-
数据库(MySQL)的存储过程
一、存储过程介绍

存储过程是事先经过编译并存储在数据库中的一段SQL 语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。 存储过程思想上很简单,就是数据库SQL 语言层面的代码封装与重用。

特点
- 封装,复用
- 可以接收参数,也可以返回数据
- 减少网络交互,效率提升
二、存储过程的基本语法

2.1 创建
- CREATE PROCEDURE 存储过程名称( [参数列表] )
- BEGIN
- SQL 语句
- END;

2.2 调用
CALL 名称 ( [参数])
2.3 查看

--查询指定数据库的存储过程及状态信息
SELECT* FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA = '对应的数据库名称'
--查询某个存储过程的定义
SHOW CREATE PROCEDURE 存储过程名称2.4 删除
DROP PROCEDURE [ IFEXISTS ] 存储过程名称三、存储过程中的变量
3.1 系统变量

系统变量是MySQL服务器提供,不是用户定义的,属于服务器层面。分为全局变量(GLOBAL)、会话变量(SESSION)。
--查看系统变量
SHOW [SESSION | GIOBAL ] VARIABLFS ; --查看所有系统变景
SHOW [SESSION |GLOBAL] VARUABLES LIKE ..…. ; --可以通过UKL模糊匹配方式查找变量SELECT @@[SESSION | GLOBAL] 系统变量名; --查看指定变量的值
--设置系统变量
SET [ SESSION| GLOBAL] 系统变量名 = 值;
SET @@[SESSION | GLOBAL] 系统变量名 = 值;注意:
如果没有指定SESSION/GLOBAL,默认是SESSION,会话变量。
mysql服务重新启动之后,所设置的全局参数会失效,要想不失效,可以在/etc/my.cnf 中配置。
3.2 用户自定义变量

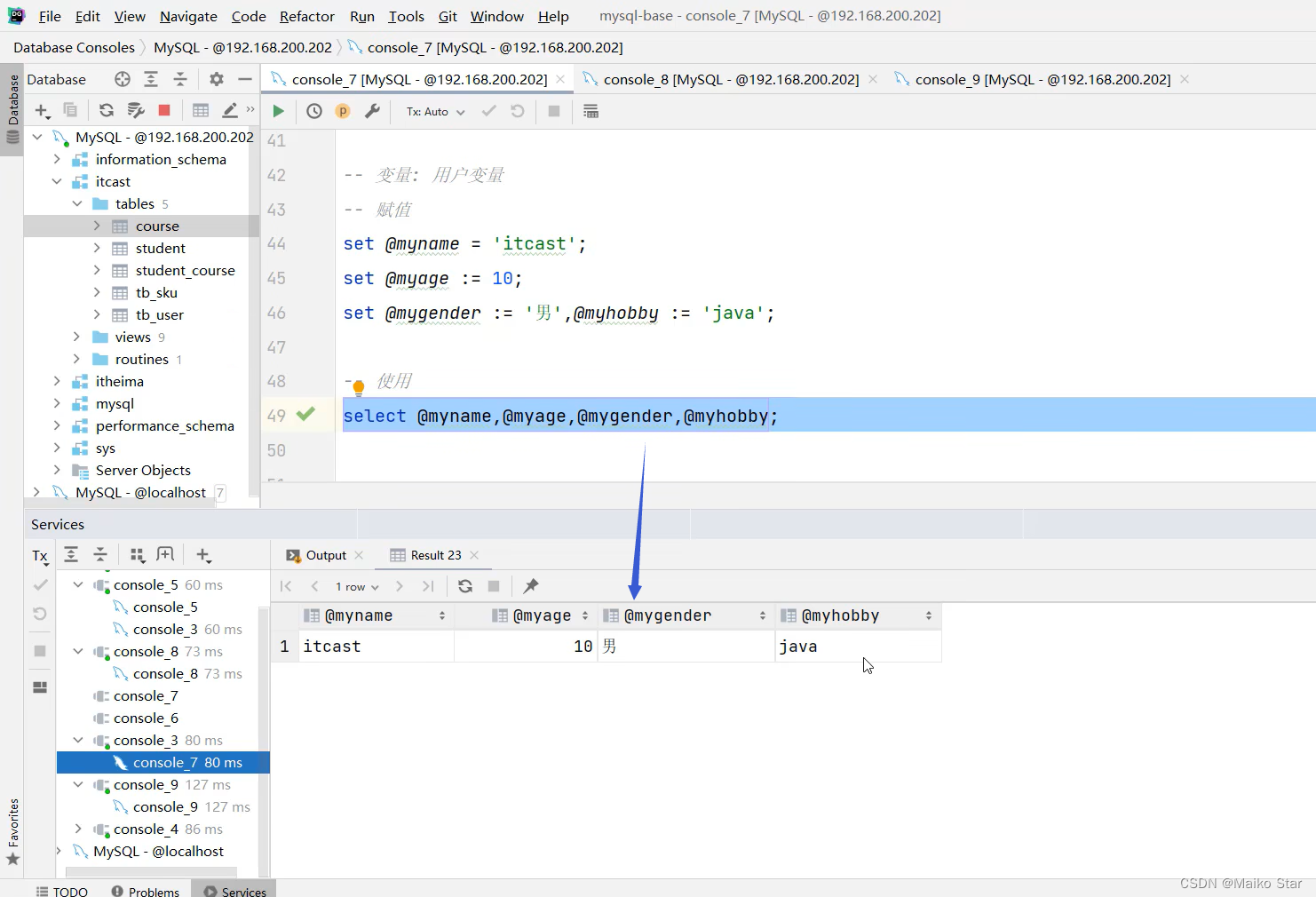
用户定义变量是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用“@变量名”使用就可以。其作用域为当前连接。
--赋值
SET @var_name = expr [,@var_name = expr ]... ;SET @var_name := expr [,@var_name := exprl] ... ;
SELECT @var_name :=expr [,@var_name :=expr ] ..- ;
SELECT字段名INTO@var_name FROM表名;
--使用
SELECT @var_name ;

注意:
用户定义的变量无需对其进行声明或初始化,如果没有进行声明或初始化,将会获取到的值为NULL。如下所示:@abc没有声明,查看自定义变量@abc将会获取到null。

3.3 局部变量

局部变量是根据需要定义的在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的BEGIN.... END块。
声明
DECLARE 变量名 变量类型 [DEFAULT...];
变量类型就是数据库字段类型:INT、BIGINT、CHAR.VARCHAR.DATE、TIME等。赋值
SET 变量名 = 值;SET 变量名 := 值;
SELECT 字段名 INTO 变量名 FROM 表名....;
四、存储过程--流程控制
4.1 存储过程-if判断

语法:
IF 条件1 THEN
ELSEIF 条件2 THEN --可选
ELSE --可选
END IF;
定义存储过程,完成如下需求:
根据定义的分数scre变量,判定当前分数对应的分数等级。
1.score >=85分,等级为优秀。
2.score >=60分且score <85分,等级为及格。
3.score<60分,等级为不及格。
4.2 存储过程-参数

用法:
CREATE PROCEDURE 存储过程名称 ([ IN/OUT/INOUT参数名参数类型 ])
BEGIN
--SQL语句
END ;
定义存储过程,完成如下需求:
1.根据传入参数score,判定当前分数对应的分数等级,并返回。
①score >=85分,等级为优秀。
②score >= 60分且score <85分,等级为及格。
③score<60分,等级为不及格。
2.将传入的200分制的分数,进行换算,换算成百分制,然后返回。

4.3 case

定义存储过程,完成如下需求:
根据传入的月份,判定月份所属的季节(要求采用case结构)。
1. 1-3月份,为第一季度
2. 4-6月份,为第二季度
3. 7-9月份,为第三季度
4. 10-12月份,为第四季度

五、存储过程-循环
5.1 循环-while

定义存储过程,完成如下需求:
计算从1累加到n的值,n为传入的参数值。

5.2 循环-repeat

repeat循环控制语句至少会执行一次,满足条件则退出。
定义存储过程,完成如下需求:
计算从1累加到n的值,n为传入的参数值。

5.3 循环-loop

LOOP实现简单的循环,如果不在sQL逻辑中增加退出循环的条件,可以用其来实现简单的死循环。LOOP可以配合一下两个语句使用:
① LEAVE: 配合循环使用,退出循环。
② ITERATE: 必须用在循环中,作用是跳过当前循环剩下的语句,直接进入下一次循环。
语法:[begin_label:] LOOP
SQL逻辑..
END LOOP [end_ label];LEAVE label; --退出指定标记的循环体
ITERATE label; --直接进入下一次循环定义存储过程,完成如下需求:
1.计算从1累加到n的值,n为传入的参数值。

2.计算从1到n之间的偶数累加的值,n为传入的参数值。
六、存储过程-游标-cursor

游标(CURSOR)是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。游标的使用包括游标的声明、OPEN、FETCH和CLOSE,其语法分别如下。
声明游标
DECLARE 游标名称 CURSOR FOR 查询语句;
打开游标
OPEN 游标名称;
获取游标记录
FETCH 游标名称 INTO 变量 [,变量];
关闭游标
CLOSE 游标名称;
定义存储过程,完成如下需求:
根据传入的参数uage,来查询用户表tb_user中,所有的用户年龄小于等于uage的用户姓名(name)和专业(profession),并将用户的姓名和专业插入到所创建的一张新表tb_user_pro
(id,name,profession)中。
--逻辑:
①声明游标,存储查询结果集②准备:创建表结构
③开启游标
④获取游标中的记录
⑤插入数据到新表中
⑥关闭游标

完整的存储过程语句如下:
- create procedure p1l(in uage int)
- begin
- declare uname varchar(100);
- decLare upro varchar(100);
- declare u_cursor cursor for select name,profession from tb_user where age <= uage;
- 当 条件处理程序的处理的状态码为02000的时候,就会退出。
- declare exit handler for SQLSTATE '02000'close u_cursor;
- drop table if exists tb_user_pro;
- create table if not exists tb_user_pro(
- id int primary key auto_increment,
- name varchar(100),
- profession varchar(100)
- );
- open u_cursor;
- while true do
- fetch u_cursor into uname,Upro;
- insert into tb_user_pro values(null,uname,Upro);
- end while;
- close u_cursor;
- end;
七、存储过程-条件处理程序-handle

八、存储函数

定义存储函数,完成如下需求:
计算从1累加到n的值,n为传入的参数值。

-
相关阅读:
【待解决】Not a Prefab scene
jasperreports6.12.2 could not load the following font解决方法
速卖通数据分析怎么看?速卖通数据分析工具有哪些?—站斧浏览器
解决Agora声网音视频在后台没有声音的问题
性能测试笔记
uniapp制作安卓原生插件踩坑
LeetCode 面试题 16.21. 交换和
日志打印的学习之log4j2(一)最简单的案例
java集合处理数据量过大导致超过Mysql in的最大值
eval()方法字符串转对象; 分别取对象属性名和属性的方法
- 原文地址:https://blog.csdn.net/weixin_55772633/article/details/132640169