-
AB实验总结
互联网有线上系统,可做严格的AB实验。传统行业很多是不能做AB实验的。
匹配侧是采用严格的AB实验来进行模型迭代,而精细化定价是不能通过AB实验来评估模型好坏,经历过合成控制法、双重差分法,目前采用双重差分法来进行效果评估。
本次只讨论AB实验,其他的非AB实验方法不做详细描述,大家可初步参考之前吴百威整理的文档。登录 上海哈啰普惠科技有限公司 · 上海哈啰普惠科技有限公司 《双边市场下的实验设计》。总体来说,实验研究的方法梳理见下图:
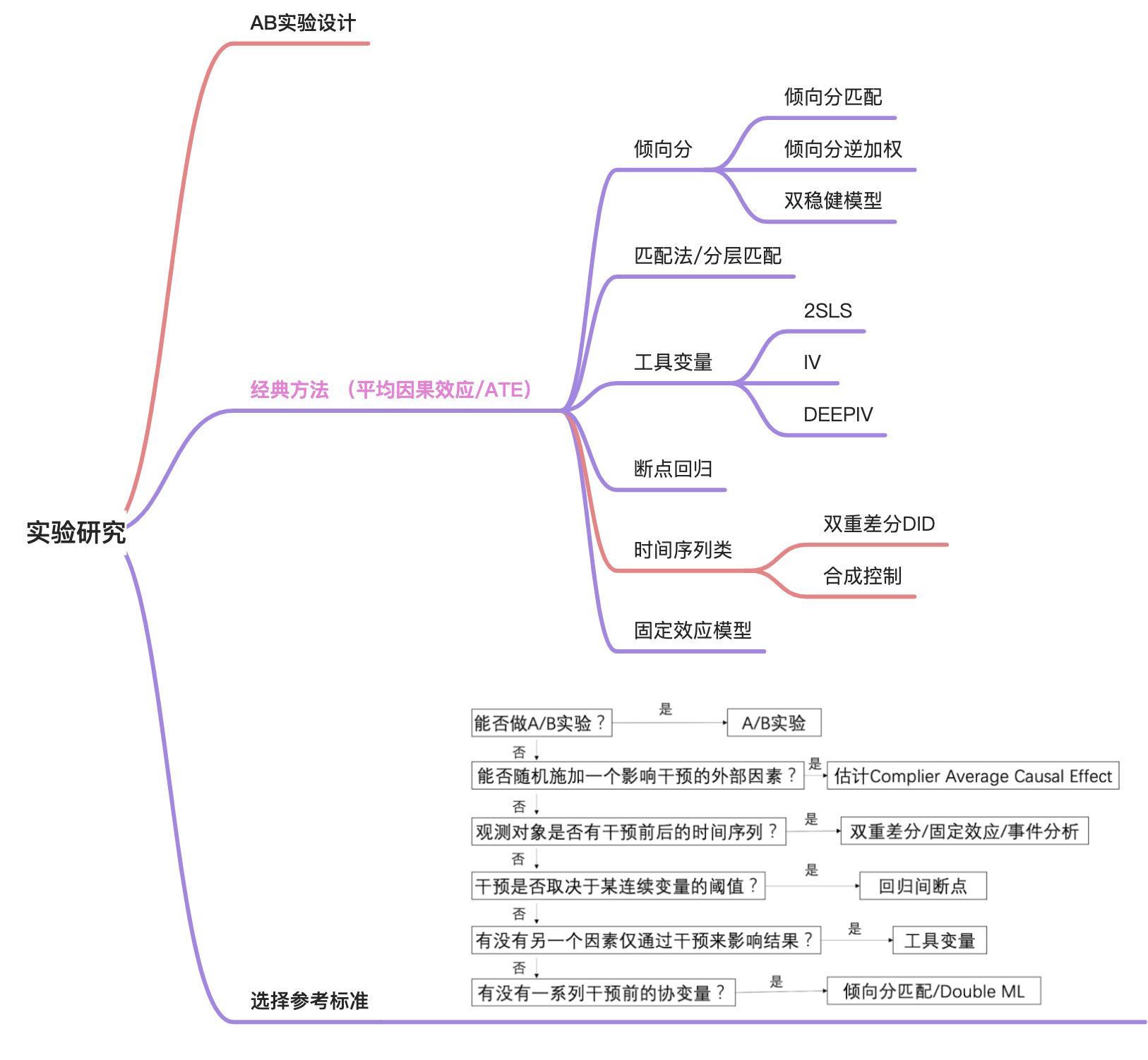
AB实验基础
A/B实验的目的在于通过科学的实验设计、采样样本代表性、流量分割与小流量测试等方式来获得具有代表性的结论,并确信该结论可推广到全部流量。
A/B实验的基本思想其实非常简单——通过控制变量法,随机抽取一些样本进行实验组和对照组的对比实验,回收实验数据,通过统计学相关知识判断两组的优劣。而目前互联网行业的A/B实验设计基本上都是参考Google公司的经典论文:《Overlapping Experiment Infrastructure:More, Better, Faster Experimentation》。通过“层”,“域”的设计,从宝贵的线上流量中选择一部分,验证产品的某个新特性,回收数据,以此选择产品迭代方向。大胆假设,小心求证,用科学的方式让产品的每一次迭代都走在正确的道路上。
传统AB实验
将正交的参数放在不同的层中,这样就可以达到同层流量互斥,分层流量复用的目标
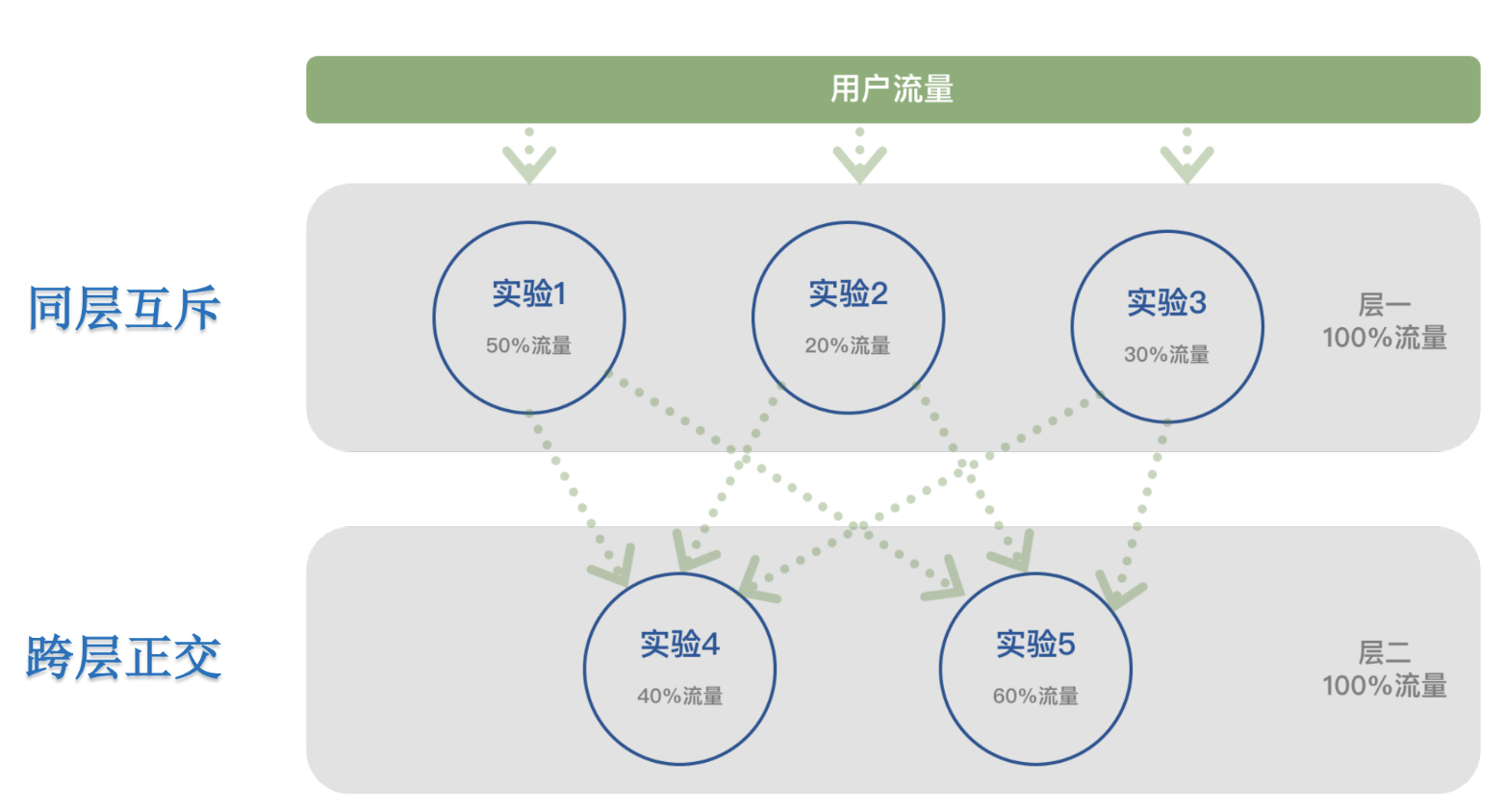
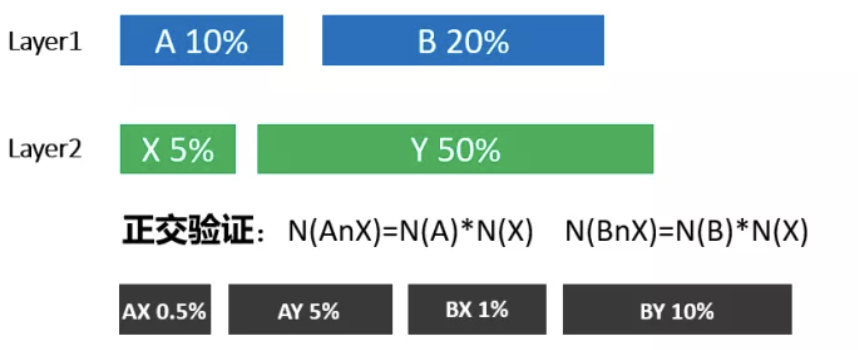
正交性校验:
A,B是第1层中任意两个桶,用户占比例分别为N(A),N(B),X是第2层中任意一个桶,如果满足以下条件:N(AnX)=N(A)*N(X)、N(BnX)=N(B)*N(X),则说明第1层和第2层是正交的。同样,这个也是可以从数学上进行证明的
最小样本量计算:
设置指标时要根据业务情况决定,设置为对业务有意义的提升下限。比如1个实验业务认为至少提升5个点才有意义,提升2个点没有意义,那就设置为提升5个点需要的最小样本量是多少,2个点的差异不管有没有被检验出来都不重要。
规律:提升幅度越高,需要的最小样本数量越少
顺风车业务体量,基本可以忽略这个问题
自动计算工具:Sample Size Calculator

实验的有效天数:定价实验特别要考虑
需要考虑两个因素:
(1)试验进行多少天能达到流量的最小样本量
(2)同时还要考虑到用户的行为周期和适应期
- 用户的行为周期
部分行业用行为存在周期性,例如电商用户购买行为,周末与工作日有显著差异。故实验有效天数应覆盖一个完整的用户行为周期。
- 用户学习效应
我们的一些改动会引起老用户的好奇或不满,这时候,我们可以拉长实验周期,或者仅用新用户进行实验。
还有其他置信区间、验证指标的显著的检验方法,不详细写了。
伽利略平台已经具有的能力,顺风车所有实验都是使用数分配置的指标进行,指标统一。

网络溢出效应的AB实验
用户之间存在相互影响,这个就是我们提到的社交活动,比如说分享红包,我可以在活动发起端把用户分成实验组跟对照组,实验组参与这个活动的时候,用户把活动分享出去,就会把这个活动覆盖到原来队长组的那一波人里,就会影响效果。我们可以通过社交网络关系的刻画,找到相对孤岛的一群人,就这一群人相对内部闭环,然后把这一波人切下来去做对照组,跟其他的用户进行效果对比。他们因为关联性会比较小,所以产生的联系会比较少,但是这里面用户本身可能天然存在一定的差异。
基于地理隔离
由于用户之间的相互影响,可能产生网络效应,导致AB测试用户分隔达不到预期,所以我们要尽量从地理上去区隔用户进行实验。
从地理上区隔用户,这种情况适合滴滴这种能够从地理上区隔的产品,比如北京是实验组,上海是对照组,只要两个城市样本量相近即可。
基于簇的随机化网络实验
它的思想是把网络传播路径用一个社交关系图来刻画,并通过算法把关系图划分成不相交的簇,对簇做随机化实验,从而降低网络效应带来的偏差。
双边交易市场的AB实验
双边市场是一个连接两个群体的平台,在经济学中,我们称之为供给方和需求方。由于需求方和供给方的行为存在彼此影响(即双边网络效应),导致在 AB 测试中,实验组和对照组很难满足独立性的假设,因此如何设计实验是一个比较大的挑战。
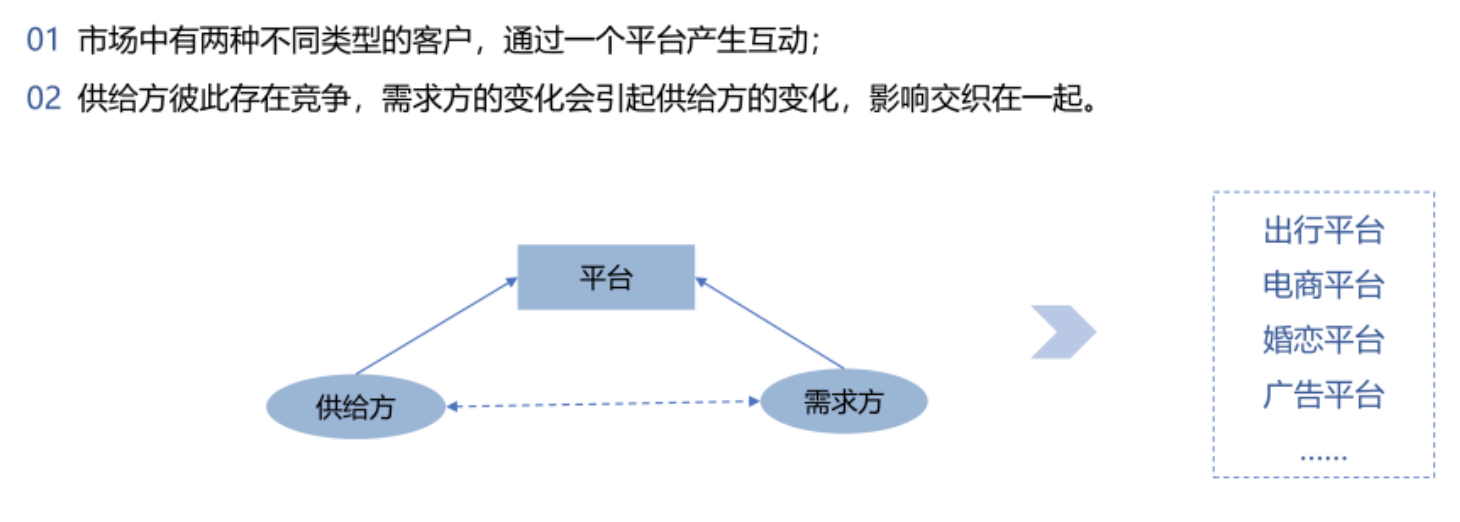
双边网络中,供给方彼此存在竞争,需求方内部存在竞争,同时需求方的变化会引起供给方的变化,影响相互交织形成复杂的竞争环境。
电商平台AB实验
没啥新意,不存在抢夺效应,简单的用户随机分流即可
广告平台AB实验
主要是参考腾讯的这个分享,目前分析下来广告平台的隔离思路在出行行业没法使用
隔离广告和流量,新方法只在实验广告组和实验流量组生效

广告和流量同时隔离
广告和流量同时隔离,但是多出空白组
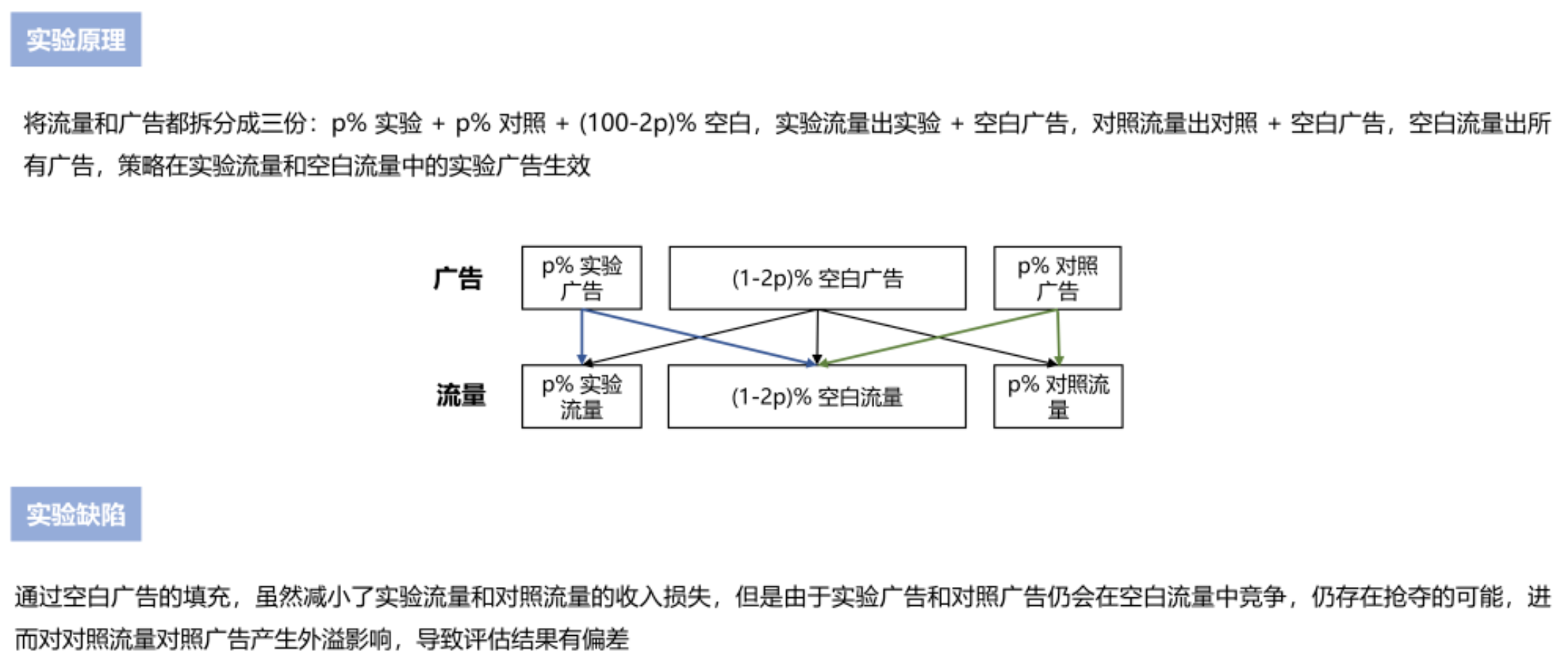
广告分身实验

出行平台AB实验
时间片分流
常见时间片分流
一般是城市id+时间片,滴滴的方式。
传统AB随机分流的分流对象是用户唯一ID(司机唯一ID),而时间片分流的分流对象是一段段的时间片。这种分流算法的应用在某些业务场景并不关注单个用户的选择,更关注在一个时间片内所有用户的选择。假定时间片大小为1s,那么在这1s内所有的用户都会进入同一个组。同时将城市id加入随机因子中,就可以观察不同城市在一个时间片内用户分流情况的对比,计算业务评估指标。
- 比如选定城市上海,A:实验组,B:对照组,实验周期14天=14T,每个周期T=1天,每个时间片假定是2小时,具体AB实验分组如下:可以看到AB2组在实验期间的流量占比=1:1

- 缺点:
1: 实验周期太长,上海这座城市实验期间可能还会上线别的实验,没法保证时间片分流的正交
2: 实验组和对照组上来就是50对50分的大盘流量占比,如果实验组效果不好,没法及时感知到。
时间片轮播分流
这是参考货拉拉的方式
时间片轮播,首先需要划分一个周期,比如一天(24*3600s),再指定时间片大小3600s,同时设置不同组占用的时间片的个数,那么分流SDK就会按照该所设置不同分组占用时间片的个数进行分流,保证一个时间片内所有订单进入相同组,并且在一个周期内,不同组占用时间片的比例符合预先的设定。

为了方便统计效果,最好实验周期是以天为单位,上面的做法太散了
- 针对大盘流量,A:实验组,B:对照组,实验阶段一周期2天=1T,每个周期T=4小时,需12个周期。每个时间片假定是1小时,AB2组在实验期间的流量占比=1:3

多实验并行和长期实验效果评估
多实验并行
题目1:国庆期间,产品进行了一系列组合拳,拼三单功能开启,快筛增加了国庆期间订单过滤,营销活动等,请问:产品运营一系列动作对大盘的贡献是多少?
简单解法1: 采用累乘的方式近似计算
base发完率
迭代实验1大盘提升3%
迭代实验2大盘提升2%
迭代实验3大盘提升1%
总共3次实验
50%
50%*(1+3%)=51.5%
51.5%*(1+2%)=52.53%
52.53%*(1+1%)=53%
50%-》53%
有没有更好的办法?
- 有时候,实验A和实验B,有着相互放大的作用,这时候就会 1+1 > 2
- 还有时候,实验A和实验B,本质上是做相同的事,这时候就会 1+1 < 2
多数的实验都是短期的,长期的实验该如何设计?对于长期业务,可能需要非常多的实验同时进行,不但需要对比每个小迭代的贡献,还需要对比整个模块对大盘的贡献量、部门整体对大盘的贡献量,这样就需要运用到了实验的「层域架构」。注:这个架构最早是由Google的《Overlapping Experiment Infrastructure》论文提出。
就需要一个贯穿所有活动的对照组,在AB实验系统中通俗称作「贯穿层/域」。
注:「贯穿层」在Google的论文中称为「non-overlapping domain」
根据层域架构设计顺风车大盘分流图

有个这个分流图后,我们来回答题目1:
1: 计算国庆活动1的贡献:国庆活动1的实验组 VS 国庆活动1的对照组
2: 计算国庆活动2的贡献:国庆活动2的实验组 VS 国庆活动2的对照组
3: 计算国庆活动整体贡献:业务实验域-贯穿层-国庆活动填充组 VS 大盘贯穿域-线上推全版本填充组
长期实验效果评估
题目2:这个季度算法侧推荐算法模型5次,发完率每次分别提升5%,4%,3%,2%,1%,请问:总共对业务有提升多少?
根据分流图后,我们来回答题目2:
计算上个季度整体贡献:业务实验域-贯穿层-推荐算法填充组 VS 大盘贯穿域-上个季度版本填充组
历史文档:
AB实验技术前沿:双边市场、用户泄漏、因果推断等话题的深入探讨
如何设计一个 A/B test --来自腾讯数据分析师的分享_如何写ab test 模版_浮豹的博客-CSDN博客
浅谈AB Test实验设计(二)——同时多实验并行和长期实验
-
相关阅读:
基于SpringBoot的在线商城系统设计与实现
【动画进阶】有意思的 Emoji 3D 表情切换效果
相信中国杂交水稻技术 国稻种芯:中菲农业创繁荣发展时代
STM32--WDG看门狗
el-table 表格从下往上滚动,触底自动请求新数据
软件生命周期过程
C++IO流
WIN10商业版64位22H2正式版19045.2251MSDN11月原版镜像
常用随机变量的数学期望和方差
python二次开发Solidworks:修改实体尺寸
- 原文地址:https://blog.csdn.net/u013385018/article/details/133149296