-
正则表达式的学习笔记
[!note]
其实这个正则表达式整体上不难,
自从这个 gpt 出来之后这种正则表达式已经不需要我们去写了, 我们并不需要自己能够去写特别深奥的代码, 我们可以将这个正则表达式交给 gpt 去做, 我们只需要能够看懂就行了, 所以学习这个正则表达式, 自己写不出来那种比较难的正则没有事情, 只要你能够看懂别人给你的, 你就达标了正则表达式的练习和可视化的网站
练习网站
[可视化工具]( https://c.runoob.com/front-end/7625/#!flags=&re=%5E (a%7 Cb)*%3 F%24)正则表达式
1.1 正则表达式的概念及演示
- 在 Java 中,我们经常需要验证一些字符串,例如:年龄必须是 2 位的数字、用户名必须是 8 位长度而且只能包含大小写字母、数字等。正则表达式就是用来验证各种字符串的规则。它内部描述了一些规则,我们可以验证用户输入的字符串是否匹配这个规则。
- 先看一个不使用正则表达式验证的例子:下面的程序让用户输入一个 QQ 号码,我们要验证:
- QQ 号码必须是 5–15 位长度
- 而且必须全部是数字
- 而且首位不能为 0
package com.itheima.a08regexdemo; public class RegexDemo1 { public static void main(String[] args) { /* 假如现在要求校验一个qq号码是否正确。 规则:6位及20位之内,日不能在开头,必须全部是数字。 先使用目前所学知识完成校验需求然后体验一下正则表达式检验。 */ String qq ="1234567890"; System.out.println(checkQQ(qq)); System.out.println(qq.matches("[1-9]\\d{5,19}")); } public static boolean checkQQ(String qq) { //规则:6位及20位之内,日不能在开头,必须全部是数字 。 //核心思想: //先把异常数据进行过滤 //下面的就是满足要求的数据了。 int len = qq.length(); if (len < 6 || len > 20) { return false; } //0不能在开头 if (qq.startsWith("0")) { return false; } //必须全部是数字 for (int i = 0; i < qq.length(); i++) { char c = qq.charAt(i); if (c < '0' | c > '9') { return false; } } return true; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 使用正则表达式验证:
public class Demo { public static void main(String[] args) { String qq ="1234567890"; System.out.println(qq.matches("[1-9]\\d{5,19}")); } }- 1
- 2
- 3
- 4
- 5
- 6
我们接下来就重点学习怎样写正则表达式
正则表达式字符类
- 语法示例:
[abc]:代表 a 或者 b,或者 c 字符中的一个。
一次只能匹配一个字符, 如果正则表达式少于字符串的长度, 那么就会返回 false, 如果我们想要让他们多匹配, 我们就要多添加几个正则表达式System.out.println("a".matches("[abc]")); // true System.out.println("z".matches("[abc]")); // false System.out.println("ab".matches("[abc]")); // false System.out.println("ab".matches("[abc][abc]")); // true- 1
- 2
- 3
- 4
[^abc]:代表除 a, b, c 以外的任何字符。
System.out.println("a".matches("[^abc]")); // false System.out.println("z".matches("[^abc]")); // true System.out.println("zz".matches("[^abc]")); //false System.out.println("zz".matches("[^abc][^abc]")); //true- 1
- 2
- 3
- 4
[a-z]:代表 a-z 的所有小写字符中的一个,
[A-Z]:代表 A-Z 的所有大写字符中的一个。
[a-zA-Z 0-9]代表 a-z 或者 A-Z 或者 0-9 之间的任意一个字符。
[0-9]:代表 0-9 之间的某一个数字字符。
[a-dm-p]:a 到 d 或 m 到 p 之间的任意一个字符。// a到zA到Z(包括头尾的范围) System.out.println("a".matches("[a-zA-z]")); // true System.out.println("z".matches("[a-zA-z]")); // true System.out.println("aa".matches("[a-zA-z]"));//false System.out.println("zz".matches("[a-zA-Z]")); //false System.out.println("zz".matches("[a-zA-Z][a-zA-Z]")); //true System.out.println("0".matches("[a-zA-Z]"));//false System.out.println("0".matches("[a-zA-Z0-9]"));//true- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
System.out.println("a".matches("[a-d[m-p]]"));//true System.out.println("d".matches("[a-d[m-p]]")); //true System.out.println("m".matches("[a-d[m-p]]")); //true System.out.println("p".matches("[a-d[m-p]]")); //true System.out.println("e".matches("[a-d[m-p]]")); //false System.out.println("0".matches("[a-d[m-p]]")); //false- 1
- 2
- 3
- 4
- 5
- 6
逻辑关系符且
// [a-z&&[def]] a-z和def的交集。为:d,e,f System.out.println("a".matches("[a-z&[def]]")); //false 此时的且简简单单的表示一个符号而已 System.out.println("&".matches("[a-z&[def]]")); //true 此时的且简简单单的表示一个符号而已 System.out.println("d".matches("[a-z&&[def]]")); //true 这里的且才是表示且符号 System.out.println("0".matches("[a-z&&[def]]")); //false- 1
- 2
- 3
- 4
- 5
总结规律, 这个正则表达式这个双引号不能少, 范围的话要用括号来代替, 其中这几个联立范围的正则表达式的顺序没有要求
这个或者可以用括号, 也可以不用括号, 但最好用括号正则表达式预定义字符
- “.” : 匹配任何字符。
- “\d”:任何数字[0-9]的简写;
- “\D”:任何非数字[^0-9]的简写;
- “\s”: 空白字符:[ \t\n\x 0 B\f\r] 的简写
- “\S”: 非空白字符:[^\s] 的简写
- “\w”:单词字符:[a-zA-Z_0-9]的简写
- “\W”:非单词字符:[^\w]
转义字符\能够让在 java 中原本有意义的字符变成没有意义, 普普通通的字符
我们要始终记得, 这个转义字符\也是一个字符, 为了让这个字符表示出来, 我们一般要在这个转义字符\前面再加入一个\, 因此这个\不单独出现
正则表达式数量词
语法示例:
- X? : 0 次或 1 次
- X* : 0 次到多次
- X+ : 1 次或多次
- X{n} : 恰好 n 次
- X{n,} : 至少 n 次
- X{n, m}: n 到 m 次 (n 和 m 都是包含的)
正则表达式是 Paten 类里面的
特点
小括号表示分组, 表示这一组数据然后就可以对这一组进行量词的修饰
String regex3 = "\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}){1,2}";- 1
"|"表示两组数组取一组就行了
String regex4 = "([01]\\d|2[0-3]):[0-5]\\d:[0-5]\\d";- 1
忽略大小写

组合字符用小括号进行分组
String regexSimple ="\\d{17}(\\d|X|x)";- 1
一步一步的找规律, 然后进行拼接就好了


爬虫
Pattern:表示正则表达式
Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。在大串中去找符合匹配规则的子串。package com.itheima.a08regexdemo; import java.util.regex.Matcher; import java.util.regex.Pattern; public class RegexDemo6 { public static void main(String[] args) { String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台"; //1.获取正则表达式的对象,这个对象表示的是这个正则表达式的规则 Pattern p = Pattern.compile("Java\\d{0,2}"); //2.获取文本匹配器的对象 //拿着m去读取str,找符合p规则的子串 Matcher m = p.matcher(str); //3.利用循环获取 这个find函数判断是否找到了对象,如果找到了就返回true,否则返回false while (m.find()) { //获取这个找到的这个对象的下标,并截取这一段的内容, String s = m.group(); System.out.println(s); } } private static void method1(String str) { //获取正则表达式的对象 Pattern p = Pattern.compile("Java\\d{0,2}"); //获取文本匹配器的对象 //m:文本匹配器的对象 //str:大串 //p:规则 //m要在str中找符合p规则的小串 Matcher m = p.matcher(str); //拿着文本匹配器从头开始读取,寻找是否有满足规则的子串 //如果没有,方法返回false //如果有,返回true。在底层记录子串的起始索引和结束索引+1 // 0,4 boolean b = m.find(); //方法底层会根据find方法记录的索引进行字符串的截取 // substring(起始索引,结束索引);包头不包尾 // (0,4)但是不包含4索引 // 会把截取的小串进行返回。 String s1 = m.group(); System.out.println(s1); //第二次在调用find的时候,会继续读取后面的内容 //读取到第二个满足要求的子串,方法会继续返回true //并把第二个子串的起始索引和结束索引+1,进行记录 b = m.find(); //第二次调用group方法的时候,会根据find方法记录的索引再次截取子串 String s2 = m.group(); System.out.println(s2); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
按照要求进行爬取数据
按要求爬取
需求:
有如下文本,按要求爬取数据。
Java 自从 95 年问世以来,经历了很多版本,目前企业中用的最多的是 Java 8 和 Java 11,因为这两个是长期支持版本,下一个长期支持版本是 Java 17,相信在未来不久 Java 17 也会逐渐登上历史舞台。
需求 1:
爬取版本号为 8,11.17 的 Java 文本,但是只要 Java,不显示版本号。
需求 2:
爬取版本号为 8,11,17 的 Java 文本。正确爬取结果为:Java 8 Java 11 Java 17 Java17
需求 3:
爬取除了版本号为 8,11,17 的 Java 文本。忽略大小写
(? I) Java
查找某个数据, 但是只获取这个数据的前面部分
((? I) java)(?=8|11||17)
//1.定义正则表达式 //?理解为前面的数据Java //=表示在Java后面要跟随的数据 //但是在获取的时候,只获取前半部分- 1
- 2
- 3
- 4
除了某一项
?!..
代码示例:
public class RegexDemo9 { public static void main(String[] args) { /* 有如下文本,按要求爬取数据。 Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11, 因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台 需求1:爬取版本号为8,11.17的Java文本,但是只要Java,不显示版本号。 需求2:爬取版本号为8,11,17的Java文本。正确爬取结果为:Java8 Java11 Java17 Java17 需求3:爬取除了版本号为8,11.17的Java文本, */ String s = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," + "因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台"; //1.定义正则表达式 //?理解为前面的数据Java //=表示在Java后面要跟随的数据 //但是在获取的时候,只获取前半部分 //需求1: String regex1 = "((?i)Java)(?=8|11|17)"; //需求2: String regex2 = "((?i)Java)(8|11|17)"; String regex3 = "((?i)Java)(?:8|11|17)"; //需求3: String regex4 = "((?i)Java)(?!8|11|17)"; Pattern p = Pattern.compile(regex4); Matcher m = p.matcher(s); while (m.find()) { System.out.println(m.group()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
贪婪爬取和非贪婪爬取
尽可能多 X+
尽可能少 X+?只写+和*表示贪婪匹配 +? 贪婪匹配 *? 非贪婪匹配 贪婪爬取:在爬取数据的时候尽可能的多获取数据 非贪婪爬取:在爬取数据的时候尽可能的少获取数据 ab+: 贪婪爬取:abbbbbbbbbbbb 非贪婪爬取:ab- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.13 String 的 split 方法中使用正则表达式
- String 类的 split ()方法原型:
public String[] split(String regex) //参数regex表示正则表达式。可以将当前字符串中匹配regex正则表达式的符号作为"分隔符"来切割字符串。- 1
- 2
- 代码示例:
/* 有一段字符串:小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠 要求1:把字符串中三个姓名之间的字母替换为vs 要求2:把字符串中的三个姓名切割出来*/ String s = "小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠"; //细节: //方法在底层跟之前一样也会创建文本解析器的对象 //然后从头开始去读取字符串中的内容,只要有满足的,那么就切割。 String[] arr = s.split("[\\w&&[^_]]+"); for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1.14 String 类的 replaceAll 方法中使用正则表达式
- String 类的 replaceAll ()方法原型:
public String replaceAll(String regex,String newStr) //参数regex表示一个正则表达式。可以将当前字符串中匹配regex正则表达式的字符串替换为newStr。- 1
- 2
- 代码示例:
/* 有一段字符串:小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠 要求1:把字符串中三个姓名之间的字母替换为vs 要求2:把字符串中的三个姓名切割出来*/ String s = "小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠"; //细节: //方法在底层跟之前一样也会创建文本解析器的对象 //然后从头开始去读取字符串中的内容,只要有满足的,那么就用第一个参数去替换。 String result1 = s.replaceAll("[\\w&&[^_]]+", "vs"); System.out.println(result1);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
分组

练习 (捕获分组)
捕获分组
后续还要继续使用本组的数据, 正则内部使用\加组号
正则外部使用:$组号非捕获分组
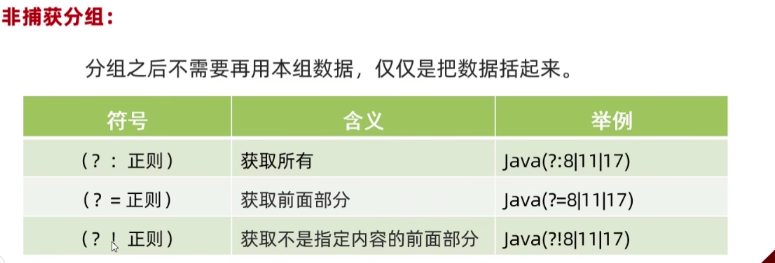

分组

package demo.day1; import java.util.Scanner; public class 分组练习 { public static void main(String[] args) { Scanner sc = new Scanner(System.in); String str = sc.next(); //判断一个字符串的开始字符和结束字符是否一致,只考虑一个字符 String regex1 ="(.).+\\1"; //判断一个字符串的开始部分和结束部分是否一直,可以有多个字符 System.out.println(str.matches(regex1)); String regex2="(.+).+\\1"; System.out.println(str.matches(regex2)); String regex3="((.)\\2*).+\\1"; System.out.println(str.matches(regex3)); sc.close(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
替换
$1 表示替换第一组的内容
public static void main(String[] args) { //Scanner input = new Scanner(System.in); //String str = input.next(); //正则表达式进行替换 //我要学学编编编编程程程程程程 String str ="我要学学编编编编程程程程程程"; // String regex ="(.)\\1+"; String result = str.replaceAll("(.)\\1+", "$1"); System.out.println(result); //input.close(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
相关阅读:
Windows系统Android Studio断点调试Android源码
电脑技巧:Win10自带的6个实用功能,你都会用吗
2023最新SSL证书在线申请系统源码 | 支持API接口
软件测试之发现和解决bug
数据库(MySQL)的存储过程
HashMap总结
Primavera Unifier 21.12.4~21.12.7.0疑似漏洞
SpringCloud & SpringCloud Alibaba基本介绍
数据库表的字符集编码报错问题
redis高可用的哨兵模式实现
- 原文地址:https://blog.csdn.net/everything_study/article/details/133065383
