-
linux入门---共享内存
共享内存的原理
通过前面的内容我们知道不同的进程通过虚拟地址空间和页表能够将自己的数据映射到内存上的不同地方比如说下面的图片:
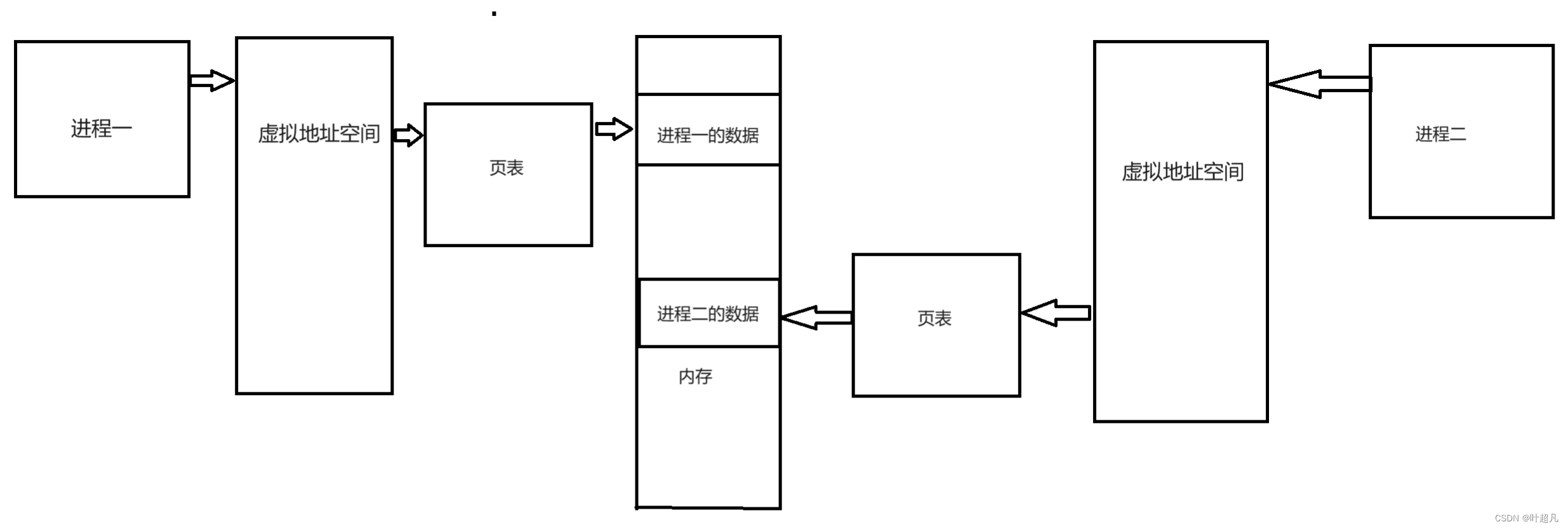
每个进程通过页表都会认为自己占用了整个内存,可实际上这个页表只是一个映射惯性,将不同进程的数据映射到内存中的不同地方,这样就可以在一定的程度上保证进程的独立性。通过上面我们知道创建一个进程时操作系统会给在内存上申请一块空间,然后将该空间通过页表映射到进程的虚拟地址上,那么这里就存在一个问题创建进程时操作系统能在内存上申请一块空间并进行映射,那在其他时候操作系统能不能也在内存上申请一块空间然后进行映射呢?答案是可以的,那么操作系统可以在内存上申请一块空间然后通过页表和进程地址空间将其映射到不同的进程上面,这样不同的进程就可以通过页表看到内存上的同一块的区域,然后一个进程就可以往这块区域上进行写入数据,另外一个进程就可以往这个进程上读取数据,那么我们就把这样的通信方式称为共享内存,
看到同一块空间就可以实现通信,等未来进程之间不想通信的时候就可以取消进程和内存的映射关系(称为去关联)然后释放内存(称为释放共享内存),那么我们就把操作系统申请的一块空间的方式称为共享内存,将共享内存和进程地址空间进行映射的过程称为挂接。共享内存的理解
在之前的学习我们知道malloc也能让程序向内存申请空间,那我们能使用malloc来实现共享内存进而实现通信吗?答案是不行的malloc虽然可以在物理内存上申请空间,也可以将物理内存和进程地址空间之间构建联系,但是一个进程mlloc出来的空间无法让另外一个进程看到,这个内存只能被申请的进程所使用,所以malloc不能实现共享内存,所以这里的共享内存实现的进程间的通信是后来程序员专门设计的,有一套单独的使用方法和体系,其次共享内存是一种通信的方式,所有想通信的进程都可以使用。所以操作系统中一定会同时存在很多的共享内存。最后我们来看看共享内存的概念:通过让不同的进程看到同一个内存快的通信方式就称为共享内存。那么接下来我们来看看与共享内存相关的函数以及对应的使用方法。
shmget函数
该函数的声明如下:
int shmget(key_t key,size_t size,int shmflg)这个函数的大致作用就是创建共享内存,函数具有三个参数:参数shmflg用来接收该函数所使用的和标记标记位,标记位有两个:
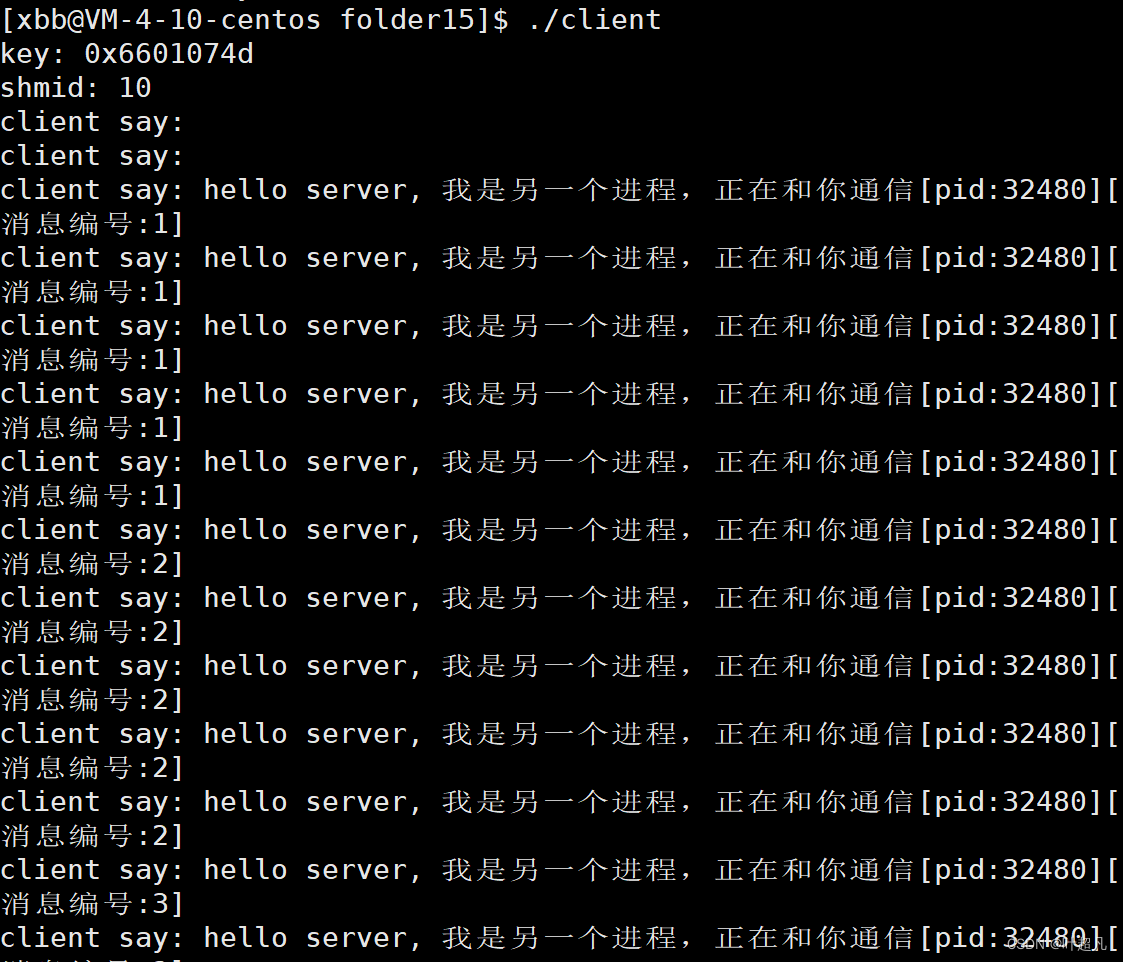
IPC_CREAT表示创建的共享内存如果不存在则创建共享内存,如果共享内存存在则获取那个共享内存,也就是得到共享内存的地址, IPC_EXCL标记位无法单独使用必须得结合IPC_CREAT来使用,表示如果不存在就创建共享内存如果存在该函数就直接报错返回,所以对于使用该标记位的用户来说如果创建成功,那么这个内存一定是一个新的刚刚创建的共享内存。 参数size用来表示共享内存的大小,你想要申请多大的一块空间用来通信你就传递多大的数据给这个参数,返回值:如果创建成功会返回共享内存的标识符,我们一般把这个标识符称为shmid如果创建失败就返回-1,这个标识符本质上就是一个数组下标,但是这个下标在不同的操作系统中的值是不同的,有些操作系统是从0 1 2 开始,有些操作系统是从几万开始,虽然他是数组下标但是他和文件系统的下标没有任何关系,未来我们想要对创建的共享内存进行操作时就可以使用shmid这个标识符来对共享内存进行操作就行。参数key的作用就是进行唯一性表示,key的值是多少不重要重要的是可以进行唯一性标识,使用函数ftok可以生成key值,我们来看看ftok函数的声明和作用:
ftok需要一个字符串参数和一个整形参数,然后再内部就可以使用一些算法来生成一个唯一的key值,然后两个进程就可以根据相同的key值访问到同一块共享内存,而要想获得相同的key就只用给ftok传递相同的参数即可,ftok函数可能运行成功也可能会运行失败,如果成功的话ftok函数就会返回key值,如果创建失败该函数就会返回-1和对应的错误码。key和shmid的区别
在c语言里面使用malloc申请空间的时候会多申请一块空间,多申请的空间会用来维护刚刚申请的空间,共享内存也是如此,共享内存在申请空间的时候也得多开辟一块空间用来管理申请的空间,所以共享内存=物理内存块+共享内存相关的属性,每个进程都可以像操作系统申请共享内存,而操作系统中存在多个进程,所以操作系统中注定存在多个共享内存,那进程在选着要读取或者写入的共享内存时,是如何保证这个共享内存是我们指定的那个呢?答案是通过key值来保证共享内存的唯一性,那这里就存在一个问题我们说shmget函数会返回一个值,我们把这个值称为shmid,以后我们要对共享内存进行操作的时候就可以使用这个shmid来进行操作,也就是说shmid和key值有着相同的功能都可以进行共享内存的标识,那为什么要创建两个东西呢?直接使用一个来进行标识不就够了嘛?那么这里我就可以举一个生活中的例子来进行解释,我们中国有14亿的人口,每个人出生之后就会拥有一个独一无二的身份证号,通过这个身份证号我们就可以标识一个人,那为什么还要给每个人取一个名字呢?直接使用身份证号来代替名字不就可以了吗?对吧!我们可以再思考一下,每个人都有一个独一无二的身份证号,那为什么学生要有学号,公司的人要有一个工号呢?对吧!直接使用身份证号来标定不就行了吗?那么之所以这么做是因为使用名字可以更加方便的社交,在短范围内能够更快的确定一个人,而在公司在学校里面使用工号或者学号来标定一个人是因为工号和学号可以更加方便更加容易的管理这个群体,如果都使用身份证号的话就会导致标识和管理的时候比较臃肿,那么这里也是同样的道理,对于我们使用者来说使用key值来标定共享内存太难了太复杂了,所以我们使用shmid来标识共享内存这样可以更加的方便和容易,而操作系统他不嫌麻烦他为了更加严谨的标识共享内存就必须得使用更加复杂的key值来进行标定,就好比政府机构在处理具体某个人的事情时,都会拿身份证号来标定某个人,因为身份证号更加的复杂更加的准确权威性更高,那么这就是key和shmid的区别,所以在操作系统里面两个进程要想看到同一个共享内存只需要使用相同的key值就行,通过key标定同一块内存之后就可以使用shmid来对内存进行操作,那key值在哪里存储的呢?我们说操作系统中存在多个共享内存所以要进行先描述在组织,那么描述共享内存的shm结构体中就存在一个字段专门用来记录共享内存的key值,所以key值会通过系统调用shmget设置进共享内存的属性中的用来表示共享内存在内核中的唯一性,shmid和key就相当于文件系统的fd和inode,一个是用来给操作系统看的一个是用来给我们操作者使用的,操作系统之所以这么做是为了方便标识符的解藕,用户层和操作系统层使用不同的东西来标识内存,这样用户层和操作系统层就不会发生相互的干扰,也就是一个层面出现了问题不会影响另外的一个层面,比如说你的学号和工号出现了问题不会影响你的身份证号,那么这就是key和shmid的区别。
ipcs -m和shmctl
有了上面的两个函数我们就可以来实现两个进程之间的通信,首先创建如下几个文件:

comm.hpp文件提供共享内存有关的操作方法,client.cc文件和server.cc文件之间实现通信,首先来实现comm.hpp文件,创建共享内存的前提是看到同一个共享内存所以我们得提供一个函数用来返回key值,因为这里就两个进程来实现通信,所以我们就定义两个宏分别表示两个地址:#define PATHNAME "." #define PROJ_ID 0x66 key_t getKey() { }- 1
- 2
- 3
- 4
- 5
- 6
然后在函数里面就调用ftok函数得到key值,因为创建的过程可能会失败所以就得使用if语句判断一下如果key值小于0就打印错误信息并使用exit函数结束进程,那么这里的代码如下:
key_t getKey() { key_t k =ftok(PATHNAME,PROJ_ID); if(k<0) { cerr<<errno<<" : "<<strerror(errno)<<endl; exit(2); } return k; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
得到key值之后我们就可以创建共享内存,但是只有一个进程需要创建共享内存另外一个进程只用得到该内存的shmid就可以了,所以两个进程调用shmget函数传递的标记位不同,所以我们创建一个名为getShmHelper函数专门用来调用shmget函数,然后再创建两个函数,getShm函数调用getShmHelper函数得到进程的shmid,createShm函数调用getShmHelper函数创建共享内存,因为shmget函数需要两个参数所以getShmHelper函数也需要两个参数一个表示key值一个表示该函数的标记位,因为两个函数对shmget函数进行了分类,所以shmget函数和creatshm函数就只需要一个参数表示key值就行,那么这里的函数实现如下:
int getShmHelper(key_t k,int flags) { int shmid =shmget(k,flags); if(shmid<0) { cerr<<errno<<" : "<<strerror(errno)<<endl; exit(2); } return shmid; } int createShm(key_t k) { return getShmHelper(k,IPC_CREAT|IPC_EXCL); } int getShm(key_t k) { return getShmHelper(k,IPC_CREAT); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
然后在server文件里面就创建共享内存,在client文件里面就可以得到共享内存的,那么首先就是调用getkey函数然后再分贝调用creatShm函数和getShm函数,那么这里的代码如下:
//server.cc #include"comm.hpp" int main() { key_t key=getKey(); printf("key: 0x%x\n", key);//key int shmid=createShm(key); printf("shmid: %d\n", shmid); //shmid return 0; } //client.cc #include"comm.hpp" int main() { key_t key=getKey(); printf("key: 0x%x\n", key);//key int shmid=getShm(key); printf("shmid: %d\n", shmid); //shmid return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
那么代码的运行结果如下:
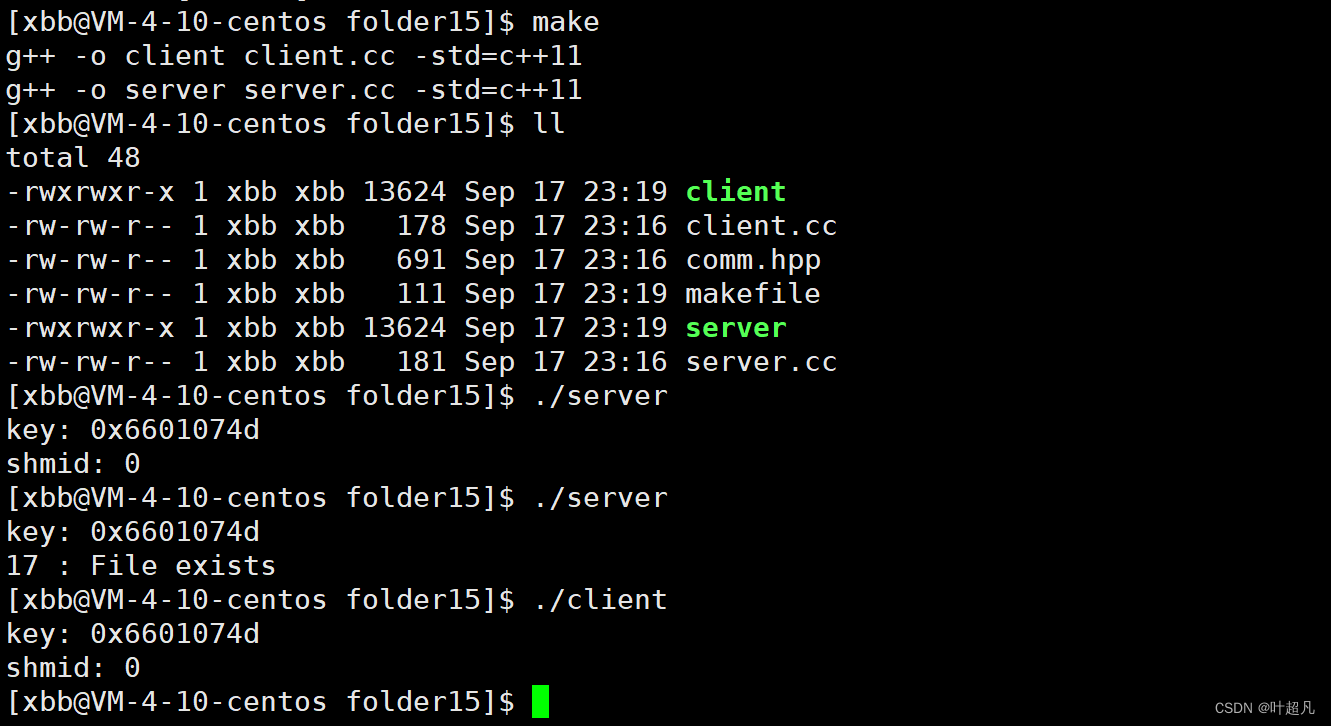 可以看到第一次运行server程序的时候没有任何问题成功的打印了key值和shmid,打印完程序就结束了运行,可是当我们再一次执行该程序的时候就会发现这里出现了问题,程序跟我们说文件已经存了,然后我们在执行client函数发现client函数执行的结果也是正确的,那么这就是共享内存的特点共享内存的生命周期是随操作系统不随进程的,所以进程退出是不会影响到共享内存的,这是system v版本通信的共性。使用ipcs -m指令可以查看到当前操作系统中存在的共享内存:
可以看到第一次运行server程序的时候没有任何问题成功的打印了key值和shmid,打印完程序就结束了运行,可是当我们再一次执行该程序的时候就会发现这里出现了问题,程序跟我们说文件已经存了,然后我们在执行client函数发现client函数执行的结果也是正确的,那么这就是共享内存的特点共享内存的生命周期是随操作系统不随进程的,所以进程退出是不会影响到共享内存的,这是system v版本通信的共性。使用ipcs -m指令可以查看到当前操作系统中存在的共享内存:
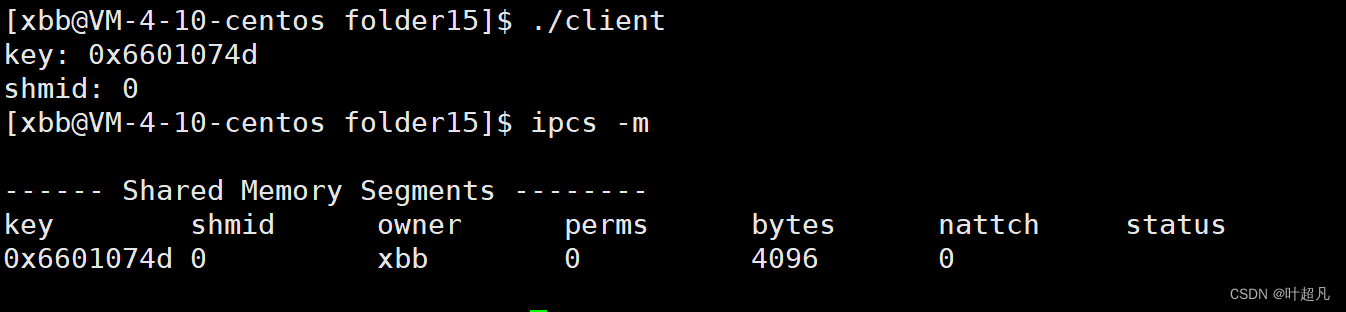
可以看到当前存在一个共享内存,该共享内存的key跟上面进程打印的一模一样,shmid的值为1,owner表示当前共享内存的拥有者,perms表示当前贡献内存的权限,bytes表示共享内存的大小,nattach表示当前有几个进程指向了这个共享内存,status表示共享内存的状态,那么我们要想删除共享内存的话就可以使用指令ipcrm -m shmid
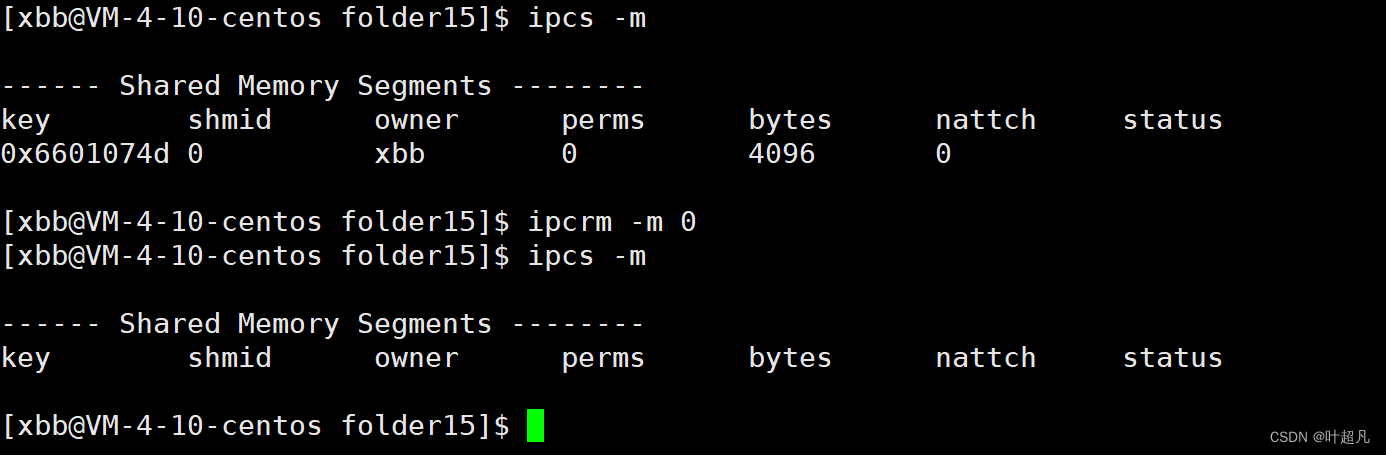
那么这是指令删除共享内存的方法,在程序里面使用shmctl可以对进程进行控制,我们来看看这个函数的介绍:
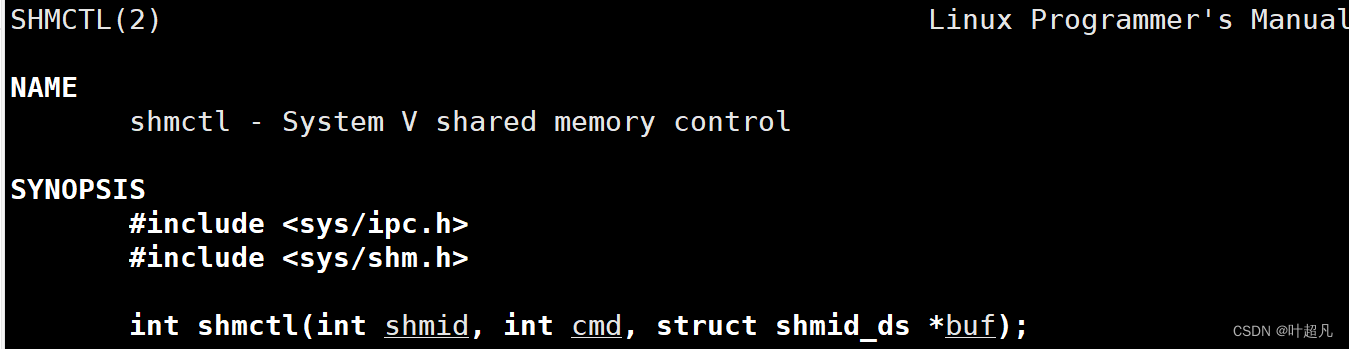
第一个参数表示对哪个共享内存进行控制(这里的控制包括删除),第二个参数是一个标记位表示如何对共享内存进行控制,我们来看看第二个参数有哪些标记位:
IPC_STAT的作用就是获取当前共享内存的属性,IPC_SAT就是将我们给的共享内存属性设计进执行的共享内存里面,IPC_RMID是删除指定的共享内存,因为我们又要获取共享内存的属性又要设置进共享内存的属性,所以我们这里还得需要第三个参数,如果我们想要获取属性的话就可以给这个参数传递一个对应的结构体指针,如果我们想要将属性设置进共享内存的话就可以将想要设置的属性放到这个参数里面,如果只是删除的话就之间将这个参数设置为空。这个函数的返回值如下:

如果删除失败了这个函数就会返回-1,所以我们就可以使用这个函数进行判断,那么有了这个函数之后就可以在comm.hpp函数里面添加一个delShm函数用来删除共享内存,这个函数的内部就是调用shmctl函数来实现,那么这里的代码如下:void delShm(int shmid) { if(shmctl(shmid,IPC_RMID,nullptr)==-1) { cerr<<errno<<" : "<<strerror(errno)<<endl; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后在server文件里面就可以调用这个函数:
#include"comm.hpp" int main() { key_t key=getKey(); printf("key: 0x%x\n", key);//key int shmid=createShm(key); printf("shmid: %d\n", shmid); //shmid delShm(shmid); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
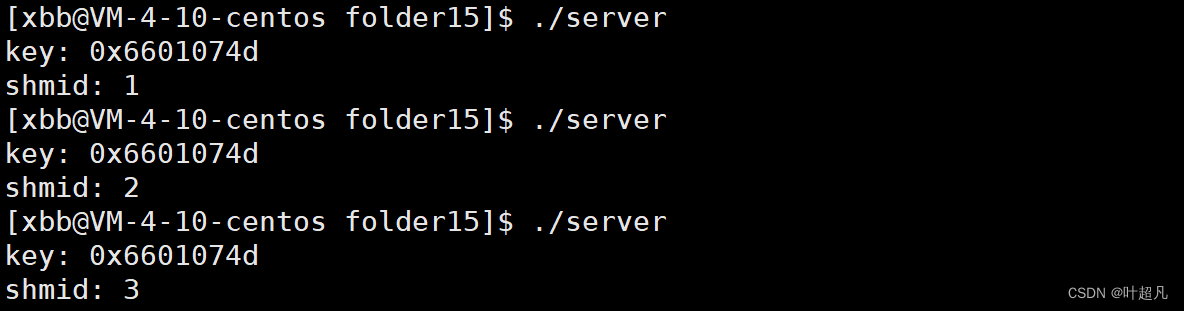
然后就可以看到多次调用server可执行程序也不会爆出文件存在的错误:
shmat
首先来看看这个函数的介绍:

第一个参数用来表示跟哪个共享内存相关联,你想跟哪个共享内存相关联就传递对应的shmid就可以,第二个参数表示将共享内存映射到虚拟地址空间的哪个位置这个参数大多数不管直接传递nullptr就可以了,第三个参数用来表示共享空间的权限这里就不用管直接传递0就可以了,表示既可以读也可以写,函数的返回值表示共享空间的起始地址。如果返回值为转化为整形类型之后的值为-1话就表示链接失败,我们的操作系统中采用的是64位系统,所以指针的大小是8个字节所以得使用long long来进行接收,那么有了这个函数之后我们就可以创建一个函数专门帮助进程连接共享内存:void *attachShm(int shmid) { void * mem=shmat(shmid,nullptr,0); if((long long)mem==-1) { cout<<errno<<" : "<<strerror(errno)<<endl; exit(3); } return mem; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
shmdt
既然有函数可以连接贡献内存,那么同样的道理也存在函数可以将进程和共享内存之间断开,那么这个函数就是shmdt,该函数的声明如下:

这个函数只有一个参数,如果你想将本进程与哪个共享内存取消关联就传递该共享内存的地址,也就是shmat函数的返回值,我们来看看这个函数的返回值:

如果取消关联成功这个函数就会返回0,失败就会返回-1,那么我们就可以创建一个函数对该函数进行封装:void detachShm(void *start) { if(shmdt(start) == -1) { std::cerr <<"shmdt: "<< errno << ":" << strerror(errno) << std::endl; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
共享内存的通信
那么这里就是server发送信息,client读取信心,在发送信息前得先与共享内存进行链接,链接结束后得取消关联然后删除共享内存:
#include"comm.hpp" int main() { key_t key=getKey(); printf("key: 0x%x\n", key);//key int shmid=createShm(key); printf("shmid: %d\n", shmid); //shmid char * start =(char*)attachShm(shmid);//链接共享内存 printf("attach success start:%s",start); //通信 detachShm(start);//取消链接 delShm(shmid); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在c语言中使用malloc之后我们会得到申请空间的起始地址,然后我们就可以使用该地址往内存里面写入信息,那么这里也是同样的道理,得到起始地址之后就可以直接根据地址往里面写入内容,要写入的信息如下:
const char* message = "hello server, 我是另一个进程,正在和你通信"; pid_t id = getpid(); int cnt = 1;- 1
- 2
- 3
然后我们就可以创建一个循环然后在循环里面使用fprintf函数往里面写入数据,fprintf的函数的声明如下:

第一个参数表示你要写入的位置,那么我们就可以将上面的start指针传递过去,那么这里的代码如下:#include"comm.hpp" int main() { key_t key=getKey(); printf("key: 0x%x\n", key);//key int shmid=createShm(key); printf("shmid: %d\n", shmid); //shmid char * start =(char*)attachShm(shmid);//链接共享内存 printf("attach success start:%s",start); //通信 const char* message = "hello server, 我是另一个进程,正在和你通信"; pid_t id = getpid(); int cnt = 1; while(true) { sleep(1); snprintf(start, MAX_SIZE, "%s[pid:%d][消息编号:%d]", message, id, cnt++); } detachShm(start);//取消链接 delShm(shmid); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
那么在client里面就可以使用while循环加printf函数打印地址里面的内容:
#include"comm.hpp" int main() { key_t key=getKey(); printf("key: 0x%x\n", key);//key int shmid=getShm(key); printf("shmid: %d\n", shmid); //shmid char* start=(char*)attachShm(shmid); while(true) { printf("client say: %s",start); sleep(1); } detachShm(start); delShm(shmid); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
然后我们先运行一下client进程,可以看到下面这样的场景:
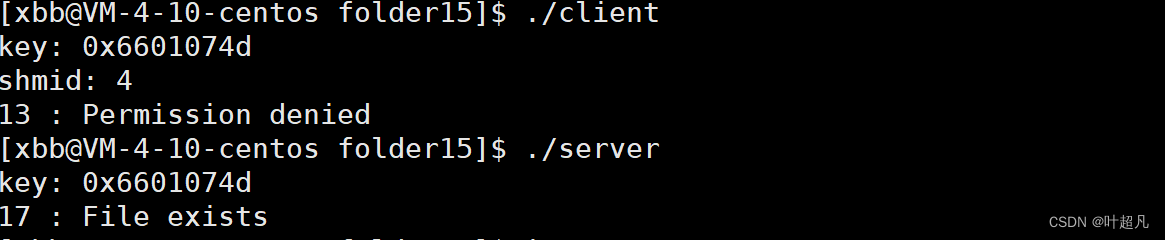
这里直接显示了没有权限并且执行server的时候显示文件已经存在了 ,那么出现这样的情况就说明client还没有执行到删除共享内存的时候就已经终止了,那这是为什么呢?我们来查看一下该共享内存的属性:

这些属性中存在一个名为prms的权限,这个权限为0表示任何人都没有读写权限,所以就会出现没有权限的情况,那么要想给这个内存设计权限就得在shmget函数中的标记位后面添加权限,那么这里就是在creatShm函数中添加权限:int createShm(key_t k) { return getShmHelper(k,IPC_CREAT|IPC_EXCL|0600); }- 1
- 2
- 3
- 4
再运行一下就会出现下面的情况:

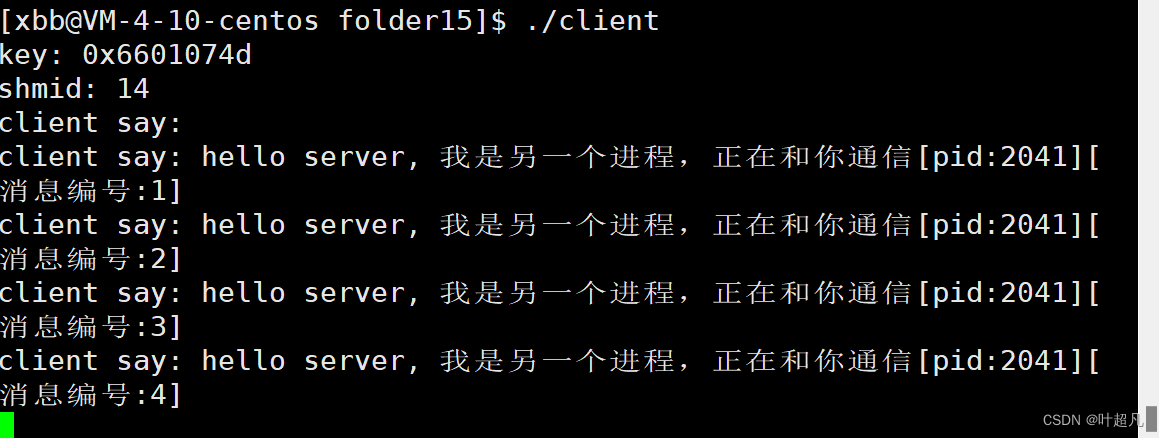
那么这就是共享内存的通信共享内存的优点
共享内存时所有通信中熟读最快的,能够大大的减少拷贝的次数,因为共享内存是直接将数据写入内存然后读端直接进入内存进行读取,而管道却不是这样的,比如说相同的数据使用管道需要进行4次数据拷贝:先将数据输入到缓冲区,再输入到管道,再输入到输出端对应的缓冲区,再输出到其他地方,所以会经过四次拷贝,而共享内存只需要拷贝两次,将数据写入到内存中,然后再将内存的数据写入到其他地方即可,那么这就是共享内存的有点。
共享内存的缺点
共享内存没有同步和互斥的操作,也就是没有对数据进行任何的保护,之前讲管道的时候我们说过管道一端的状态是会影响到另外一端的,比如说写段没有写入新的数据的时候读端是不会读的,但是共享内存却不会这样,当读端没有写入新的数据的时候读端是会读取之前的老数据的,比如说将写段的休眠时间改成5秒就会出现下面这样的情况:
多次读取相同的内容,那么这就是共享内存的缺点他不会对内存进行保护,也没有读端和写段的互斥和同步。共享内存的特点
共享内存一般建议是4KB的整数倍,如果你给的不是4KB的整数倍,操作系统会向上取整,比如说你申请了4097个字节但是操作系统给你申请的空间却是8192个字节,但是我们查看属性的时候依然是4097个字节,原因是操作系统申请的和你能够使用的是两码事,如果操作系统给你的比你想要的少,那么以后出现越界访问的话就是操作系统的问题,但是我申请多了你要的少了并不代表你能合法的使用我申请的所有空间,那么这就是共享内存的特点,申请的时候向上取整,用的时候只能按你申请的大小使用。
-
相关阅读:
入门力扣自学笔记107 C++ (题目编号593)
使用GPT-4生成训练数据微调GPT-3.5 RAG管道
close excel by keyword 根据关键字关闭 excel 窗口 xlwings 方式实现
报错AttributeError: Attempted to set WANDB to False, but CfgNode is immutable
第05、WireShark抓包-协议分析
【云原生系列】第四讲:Knative 之 Eventing
TypeScript入门
你的第一个基于Vivado的FPGA开发流程实践——二选一多路器
SkyEye助力火箭“一”飞冲天
【FFmpeg】ffmpeg使用drawtext过滤器在视频上叠加文字
- 原文地址:https://blog.csdn.net/qq_68695298/article/details/132818550
