-
编译原理龙书-词法分析
词法分析
词法分析器的作用
词法分析器的主要任务是读入源程序的输入字符,将它们组成词素,生成并输出一个词法单元序列,每个词法单元对应于一个词素
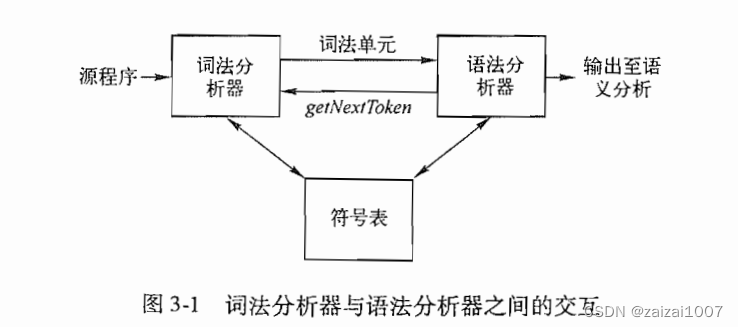
有时,词法分析器可以分成两个级联的处理阶段:
- 扫描阶段主要负责完成一些不需要生成词法单元的简单处理,比如删除注释和将多个连续的空白字符压缩成一个字符
- 词法分析阶段是较为复杂的部分,它将处理扫描阶段的输出并生成词法单元
词法单元,模式和词素
- 词法单元 由一个词法单元名和一个可选的属性值组成
- 模式 描述了一个词法单元的词素可能具有的形式
- 词素 是源程序中的一个字符序列,他和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例
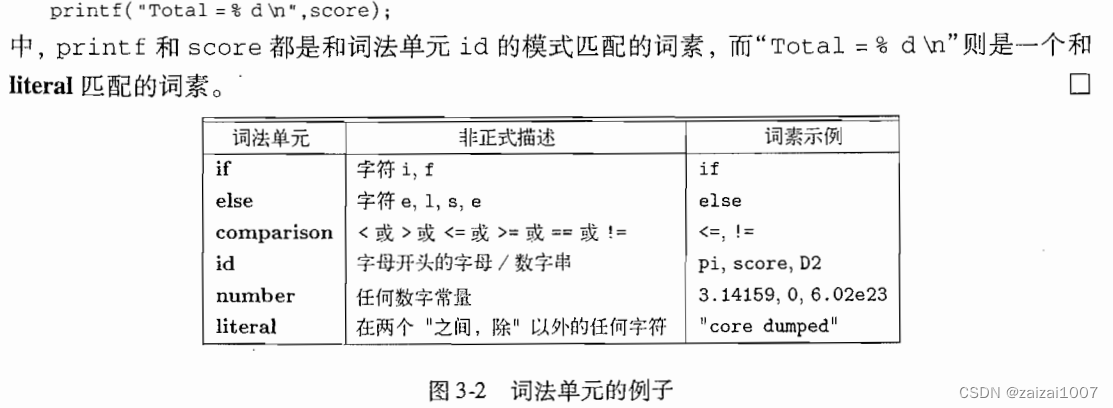
在很多程序设计语言中,下面的类别覆盖了大部分或者所有的词法单元
- 每个关键字都有一个词法单元。一个关键字的模式就是该关键字本身
- 表示运算符的词法单元,它可以表示单个运算符,也可以表示一类运算符
- 一个表示所有标识符的词法单元
- 一个或多个表示常量的词法单元,比如数字和字面值字符串
- 每一个标点符号有一个词法单元,比如左右括号,逗号,分号
输入缓冲
缓冲区对

哨兵标记
用一个不会在正文中出现的符号作为哨兵(eof字符)放在末尾,就可以将移动指针时的是否到达缓冲区的末尾的检查和确定读入的字符是什么的检查合二为一
任何不是出现在某个缓冲区末尾的 eof 都表示到达了输入的结尾

词法单元的规约
串和语言
串 s 的长度,通常记作 |s|,是指 s 中符号出现的次数,banaba 是一个长度为6的串,长度为0的串叫做空串,用 表示

串的各部分的术语



正则表达式


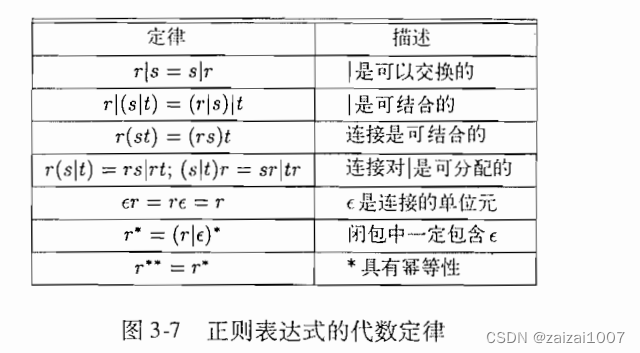
正则定义

C标识符对应的语言的一个正则定义:


正则表达式的扩展

词法单元的识别
词法分析器负责消除空白符,方法是让它识别如下定义的“词法单元” ws
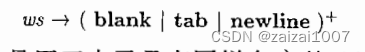
当我们识别到 ws 时,并不会将它返回给语法分析器,而是从这个空白之后的字符开始继续进行词法分析
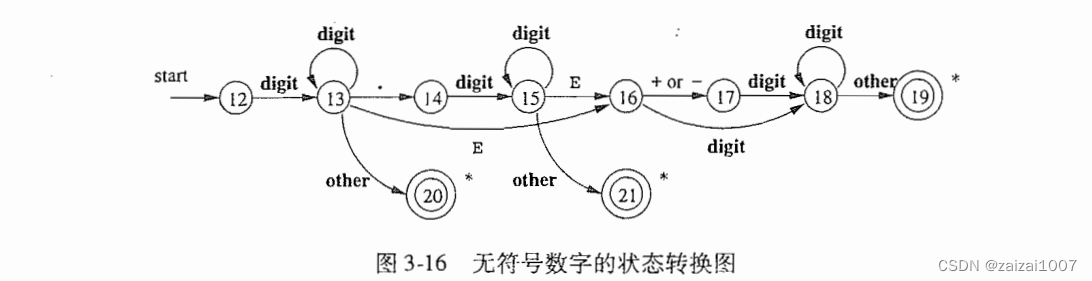
状态转换图
状态转换图有一组被称为状态的节点或圆圈
状态图中的边从图的一个状态指向另一个状态,每条边的标号包含了一个或多个符号
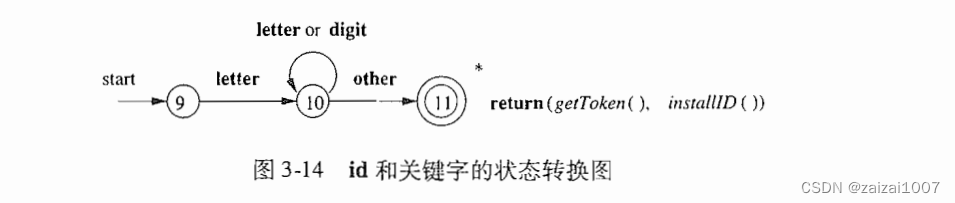
因为最后一位字符不是标识符的一部分,我们必须将输入回退一个位置 *表示回退一位
词法分析器生成工具Lex

它支持使用正则表达式来描述各个词法单元的模式,由此给出一个词法分析器的规约。Lex 工具的输入表示方法称为 Lex 语言,而工具本身则称为 Lex 编译器,在它的核心部分,Lex 编译器将输入的模式转换成一个状态转换图,并生成相应的实现代码,并存放到文件 lex.yy.c 中
Lex 的使用


Lex中的冲突解决

有穷自动机

不确定的有穷自动机(NFA)
一个不确定的有穷自动机(NFA)由以下几个部分组成:
- 一个有穷的状态集合S

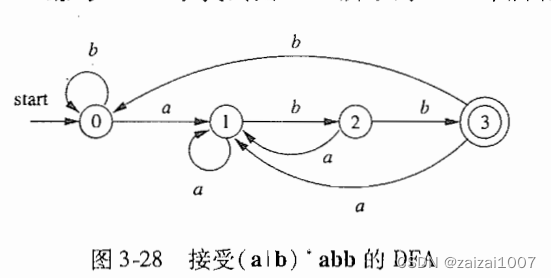
识别正则表达式(a | b)* abb 的语言的NFA的转换图

转换表
表的各行对应于状态,各行对应于输入符号和
 ,对应于一个给定状态和给定输入的条目是将NFA的转换函数应用于这些参数后得到的值,如果转换函数没有给出对应于某个状态-输入对的信息,我们就把
,对应于一个给定状态和给定输入的条目是将NFA的转换函数应用于这些参数后得到的值,如果转换函数没有给出对应于某个状态-输入对的信息,我们就把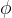 放入相应的表项中
放入相应的表项中 与3-24 对应的转换表
与3-24 对应的转换表只要存在某条其标号序列为某符号串的路径能够从开始状态到达某个接受状态,NFA就接受这个符号串。
由一个NFA定义(或接受)的语言是从开始状态到某个接受状态的所有路径上的标号串的集合
确定的有穷自动机(DFA)

-
相关阅读:
Java学习笔记6.1.2 字节流 - 文件字节输入流和文件字节输出流
【ESP-S3-BOX-Lite花屏问题】:Github下载源码(出厂源码factory_demo)编译调试到ESP-S3-BOX-Lite中出现花屏现象
第14章总结:lambda表达式与处理
goland 旧版本使用1.19环境
为什么要用std::function
阿里云混合云首席架构师张晓丹:政企混合云技术架构的演进和发展
视觉在自动泊车系统中的设计与实现和挑战综述
Android Glide preload RecyclerView切入后台不可见再切换可见只加载当前视野可见区域item图片,Kotlin
excel导出图片中的单位问题
Navicat 16.1 的新功能 - 第 3 部分
- 原文地址:https://blog.csdn.net/zaizai1007/article/details/133242290