-
面试官:Redis基本命令有哪些,Redis怎么实现分布式锁?
哈喽!大家好,我是奇哥,一位专门给面试官添堵的职业面试员
文章持续更新,可以微信搜索【小奇JAVA面试】第一时间阅读,回复【资料】更有我为大家准备的福利哟!一、Redis基本数据类型与使用场景
面试官:我看你简历上写的精通Redis?(哼,面试官轻蔑的一笑)
(看着面试官轻蔑的笑容,我忍不住拿出了我的Redis书籍推给了他)
我:这本书我倒背如流,你随便提问,答不上来算我输,答上来你就要为你的轻蔑向我道歉。

(我的笑容逐渐自信。。。)

(此时面试官看着书若有所思,我怀疑他肯定在想他对这本书的了解程度吧)
面试官:好吧,那先简单说一下Redis有哪些数据类型吧
我:redis主要有五种数据类型,分别是String、Hash、List、Set、ZSet。
面试官:那他们都是怎么存储和读取数据的呢,有哪些使用场景呢?
1、String
单值存储:set [key] [value]

取值:get [key]

多值存储:mset [key1] [value] [key2] [value]

取值:mget [key1] [key2]

分布式锁上锁:setnx [key] true
返回1代表上锁成功

返回0代表上锁失败

分布式锁释放锁:del [key]

设置超时时间:expire [key] [时间] (如果出现异常导致删除锁失败,可以设置超时时间,到达时间锁自动删除)

实现原子性分布式锁加锁并设置超时时间:set [key] true ex [时间] nx (如果上完锁在给锁设置超时时间之间出现异常,还是会导致锁无法删除,那么将上锁命令和设置超时时间命令合为一个命令)

计数器:incr [key]
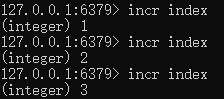
获取计数器的值:get [key]

批量获取计数:incrby [key]

获取计数器的值:get [key]

2、Hash
存储数据:hset [table] [key] [value] (这里我们可以假设实现向购物车中添加商品)
向购物车添加一个苹果

向购物车添加一本书

向购物车添加一个香蕉

在原有商品上加数量:hincrby [table] [key] [数量]
再向购物车中添加一个苹果

商品种类数量:hlen [table]
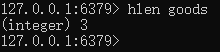
获取购物车所有的商品:hgetall [table]
删除商品:hdel [table] [key]

3、List
将一个值放入列表的头部(最左边):lpush [key] [value]
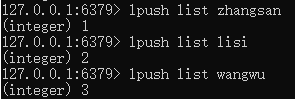
移除并返回列表的头元素:lpop [key]

将一个值放入列表的尾部(最右边):rpush [key] [value]

移除并返回列表的尾元素:rpop [key]

返回列表中指定区间内的元素:lrange [key] [开始位置] [结束位置]

从列表表头弹出一个元素,若列表中没有元素,阻塞等待time秒,如果time=0,一直阻塞等待

从列表表尾弹出一个元素,若列表中没有元素,阻塞等待time秒,如果time=0,一直阻塞等待

4、Set
往集合key中存入元素,元素存在则忽略,若key不存在则新建:sadd [key] [元素] (这里我们模仿一个抽奖的业务场景,先往集合中放入要抽奖的人)
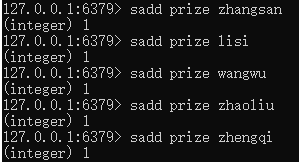
从集合key中随机选取几个元素,元素不从集合中删除:srandmember [key] [元素个数] (这里我们抽两个奖项)

获取集合key中所有元素:smembers [key]
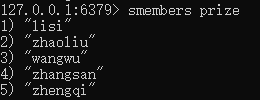
获取集合key中元素的个数:scard [key]

判断一元素是否存在于集合中:sismember [key] [元素]

从集合中删除元素:srem [key] [元素]

从集合中随机选出几个元素,并且删除:spop [key] [元素个数] (例如我们抽奖的时候先抽了三等奖,那么抽二等奖的时候三等奖的人就没有资格了,就要将三等奖的人删除)
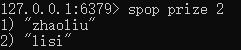
交集运算:sinter [key] [元素]

将交集结果存入新集合key2中:sinterstore [key2] [key] [元素]

并集运算:sunion [key] [元素]

将并集结果存入新集合key2中:sunionstore [key2] key [元素]

差集运算:sdiff [key] [运算]

将差集结果存入新集合key2中:sdiffstore [key2] [key] [元素]

5、ZSet
往有序集合key中加入带分值的元素:zadd [key] [分值] [元素] (业务中我们可以用来实现例如微博热搜排行的功能)
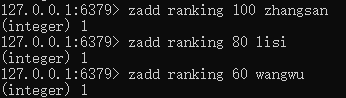
返回有序集合key中元素的分值:zscore [key] [元素]
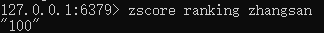
返回有序集合key中元素的个数:zcard [key]

为有序集合key中元素的分值加上一个分值:zincrby [key] [分值] [元素]

正序获取有序集合key从开始下标到结束下标的元素:zrange [key] [开始] [结束]
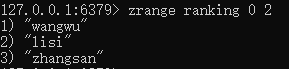
倒叙获取有序集合key从开始下标到结束下标的元素:zrevrange [key] [开始下标] [结束下标] (这里就是例如微博热搜榜中根据热度倒叙排序获取前十个)
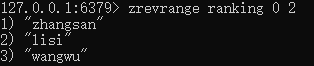
从有序集合key中删除元素:zrem [key] [元素]

(整理不易,性感小奇在线求赞。。。)

二、Redis日常问题
面试官:嗯。你上面写了那么多我也顾不上看,简单的问你几个问题吧
我:好
面试官:Redis中我们怎么创建分布式锁
我:使用setnx命令
面试官:Redis中创建分布式锁后出现异常解锁失败,怎么将这个锁删掉
我:可以使用expire来给锁加一个时间,过了这个时间后Redis自动将这个锁删掉。
面试官:如果在加时间之前就出现异常了,时间没有加上怎么办?
我:可以使用原子性的命令将分布式锁和时间一同创建出来,这样就不用担心异常了,因为原子性,一个成功都成功,一个失败都失败。

面试官:Redis是单线程的吗?
我:Redis在读写操作的时候是单线程的,但是其它功能,例如持久化、异步删除、集群数据同步等是有额外的线程执行的。
面试官:Redis单线程为什么还能这么快?
我:因为Redis的数据都在内存中,而且单线程避免了多线程的切换性能损耗问题。
面试官:Redis单线程如何处理并发客户端连接?
我:Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器中,事件分派器将事件分发给事件处理器。

面试官:我想全量查询Redis中所有key怎么查询,或者模糊查询符合规则的key怎么查询呢
我:使用 keys * 可以查询Redis中所有的key,如果要模糊查询直接加上规则即可,例如要查询前缀为小奇的key可以使用 keys 小奇* 来查询
面试官:这样查询有没有什么问题呢,有没有其他的解决方案呢?
我:使用 keys * 查询是全量查询Redis中的key值,如果key值过多的话最造成线程堵塞,因为Redis读写是单线程的,我们可以使用scan命令渐进式读取数据。
面试官:可以详细说一下scan命令吗?
我:scan命令的格式为:scan [游标] match [通配符] count [每一次查询的数量] (初始查询的时候游标为0,然后第二次查询游标为第一次查询时返回的数据,依次类推,最后游标返回0时表示查询完毕)
我现在Redis中一共有9条数据,我每次查询3条,分三次查询完毕。
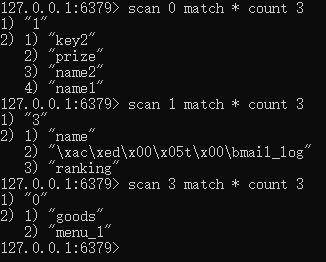
面试官:scan命令有什么缺点吗,一定能够完全获取全量的数据吗?
我:不一定,如果在scan的过程中有新的数据变化,例如插入数据,删除数据等,那么新增的键可能没有遍历到,因为scan遍历过的地方就不在遍历了,你插入到遍历过的地方就不会再遍历到。

面试官:小伙子真厉害啊,我这边没有什么要问的了,你还有什么问题要问(面试官两眼放光)
我:请问咱们这里上厕所会计时吗。。。
三、总结
这里关于Redis还没有整理完毕,文章后面持续更新,建议收藏。
文章中涉及到的命令大家一定要像我一样每个都敲几遍,只有在敲的过程中才能发现自己对命令是否真正的掌握了。
如果觉得我的文章还不错的话就点个赞吧,另外可以微信搜索【小奇JAVA面试】阅读更多的好文章,获取我为大家准备的资料。
-
相关阅读:
做接口测试的目的以及测试点
Python学习 - 异常处理
通义灵码牵手阿里云函数计算 FC ,打造智能编码新体验
猿创征文 |【MySQL数据库一SQL 语句】
正则表达式的限定符、或运算符、字符类、元字符、贪婪/懒惰匹配
基础算法篇——双指针算法
Blazor和Vue对比学习(基础1.7):传递UI片断,slot和RenderFragment
java基础 API Calendar类
敏捷交付的工程效能治理
Python文件操作
- 原文地址:https://blog.csdn.net/weixin_44096133/article/details/133363127