-
玩转数据-大数据-Flink SQL 中的时间属性
一、说明
时间属性是大数据中的一个重要方面,像窗口(在 Table API 和 SQL )这种基于时间的操作,需要有时间信息。我们可以通过时间属性来更加灵活高效地处理数据,下面我们通过处理时间和事件时间来探讨一下Flink SQL 时间属性。
二、处理时间
2.1、准备WaterSensor类,方便使用
package com.lyh.bean; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @NoArgsConstructor @AllArgsConstructor public class WaterSensor { private String id; private Long ts; private Integer vc; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.2、DataStream 到 Table 转换时定义
处理时间属性可以在 schema 定义的时候用 .proctime 后缀来定义。时间属性一定不能定义在一个已有字段上,所以它新增一个字段。
代码段:package com.lyh.flink12; import com.lyh.bean.WaterSensor; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import static org.apache.flink.table.api.Expressions.$; public class Flink_Sql_Proctime { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<WaterSensor> waterSensorStream = env.fromElements(new WaterSensor("sensor_1", 1000L, 10), new WaterSensor("sensor_1", 2000L, 20), new WaterSensor("sensor_2", 3000L, 30), new WaterSensor("sensor_1", 4000L, 40), new WaterSensor("sensor_1", 5000L, 50), new WaterSensor("sensor_2", 6000L, 60)); // 1. 创建表的执行环境 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 声明一个额外的字段来作为处理时间字段 Table sensorTable = tableEnv.fromDataStream(waterSensorStream, $("id"), $("ts"), $("vc"), $("pt").proctime()); sensorTable.execute().print(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
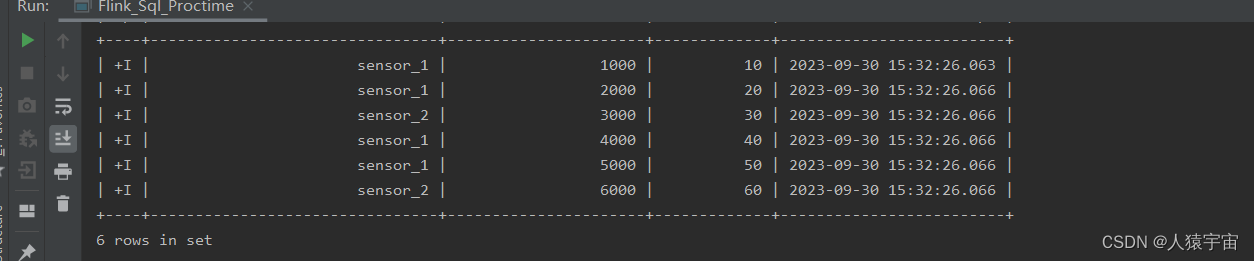
执行结果:
2.3、创建数据文件sensor.txt 数据,方便使用
sensor_1,1,10 sensor_1,2,20 sensor_2,4,30 sensor_1,4,400 sensor_2,5,50 sensor_2,6,60- 1
- 2
- 3
- 4
- 5
- 6
2.4、在创建表的 DDL 中定义
package com.lyh.flink12; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.TableResult; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; public class Flink_Sql_ddl_Procetime { public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); tableEnv.executeSql("create table sensor(id string,ts bigint,vc int,pt_time as PROCTIME()) with(" + "'connector' = 'filesystem'," + "'path' = 'input/sensor.txt'," + "'format' = 'csv'" + ")"); Table table = tableEnv.sqlQuery("select * from sensor"); table.execute().print(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
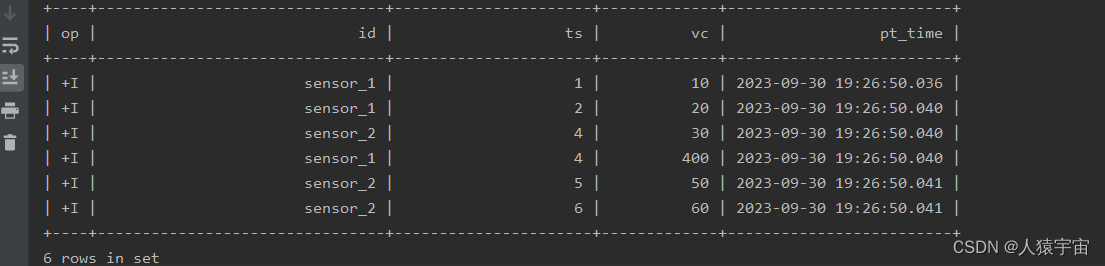
运行结果:
三、事件时间
事件时间允许程序按照数据中包含的时间来处理,这样可以在有乱序或者晚到的数据的情况下产生一致的处理结果。它可以保证从外部存储读取数据后产生可以复现(replayable)的结果。
除此之外,事件时间可以让程序在流式和批式作业中使用同样的语法。在流式程序中的事件时间属性,在批式程序中就是一个正常的时间字段。
为了能够处理乱序的事件,并且区分正常到达和晚到的事件,Flink 需要从事件中获取事件时间并且产生 watermark(watermarks)。3.1、DataStream 到 Table 转换时定义
事件时间属性可以用 .rowtime 后缀在定义 DataStream schema 的时候来定义。时间戳和 watermark 在这之前一定是在 DataStream 上已经定义好了。
在从 DataStream 到 Table 转换时定义事件时间属性有两种方式。取决于用 .rowtime 后缀修饰的字段名字是否是已有字段,事件时间字段可以是:
1、在 schema 的结尾追加一个新的字段
2、替换一个已经存在的字段。
不管在哪种情况下,事件时间字段都表示 DataStream 中定义的事件的时间戳。
代码:
援用上面WaterSensor类package com.lyh.flink12; import com.lyh.bean.WaterSensor; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import java.time.Duration; import static org.apache.flink.table.api.Expressions.$; public class Flink_Sql_EventTime { public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); SingleOutputStreamOperator<WaterSensor> waterSensorSource = env.fromElements( new WaterSensor("sensor_1", 1000L, 100), new WaterSensor("sensor_1", 1000L, 100), new WaterSensor("sensor_2", 1000L, 200), new WaterSensor("sensor_2", 1000L, 200) ).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner((element, recordtime) -> element.getTs())); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); tableEnv.fromDataStream(waterSensorSource,$("id"),$("ts"),$("vc"),$("pt").rowtime()) .execute().print(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
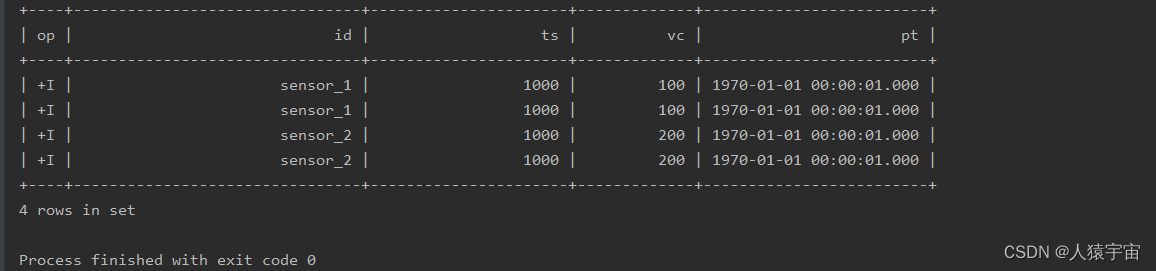
运行结果:
3.2、使用已有的字段作为时间属性
.fromDataStream(waterSensorStream, $("id"), $("ts").rowtime(), $("vc"));- 1
3.3、在创建表的 DDL 中定义
事件时间属性可以用 WATERMARK 语句在 CREATE TABLE DDL 中进行定义。WATERMARK 语句在一个已有字段上定义一个 watermark 生成表达式,同时标记这个已有字段为时间属性字段.
package com.lyh.flink12; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.TableResult; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; public class Flink_Sql_ddl_EventTime { public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); tableEnv.executeSql("create table sensor(" + "id string," + "ts bigint," + "vc int, " + "t as to_timestamp(from_unixtime(ts/1000,'yyyy-MM-dd HH:mm:ss'))," + "watermark for t as t - interval '5' second)" + "with(" + "'connector' = 'filesystem'," + "'path' = 'input/sensor.txt'," + "'format' = 'csv'" + ")"); tableEnv.sqlQuery("select * from sensor") .execute().print(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
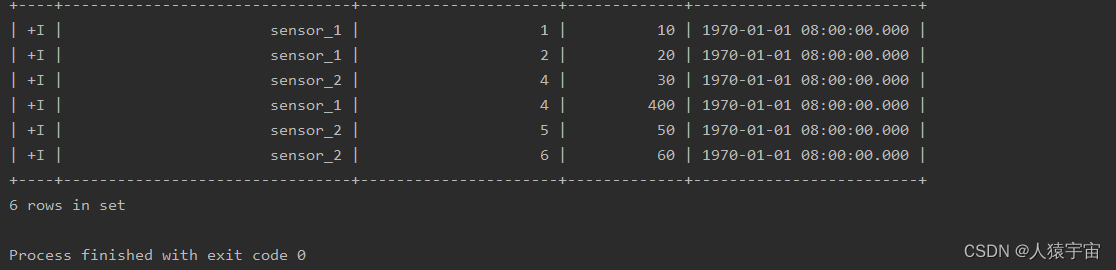
运行结果:
说明:
1.把一个现有的列定义为一个为表标记事件时间的属性。该列的类型必须为 TIMESTAMP(3),且是 schema 中的顶层列,它也可以是一个计算列。
2.严格递增时间戳: WATERMARK FOR rowtime_column AS rowtime_column。
3.递增时间戳: WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘0.001’ SECOND。
乱序时间戳: WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL ‘string’ timeUnit。 -
相关阅读:
如何成为不可替代的程序员?掌握这个方法,裁员名单永远没有你
【jvm】《尚硅谷宋红康JVM全套教程(详解java虚拟机)》上篇 笔记
心电信号导出呼吸频率的算法
SQL基础理论篇(三):数据表的创建原则
初识 Jenkins 持续集成
【Python机器学习】利用AdaBoost元算法提高分类性能——完整的AdaBoost算法的实现
【2023集创赛】加速科技杯作品:高光响应的二硫化铼光电探测器
Chrome 103支持使用本地字体,纯前端导出PDF优化
【暑期每日一题】洛谷 P6284 [COCI2016-2017#1] Tarifa
代码随想录笔记_动态规划_121买卖股票的最佳时机
- 原文地址:https://blog.csdn.net/s_unbo/article/details/133431403