-
transformer系列3---transformer结构参数量统计
1 Embedding
NLP算法会使用不同的分词方法表示所有单词,确定分词方法之后,首先建立一个词表,词表的维度是词总数vocab_size ×表示每个词向量维度d_model(论文中dmodel默认值512),这是一个非常稀疏的矩阵。这样,对于Transformer的encoder输入的句子sentence,先用相应的分词方法转换成新的序列src_vocab,然后用每个词的id去前面的稀疏矩阵查表,通过查表(nn.Embedding)将该序列转换到新的向量空间,就是词嵌入的结果。Transformer的decoder输入(输出)同理,先用相应的分词方法转换成新的序列tgt_vocab,然后将该序列经过embedding转换到新的向量空间。
因此统计参数量时,应为词表的维度=vocab_size × d_model。2 Positional Encoding
位置编码同理,首先建立一个位置矩阵,维度是输入向量的最大长度src_max_len × dmodel,实际使用时候根据实际词长度n取前n个位置编码
因此,位置编码的参数量=src_max_len × dmodel。3 Transformer Encoder
3.1 单层EncoderLayer
3.1.1 MHA
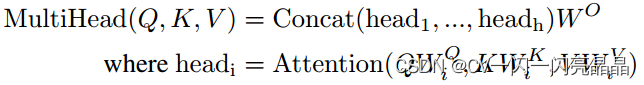
MHA包含 W Q , W K , W V W^{Q},W^{K},W^{V} WQ,WK,WV和输出的权重矩阵 W O W^{O} WO以及偏置, W Q , W K 维度是 d m o d e l × d k , W V 维度是 d m o d e l × d v W^{Q},W^{K}维度是dmodel × dk,W^{V}维度是dmodel × dv WQ,WK维度是dmodel×dk,WV维度是dmodel×dv,输出权重矩阵 W O 的维度是 ( h × d v ) × d m o d e l W^{O}的维度是(h×dv)×dmodel WO的维度是(h×dv)×dmodel,论文中dk = dv = dmodel/h = 64,头数h = 8。
- 一个头中3个矩阵的参数量是dmodel × dk + dmodel × dk + dmodel × dv= 3dk × dmodel
- h个头的参数量=h × 3 × dk × dmodel = 3 d m o d e l 2 3dmodel^{2} 3dmodel2
- 加上输出矩阵后的矩阵总参数量=(h × dv) × dmodel + 3dmodel × dmodel = 4 d m o d e l 2 4dmodel^{2} 4dmodel2
- 每个矩阵偏置维度是dmodel,4个矩阵的偏置=4dmodel
- MHA总参数量= 4 d m o d e l 2 + 4 d m o d e l 4dmodel^{2}+4dmodel 4dmodel2+4dmodel
3.1.2 layer normalization
layer normalization层的参数包含weight和bias,代码中nn.LayerNorm(dmodel),因此weight和bias的维度都是dmodel,参数量之和=2dmodel
3.1.3 MLP
由两个线性层组成,W1维度是(dmodel,4×dmodel),b1维度是4×dmodel,W2维度是(4×dmodel,dmodel),b2维度是dmodel,参数量为 dmodel×4×dmodel+4×dmodel+4×dmodel×dmodel+dmodel = 8 d m o d e l 2 + 5 d m o d e l 8dmodel^{2}+5dmodel 8dmodel2+5dmodel
3.1.4 layer normalization
同3.1.2,参数量之和=2dmodel
3.2 N层Encoderlayer总参数量
-
综上计算,Transformer中1层Encoderlayer的总参数量是 4 d m o d e l 2 + 4 d m o d e l + 2 d m o d e l + 8 d m o d e l 2 + 5 d m o d e l + 2 d m o d e l = 12 d m o d e l 2 + 13 d m o d e l 4dmodel^{2}+4dmodel+2dmodel+8dmodel^{2}+5dmodel+2dmodel=12dmodel^{2}+13dmodel 4dmodel2+4dmodel+2dmodel+8dmodel2+5dmodel+2dmodel=12dmodel2+13dmodel
-
论文中Encoderlayer的层数是N = 6 ,因此N层的Encoderlayer的参数量统计为 12 N d m o d e l 2 + 13 N d m o d e l 12Ndmodel^{2}+13Ndmodel 12Ndmodel2+13Ndmodel,实际中常常省略一次项,参数量统计= 12 N d m o d e l 2 12Ndmodel^{2} 12Ndmodel2。
4 Transformer Decoder
Decoder比Encoder多一层交叉多头注意力,以及一个layer normalization,但计算方式与Encoder相同,直接采用上面的结论
4.1 单层Decoderlayer
4.1.1 mask MHA
mask MHA总参数量= 4 d m o d e l 2 + 4 d m o d e l 4dmodel^{2}+4dmodel 4dmodel2+4dmodel
4.1.2 layer normalization
layer normalization参数量=2dmodel
4.1.3 交叉多头注意力
总参数量= 4 d m o d e l 2 + 4 d m o d e l 4dmodel^{2}+4dmodel 4dmodel2+4dmodel
4.1.4 layer normalization
layer normalization参数量=2dmodel
4.1.5 MLP
MLP参数量= 8 d m o d e l 2 + 5 d m o d e l 8dmodel^{2}+5dmodel 8dmodel2+5dmodel
4.1.6 layer normalization
layer normalization参数量=2dmodel
4.2 N层Decoderlayer总参数量
- 1层Decoderlayer参数量为上述计算之和, 4 d m o d e l 2 + 4 d m o d e l + 2 d m o d e l + 4 d m o d e l 2 + 4 d m o d e l + 2 d m o d e l + 8 d m o d e l 2 + 5 d m o d e l + 2 d m o d e l = 16 d m o d e l 2 + 19 d m o d e l 4dmodel^{2}+4dmodel+2dmodel+4dmodel^{2}+4dmodel+2dmodel+8dmodel^{2}+5dmodel+2dmodel=16dmodel^{2}+19dmodel 4dmodel2+4dmodel+2dmodel+4dmodel2+4dmodel+2dmodel+8dmodel2+5dmodel+2dmodel=16dmodel2+19dmodel
- N层Decoderlayer参数量= 16 N d m o d e l 2 + 19 N d m o d e l 16Ndmodel^{2}+19Ndmodel 16Ndmodel2+19Ndmodel
5 Transformer输出
Decoder输入输出向量的最大长度tgt_max_len,最后一层参数量=dmodel×tgt_max_len
Transformer的总参数量为上述5个部分的参数量之和。
-
相关阅读:
机器学习集成学习进阶Xgboost算法原理
【Spring Boot 源码学习】JedisConnectionConfiguration 详解
基于springboot+vue的学生评奖评优管理系统
python中yield浅析
SQL必需掌握的100个重要知识点:组合查询
Java文件输入输出(简单易懂版)
了解 OpenJDK 以及为什么要使用OpenJDK?
【机械臂、无人机规控篇】(9)机械臂轨迹规划、跟踪控制方向
LockSupport-park和unpark编码实战
13.从架构设计角度分析AAC源码-Room源码解析第2篇:RoomCompilerProcessing源码解析
- 原文地址:https://blog.csdn.net/lansebingxuan/article/details/133304411