-
协议-TCP协议-基础概念03-Keep live保活机制-TCP RST-TCP连接
Keep live保活机制-TCP RST-TCP连接
参考来源:
《极客专栏-网络排查案例课》Keep live保活机制
定时发送心跳探测包;
对于心跳回复包有超时限制;
要打开这个 TCP Keep-alive 特性,你需要使用 setsockopt() 系统调用,对已经创建的Socket 进行配置,启用 Keep-alive。具体的调用方法,你可以参考 man setsockopt。在 Linux 操作系统层级,也有三个跟 Keep-alive 有关的全局配置项。
间隔时间:net.ipv4.tcp_keepalive_time,其值默认为 7200(秒),也就是 2 个小时。
最大探测次数:net.ipv4.tcp_keepalive_probes,在探测无响应的情况下,可以发送的最多连续探测次数,其默认值为 9(次)。
最长间隔:net.ipv4.tcp_keepalive_intvl,在探测无响应的情况下,连续探测之间的最长间隔,其值默认为 75(秒)。
补充:你可以在 Linux 系统里面,执行 man tcp,查看内核对 TCP 协议栈的详细文档。这里我摘录一下关于 Keep-alive 的部分:
如果我们连接后启用了Keep-alive,但没有设定自定义的数值,那么就会便用上面这些默认值,即:当连接闲置(没有数据交互)送到7200秒(2小时)时发送心跳包,每次心跳包超时时间为75秒,最多重试9次。
这样的话,对于一个已经失效的 TCP 连接,最大需要 7200+75*9=7875 秒(约等于 2 小时 11 分钟)才能探测到。
毫无疑问,这个时间是相当长的。不过结合时代背景,这个其实也可以理解:TCP Keep-alive 被设计的时候是八十年代,当时因特网还很初级,所以设计者们并不想让心跳包占据太多的网络资源。从而,就有了这么一个感知时间很长的心跳机制。关于 TCP Keep-alive的一些更多信息在RFC1122里,你有兴趣的话可以去研究一下。
长连接失效、被重置、异常关闭等问题的排查思路:
我们需要先从应用层查找原因,然后是操作系统层面,最后是网络层分析。排查的顺序就是这样的:
应用层代码 -> 操作系统的时间配置 -> 网络的抓包分析TCP RST的三类原因
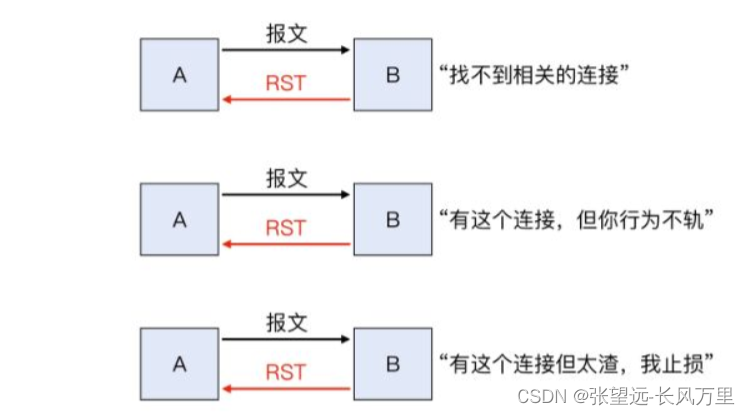
大体上,TCP RST 的原因可以分为这么几个大类:
找不到相关连接,那么接收端可以放心地直接发送 RST。
找到了相关连接,但收到的报文不符合 TCP 规范,那么接收端也可以发送 RST。
找到了相关连接,但传输状况恶劣,内核选择及时“止损”,发送 RST。
TCP连接
误区-一台机器最多 65535 个 TCP 连接
连接是四元组,并不是单纯的源端口或者目的端口。那么多个数相乘,这个乘积当然可以远远超过 65535 了。先不谈论海量级网站的场景,就算我们维护一台 Web 服务器,假如当前有 10 万台客户端连着你,平均每个客户端跟你有 6 个连接(这很常见),那么就是 60 万个连接了,是不是也早就超过 6 万了?
当然,在限定场景下,一个客户端(假设只有一个出口 IP)和一个服务端(假设也只有一个 IP 和一个服务端口),那么确实只能最多发起 6 万多个连接。但你自己也已经明白,这跟前面的误解,已经是两回事了。
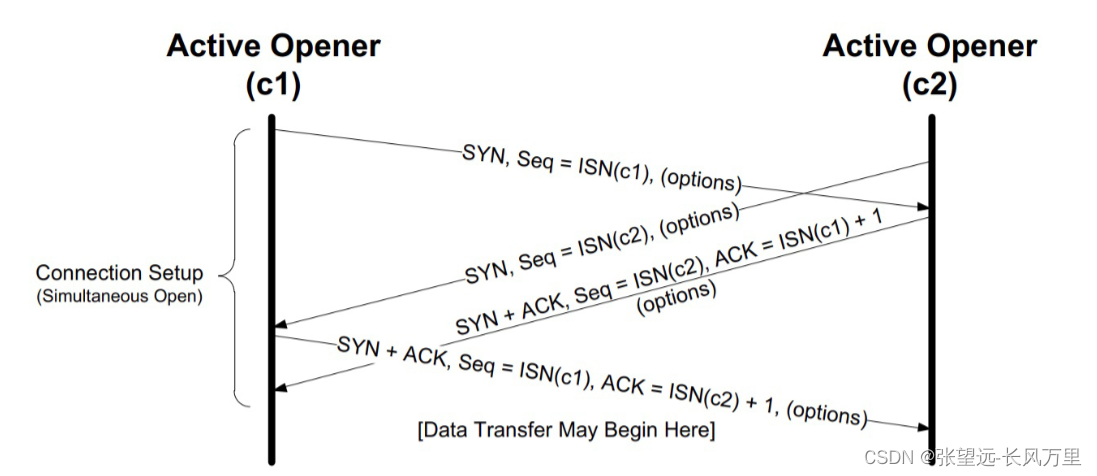
通信双方还真的可以同时向对方发送 SYN,也能建立起连接
-
相关阅读:
手把手教你搭建python+selenium自动化环境
新时代布局新特性 -- 容器查询
Hugging News #0731: 新课程重磅发布、用户交流群邀请你加入、真实图像编辑方法 LEDTIS 来啦!
基于个性化推荐的图书网站设计与实现
两天两夜,1M图片优化到100kb!
校园二手交易系统,二手交易网站,闲置物品交易系统毕业设计作品
电脑线路修改教程
数据结构(王卓)(4)附:链表的销毁与清空
给大家看下刚薅的阿里云99元服务器CPU性能如何?
一台服务器,一个新世界
- 原文地址:https://blog.csdn.net/qinaide56/article/details/133278215