1) / 2)
- gauss_coords_w = torch.arange(totalpixel) - int((totalpixel - 1) / 2)
- gauss_x, gauss_y = torch.meshgrid([gauss_coords_h, gauss_coords_w])
- sigma = 10
- gauss_pos_index = torch.exp(torch.true_divide(-(gauss_x ** 2 + gauss_y ** 2), (2 * sigma ** 2))) # 二维高斯函数
- self.register_buffer("gauss_pos_index", gauss_pos_index)
- self.token_wA = nn.Parameter(torch.empty(1, self.att_inputsize * self.att_inputsize, dim),
- requires_grad=True) # Tokenization parameters
- torch.nn.init.xavier_normal_(self.token_wA)
- self.token_wV = nn.Parameter(torch.empty(1, dim, dim),
- requires_grad=True) # Tokenization parameters
- torch.nn.init.xavier_normal_(self.token_wV)
- def forward(self, x, mask=None):
- B_, N, C = x.shape
- wa = repeat(self.token_wA, '() n d -> b n d', b=B_) # wa (bs 4 64)
- wa = rearrange(wa, 'b h w -> b w h') # Transpose # wa (bs 64 4)
- A = torch.einsum('bij,bjk->bik', x, wa) # A (bs 81 4)
- A = rearrange(A, 'b h w -> b w h') # Transpose # A (bs 4 81)
- A = A.softmax(dim=-1)
- VV = repeat(self.token_wV, '() n d -> b n d', b=B_) # VV(bs,64,64)
- VV = torch.einsum('bij,bjk->bik', x, VV) # VV(bs,81,64)
- x = torch.einsum('bij,bjk->bik', A, VV) # T(bs,4,64)
- absolute_pos_bias = self.gauss_pos_index.unsqueeze(0) # 获取高斯绝对位置信息
- q = self.qkv(x).reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # 分支头q进行线性变换
- k = x.reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # 分支头k,v直接输入一个x
- v = x.reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
- q = q * self.scale # 除以根号d,对注意力权重进行缩放,以确保数值的稳定性
- attn = (q @ k.transpose(-2, -1)) # 矩阵乘法,计算相似性矩阵
- attn = attn + absolute_pos_bias.unsqueeze(0) # 融合高斯绝对位置信息
- if mask is not None:
- nW = mask.shape[0]
- attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
- attn = attn.view(-1, self.num_heads, N, N)
- attn = self.softmax(attn)
- else:
- attn = self.softmax(attn) # softmax函数,进行归一化处理
- attn = self.attn_drop(attn) # 随机丢弃一些线性神经元,防止过拟合
- x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 融合注意力
- x = self.proj(x) # 最后再通过一个线性层
- x = self.proj_drop(x) # 随机丢弃,防止过拟合
- return x
- def extra_repr(self) -> str:
- return f'dim={self.dim}, num_heads={self.num_heads}'
4. LSGA transformer模块总述
LSGA transformer模块,如下图所示:
在LSGA Transformer模块中,对输入特征图进行层归一化,然后通过LSGA得到的
,再进行残差连接。之后,LSGA Transformer模块的末端顺序地执行归一化、MLP(多层感知机)和残差连接。在执行两次LSGA Transformer模块之后,最后,通过线性层将特征图展平以用于最终分类。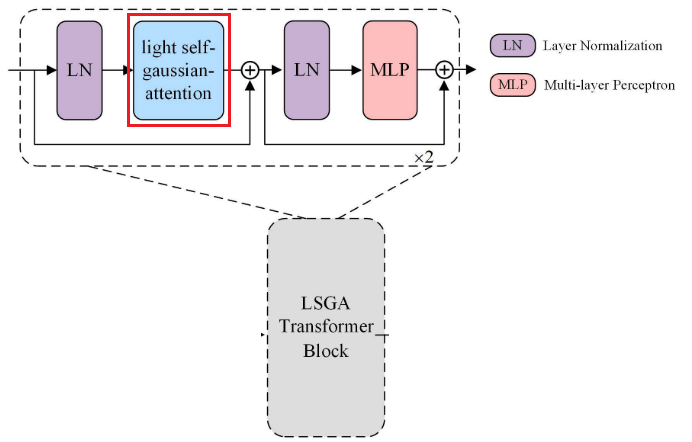
代码:
- ## 轻量的自高斯注意模块
- class LSGAVITBlock(nn.Module):
- def __init__(self, dim, input_resolution, num_heads,
- mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
- act_layer=nn.GELU, norm_layer=nn.LayerNorm,
- fused_window_process=False):
- super().__init__()
- self.dim = dim
- self.input_resolution = input_resolution
- self.num_heads = num_heads
- self.mlp_ratio = mlp_ratio
- self.norm1 = norm_layer(dim)
- self.attn = LSGAttention(
- dim, att_inputsize=input_resolution, num_heads=num_heads,
- qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
- self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() # 将深度学习模型中的多分支结构随机”删除“,将这些路径上的权重置为0,从而减少模型参数的数量,防止过拟合
- self.norm2 = norm_layer(dim)
- mlp_hidden_dim = int(dim * mlp_ratio)
- self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
- def forward(self, x):
- H, W = self.input_resolution
- B, L, C = x.shape
- assert L == H * W
- shortcut = x
- x = self.norm1(x) # 正则化层
- x = self.attn(x) # 获取轻量的自高斯注意力
- x = shortcut + self.drop_path(x) # 残差连接
- x = x + self.drop_path(self.mlp(self.norm2(x))) # 再经过正则化层 + MLP(多层感知机),再进行残差连接
- return x
- def extra_repr(self) -> str:
- return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
- f"mlp_ratio={self.mlp_ratio}"
四、实验
数据集:IP,Salinsa Scene(SA),Pavia University(PU)和Houston 2013(Houston)。
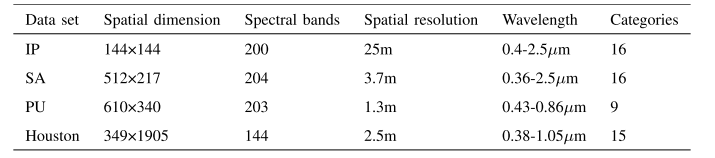
评价标准:总体准确率(OA)、平均准确率(AA)和Kappa系数(K)作为量化指标来验证LSGA-VIT的实验性能。
实验配置:所有实验都在配备有Intel Core I7- 10700 K CPU、RTX 2070 GPU和32-GB RAM的计算机上进行。本文中的所有实验训练集都设置为数据集的10%。
1. 消融实验
对比SA(自注意力)、LSA(轻量自注意力)、自高斯注意(self-Gaussian attention, SGA)和LSGA(轻量自高斯注意力)
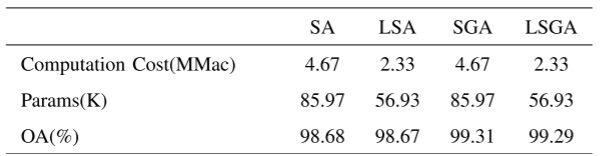
可以看到LSGA减少了 50%的计算量,减少了 30%的参数,仅损失了 0.02%的OA。
2. 对比实验
实验数据表明,该算法在4个数据集上均取得了较好的分类精度,尤其是在3个数据集上取得了最优的OA。
五、总结
1. 通过混合谱-空间标记器获得X(t个token向量),以保持图像上每个点的空间相关性,再传入LSGA模块融合注意力。
2. LSGA模块(轻量自高斯注意力模块)首先经过公式推导去除了分支头K,V中的线性操作
、。(没错这里是线性,作者采用线性变换而不是卷积来降低参数)3. 采用2-D高斯函数获取高斯绝对位置来提取像素间的空间关系。
六、代码实现
- import torch
- from einops import rearrange, repeat
- import torch.nn as nn
- import torch.utils.checkpoint as checkpoint
- from timm.models.layers import DropPath, to_2tuple, trunc_normal_
- from torchsummary import summary
- class Mlp(nn.Module):
- def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
- super().__init__()
- out_features = out_features or in_features
- hidden_features = hidden_features or in_features
- self.fc1 = nn.Linear(in_features, hidden_features)
- self.act = act_layer()
- self.fc2 = nn.Linear(hidden_features, out_features)
- self.drop = nn.Dropout(drop)
- def forward(self, x):
- x = self.fc1(x)
- x = self.act(x)
- x = self.drop(x)
- x = self.fc2(x)
- x = self.drop(x)
- return x
- ## 获取轻量的自高斯注意力
- class LSGAttention(nn.Module):
- def __init__(self, dim, att_inputsize, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
- super().__init__()
- self.dim = dim
- self.att_inputsize = att_inputsize[0]
- self.num_heads = num_heads
- head_dim = dim // num_heads
- self.scale = qk_scale or head_dim ** -0.5
- self.qkv = nn.Linear(dim, dim, bias=qkv_bias) # 线性层
- self.attn_drop = nn.Dropout(attn_drop) # 随机丢弃一些线性神经元,防止过拟合
- self.proj = nn.Linear(dim, dim) # 线性层
- self.proj_drop = nn.Dropout(proj_drop)
- self.softmax = nn.Softmax(dim=-1)
- totalpixel = self.att_inputsize * self.att_inputsize
- gauss_coords_h = torch.arange(totalpixel) - int((totalpixel - 1) / 2)
- gauss_coords_w = torch.arange(totalpixel) - int((totalpixel - 1) / 2)
- gauss_x, gauss_y = torch.meshgrid([gauss_coords_h, gauss_coords_w])
- sigma = 10
- gauss_pos_index = torch.exp(torch.true_divide(-(gauss_x ** 2 + gauss_y ** 2), (2 * sigma ** 2))) # 二维高斯函数
- self.register_buffer("gauss_pos_index", gauss_pos_index)
- self.token_wA = nn.Parameter(torch.empty(1, self.att_inputsize * self.att_inputsize, dim),
- requires_grad=True) # Tokenization parameters
- torch.nn.init.xavier_normal_(self.token_wA)
- self.token_wV = nn.Parameter(torch.empty(1, dim, dim),
- requires_grad=True) # Tokenization parameters
- torch.nn.init.xavier_normal_(self.token_wV)
- def forward(self, x, mask=None):
- B_, N, C = x.shape
- wa = repeat(self.token_wA, '() n d -> b n d', b=B_) # wa (bs 4 64)
- wa = rearrange(wa, 'b h w -> b w h') # Transpose # wa (bs 64 4)
- A = torch.einsum('bij,bjk->bik', x, wa) # A (bs 81 4)
- A = rearrange(A, 'b h w -> b w h') # Transpose # A (bs 4 81)
- A = A.softmax(dim=-1)
- VV = repeat(self.token_wV, '() n d -> b n d', b=B_) # VV(bs,64,64)
- VV = torch.einsum('bij,bjk->bik', x, VV) # VV(bs,81,64)
- x = torch.einsum('bij,bjk->bik', A, VV) # T(bs,4,64)
- absolute_pos_bias = self.gauss_pos_index.unsqueeze(0) # 获取高斯绝对位置信息
- q = self.qkv(x).reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # 分支头q进行线性变换
- k = x.reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # 分支头k,v直接输入一个x
- v = x.reshape(B_, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
- q = q * self.scale # 除以根号d,对注意力权重进行缩放,以确保数值的稳定性
- attn = (q @ k.transpose(-2, -1)) # 矩阵乘法,计算相似性矩阵
- attn = attn + absolute_pos_bias.unsqueeze(0) # 融合高斯绝对位置信息
- if mask is not None:
- nW = mask.shape[0]
- attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
- attn = attn.view(-1, self.num_heads, N, N)
- attn = self.softmax(attn)
- else:
- attn = self.softmax(attn) # softmax函数,进行归一化处理
- attn = self.attn_drop(attn) # 随机丢弃一些线性神经元,防止过拟合
- x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 融合注意力
- x = self.proj(x) # 最后再通过一个线性层
- x = self.proj_drop(x) # 随机丢弃,防止过拟合
- return x
- def extra_repr(self) -> str:
- return f'dim={self.dim}, num_heads={self.num_heads}'
- ## 轻量的自高斯注意模块
- class LSGAVITBlock(nn.Module):
- def __init__(self, dim, input_resolution, num_heads,
- mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
- act_layer=nn.GELU, norm_layer=nn.LayerNorm,
- fused_window_process=False):
- super().__init__()
- self.dim = dim
- self.input_resolution = input_resolution
- self.num_heads = num_heads
- self.mlp_ratio = mlp_ratio
- self.norm1 = norm_layer(dim)
- self.attn = LSGAttention(
- dim, att_inputsize=input_resolution, num_heads=num_heads,
- qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
- self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() # 将深度学习模型中的多分支结构随机”删除“,将这些路径上的权重置为0,从而减少模型参数的数量,防止过拟合
- self.norm2 = norm_layer(dim)
- mlp_hidden_dim = int(dim * mlp_ratio)
- self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
- def forward(self, x):
- H, W = self.input_resolution
- B, L, C = x.shape
- assert L == H * W
- shortcut = x
- x = self.norm1(x) # 正则化层
- x = self.attn(x) # 获取轻量的自高斯注意力
- x = shortcut + self.drop_path(x) # 残差连接
- x = x + self.drop_path(self.mlp(self.norm2(x))) # 再经过正则化层 + MLP(多层感知机),再进行残差连接
- return x
- def extra_repr(self) -> str:
- return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
- f"mlp_ratio={self.mlp_ratio}"
- class PatchMerging(nn.Module):
- def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
- super().__init__()
- self.input_resolution = input_resolution
- self.dim = dim
- self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
- self.norm = norm_layer(4 * dim)
- def forward(self, x):
- """
- x: B, H*W, C
- """
- H, W = self.input_resolution
- B, L, C = x.shape
- assert L == H * W, "input feature has wrong size"
- assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
- x = x.view(B, H, W, C)
- x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
- x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
- x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
- x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
- x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
- x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
- x = self.norm(x)
- x = self.reduction(x)
- return x
- def extra_repr(self) -> str:
- return f"input_resolution={self.input_resolution}, dim={self.dim}"
- def flops(self):
- H, W = self.input_resolution
- flops = H * W * self.dim
- flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
- return flops
- class BasicLayer(nn.Module):
- def __init__(self, dim, input_resolution, depth, num_heads,
- mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
- drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
- fused_window_process=False):
- super().__init__()
- self.dim = dim
- self.input_resolution = input_resolution
- self.depth = depth
- self.use_checkpoint = use_checkpoint
- # build blocks
- self.blocks = nn.ModuleList([
- LSGAVITBlock(dim=dim, input_resolution=input_resolution,
- num_heads=num_heads,
- mlp_ratio=mlp_ratio,
- qkv_bias=qkv_bias, qk_scale=qk_scale,
- drop=drop, attn_drop=attn_drop,
- drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
- norm_layer=norm_layer,
- fused_window_process=fused_window_process)
- for i in range(depth)])
- # patch merging layer
- if downsample is not None:
- self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
- else:
- self.downsample = None
- def forward(self, x):
- for blk in self.blocks:
- if self.use_checkpoint:
- x = checkpoint.checkpoint(blk, x)
- else:
- x = blk(x)
- if self.downsample is not None:
- x = self.downsample(x)
- return x
- def extra_repr(self) -> str:
- return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
- def flops(self):
- flops = 0
- for blk in self.blocks:
- flops += blk.flops()
- if self.downsample is not None:
- flops += self.downsample.flops()
- return flops
- ## 混合谱-空间标记器
- class PatchEmbed(nn.Module):
- def __init__(self, img_size, patch_size, conv_embed_dim=4, in_chans=3, embed_dim=96, norm_layer=None):
- super().__init__()
- img_size = to_2tuple(img_size)
- patch_size = to_2tuple(patch_size)
- patches_resolution = [img_size[0], img_size[1]]
- self.img_size = img_size
- self.patch_size = patch_size
- self.patches_resolution = patches_resolution
- self.num_patches = patches_resolution[0] * patches_resolution[1]
- self.conv_embed_dim = conv_embed_dim
- self.in_chans = in_chans
- self.embed_dim = embed_dim
- self.conv3d_features = nn.Sequential(
- nn.Conv3d(1, out_channels=conv_embed_dim, kernel_size=(3, 3, 3), padding=1, stride=1),
- nn.BatchNorm3d(conv_embed_dim),
- nn.ReLU(),
- )
- self.conv2d_features = nn.Sequential(
- nn.Conv2d(in_channels=in_chans * conv_embed_dim, out_channels=embed_dim, kernel_size=(3, 3), padding=1,
- stride=1),
- nn.BatchNorm2d(embed_dim),
- nn.ReLU(),
- )
- self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, padding=1, stride=1)
- if norm_layer is not None:
- self.norm = norm_layer(embed_dim)
- else:
- self.norm = None
- def forward(self, x):
- B, C, H, W = x.shape
- # FIXME look at relaxing size constraints
- assert H == self.img_size[0] and W == self.img_size[1], \
- f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
- x = x.unsqueeze(1) # 扩展维度, [b, 1, 36, w, h]
- x = self.conv3d_features(x) # 3-D卷积层, [b, 4, 36, w, h]
- x = x.view(B, -1, H, W) # 合并前两个维度,方便输入2-D卷积层, [b, 144, w, h]
- x = self.conv2d_features(x) # 2-D卷积层, [b, 96, w, h]
- x = x.flatten(2).transpose(1, 2) # 将后两个维度展平并转置,得到长度为96的w*h个token向量, [b, w*h, 96]
- # x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
- if self.norm is not None:
- x = self.norm(x) # 归一化,来减少样本不平衡对分类精度的影响, [b, w*h, 96]
- return x
- def flops(self):
- Ho, Wo = self.patches_resolution
- flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
- if self.norm is not None:
- flops += Ho * Wo * self.embed_dim
- return flops
- ## LSGAVIT主模块
- class LSGAVIT(nn.Module):
- def __init__(self, img_size, patch_size, in_chans, num_classes,
- embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
- mlp_ratio=4., qkv_bias=True, qk_scale=None,
- drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
- norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
- use_checkpoint=False, fused_window_process=False, **kwargs):
- super().__init__()
- self.num_classes = num_classes
- self.num_layers = len(depths)
- self.embed_dim = embed_dim
- self.ape = ape
- self.patch_norm = patch_norm
- self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
- self.mlp_ratio = mlp_ratio
- # split image into non-overlapping patches
- self.patch_embed = PatchEmbed(
- img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
- norm_layer=norm_layer if self.patch_norm else None)
- num_patches = self.patch_embed.num_patches
- patches_resolution = self.patch_embed.patches_resolution
- self.patches_resolution = patches_resolution
- # absolute position embedding
- if self.ape:
- self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
- trunc_normal_(self.absolute_pos_embed, std=.02)
- self.pos_drop = nn.Dropout(p=drop_rate)
- # stochastic depth
- dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
- # build layers
- self.layers = nn.ModuleList()
- for i_layer in range(self.num_layers):
- layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
- input_resolution=(patches_resolution[0] // (2 ** i_layer),
- patches_resolution[1] // (2 ** i_layer)),
- depth=depths[i_layer],
- num_heads=num_heads[i_layer],
- mlp_ratio=self.mlp_ratio,
- qkv_bias=qkv_bias, qk_scale=qk_scale,
- drop=drop_rate, attn_drop=attn_drop_rate,
- drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
- norm_layer=norm_layer,
- downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
- use_checkpoint=use_checkpoint,
- fused_window_process=fused_window_process)
- self.layers.append(layer)
- self.norm = norm_layer(self.num_features)
- self.avgpool = nn.AdaptiveAvgPool1d(1)
- self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
- self.apply(self._init_weights)
- def _init_weights(self, m):
- if isinstance(m, nn.Linear):
- trunc_normal_(m.weight, std=.02)
- if isinstance(m, nn.Linear) and m.bias is not None:
- nn.init.constant_(m.bias, 0)
- elif isinstance(m, nn.LayerNorm):
- nn.init.constant_(m.bias, 0)
- nn.init.constant_(m.weight, 1.0)
- @torch.jit.ignore
- def no_weight_decay(self):
- return {'absolute_pos_embed'}
- def forward_features(self, x):
- x = self.patch_embed(x) # 1. 获取token向量,即patch embedding
- if self.ape:
- x = x + self.absolute_pos_embed # 这里是一个线性残差,引入高斯绝对位置偏差
- x = self.pos_drop(x) # 随机丢弃一些线性神经元,防止过拟合,这里设为0
- for layer in self.layers:
- x = layer(x) # 2. 融合自注意力,调用 x -> LSGAVITBlock轻量高斯自注意力模块
- x = self.norm(x) # B L C
- x = self.avgpool(x.transpose(1, 2)) # B C 1
- x = torch.flatten(x, 1) # 3. 将特征图展平以用于最终分类
- return x
- def forward(self, x):
- x = self.forward_features(x)
- x = self.head(x)
- return x
- def flops(self):
- flops = 0
- flops += self.patch_embed.flops()
- for i, layer in enumerate(self.layers):
- flops += layer.flops()
- flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
- flops += self.num_features * self.num_classes
- return flops
- if __name__ == '__main__':
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- net = LSGAVIT(8, 3, 36, 16).to(device)
- # 打印网络结构和参数
- summary(net, ( 36, 8, 8))
-
相关阅读:
网络攻防实验 (by quqi99)
线上项目源码安全性处理方案
用DIV+CSS技术设计的餐饮美食网页与实现制作(web前端网页制作课作业)HTML+CSS+JavaScript美食汇响应式美食菜谱网站模板
使用vue3 和Springboot 通过 websocket实现前后端通信
【自然语言处理(NLP)】基于ERNIE-GEN的中文自动文摘
产品周报第33期|完善铁粉规则,优化原创保护策略,升级创作中心的数据展示,开放业界专家自定义域名权益……
html5
h5的扫一扫功能 (非微信浏览器环境下)
SSM基于微信小程序的实验室安全管理系统毕业设计-附源码031527
学生党蓝牙耳机怎么选?四款性价比高的蓝牙耳机推荐
- 原文地址:https://blog.csdn.net/qq_45981086/article/details/133436621
