-
图神经网络(GNN)最新顶会论文汇总【附源码】
得益于强大的建模和分析能力,图神经网络(GNN)在社交网络分析、推荐系统、知识图谱、文本分析、等诸多领域得到了广泛的应用,目前已成为了人工智能领域的热门研究方向。
在今年的各大顶会获奖论文中,图神经网络相关的论文数量也是意料之中的可观,所以建议有想法发paper的同学抓紧时间。
为了帮大家快速找到idea,这次我精选了近两年图神经网络的各大顶会好文,共40篇,涵盖了可解释性、图transformer、图结构等热门细分领域。
需要论文以及源代码的同学看文末
2023年
1、Do Not Train It: A Linear Neural Architecture Search of Graph Neural Networks
ICML 2023
标题:Do Not Train It: 一种基于线性图神经网络的神经架构搜索方法
内容:图神经网络的神经架构搜索(NAS)方法(称为NAS-GNNs)相比手工设计的GNN架构能够取得显著的性能提升。但是,这些方法继承了传统NAS方法的问题,如计算成本高和优化困难。更重要的是,以前的NAS方法忽略了GNNs的独特性,即GNNs在没有训练的情况下就具有表达能力。我们可以利用稀疏编码目标在随机初始化权重的情况下求出最优的架构参数,并推导出一种新的NAS-GNNs方法,即神经架构编码(NAC)。
2、Feature Expansion for Graph Neural Networks
ICML 2023
标题:图神经网络的特征扩展
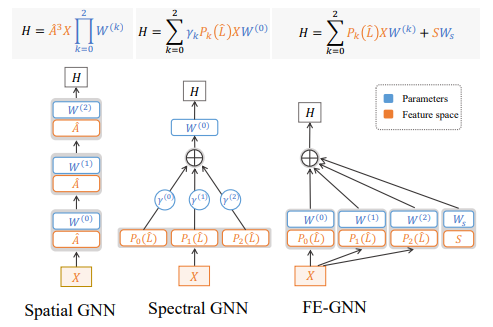
内容:最近,许多方法从优化目标和图谱谱理论的角度研究了GNNs的表示。但是,主导表示学习的特征空间还没有在图神经网络中得到系统的研究。本文通过分析空间模型和谱模型的特征空间来填补这一空白。作者将图神经网络分解为确定的特征空间和可训练的权重,这为使用矩阵空间分析明确地研究特征空间提供了方便。在理论上发现,由于重复聚合,特征空间趋向于线性相关。基于这些发现,作者提出了1)特征子空间展平和2)结构主成分来扩展特征空间。
3、LMC: FAST TRAINING OF GNNS VIA SUBGRAPHWISE SAMPLING WITH PROVABLE CONERGENCE
ICLR 2023
标题:LMC:通过子图抽样实现GNNs的快速训练并保证收敛性
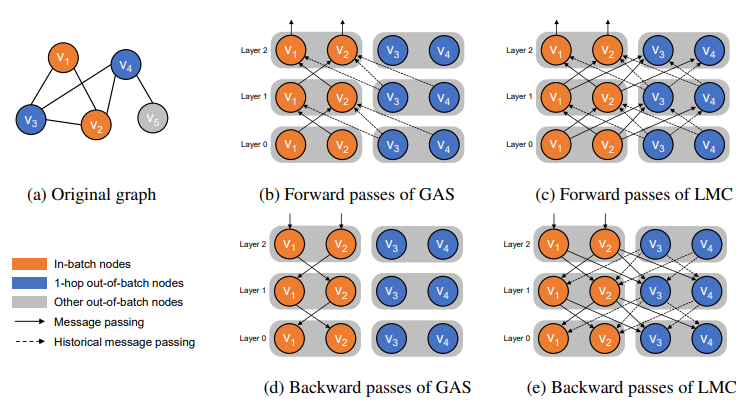
内容:作者提出了一种新的子图抽样方法LMC,它可以恢复反向传播中被丢弃的消息,从而计算出更准确的梯度。作者证明了LMC可以收敛于图神经网络的驻点。实验结果显示,LMC相比现有子图抽样方法,收敛速度更快,计算效率更高。本研究为大规模图上的神经网络训练提供了具有收敛保证的高效解决方案。
4、E-commerce Search via Content Collaborative Graph Neural Network
KDD 2023
标题:基于内容协同的图神经网络在电商搜索中的应用
内容:最近的电商搜索图神经网络模型存在三个问题:(1)缺乏对产品内容的语义表示;(2)大规模图上的计算效率较低;(3)对长尾查询和冷启动产品的准确性较差。为同时解决这三个问题,本文提出了基于内容协同的图神经网络CC-GNN。其主要创新包括:1)允许内容词组参与图传播表达语义;2)高效的图构建和消息传递机制;3)使用对抗学习补充长尾查询和冷启动产品的数据。
5、From Relational Pooling to Subgraph GNNs: A Universal Framework for More Expressive Graph Neural Networks
ICML 2023
标题:从关系汇聚到子图GNNs:一个用于更有表达能力的图神经网络的通用框架
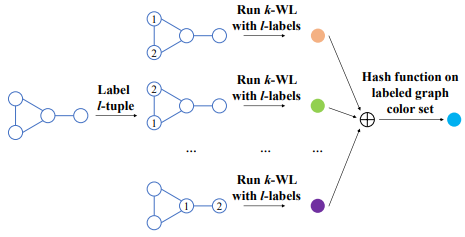
内容:关系汇聚框架构建的图神经网络表达能力和区分图同构的能力有限。为提高表达能力,作者提出了k,lWL算法,它通过给节点添加标签特征,扩展了传统WL测试。此外,作者将子图概念引入,提出了局部化k,l-WL框架,统一了许多子图GNN。理论分析表明,k,lWL优于k-WL。
6、xGCN: An Extreme Graph Convolutional Network for Large-scale Social Link Prediction
WWW 2023
标题:xGCN:用于大规模社交链接预测的极端图卷积网络
内容:针对大规模图的表示学习,xGCN采用极端卷积方式对图结构进行编码。它将节点嵌入看作静态特征,通过传播操作平滑节点特征,然后用精炼网络反复学习新的嵌入特征。这样可以高效利用图结构信息,并连续改进节点表示,避免直接学习大规模可训练嵌入参数。在链接预测任务上,xGCN取得最优准确率,且高效可扩展。本研究为大规模网络表示学习提供了实用高效的框架。
7、GraphSHA: Synthesizing Harder Samples for Class-Imbalanced Node Classification
KDD 2023
标题:GraphSHA:为类别不平衡的节点分类任务合成更难样本
内容:针对GNN在类别不平衡任务中的表现不佳,作者提出了GraphSHA框架。它通过合成更难少类样本来扩大少类的决策边界,并使用SemiMixup模块来控制边界扩张的范围。在多个基准数据集上,GraphSHA优于各种基线,证明了它在扩大少类决策边界上的有效性。

8、Characterizing the Influence of Graph Elements
ICLR 2023
标题:总结图元素的影响
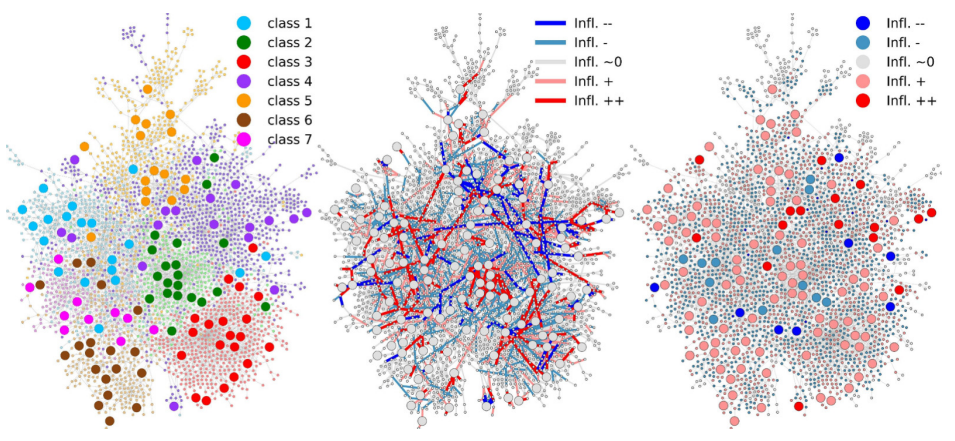
内容:该工作研究了图卷积网络(GCNs)的influence function。influence function可以有效地度量删除或修改训练实例对模型参数或相关函数的影响,无需进行昂贵的模型重新训练。但是在GCNs中,由于节点和边之间的相互依赖性,求解influence function存在挑战。为此,该工作基于简单图卷积(SGC)模型,推导了一个influence function来估计删除属性图中的节点或边对模型参数变化的影响。并且理论分析了删除边的influence function的误差界。
9、Robust Graph Dictionary Learning
ICLR 2023
标题:稳健的图字典学习
内容:传统的字典学习(DL)通过稀疏线性组合来逼近数据向量,并被广泛用于机器学习、计算机视觉和信号处理。Vincent-Cuaz等在2021年提出了一种图字典学习方法GDL,它使用配对关系矩阵(PRM)描述每个图的拓扑结构,并通过Gromov-Wasserstein不相符度(GWD)比较不同PRM。但是GWD对图的结构噪声较敏感,限制了GDL的应用。本文提出了一种基于稳健Gromov-Wasserstein不相符度(RGWD)的改进图字典学习算法,RGWD具有良好的理论属性和高效的计算方案。基于该不相符度,提出的算法可以从含噪声的图数据中学习字典原子。
10、AutoGT: Automated Graph Transformer Architecture Search (Oral)
ICLR 2023
标题:AutoGT:自动图转换器架构搜索
内容:该研究提出自动图Transformer架构搜索方法AutoGT。它设计了统一的图Transformer搜索空间,并使用编码感知的性能估计策略处理架构与图编码之间的耦合关系。实验结果显示,相比手工设计,AutoGT可以搜索出在多个数据集上性能更优的图Transformer架构。
11、Relational Attention: Generalizing Transformers for Graph-Structured Tasks (Spotlight)
ICLR 2023
标题:关系注意力:推广Transformer用于图结构任务
内容:Transformer可以在表示任务特定实体及其属性的实向量集上灵活操作,但在推理更通用的图结构数据时有局限,因为图中节点表示实体,边表示实体间关系。为解决这一缺陷,本文将Transformer注意力推广到边向量,以在每层中同时考虑和更新节点向量和边向量。在各种图结构任务上的评估显示,关系Transformer明显优于专门设计用于图推理的最先进图神经网络。分析表明,这是因为关系注意力内在地利用了图相对于集合的更高的表达能力。
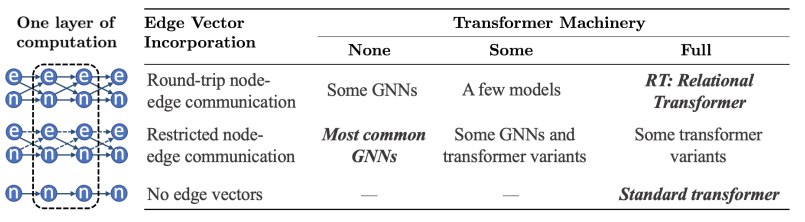
12、Do We Really Need Complicated Model Architectures For Temporal Networks? (Oral)
ICLR 2023
标题:我们真的需要为时态网络设计复杂的模型架构吗?
内容:循环神经网络(RNN)和自注意力机制(SAM)是提取时态图的时空信息的事实标准方法。有趣的是,我们发现尽管RNN和SAM都能取得良好表现,但在实践中它们并非总是必需的。本文提出了GraphMixer,一个概念上和技术上很简单的架构,包含了:(1)仅基于多层感知器(MLP)的链接编码器;(2)仅基于邻居均值池化的节点编码器,(3)基于编码器输出的MLP链接分类器。虽然简单,但GraphMixer在时态链路预测基准测试上取得了出色表现,具有更快收敛速度和更好的泛化能力。
13、Temporal Domain Generalization with Drift-Aware Dynamic Neural Networks (Oral)
ICLR 2023
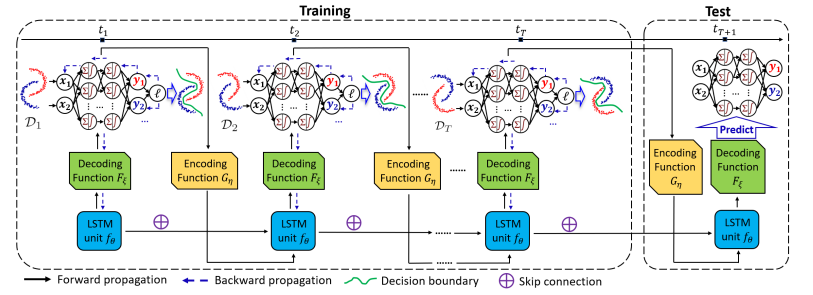
标题:带漂移感知的动态神经网络实现时域泛化
内容:时域泛化目标是学习能够泛化到未见分布的模型,在时间变化的数据分布下具有极大挑战。本文提出了时域泛化的漂移感知动态神经网络(DRAIN)框架。首先,它从贝叶斯角度联合建模了数据和模型动态之间的关系。然后,它通过生成式方法捕获了学习到的动态图神经网络随时间变化的模型参数和数据分布漂移,从而可以在没有未来数据的情况下预测未来模型。此外,它还从理论上分析了时域泛化下的模型性能保证和泛化误差。
14、Transfer NAS with Meta-learned Bayesian Surrogates (Oral)
ICLR 2023
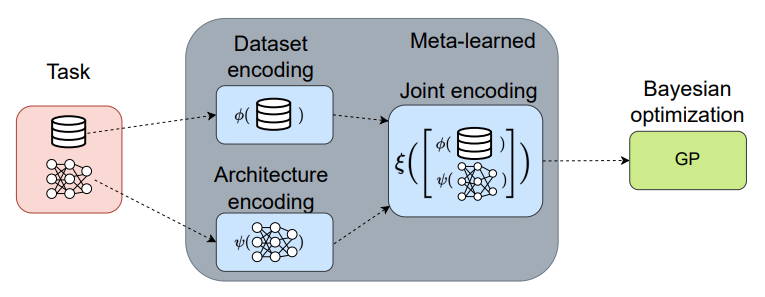
标题:使用元学习贝叶斯替身的神经架构搜索迁移
内容:神经架构搜索(NAS)技术通常要么计算代价高,要么泛化能力差。而人工设计过程中研究人员可以利用之前的经验,如从相关问题中迁移架构。本文采用这种人工设计策略,提出一个元学习的NAS替身模型,可以在不同数据集上进行架构评估和迁移。具体来说,该方法使用贝叶斯优化、图神经网络架构嵌入和数据集转换器编码器。实验结果显示,在多个计算机视觉数据集上,该方法一致地达到了最先进的结果,与一次性NAS方法的速度相当。
2022年
1. Graph neural network for traffic forecasting: A survey
Expert Syst. Appl.(2022)
2. Improving graph neural network expressivity via subgraph isomorphism counting
IEEE TPAMI (2022)
3. Federated social recommendation with graph neural network
ACM T INTEL SYST TEC
4. Multiphysical graph neural network (MP-GNN) for COVID-19 drug design
BRIEF BIOINFORM(2022)
5. GRIP: A graph neural network accelerator architecture
IEEE T-C (2022)
6. Data-augmentation for graph neural network learning of the relaxed energies of unrelaxed structures
NPJ COMPUT MATER (2022)
7. ConGNN: Context-consistent cross-graph neural network for group emotion recognition in the wild
Information Sciences(2022)
8. A Self-supervised Mixed-curvature Graph Neural Network
AAAI 2022
9. Explainability in graph neural networks: A taxonomic survey
IEEE TPAMI (2022).
10. Graphlime: Local interpretable model explanations for graph neural networks
IEEE KDE (2022).
11. Graph neural networks in network neuroscience
IEEE TPAMI (2022).
12. Self-supervised learning of graph neural networks: A unified review
IEEE TPAMI(2022).
13. Protgnn: Towards self-explaining graph neural networks
AAAI 2022
14. Graph neural networks for recommender system
WSDM 2022
15. A machine learning approach for predicting hidden links in supply chain with graph neural networks
INT J PROD RES (2022)
16. My house, my rules: Learning tidying preferences with graph neural networks
CoRL 2022
17. Cf-gnnexplainer: Counterfactual explanations for graph neural networks
AISTATS 2022
18. Model Inversion Attacks against Graph Neural Networks
IEEE KDE (2022). (2022)
19. Probing the rules of cell coordination in live tissues by interpretable machine learning based on graph neural networks
PLOS COMPUT BIOL (2022)
20. Graph neural networks for particle tracking and reconstruction
21. Deep reinforcement learning meets graph neural networks: Exploring a routing optimization use case
Computer Communications (2022)
22. Understanding pooling in graph neural networks
IEEE T NEUR NET LEAR (2022).
23. Discovering invariant rationales for graph neural networks
ICLR 2022
24. AEGNN: Asynchronous Event-based Graph Neural Networks
CVPR 2022
25. Learning graph normalization for graph neural networks
Neurocomputing 2022
26. Orphicx: A causality-inspired latent variable model for interpreting graph neural networks
CVPR 2022
关注下方【学姐带你玩AI】🚀🚀🚀
回复“GNN精选”获取论文+源代码合集
码字不易,欢迎大家点赞评论收藏!
-
相关阅读:
图的最小生成树-Prim算法
Oracle数据库连接之TNS-03505_无法解析服务名异常
Flask笔记二之blueprint和session介绍
分期付款中的利率问题
Flutter组件--Align和AnimatedAlign
【C++】函数重载 & 引用 & 内联函数
大学生静态HTML鲜花网页设计作品 DIV布局网上鲜花介绍网页模板代码 DW花店网站制作成品 web网页制作与实现
Si24R2F+畜牧 耳标测体温开发资料
【Arcpy】批量表格转xy点
【论文】基于Hadoop的铁路货运大数据平台设计与应用
- 原文地址:https://blog.csdn.net/weixin_42645636/article/details/133174260