-
Heap及其应用
目录
树本身的数据结构除了用与文件系统,在现实生活中应用是很少的,想要更广泛地使用这种数据结构,我们可以把树的节点存储在数组中,通过数组来访问和处理数据。
当然,并不是所有的树都适合使用数组来存储树中的数据,只有满二叉树/完全二叉树可以合适的使用,其他的树使用数组来存储,可能会造成一定的空间浪费,如图:
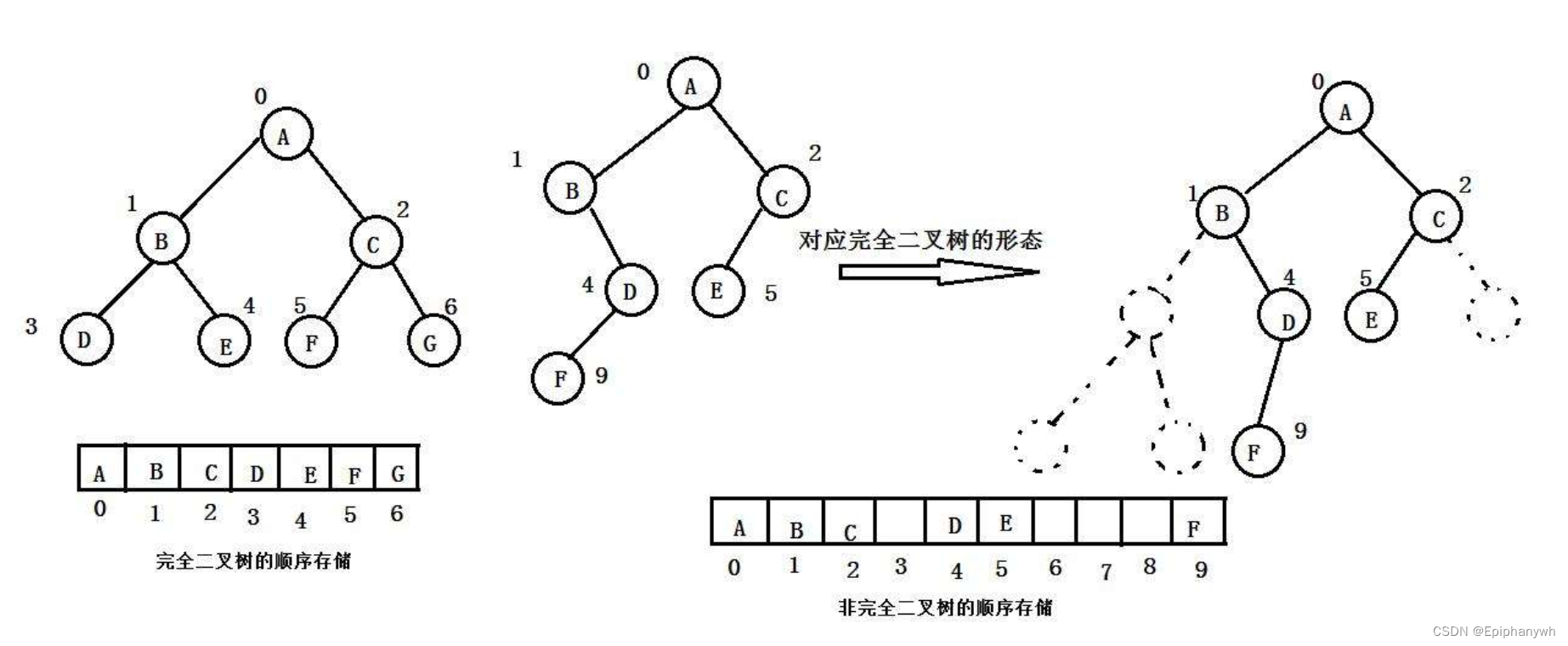 使用数组来存储就可以用来解决一些问题:堆排序、TopK问题……
使用数组来存储就可以用来解决一些问题:堆排序、TopK问题……这篇博客主要是如何实现一
堆的相关知识
在介绍堆之前,你还需要了解一下树节点的一些规律,下面实现堆的过程中将会使用到:
1. 若 i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
2. 若2i+1
3. 若2i+2
与之前的栈和队列一样,堆是一种特殊的数据结构,用于存储和组织数据,它是一种根据特定规则进行插入和删除操作的动态数据结构。堆通常是一个二叉树,其中每个节点都有一个与之关联的值。
-
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;(父节点的值大于等于其孩子节点的值,称为大堆;父节点小于等于其孩子节点的值,称为小堆)
- 堆总是一棵完全二叉树(满二叉树是一种特殊的完全二叉树)
这里补充一下:小堆根节点的值是所有节点中的最小值;大堆根节点的值是所有节点中的最大值。
因为小堆的父亲节点的值总是小于孩子节点的,从根节点往后的节点一定大于前面的节点;
对于大堆而言,也是同样的道理。
因为堆的存储结构是一个数组,所以可以将堆的存储结构可以看成一个顺序表。
堆的结构:
- typedef int HPDataType;
- // 堆的数据结构
- typedef struct Heap
- {
- HPDataType* data;
- int size;
- int capacity;
- }Heap;
下面以实现一个小堆为例:
(一)堆的插入
当我们插入一个节点进入堆中,就相当于在数组插入一个数(在数组中采用尾插效率较高,所以插入一个数会使用尾插的方法),并且还要保证插入这个数后,整个数组还满足上述堆的性质。这样我们就会发现,如何将这个数调整到一个合适的位置就至关重要。
向上调整法:
- 如果这个数小于父亲的值,就将数组中的值进行交换;
- 如果大于父亲的值,就结束操作,这个数插入成功。
之后重复上面这个步骤,直到这个数插入成功。这个步骤叫做向上调整法。
寻找父节点
那么如何找到当前位置的父亲节点呢?
还记得我开头的公式吗:
1. 若 i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点
2. 若2i+1
3. 若2i+2由公式可以得到父亲节点值的下标为:(当前下标 - 1)/ 2;
循环结束条件
既然需要重复这个过程,就可以用循环来实现,那循环结束的条件是什么呢?

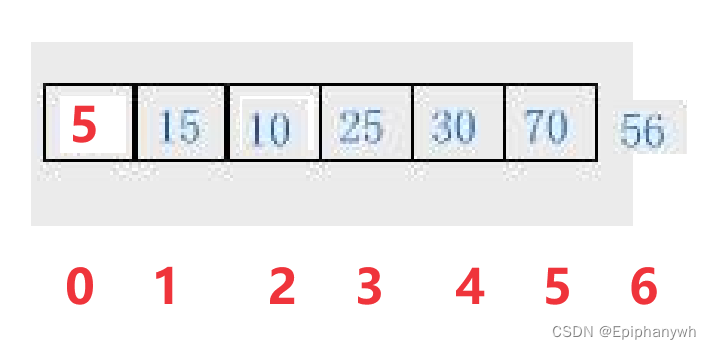
由图中可以观察到,最坏的情况是,插入的数是最小时,循环的结束条件应该是:当前下标为0;如果插入的数大于父亲节点的值时也要结束循环。
注意:
这里有人可能会用,父亲节点下标<0,作为循环结束条件,但是这样会产生一定的错误:
当要插入的数已经移动到根节点时,其下标为0,再用公式求得父亲节点的坐标得到 (0-1)/2 = 0,此时,父亲节点的坐标不小于0,循环继续,之后就会造成越界访问,出现错误。
代码:
- void Swap(HPDataType* a, HPDataType* b)
- {
- HPDataType temp = *a;
- *a = *b;
- *b = temp;
- }
- void AdjustUP(HPDataType* data, int child)
- {
- int parent = (child - 1) / 2;
- while (child > 0)
- {
- // 如果插入的数小于父亲节点,就交换
- if (data[child] < data[parent])
- {
- Swap(&data[child], &data[parent]);
- child = parent;
- parent = (parent - 1) / 2;
- }
- else
- break;
- }
- }
- void HeapPush(Heap* PHeap, HPDataType x)
- {
- assert(PHeap);
- // 判断是否还有空间可以用来插入数据
- if (PHeap->size == PHeap->capacity)
- {
- // 扩容
- HPDataType* temp = (HPDataType*)realloc(PHeap->data, sizeof(HPDataType) * PHeap->capacity * 2);
- if (temp == NULL)
- {
- perror("realloc failed");
- exit(-1);
- }
- PHeap->data = temp;
- PHeap->capacity = PHeap->capacity * 2;
- }
- // 尾插,插入数据
- PHeap->data[PHeap->size] = x;
- PHeap->size++;
- // 向上调整
- AdjustUp(PHeap->data, PHeap->size - 1);
- }
这里我是以实现一个小堆为例,所以在向上调整时使用的交换逻辑是 data[child] < data[parent] ,如果你想实现一个大堆,在不改变向上函数的主体的条件下,你可以使用回调函数,自己控制交换的逻辑。
(二)堆的删除
这里要删除的节点是根节点。
要删除根节点不能像数组删除一个数一样(向前覆盖),因为这样不能保证删除根节点之后,剩余的数还能构成一个小堆。
例如一个小堆的数据为:2 3 5 7 4 6 8,删除根节点后:3 5 7 4 6 8,就不能再构成一个小堆了
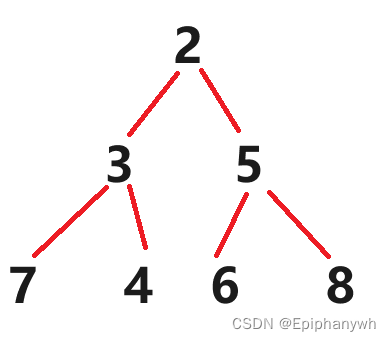
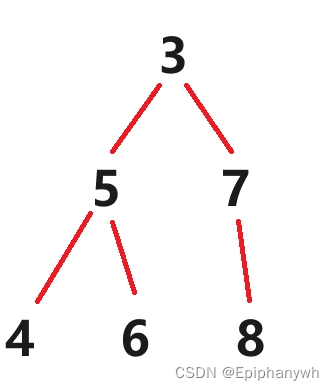
由图中可以发现,如果按上述删除方法来删除的话,节点之间的关系都可能发生变化:3和5原先是兄弟关系,现在变成了父子关系了。
删除根节点的正确方法:
-
将最后一个叶子节点(通常是最右侧的叶子节点)与根节点交换位置,以保持完全二叉树的性质;
-
删除最后一个叶子节点,在数组中的体现就是,数组的长度减一;
-
对新的根节点(原先的叶子节点)执行下沉操作/向下调整(percolate down),即将新的根节点与其子节点进行比较。如果子节点中存在比根节点更小的值,则将根节点与其中较小的子节点交换位置。重复此过程,直到新的根节点满足小堆的性质,即父节点的值小于等于子节点的值。
找到孩子节点
向下调整如何找到孩子节点,也是可以使用开头的公式的:
左孩子:childLeft = parent * 2 + 1;右孩子: childRight = parent * 2 + 2;
调整时,应该选择孩子中较小的,再与父亲节点的值进行比较、交换
循环结束条件
同样也是需要控制循环结束条件的:
孩子节点的下标不能超过总结点的个数-->所以我们还需要在向下调整函数中,将传递节点总个数作为参数。
代码:
- void AdjustDown(HPDataType* data, int n, int parent)
- {
- // n是节点的个数,用于循环的结束条件
- int child = parent * 2 + 1;
- while (child < n)
- {
- // 找到孩子中数值较小的孩子
- if (child + 1 < n && data[child] > data[child + 1])
- {
- child++;
- }
- // 调整
- if (data[parent] > data[child])
- {
- Swap(&data[parent], &data[child]);
- parent = child;
- child = parent * 2 + 1;
- }
- else
- break;
- }
- }
- void HeapPop(Heap* PHeap)
- {
- // 交换
- Swap(&PHeap->data[0], &PHeap->data[PHeap->size]);
- // 删除
- PHeap->size--;
- // 向下调整
- AjustDown(PHeap->data, PHeap->size, 0);
- }
需要注意的是,在找到较小孩子节点时,需要注意不要越界访问。
向上调整和向下调整:
向上调整:当要调整值的前面的值符合堆
和向下调整:当要调整值的后面的值符合堆,小堆:小的向上调,大的向下调
时间复杂度为log(N)--树的高度,N是节点的个数
(三)取堆顶的数据
堆顶的数据就是根节点的数据,所以可以直接返回堆顶的数据。
代码:
- HPDataType HeapTop(Heap* PHeap)
- {
- assert(PHeap);
- assert(PHeap->size > 0);
- return PHeap->data[0];
- }
因为经过删除一次之后,根节点的位置又是整个堆中(删除后)数值最小的,即删除前堆中次小的。所以通过 堆的删除 操作和 取堆顶的操作 后就可以得到排名前几个元素。
例如,在美团点餐时,app上会显示前几名的店铺,如果当地的店铺很多,使用排序效率就会比较低,但是使用这两个操作,就可以很快得到结果。
- int main()
- {
- int data[] = { 8,7,6,1,5,3,9 };
- Heap heap;
- HeapInit(&heap);
- for (int i = 0; i < sizeof(data) / sizeof(int); i++)
- {
- HeapPush(&heap, data[i]);
- }
- int k = 3;
- HeapPrint(&heap);
- while (!HeapEmpty(&heap) && k--)
- {
- printf("%d ", HeapTop(&heap));
- HeapPop(&heap);
- }
- HeapDestroy(&heap);
- return 0;
- }
通过这两个操作后,就可以的到数组中的前三名:

(四)堆的判空
与栈的判空逻辑一样。
- bool HeapEmpty(Heap* PHeap)
- {
- assert(PHeap);
- return PHeap->size == 0;
- }
堆的应用
(一)堆排序
由前面实现小堆的过程中,使用 取堆顶的数据 和 堆的删除 可以依次获得最小数,我们可以将每一次的堆顶的数据取出覆盖到要排序的数组中,就可以获得一个升序的数组。
代码:
- //堆排序
- void HeapSort(HPDataType* data, int n)
- {
- Heap heap;
- HeapInit(&heap);
- // 将数组中的数据存储到堆中
- for (int i = 0; i < n; i++)
- {
- HeapPush(&heap, data[i]);
- }
- int i = 0;
- while (!HeapEmpty(&heap))
- {
- // 去堆顶的元素覆盖到数组中
- data[i++] = HeapTop(&heap);
- HeapPop(&heap);
- }
- HeapDestroy(&heap);
- }
- int main()
- {
- int data[] = { 8,7,6,1,5,3,9 };
- HeapSort(data, sizeof(data) / sizeof(int));
- for (int i = 0; i < sizeof(data) / sizeof(int); i++)
- {
- printf("%d ", data[i]);
- }
- return 0;
- }
运行结果:
但是这种写法有一定的缺陷:
- 你首先需要有一个堆,才能使用;
- 排序需要额外开辟一个的空间,用来做堆。(虽然在排序完成后,将堆的这块空间销毁了,但是这也是有消耗的)
优化:
第一种实现方式,是开辟另外一块空间并使用要进行排序数组中的数,通过向上调整,使得开辟的空间成为一个堆,最后再依次将堆顶的数据取到数组中并删除堆顶(最小值)的值,最终,使要进行排序的数组成为一个升序/降序的数组。
那么我们可不可以直接在数组中,通过调整使要进行排序的数组成为一个堆,这样就不需要再开辟空间了。
使用建立小堆实现升序:
我们先来看一段错误的代码,分析一下建立小堆的过程。
- void AdjustUp(HPDataType* data, int child)
- {
- int parent = (child - 1) / 2;
- while (child > 0)
- {
- // 如果插入的数小于父亲节点,就交换
- if (data[child] < data[parent])
- {
- Swap(&data[child], &data[parent]);
- child = parent;
- parent = (parent - 1) / 2;
- }
- else
- break;
- }
- }
- //堆排序
- void HeapSort(HPDataType* data, int n)
- {
- // 将数组中的数据调整成为一个堆
- for (int i = 1; i < n; i++)
- {
- AdjustUp(data, i);
- }
- }
- int main()
- {
- int data[] = { 8,7,6,1,5,3,9 };
- HeapSort(data, sizeof(data) / sizeof(int));
- for (int i = 0; i < sizeof(data) / sizeof(int); i++)
- {
- printf("%d ", data[i]);
- }
- return 0;
- }
运行结果:

分析:
从运行结果中可以发现,排序的结果不对,这是为什么?
这是因为,与优化前的那种方法相比,这种方法只是将要排序的数组变成了一个堆(即将最小值调整到根节点的位置上),这也就意味着,去掉第一个数后,后面的数组成的树(5,3,8,6,7,9)就不再是一个堆了,导致的结果就是,第二个数(也就是5)不再是次小值了。
而优化前,我们取出堆顶元素(最小值)到要排序的数组中后进行了删除堆的操作,这个操作不仅可以将最小值删除掉,而且把次最小值移动到根节点的位置,然后再一次取堆顶元素到要排序的数组中,就可以取到次最小值,以此类推,要排序的数组就是一个升序的数组。
既然根节点后面的值不再是堆,那我们可以将后面的值再看作一个数组继续使用向上调整法,使得后面的数据成为一个小堆,这样第二个数就是次小值了,依次类推直到排序完成。
具体步骤:
-
构建小堆:将待排序的数组看作一个完全二叉树,从第二个节点开始,对每个节点进行向上调整操作,将数组转化为小堆。
-
排序阶段:将小堆中的根节点(最小值)后面的值再看作一个数组继续使用向上调整法使其一个小堆。
-
重复以上步骤,直到堆中只剩下一个元素。经过这些步骤之后,原始数组就会被排序。
时间复杂度的分析:

使用建立大堆实现升序:
具体步骤:
-
构建大堆:将待排序的数组看作一个完全二叉树,从最后一个非叶子节点开始,从右至左对每个节点进行向下调整操作,将数组转化为大堆。向下调整操作的目的是确保父节点的值大于等于其子节点的值。
-
排序阶段:将大堆中的根节点(最大值)与数组中的最后一个元素交换位置,并将最后一个元素从堆中移除(相当于将其视为已排序部分)。然后,对交换后的根节点执行一次向下调整操作,将最大值移至堆的根节点。
-
重复以上步骤,直到堆中只剩下一个元素。经过这些步骤之后,原始数组就会被排序
还是使用上面的数据,构成大堆的结果为:9 7 8 1 5 3 6
时间复杂度分析:

代码:
- void Swap(HPDataType* a, HPDataType* b)
- {
- HPDataType temp = *a;
- *a = *b;
- *b = temp;
- }
- void AdjustUp(HPDataType* data, int child)
- {
- int parent = (child - 1) / 2;
- while (child > 0)
- {
- // 如果插入的数小于父亲节点,就交换
- if (data[child] > data[parent])
- {
- Swap(&data[child], &data[parent]);
- child = parent;
- parent = (parent - 1) / 2;
- }
- else
- break;
- }
- }
- void AdjustDown(HPDataType* data, int n, int parent)
- {
- // n是节点的个数,用于循环的结束条件
- int child = parent * 2 + 1;
- while (child < n)
- {
- // 找到孩子中数值较小的孩子
- if (child + 1 < n && data[child] < data[child + 1])
- {
- child++;
- }
- // 调整
- if (data[parent] < data[child])
- {
- Swap(&data[parent], &data[child]);
- parent = child;
- child = parent * 2 + 1;
- }
- else
- break;
- }
- }
- //堆排序
- void HeapSort(HPDataType* data, int n)
- {
- // 将数组中的数据调整成为一个大堆
- for (int i = 1; i < n; i++)
- {
- AdjustUp(data, i);
- }
- int end = n - 1; //交换最后一个元素的下标和堆元素个数
- while (end > 0)
- {
- // 大堆中的根节点(最大值)与数组中的最后一个元素交换位置
- Swap(&data[0], &data[end]);
- // 向下调整
- AdjustDown(data, end, 0);
- end--; // 从堆中删除最后一个元素
- }
- }
- int main()
- {
- int data[] = { 8,7,6,1,5,3,9 };
- HeapSort(data, sizeof(data) / sizeof(int));
- for (int i = 0; i < sizeof(data) / sizeof(int); i++)
- {
- printf("%d ", data[i]);
- }
- return 0;
- }
综合下来看,建立一个大堆实现升序是效率较高的做法;同样的道理,建立一个小堆实现降序是效率较高的做法。
注意:向上和向下调整的判断逻辑要根据你要建立的是大/小堆来确定。
(二)建堆的两种方法
建一个大/小堆有两种方法,一种是使用向上调整法;一种是使用向下调整法,下面就介绍一下两种方法的区别:
使用向上调整法建立一个大堆:
向上调整法在前面实现堆的插入时,已经讲过它的思路了,其主要思想就是在数组中尾插一个数,不过要将这个数调整的合适的位置,从数组中第二数开始使用向上调整,直到最后一个节点完成向上调整。其一次向上调整的时间复杂度是logN,共需要调整(N-1)个数,时间复杂度是N*logN;
使用向上调整的前提条件是,要调整节点前面是一个堆。如果你想要在最后一个节点使用向上调整,就需要保证其前面是一个堆,前面又要保证它前面是一个堆……递归下去,就需要从第二个节点开始(第一个数是根节点)。
使用向下调整法建立一个大堆:
使用向下调整的前提条件是,要调整节点后面是一个堆。同样的递归套路,最后需要从最后一个节点先前使用向下调整,而最后一个节点是叶子节点,不需要调整,所以就从最后一个叶子节点 60 的父亲节点 6 开始,然后是对节点 4 使用向下调整、对节点 7 使用向下调整、对节点 5 使用向下调整……而向前移动可以通过数组坐标-1获得。

代码:- for (int i = (n - 1 - 1) / 2; i >= 0; i--)
- {
- AdjustDown(data, n, i);
- }
(n-1)是最后一个叶子节点的下标,然后再带入公式parent =(child-1)/ 2;
向上/向下调整建堆的时间复杂度分析:
向上调整建堆:

所以时间复杂度就是O(N*logN - N) -- O(N*logN)。
向下调整建堆:

所以时间复杂度就是O(N - logN) -- O(N)。
从代码中看,感觉两种方法时间复杂度都是N*logN,但是向下调整的时间复杂度较小,两者主要的差距在于:
对于向下调整法而言,最后一层节点不需要调整,并且从下到上调整的次数从小到大;
对于向上调整法而言,第一层节点不需要调整,并且从上到下调整的次数从小到大。
但是节点个数随着层数的增加而增加,每层所有节点需要调整的次数 = 节点个数 * 一个节点需要调整的次数(向上/向下的层数)。所以,对于向下调整法而言,多节点数 * 少调整次数;对于向上调整法而言,多节点数 * 多调整次数。
所以,虽然向上调整法和向下调整法调整一次的时间复杂度是O(logN),但是加上节点个数的影响,使得总体的时间复杂度产生了很大的变化。
(三)TopK问题
想要获得一个数组中前几个最小/大的值,可以使用前面我们提到的方法:
①可以数组中的数转化为小堆,可以用Push额外开辟一个堆空间,依次取堆顶的数据,然后再删除堆(删除堆顶);
②也可以使用堆排序,取前几个数。
但是这两种方法,都是需要将数据存储再内存中,然后再对内存中的数据进行处理。当数据较大时,内存空间不能容纳这么多的数据,数据只能存放在文件中,前两种方法就不再适用了。
这里先给出步骤,后面再解释:
步骤:
- 先读取文件中的前100个数据,并存放在内存中建立一个小堆;
- 再依次读取剩余元素,每读取一个数据,用它与堆顶元素比较:如果它大于堆顶元素,就用它替换堆顶元素,并向下调整;
- 当读取完所有的数后,堆中的数据就是最大的前K个。
代码:
- void AdjustDown(HPDataType* data, int n, int parent)
- {
- // n是节点的个数,用于循环的结束条件
- int child = parent * 2 + 1;
- while (child < n)
- {
- // 找到孩子中数值较小的孩子
- if (child + 1 < n && data[child] > data[child + 1])
- {
- child++;
- }
- // 调整
- if (data[parent] > data[child])
- {
- Swap(&data[parent], &data[child]);
- parent = child;
- child = parent * 2 + 1;
- }
- else
- break;
- }
- }
- void PrintTopk(const char* filename, int k)
- {
- // 打开文件
- FILE* fout = fopen(filename, "r");
- if (fout == NULL)
- {
- perror("fopen fail");
- exit(-1);
- }
- // 开辟堆空间
- int* minheap = (int*)malloc(sizeof(int) * k);
- if (minheap == NULL)
- {
- perror("malloc");
- exit(-1);
- }
- // 先读取前K个元素
- for (int i = 0; i < k; i++)
- {
- fscanf(fout, "%d", &minheap[i]);
- }
- // 使用向下调整法,建立小堆
- for (int i = (k - 2) / 2; i >= 0; i--)
- {
- AdjustDown(minheap, k, i);
- }
- // 读取剩余元素
- int x = 0;
- while (fscanf(fout, "%d", &x) != EOF)
- {
- // 判断是否大于堆顶元素
- if (x > minheap[0])
- {
- //覆盖,并向下调整
- minheap[0] = x;
- AdjustDown(minheap, k, 0);
- }
- }
- fclose(fout);//关闭文件
- fout = NULL;
- for (int i = 0; i < k; i++)
- {
- printf("%d ", minheap[i]);
- }
- printf("\n");
- }
- void CreatData()
- {
- // 在文件中写一些数据,用于测试
- int n = 10000;
- srand(time(0));
- FILE* fwrite = fopen("test.txt", "w");
- if (fwrite == NULL)
- {
- perror("fopen");
- exit(-1);
- }
- //写入数据
- for (int i = 0; i < n; i++)
- {
- int x = rand() % 1000000;
- fprintf(fwrite, "%d\n", x);
- }
- fclose(fwrite);
- fwrite = NULL;
- }
- int main()
- {
- //CreatData();
- PrintTopk("test.txt", 10);
- return 0;
- }
为什么不能使用大堆?
因为当最大的数进堆时,会将这个值与堆顶元素替换后,再向下调整,这个数还是在堆顶,这样就导致再读取其他的数据(真正Topk的数)时就不能进入堆了,这样堆中就不是TopK个元素了。
使用小堆,使得小的数浮在上面而大的数下沉到下面。
复杂度:
时间复杂度为:O(N*logK);
空间复杂度为:O(K)。
今天的分享就到这里了,如果,你感觉这篇博客对你有帮助的话,就点个赞吧!感谢感谢……
-
-
相关阅读:
Go简单实现协程池
Hadoop、Hive、Spark是什么关系
Chapter 4 分类
快解析结合泛微OA
DSPE-PEG-Silane,DSPE-PEG-SIL,磷脂-聚乙二醇-硅烷可修饰材料表面
基于springboot实现房源出租信息系统演示【附项目源码+论文说明】
计算机组成原理——系统总线
Redis存储数据
数组的reduce和reduceRight方法
Redux系列实现异步请求
- 原文地址:https://blog.csdn.net/2201_75479723/article/details/132788107
