-
视频分析【video analytics】的项目的关键因素 -- 如何选择合适的摄像头,存储设备,以及AI推理硬件?

参考指标
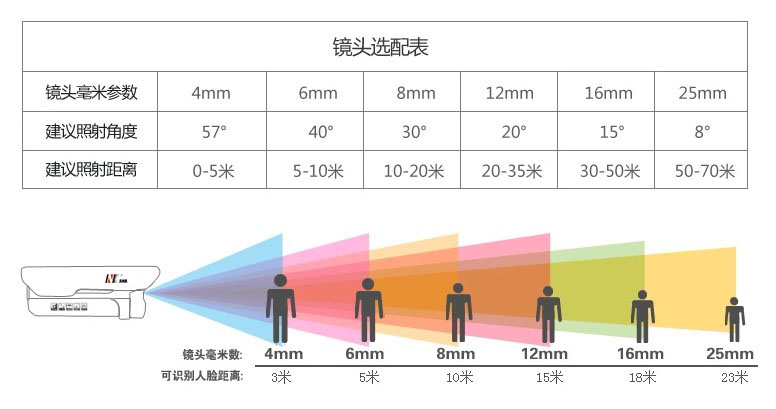
摄像机
通常的做法是将视频视为一系列图像(帧),并使用仅在图像上训练的深度神经网络模型来执行视频上的相似分析任务。在这篇论文中,我们表明,这种在图像上运行良好的深度学习模型在视频上也会运行良好的“信念飞跃”实际上是有缺陷的。
It is a common practice to think of a video as a sequence of images (frames), andre-use deep neural network models that are trained only on images for similaranalytics tasks on videos. In this paper, we show that this “leap of faith” t
-
相关阅读:
如何模糊匹配药品
【3D人脸】AI Mesh 数据工程调研
ONLYOFFICE Docs v7.5.0
锁竞争导致的慢sql分析
图上问题训练题解
VUE状态持久化,储存动态路由
R语言 R包:mFD 计算与分析功能多样性的一站式综合性
数据结构学习笔记(第四章 串)
(附源码)php养老院管理系统 毕业设计 202026
每天几道Java面试题:IO流(第五天)
- 原文地址:https://blog.csdn.net/wangyaninglm/article/details/132952388