-
并查集 size 的优化
我们把如下图所示的并查集,进行 union(4,9) 操作。
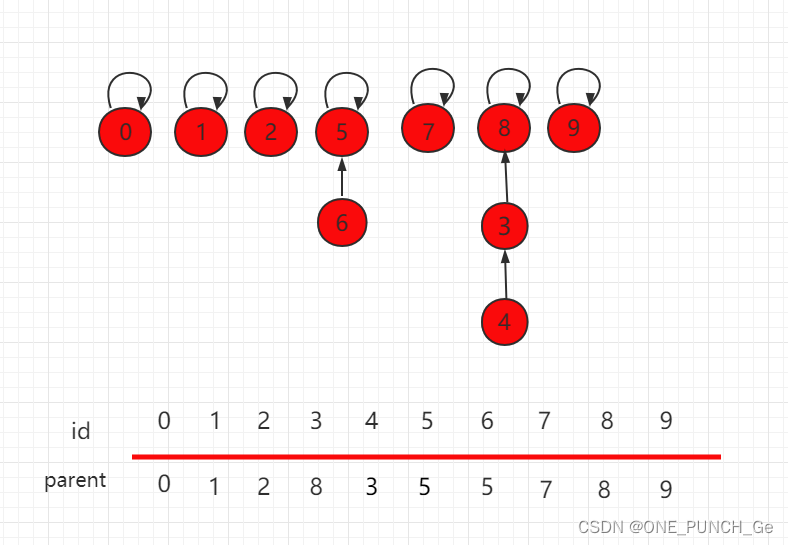
合并操作后的结构为:
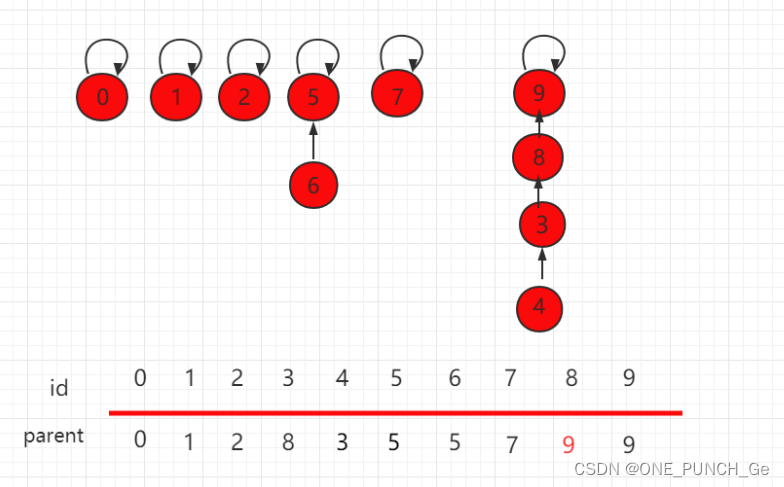
可以发现,这个结构的树的层相对较高,若此时元素数量增多,这样产生的消耗就会相对较大。解决这个问题其实很简单,在进行具体指向操作的时候先进行判断,把元素少的集合根节点指向元素多的根节点,能更高概率的生成一个层数比较低的树。
构造并查集的时候需要多一个参数,sz 数组,sz[i] 表示以 i 为根的集合中元素个数。
- // 构造函数
- public UnionFind3(int count){
- parent = new int[count];
- sz = new int[count];
- this.count = count;
- // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
- for( int i = 0 ; i < count ; i ++ ){
- parent[i] = i;
- sz[i] = 1;
- }
- }
在进行合并操作时候,根据两个元素所在树的元素个数不同判断合并方向。
- public void unionElements(int p, int q){
- int pRoot = find(p);
- int qRoot = find(q);
- if( pRoot == qRoot )
- return;
- if( sz[pRoot] < sz[qRoot] ){
- parent[pRoot] = qRoot;
- sz[qRoot] += sz[pRoot];
- }
- else{
- parent[qRoot] = pRoot;
- sz[pRoot] += sz[qRoot];
- }
- }
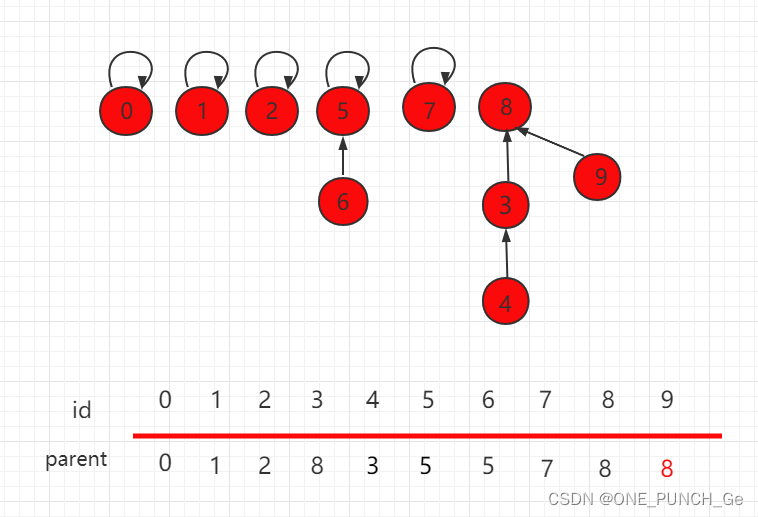
优化后,合并结果如下,9 指向父节点 8。
Java 实例代码
UnionFind3.java 文件代码:
- package runoob.union;
- /**
- * 并查集size的优化
- */
- public class UnionFind3 {
- // parent[i]表示第一个元素所指向的父节点
- private int[] parent;
- // sz[i]表示以i为根的集合中元素个数
- private int[] sz;
- // 数据个数
- private int count;
- // 构造函数
- public UnionFind3(int count){
- parent = new int[count];
- sz = new int[count];
- this.count = count;
- // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
- for( int i = 0 ; i < count ; i ++ ){
- parent[i] = i;
- sz[i] = 1;
- }
- }
- // 查找过程, 查找元素p所对应的集合编号
- // O(h)复杂度, h为树的高度
- private int find(int p){
- assert( p >= 0 && p < count );
- // 不断去查询自己的父亲节点, 直到到达根节点
- // 根节点的特点: parent[p] == p
- while( p != parent[p] )
- p = parent[p];
- return p;
- }
- // 查看元素p和元素q是否所属一个集合
- // O(h)复杂度, h为树的高度
- public boolean isConnected( int p , int q ){
- return find(p) == find(q);
- }
- // 合并元素p和元素q所属的集合
- // O(h)复杂度, h为树的高度
- public void unionElements(int p, int q){
- int pRoot = find(p);
- int qRoot = find(q);
- if( pRoot == qRoot )
- return;
- // 根据两个元素所在树的元素个数不同判断合并方向
- // 将元素个数少的集合合并到元素个数多的集合上
- if( sz[pRoot] < sz[qRoot] ){
- parent[pRoot] = qRoot;
- sz[qRoot] += sz[pRoot];
- }
- else{
- parent[qRoot] = pRoot;
- sz[pRoot] += sz[qRoot];
- }
- }
- }
-
相关阅读:
reids cluster模式的两种配置方式
4.k8s:cronJob计划任务,初始化容器,污点、容忍,亲和力,身份认证和权限
苹果证书分类及作用详解,助力开发者高效管理应用程序
抗击疫情静态HTML网页作业作品 大学生抗疫感动专题页设计制作成品 简单DIV CSS布局网站
观测云目前支持多少种图表?
六、Hive数据仓库应用之Hive事务(超详细步骤指导操作,WIN10,VMware Workstation 15.5 PRO,CentOS-6.7)
小黑星巴克冰镇浓缩leetcode之旅:21. 合并两个有序链表
Machine Learning Model
Matplotlib设置限制制作
java基于微信小程序的寻医问药 医院预约挂号系统 uniapp小程序
- 原文地址:https://blog.csdn.net/weixin_45953332/article/details/132954946
