-
search_engine:搜索引擎实现
目录
前言: 这里实现一个基于boost官方文档的搜索引擎。,但是不只可以用来搜索boost, 修改引入的内容, 就可以变成其它的搜索引擎, 比如可以用来搜索cpp官网文档内容等.
一.项目背景及原理
1.背景
搜索引擎很多互联网大厂都做过,但是他们做的是由很多人共同完成的大型项目,是一个人没法完成的,不过,可以通过实现一个"小"的搜索引擎,来揣测出这些大型搜索引擎是如何做的。
这个搜索引擎项目就是在一个网站内搜索,搜索的数据更垂直,数据量更小,实现相对比较简单。
不过呢,虽然实现的是boost搜索引擎,但是只要修改所引入的文档内容,以及相应的就可以变成其它的搜索引擎,例如JAVA搜索引擎、STL搜索引擎等。
实现的内容:

我们用百度搜索引擎搜索Boost,可以看到网页的title、网页内容的摘要描述、即将跳转的网站url。
搜索引擎项目要实现的内容就是这三大块。
2.原理
① 爬虫程序抓取网页信息:搜索引擎会使用爬虫程序在全网中抓取相关的HTML网页信息,并将其存储在服务器端的磁盘中(这里采用离线下载的方式获取网页信息)。
② 数据预处理:对抓取到的HTML文件进行去标签化和数据清理,即只保留网页文件中的主要信息(标题、正文、URL等)。
③ 建立索引:对预处理后的数据建立索引,以便快速检索。这里的索引包括正排索引和倒排索引。正排索引是根据文档ID查找文档内容,而倒排索引是根据文档内容查找文档ID(建立倒排索引要根据文档内容进行分词, 整理成不重复的多个关键字,再对应到相应的文档ID)。
④ 搜索查询:用户在浏览器中发起HTTP请求,服务端根据请求中的关键字在索引中查找相关文档,并将结果返回给客户端。
二.技术栈及项目环境
1.技术栈
后端:C/C++(C++11), STL, 准标准库Boost, jsoncpp, cppjieba, cpp-httplib
前端:html, css, js, jQuery, Ajax
2.项目环境
CentOS 7, vim, g++, Makefile, VSCode
3.环境准备
boost官方文档: Boost C++ Libraries
boost库安装: sudo yum install -y boost-devel
cppjieba: GitHub - yanyiwu/cppjieba: "结巴"中文分词的C++版本
注: 安装后, 要将deps下的limonp拷贝一份放到include/cppjieba内
这个安装后可能存在deps下的limonp内无数据, 就要再安装一下limonp: GitHub - yanyiwu/limonp at a269e34dc4948d5a9209e21a7887b52daa0d3e78
安装后把limonp/include下的limonp拷贝到刚才安装的cppjieba的include/cppjieba中
安装方式:
cppjieba: git clone GitHub - yanyiwu/cppjieba: "结巴"中文分词的C++版本limonp: git clone GitHub - yanyiwu/limonp: C++ headers(hpp) library with Python style.
使用cppjieba需要使用较新版本的gcc、g++, 可以自行搜索升级方式jsoncpp安装: sudo yum install -y jsoncpp-devel
cpp-httplib: cpp-httplib: cpp-httplib - Gitee.com
cpp-httplib安装: git clone cpp-httplib: cpp-httplib
三.模块划分

四. 遇到的问题及其解决方法
1.搜索结果出现重复文档的问题
在搜索模块 searcher 中, 如果根据关键字的各个词检索查找时, 直接创建一个存储倒排拉链的vector数组, 并且在获得当前关键字的倒排拉链后直接插入到这个vector中, 那么就可能出现一个问题: 搜索结果出现重复文档的问题.
原因: 搜索关键字被jiaba分词后的几个词对应在同一个文档((即同一个doc_id))出现, 导致倒排拉链中存在重复情况. 进而出现了多个一样的搜索结果.
存在这种问题的搜索模块实现如下:
- #pragma once
- #include
- #include
- #include "index.hpp"
- #include "util.hpp"
- #include "log.hpp"
- namespace ns_searcher
- {
- class Searcher
- {
- private:
- ns_index::Index *index; // 供系统进行查找的索引
- public:
- Searcher() {}
- ~Searcher() {}
- public:
- // 初始化搜索引擎
- void InitSearcher(const std::string &input)
- {
- // 1. 获取index对象
- index = ns_index::Index::GetInstance();
- LogMessage(DEBUG, "获取index单例成功...");
- // 2. 根据index对象建立索引
- index->BuildIndex(input);
- LogMessage(DEBUG, "建立正排和倒排索引成功...");
- }
- // 根据用户的搜索关键词, 查找结果, 并返回给用户搜索结果
- // query: 用户的搜索关键词, json_string: 返回给用户浏览器的搜索结果
- void Search(const std::string &query, std::string *json_string)
- {
- // 1. 分词: 对query按照searcher的要求进行分词
- std::vector
- ns_util::JiebaUtil::CutString(query, &words);
- // 2. 检索触发: 根据分词的各个"词进行index索引查找(建立index是忽略大小写的,所以搜索的关键字也要忽略)",
- ns_index::InvertedList inverted_list_all;
- for(std::string word : words)
- {
- // 将分的词变成小写
- boost::to_lower(word);
- // 根据倒排索引哈希表中的关键字word获得倒排拉链
- ns_index::InvertedList *inverted_list = index->GetInvertedList(word);
- if(nullptr == inverted_list) continue;
- inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());
- }
- // 3. 合并排序: 汇总查找结果, 按照相关性权重(weight)降序排序
- std::sort(inverted_list_all.begin(), inverted_list_all.end(), \
- [](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2){
- return e1.weight > e2.weight;
- });
- // 4. 构建json: 根据查找出来的结果, 构建json字符串
- // 创建Json对象root, 用于保存所有的文档信息
- Json::Value root;
- for(auto &item : inverted_list_all)
- {
- // 根据doc_id获取正排索引的文档信息
- ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);
- if(nullptr == doc) continue;
- // 创建Json对象elem, 添加标题, 摘要, url信息
- Json::Value elem;
- elem["title"] = doc->title;
- // content是文档的去标签的结果, 但是不是想要的, 想要的是其中一部分, 即摘要
- // 通过GetDesc函数获得关键字前后的内容(摘要)
- elem["desc"] = GetDesc(doc->content, item.words[0]);
- elem["url"] = doc->url;
- // 将elem添加到结果root中
- root.append(elem);
- }
- Json::FastWriter writer;
- *json_string = writer.write(root);
- }
- };
- }
那么如何解决?
首先需要重新创建一个结构体InvertedElemPrint, 不能再使用之前的index的倒排索引的结构体, 而这个结构体中将原来的string类型的word, 变成了vector
类型, 这样这一个结构体如果遇到多个词对应在同一个文档(同一个doc_id)的情况下, 就可以把这多个词都插入到vector数组中. 接下来可以创建一个token_map哈希表, 用于doc_id与InvertedElemPrint建立映射关系, 目的是为了根据doc_id去重. 遍历根据doc_id获得到的倒排拉链, 然后创建或获得doc_id在哈希表中所映射的InvertedElemPrint, 然后将InvertedElem内的关键字word放入InvertedElemPrint的vector数组中. 这样即使有doc_id相同的关键字也都会放入同一个vector中, 完成去重的效果.
最后创建一个存储InvertedElemPrint的vector数组, 并把完成去重后的每一个不重复的doc_id倒排索引放入其中. 用于后面进行合并排序, 汇总查找结果, 并按照相关性权重(weight)降序排序.
解决问题后的搜索模块实现如下:
- // 为了解决搜索结果出现重复文档的问题(搜索关键字被jiaba分词后的几个词对应在同一个文档(即同一个doc_id)出现, 导致倒排拉链中存在重复情况)
- struct InvertedElemPrint
- {
- uint64_t doc_id; // 文档ID
- int weight; // 文档权重
- // 可能多个词对应同一个ID, 所以采用数组的结构, 将搜索结果合并
- std::vector
- InvertedElemPrint() : doc_id(0), weight(0) {}
- };
- class Searcher
- {
- private:
- ns_index::Index *index; // 供系统进行查找的索引
- public:
- Searcher() {}
- ~Searcher() {}
- public:
- // 初始化搜索引擎
- void InitSearcher(const std::string &input)
- {
- // 1. 获取index对象
- index = ns_index::Index::GetInstance();
- LogMessage(DEBUG, "获取index单例成功...");
- // 2. 根据index对象建立索引
- index->BuildIndex(input);
- LogMessage(DEBUG, "建立正排和倒排索引成功...");
- }
- // 根据用户的搜索关键词, 查找结果, 并返回给用户搜索结果
- // query: 用户的搜索关键词, json_string: 返回给用户浏览器的搜索结果
- void Search(const std::string &query, std::string *json_string)
- {
- // 1. 分词: 对query按照searcher的要求进行分词
- std::vector
- ns_util::JiebaUtil::CutString(query, &words);
- // 2. 检索触发: 根据分词的各个"词进行index索引查找(建立index是忽略大小写的,所以搜索的关键字也要忽略)",
- // 存放全部文档的倒排索引, 用于后面根据权重排序
- std::vector
inverted_list_all; - // doc_id与InvertedElemPrint建立映射关系, 目的是为了根据doc_id去重
- std::unordered_map<uint64_t, InvertedElemPrint> tokens_map;
- for(std::string word : words)
- {
- // 将分的词变成小写
- boost::to_lower(word);
- // 根据倒排索引哈希表中的关键字word获得倒排拉链
- ns_index::InvertedList *inverted_list = index->GetInvertedList(word);
- if(nullptr == inverted_list) continue;
- // 遍历倒排拉链, 把重复的doc_id合并
- for(const auto &elem : *inverted_list)
- {
- // 采用引用的方式获得哈希表为doc_id映射的倒排拉链
- auto &item = tokens_map[elem.doc_id]; // 如果没有就创建, 如果有就获得
- // 这个item一定是doc_id相同的
- item.doc_id = elem.doc_id;
- // 如果存在相同的doc_id, 权值相加
- item.weight += elem.weight;
- // 将InvertedElem内的关键字word放入InvertedElemPrint的vector数组中
- // 这样即使有doc_id相同的关键字也都会放入同一个vector中, 完成去重的效果
- item.words.push_back(elem.word);
- }
- }
- // 完成去重后, 把每一个不重复的doc_id倒排索引放入记录全部文档倒排索引的数组中
- for(const auto &item : tokens_map)
- {
- inverted_list_all.push_back(std::move(item.second));
- }
- // 3. 合并排序: 汇总查找结果, 按照相关性权重(weight)降序排序
- std::sort(inverted_list_all.begin(), inverted_list_all.end(), \
- [](const InvertedElemPrint &e1, const InvertedElemPrint &e2){
- return e1.weight > e2.weight;
- });
- // 4. 构建Json: 根据查找出来的结果, 构建Json字符串
- // 创建Json对象root, 用于保存所有的文档信息
- Json::Value root;
- for(auto &item : inverted_list_all)
- {
- // 根据doc_id获取正排索引的文档信息
- ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);
- if(nullptr == doc) continue;
- // 创建Json对象elem, 添加标题, 摘要, url信息
- Json::Value elem;
- elem["title"] = doc->title;
- // content是文档的去标签的结果, 但是不是想要的, 想要的是其中一部分, 即摘要
- // 通过GetDesc函数获得关键字前后的内容(摘要)
- elem["desc"] = GetDesc(doc->content, item.words[0]);
- elem["url"] = doc->url;
- // 将elem添加到结果root中
- root.append(elem);
- }
- // FastWriter用于转换为字符串时采用快速的方法
- Json::FastWriter writer;
- // 调用write方法, 将Json对象root快速的转换为字符串
- *json_string = writer.write(root);
- }
- // 获取摘要
- std::string GetDesc(const std::string &html_content, const std::string &word)
- {
- // 找到关键字word在html content中的首次出现, 然后往前找100字节(如果没有50个, 就从begin开始), 往后找100字节(如果没有100个, 就到end结束)
- // 截取这部分内容
- const int prev_step = 100;
- const int next_step = 100;
- // 1. 找到首次出现关键字的位置
- auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){
- return (std::tolower(x) == std::tolower(y));
- });
- // 没有找到, 报错
- if(iter == html_content.end())
- {
- LogMessage(WARNING, "not exists word");
- return "None1";
- }
- // 获得关键字位置与内容开头的距离
- int pos = std::distance(html_content.begin(), iter);
- // 2. 获取start, end
- int start = 0;
- int end = html_content.size() - 1;
- // 如果之前有大于100个字节, 就更新开始位置
- if(pos > start + prev_step) start = pos - prev_step;
- // 如果之后有大于100个字节, 就更新结束位置
- if(pos + next_step < end) end = pos + next_step;
- // 3. 截取子串
- // 开头比结尾大, 报错
- if(start >= end)
- {
- LogMessage(WARNING, "start >= end");
- return "None2";
- }
- // 截取start和end内的子串, 作为摘要
- std::string desc = html_content.substr(start, end - start);
- desc += "...";
- // 返回摘要
- return desc;
- }
- };
2.实现httplib功能的问题
实现httplib的过程中遇到的问题可以说很多,究其原因是对TCP、HTTP、多路转接的理解不够深刻,同时使用经验较少,导致出现了很多的低级错误(包括请求与响应不符合http协议格式的低级错误)。
解决的方式也很简单,反复查看相关文档,多次理解相关协议与方案,编写代码并反复进行调试与修改。
五. 项目特点
1.文档记录
文档的作用是为了显示出当前项目的运行情况,是否正常运行,同时也作为一种调试的手段,是很有作用的。
这里通过实现一个单例类,这个类将标准输出和标准错误的内容重定向到日志文件中,除了该类,又实现了一个日志函数,使用可变参数列表,用来接收不同的日志内容。调用上,只需要在项目执行前,调用类内的enable函数,然后在需要日志的位置,调用LogMessage函数,添加需要的日志即可。
实现:
- #pragma once
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #define DEBUG 0
- #define INFO 1
- #define WARNING 2
- #define FATAL 3
- const char *log_level[] = {"DEBUG", "INFO", "WARINING", "FATAL"};
- #define LOGFILE "http_server.log"
- // 下面的Log类和logMessage是两种处理日志的方式
- // 管理日志文件, 将日志信息重定向到日志文件中
- // 日志类(设置为单例模式)
- class Log
- {
- private:
- // 设置为单例模式
- Log() : logFd(-1) {}
- Log(const Log&) = delete;
- void operator=(const Log&) = delete;
- static Log *instance;
- static std::mutex mtx;
- public:
- static Log *GetInstance()
- {
- if(nullptr == instance)
- {
- mtx.lock();
- if(nullptr == instance)
- {
- instance = new Log();
- }
- mtx.unlock();
- }
- return instance;
- }
- void enable()
- {
- // 修改文件掩码为0, 防止系统默认掩码影响打开文件的权限
- umask(0);
- // 打开文件
- logFd = open(LOGFILE, O_WRONLY | O_CREAT | O_TRUNC, 0666);
- // 如果logFd为-1, 说明打开文件错误
- assert(logFd != -1);
- // 将标准输出和标准错误的内容重定向到日志文件中
- dup2(logFd, 1);
- dup2(logFd, 2);
- }
- ~Log()
- {
- if (logFd != -1)
- {
- // 将日志文件中所有修改过的数据刷新到磁盘上
- fsync(logFd);
- // 关闭日志文件
- close(logFd);
- }
- }
- private:
- int logFd;
- };
- Log* Log::instance = nullptr;
- std::mutex Log::mtx;
- // 将日志信息直接输出到标准输出或标准错误中
- void LogMessage(int level, const char *format, ...)
- {
- assert(level >= DEBUG);
- assert(level <= FATAL);
- char *name = getenv("USER");
- char logInfo[1024];
- // 定义ap变量, 用于存储可变参数列表
- va_list ap;
- // 初始化ap变量, 使其指向可变参数列表中的第一个参数
- va_start(ap, format);
- // 格式化日志信息, 使用给定的格式字符串和可变参数列表中的参数来生成格式化后的字符串, 并将其存储在logInfo中
- vsnprintf(logInfo, sizeof(logInfo) - 1, format, ap);
- // 清理ap变量, 避免内存泄漏等问题
- va_end(ap);
- // 如果日志级别为FATAL, 使用标准错误; 否则, 使用标准输出
- // 输出信息包括日志级别, 时间戳, 用户名, 日志信息, 日志信息所在源文件, 日志信息所在行号
- FILE *out = (level == FATAL) ? stderr : stdout;
- fprintf(out, "%s | %u | %s | %s\n",
- log_level[level],
- (unsigned int)time(nullptr),
- name == nullptr ? "unknow" : name,
- logInfo);
- fflush(out); // 将C缓冲区中的数据刷新到OS中
- fsync(fileno(out)); // 将OS中的数据刷新到磁盘中
- }
2.竞价排名
(1)竞价排名定义
竞价排名是一种按效果付费的网络推广方式, 通过购买相关关键词, 然后给予出价获得竞价排名, 展现给目标用户, 从而获取用户点击.
很多浏览器都存在竞价排名, 因此这里我也实现一个简单的竞价排名.
(2)实现方法
首先创建一个文档, 把参与竞价排名的网址url以及出价用 | 分割放入advertise.txt文档中, 每个网址之间用 \n 分隔.
然后在index中创建advertise_rec哈希表, 用于记录竞价信息. 通过AddAdvertise函数从advertise.txt文档中读取信息并插入到advertise_rec哈希表中. 再实现一个直接返回advertise_rec的函数, 用于将advertise_rec哈希表给到searcher中.
最后在searcher中先通过index的AddAdvertise函数获取竞价信息, 再获取advertise_rec哈希表, 然后当遍历倒排拉链, 把重复的doc_id合并实现后, 再一次遍历, 判断该关键字对应的文档是否参与竞价排名, 如果参与, 就修改其权重, 并且在title后面加上[广告]标识.
(3)实现
advertise.txt:
- https://www.boost.org/doc/libs/1_82_0/doc/html/boost_dll/f_a_q_.html|2000\n
- https://www.boost.org/doc/libs/1_82_0/doc/html/interprocess/acknowledgements_notes.html|4000\acknowledgements_notes\n
- https://www.boost.org/doc/libs/1_82_0/doc/html/quickbook/change_log.html|3000\n
index:
- std::unordered_map
- // 返回竞价信息哈希表
- std::unordered_map
- {
- return advertise_rec;
- }
- // 添加竞价排名信息
- bool AddAdvertise()
- {
- const std::string Ad = "data/Ad/advertise.txt";
- // 将广告信息读取到advertise中
- std::string advertise;
- // 以输入模式(只读)打开file_path
- std::ifstream in(Ad, std::ios::in);
- // 文件没有打开成功
- if(!in.is_open())
- {
- LogMessage(WARNING, "open file %s error", Ad.c_str());
- return false;
- }
- // line用于读取in输入文件流的一行文本
- std::string line;
- while(std::getline(in, line))
- {
- // 提取url
- std::string url = line.substr(0, line.find('|'));
- // 提取出价
- int price = atoi(line.substr(line.find('|') + strlen("\3")).c_str());
- // 插入advertise数组中
- advertise_rec[url] = price;
- }
- return true;
- }
searcher:
- // 初始化搜索引擎
- void InitSearcher(const std::string &input)
- {
- // 1. 获取index对象
- index = ns_index::Index::GetInstance();
- LogMessage(DEBUG, "获取index单例成功...");
- // 2. 根据index对象建立索引
- index->BuildIndex(input);
- LogMessage(DEBUG, "建立正排和倒排索引成功...");
- // 3. 获取竞价信息
- index->AddAdvertise();
- LogMessage(DEBUG, "获取竞价信息成功...");
- }
- // 获取竞价排名信息
- std::unordered_map
- // 再次遍历, 判断是否参与竞价排名, 并对其进行修改
- for(const auto &elem : *inverted_list)
- {
- auto &item = tokens_map[elem.doc_id];
- // 获得文档
- ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);
- // 根据url查找该文档是否参与了竞价排名, 并根据出价修改所占权重, 进而修改其排序
- // 同时在其标题后写上 [广告] 标识
- for(auto &ad_pair : advertise_rec)
- {
- if(ad_pair.first == doc->url)
- {
- // 对应参与竞价排名的文档的标题加上[广告]
- doc->title += "[广告]";
- // 根据原权重以及竞价更改权重
- item.weight = item.weight * (ad_pair.second / 10);
- }
- }
- }
(4)测试结果
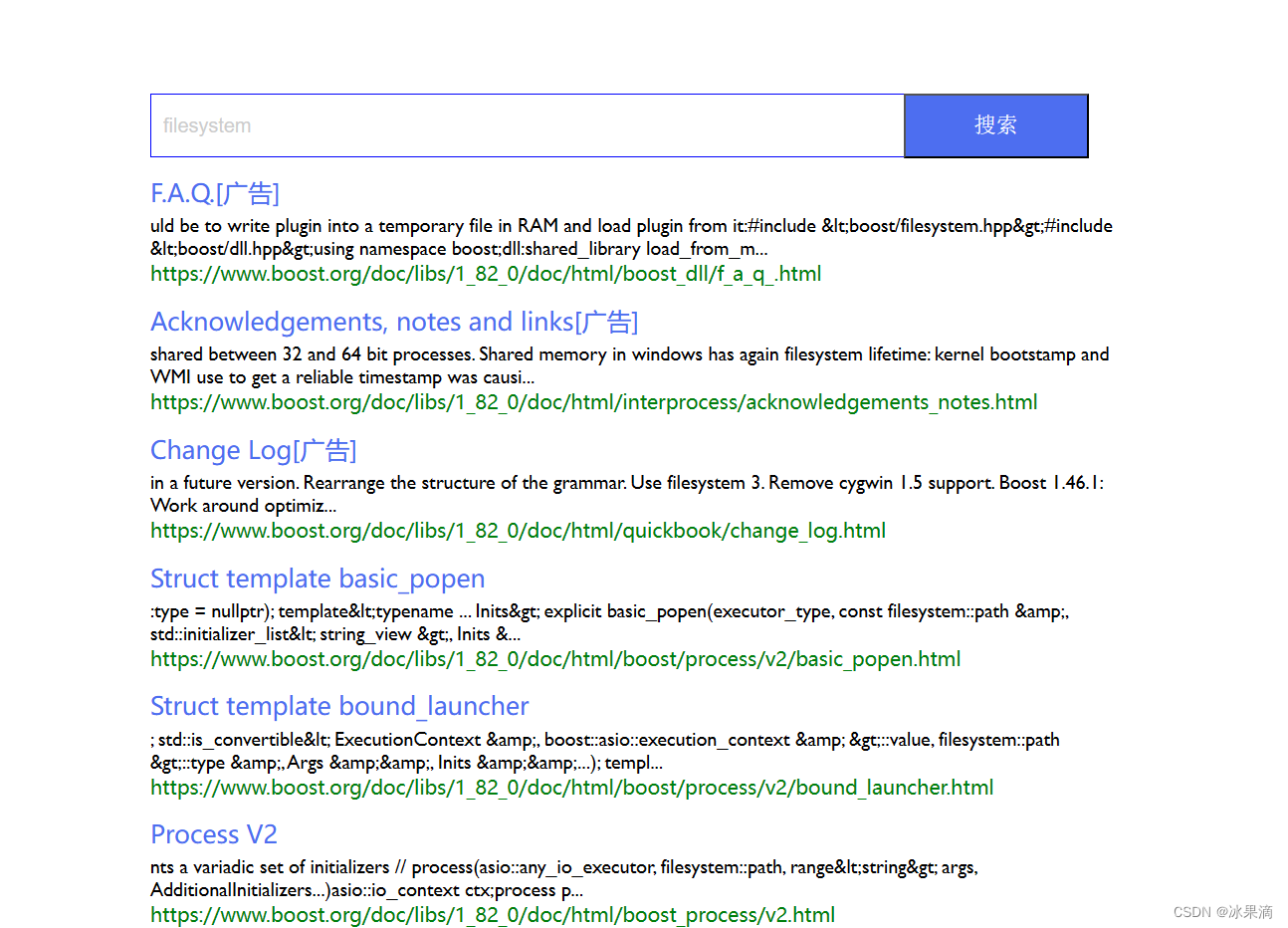
3.去掉暂停词
我们平常在搜索时,无论我们是否写了 "了", "的", "吗" 类似这样的字,搜索出来的结果是没有变化的,因为这些词在搜索中是没有什么作用的,我们想搜的内容是不会因为这些词而发生变化。而去掉这些暂停词之后,会使得搜索变得更快。这里我也实现了该功能。
通过在util中实现一个JiebaUtil单例类,在进行Jieba分词的过程中,通过将这些词与暂停词文档进行对比,如果是暂停词,就将该词去掉。
实现:
- // 定义jieba所需的文件路径
- const char* const DICT_PATH = "./dict/jieba.dict.utf8"; // 中文单词及其词频信息
- const char* const HMM_PATH = "./dict/hmm_model.utf8"; // 用于对未登录词进行分词
- const char* const USER_DICT_PATH = "./dict/user.dict.utf8"; // 用户自定义词典文件路径
- const char* const IDF_PATH = "./dict/idf.utf8"; // 逆文档频率文件路径
- const char* const STOP_WORD_PATH = "./dict/stop_words.utf8"; // 暂停词(停用词)文件路径
- // 设置为单例模式
- class JiebaUtil
- {
- private:
- //static cppjieba::Jieba jieba;
- cppjieba::Jieba jieba;
- std::unordered_map
- private:
- JiebaUtil(): jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH)
- {}
- JiebaUtil(const JiebaUtil&) = delete;
- JiebaUtil &operator=(const JiebaUtil&) = delete;
- static JiebaUtil *instance;
- public:
- // 获得唯一实例
- static JiebaUtil* get_instance()
- {
- static std::mutex mtx;
- if(nullptr == instance)
- {
- mtx.lock();
- if(nullptr == instance)
- {
- instance = new JiebaUtil();
- instance->InitJiebaUtil();
- }
- mtx.unlock();
- }
- return instance;
- }
- // 初始化(用于去掉暂停词)
- void InitJiebaUtil()
- {
- // 读取暂停词文件
- std::ifstream in(STOP_WORD_PATH);
- if(!in.is_open())
- {
- LogMessage(FATAL, "load stop words file error");
- return;
- }
- std::string line;
- while(std::getline(in, line))
- {
- // 将暂停词插入到哈希表中
- stop_words.insert({line, true});
- }
- in.close();
- }
- void CutStringHelper(const std::string &src, std::vector
- {
- // 用Jieba分词
- jieba.CutForSearch(src, *out);
- // 去掉暂停词
- for(auto iter = out->begin(); iter != out->end(); )
- {
- auto it = stop_words.find(*iter);
- if(it != stop_words.end())
- {
- // 说明string是暂停词, 需要去掉
- iter = out->erase(iter);
- }
- else
- {
- ++iter;
- }
- }
- }
- void CutS(const std::string &src, std::vector
- {
- jieba.CutForSearch(src, *out);
- }
- public:
- // 用Jieba分割单词并, 去掉暂停词
- static void CutStringRemove(const std::string &src, std::vector
- {
- ns_util::JiebaUtil::get_instance()->CutStringHelper(src, out);
- }
- // 只用Jieba分割单词, 不去掉暂停词
- static void CutString(const std::string &src, std::vector
- {
- ns_util::JiebaUtil::get_instance()->CutS(src, out);
- }
- };
- JiebaUtil *JiebaUtil::instance = nullptr;
4.模拟实现httplib库
如果使用httplib库,那么http_server这一模块可以很轻松的完成,只需要调用其中的函数即可,但是这个httplib库在实际的公司项目中基本上是不会使用这个httplib库的,因为这个库是存在一些缺点的,可能会出现一些问题。
因此,这里我自己实现该项目所需用到的相关httplib中的接口,包括TCP和http的实现。
其中TCP是按照多路转接的方案进行实现的,用到了epoll。
具体代码可以查看最终版代码。
六. 最终版代码
gitee仓库:基于某个网站的站内搜索引擎
-
相关阅读:
重量级ORM框架--持久化框架Hibernate【基础入门】
数据挖掘——RFM客户价值模型及航空公司客户分析实例
贪心算法之经典题目---订票
莱卡公司在多恩比恩全球纤维大会上推广近期的创新
2023年七牛云第二届1024创作节-校园黑客马拉松
Find My婴儿车|苹果Find My技术与婴儿车结合,智能防丢,全球定位
数据分析之pandas入门读书笔记
.NET周刊【10月第1期 2023-10-01】
leetcode 286 墙与门
SpringMVC 请求流程源码分析
- 原文地址:https://blog.csdn.net/qq_60750110/article/details/131802068
