-
MongoDB索引
索引支持在MongoDB中高效执行查询。如果没有索引,MongoDB必须扫描集合中的每个文档才能返回查询结果。如果查询存在适当的索引,MongoDB将使用该索引来限制它必须扫描的文档数。
尽管索引提高了查询性能,但添加索引对写入操作的性能有负面影响。对于具有高读写比率的集合,索引是昂贵的,因为每次插入都必须更新任何索引。下图说明了一个查询,该查询选择并排序 使用索引匹配文档:

一、用例
如果应用程序在相同的字段上重复运行查询,则可以在这些字段上创建索引以提高性能。例如,考虑以下场景:
Scenario
Index Type
人力资源部门通常需要按员工ID查找员工。您可以在员工ID字段上创建索引,以提高查询性能。
Single Field Index
销售人员通常需要按位置查找客户信息。位置存储在一个嵌入的对象中,其中包含州、城市和邮政编码等字段。可以在整个位置对象上创建索引,以提高该对象中任何字段的查询性能。
Single Field Index on an object
杂货店经理通常需要按名称和数量查找库存项目,以确定哪些项目库存不足。您可以在项目和数量字段上创建单个索引,以提高查询性能。
Compound Index
二、Details
索引是特殊的数据结构,以易于遍历的形式存储集合数据集的一小部分。MongoDB索引使用B树数据结构。
索引存储特定字段或字段集的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB可以使用索引中的顺序返回排序的结果。三、限制
某些限制适用于索引,例如索引键的长度或每个集合的索引数。有关详细信息,请参阅索引限制。
四、默认索引
MongoDB在创建集合期间在_id字段上创建唯一索引。_id索引防止客户端插入两个文档,其中_id字段的值相同。不能删除此索引。
在分片集群中,如果不使用_id字段作为分片键,则应用程序必须确保_id字段中的值的唯一性,以防止出现错误。这通常是通过使用标准的自动生成的ObjectId来完成的。
五、索引名称
索引的默认名称是索引键和索引(1或-1)中每个键的方向的串联,使用下划线作为分隔符。例如,在{item:1,quantity:-1}上创建的索引的名称为item_1_quantity_-1。
索引一旦创建就不能重命名。相反,必须删除索引,然后用新名称重新创建索引。六、Create an Index
索引支持在MongoDB中高效执行查询。如果应用程序在相同的字段上重复运行查询,则可以在这些字段上创建索引,以提高这些查询的性能。
要创建索引,请使用createIndex()shell方法或驱动程序的等效方法。本页显示MongoDB Shell和驱动程序的示例。1、关于此任务
在MongoDB Shell或驱动程序中运行创建索引命令时,MongoDB仅在不存在相同规范的索引时创建索引。
尽管索引提高了查询性能,但添加索引对写入操作的性能有负面影响。对于具有高读写比率的集合,索引是昂贵的,因为每次插入和更新都必须更新任何索引。2、Procedure
要设置此页面上示例的语言,请使用右侧导航窗格中的选择语言下拉菜单。
要使用Async Java驱动程序创建索引,请使用com.mongodb.Async.client.MongoCollection.createIndex。
collection.createIndex( <key and index type specification>, <options>, <callbackFunction>)本例在名称字段上创建单键降序索引:
- collection.createIndex(Indexes.descending("name"), someCallbackFunction());
- db.blog.createIndex(
- {
- content: "text",
- "users.comments": "text",
- "users.profiles": "text"
- },
- {
- name: "InteractionsTextIndex"
- }
- )
结果要确认索引已创建,请使用mongosh运行db.collection.getIndexes()方法:
db.collection.getIndexes()输出:
- [
- { v: 2, key: { _id: 1 }, name: '_id_' },
- { v: 2, key: { name: -1 }, name: 'name_-1' }
- ]
3、指定索引名称
创建索引时,可以为索引指定自定义名称。为索引命名有助于区分集合上的不同索引。例如,如果索引具有不同的名称,则可以更容易地在查询计划的解释结果中标识查询使用的索引。
要指定索引名称,请在创建索引时包含名称选项:- db.<collection>.createIndex(
- { <field>: <value> },
- { name: "
" } - )
默认索引名称
如果在创建索引期间未指定名称,则系统通过用下划线连接每个索引键字段和值来生成名称。例如:Index
Default Name
{ score : 1 }score_1{ content : "text", "description.tags": "text" }content_text_description.tags_text{ category : 1, locale : "2dsphere"}category_1_locale_2dsphere{ "fieldA" : 1, "fieldB" : "hashed", "fieldC" : -1 }fieldA_1_fieldB_hashed_fieldC_-14、Drop an Index
可以从集合中删除特定索引。如果看到对性能的负面影响、希望用新索引替换它或不再需要索引,则可能需要删除索引。
要删除索引,请使用以下shell方法之一:Method
Description
db.collection.dropIndex()
从集合中删除特定索引。
db.collection.dropIndexes()
删除索引集合或索引数组中的所有可移动索引(如果指定)。
5、Index Types
此页面描述可以在MongoDB中创建的索引类型。不同的索引类型支持不同类型的数据和查询。
Single Field Index
单字段索引从集合中每个文档的单个字段中收集和排序数据。
此图显示单个字段上的索引,分数:
复合索引
复合索引收集和排序来自集合中每个文档中两个或多个字段的数据。数据按索引中的第一个字段分组,然后按每个后续字段分组。
例如,下图显示了一个复合索引,其中文档首先按用户ID按升序(字母顺序)分组。然后,每个用户ID的分数按降序排序: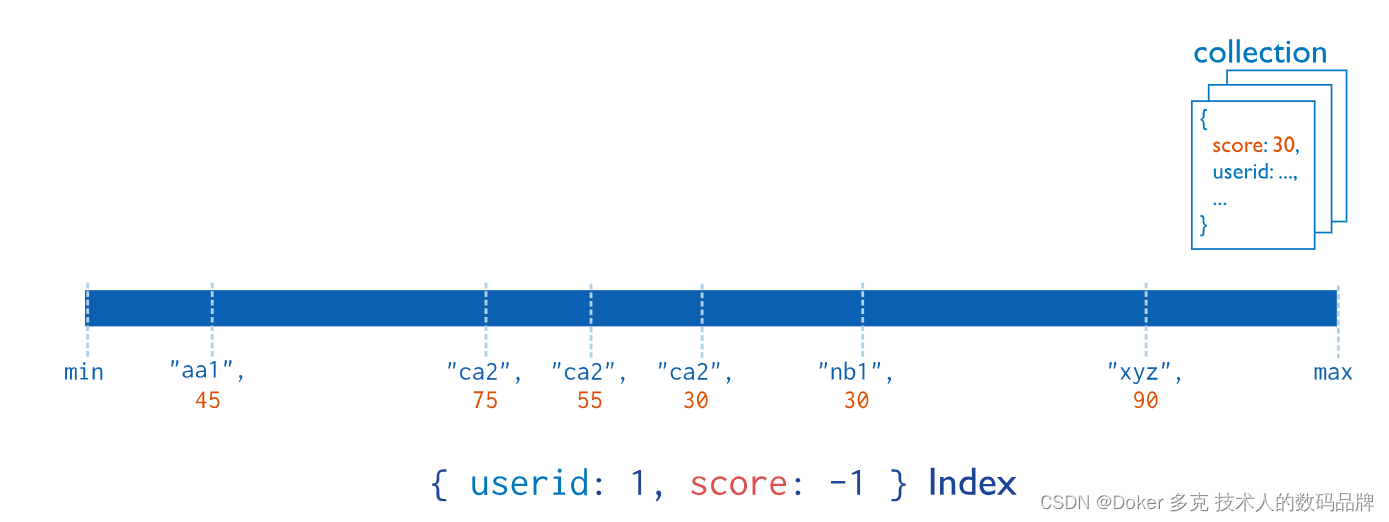
多键索引
多键索引收集和排序存储在数组中的数据。
不需要显式指定多键类型。在包含数组值的字段上创建索引时,MongoDB会自动将索引设置为多键索引。
此图显示addr.zip字段上的多键索引:地理空间索引
地理空间索引提高了查询地理空间坐标数据的性能。要了解更多信息,请参见地理空间索引。
MongoDB提供两种类型的地理空间索引:- 使用平面几何图形返回结果的2d索引。
- 使用球形几何体返回结果的2dsphere索引。
文本索引
文本索引支持对包含字符串内容的字段进行文本搜索查询。哈希索引
哈希索引支持哈希切分。哈希索引索引字段值的哈希。聚集索引
5.3版中的新增功能。
聚集索引指定聚集集合存储数据的顺序。使用聚集索引创建的集合称为聚集集合。七、Create a Compound Index
复合索引是包含对多个字段的引用的索引。复合索引提高了对索引中的字段或索引前缀中的字段进行精确查询的性能。
要创建复合索引,请使用db.collection.createIndex()方法:- db.<collection>.createIndex( {
- <field1>: <sortOrder>,
- <field2>: <sortOrder>,
- ...
- <fieldN>: <sortOrder>
- } )
1、限制
在单个复合索引中最多可以指定32个字段。
开始之前
创建包含以下文档的学生集合:- db.students.insertMany([
- {
- "name": "Alice",
- "gpa": 3.6,
- "location": { city: "Sacramento", state: "California" }
- },
- {
- "name": "Bob",
- "gpa": 3.2,
- "location": { city: "Albany", state: "New York" }
- }
- ])
2、Procedure
以下操作创建包含名称和gpa字段的复合索引:
- db.students.createIndex( {
- name: 1,
- gpa: -1
- } )
在此示例中:
- 名称上的索引是升序的(1)。
- gpa上的索引正在下降(-1)。
3、Results
创建的索引支持选择以下项的查询:
- 名称和gpa字段。
- 仅名称字段,因为名称是复合索引的前缀。
例如,索引支持以下查询:
- db.students.find( { name: "Alice", gpa: 3.6 } )
- db.students.find( { name: "Bob" } )
-
相关阅读:
【常用页面记录】vue+elementUI实现搜索框+上拉加载列表
大数据反哺_数据抽取模式分析
JavaScript高级知识-浏览器的解析以及JS运行原理
RunnerGo:轻量级、全栈式、易用性和高效性的测试工具
ABP +VUE Elment 通用高级查询(右键菜单)设计+LINQ通用类Expression<Func<TFields, bool>>方法
抗丙型肝炎病毒化合物库
springboot+二手车交易系统 毕业设计-附源码131456
LeetCode104. 二叉树的最大深度和N叉树的最大深度
矿物结构和构造的区别
【问题解决】蓝牙显示已配对,无法连接,蓝牙设备显示在其他设备中。
- 原文地址:https://blog.csdn.net/leesinbad/article/details/133147942