-
16-GuliMall ElasticSearch安装分词器
1.安装Xftp
有了Xftp就可以使用Xshell进行文件传输, 这样操纵虚拟机就比较方便
Xftp下载安装安装成功
2.安装分词器
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立的单词),然后输出 tokens 流。 例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 “Quick brown fox!” 分割 为 [Quick, brown, fox!]。 该 tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短 语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start (起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。 Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
1.安装 ik 分词器
es默认只有因为的分词器,就也就只能识别英文的词语, 但是对于中文词语或成语就不能识别, 所以我们需要安装中文分词器,也就是ik分词器
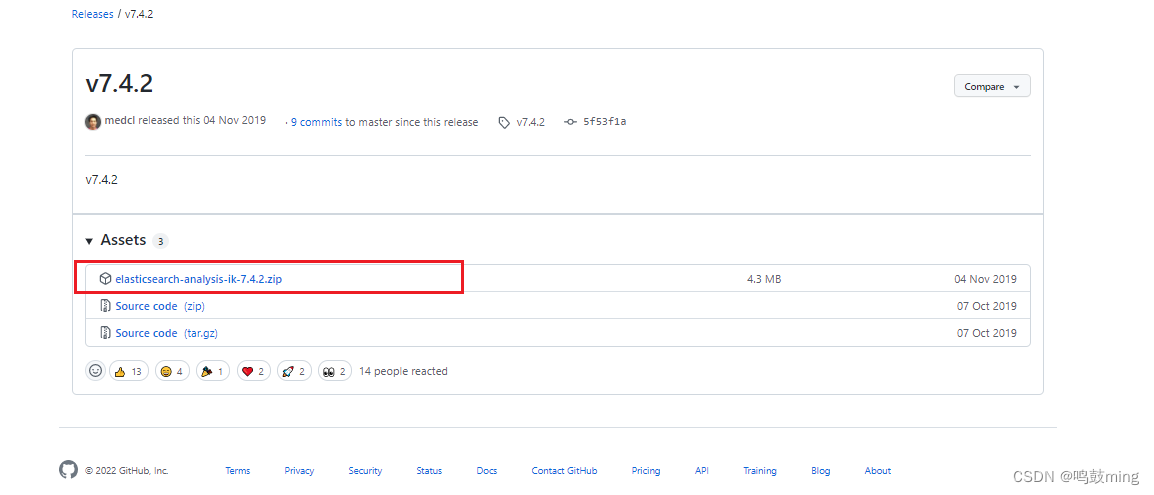
注意:不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装 https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2
对应 es 版本安装, 我的版本是v7.4.2
下载并解压(文件夹名字随便改, 为了方便我改成了ik)
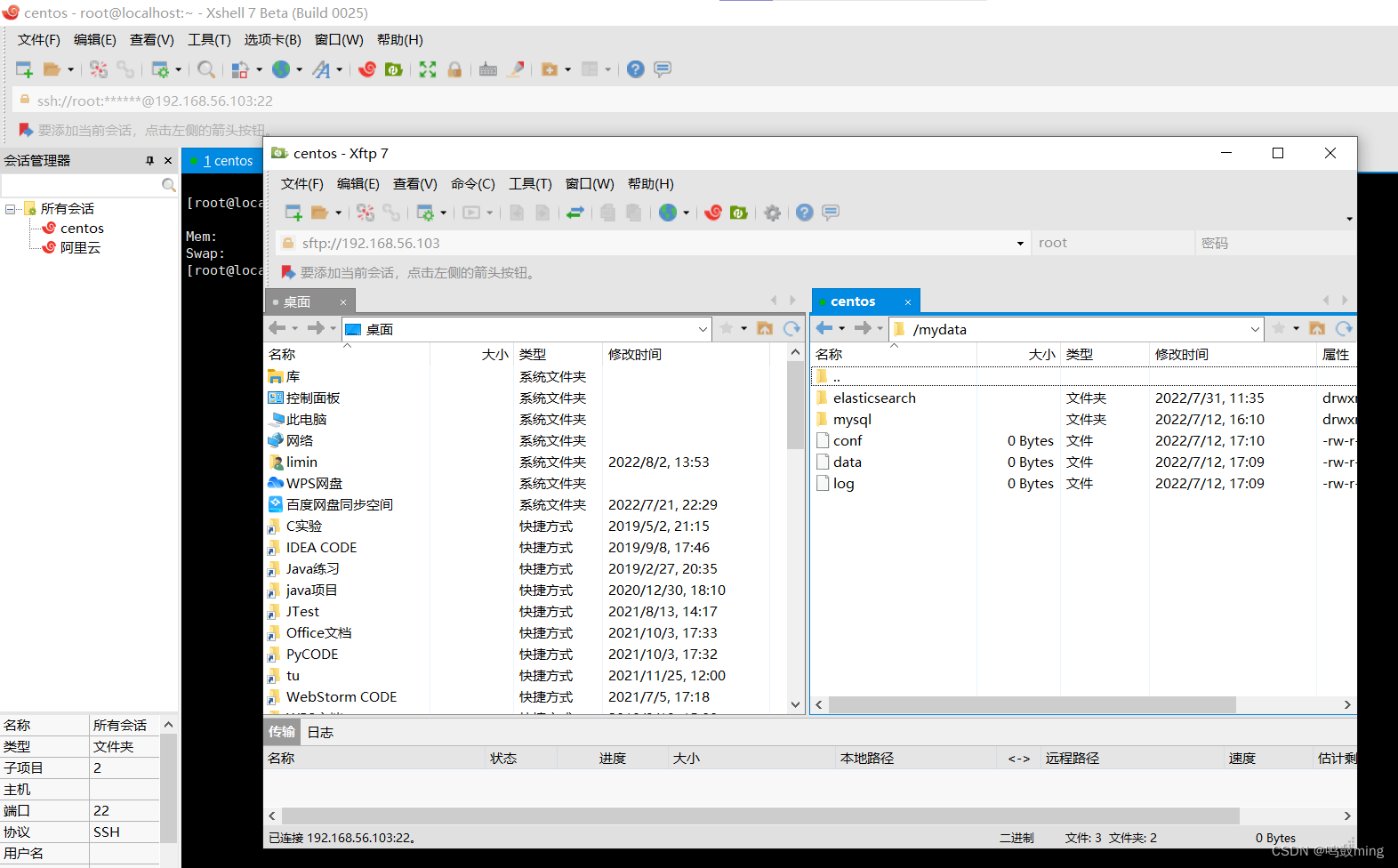
使用Xftp把ik整个文件夹复制粘贴到es的挂载目录的plugins目录里
并设置ik目录权限全部人可读可写
重启esdocker restart 容器id- 1
2.测试分词器
1.先测试默认的分词器
POST _analyze { "text": "我是中国人" }- 1
- 2
- 3
- 4
响应数据
{ "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "" , "position" : 0 }, { "token" : "是", "start_offset" : 1, "end_offset" : 2, "type" : "" , "position" : 1 }, { "token" : "中", "start_offset" : 2, "end_offset" : 3, "type" : "" , "position" : 2 }, { "token" : "国", "start_offset" : 3, "end_offset" : 4, "type" : "" , "position" : 3 }, { "token" : "人", "start_offset" : 4, "end_offset" : 5, "type" : "" , "position" : 4 } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
可以看到默认的分词器是无法识别中文词语
2.使用ik分词器
POST _analyze { "analyzer": "ik_smart", "text": "我是中国人" }- 1
- 2
- 3
- 4
- 5
响应数据
{ "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "是", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 }, { "token" : "中国人", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 2 } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
POST _analyze { "analyzer": "ik_max_word", "text": "我是中国人" }- 1
- 2
- 3
- 4
- 5
{ "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "是", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 }, { "token" : "中国人", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 2 }, { "token" : "中国", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 3 }, { "token" : "国人", "start_offset" : 3, "end_offset" : 5, "type" : "CN_WORD", "position" : 4 } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
能够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默 认的 mapping 了,要手工建立 mapping, 因为要选择分词器。
3.自定义词库
修改ik分词器的配置文件 IKAnalyzer.cfg.xml, 文件可以通过挂载目录修改
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置comment> <entry key="ext_dict">entry> <entry key="ext_stopwords">entry> <entry key="remote_ext_dict">http://192.168.56.103:80/es/words.txtentry> properties>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这个远程访问资源链接我们可以在web项目写一个服务接口来响应这么一个扩展字典数据, 也可以使用nginx来创建接口并返回数据.这里我们使用ngnix.
1.安装ngnix
先随便启动一个 nginx 实例,只是为了复制出配置目录和文件
docker pull nginx:1.10 docker run -p 80:80 --name nginx -d nginx:1.10- 1
- 2
使用命令进入到挂载目录mydata(哪个目录都行, 你可以自己创建一个)
cd /mydata- 1
将容器内的配置文件拷贝到当前目录, 也就是mydata目录
docker container cp nginx:/etc/nginx .- 1
解释一下这个命令 docker container cp 表示复制容器的内容 nginx 是容器的名字 /etc/nginx 是容器内的文件夹 点"."前面有一个空格,别漏了- 1
- 2
- 3
- 4
- 5
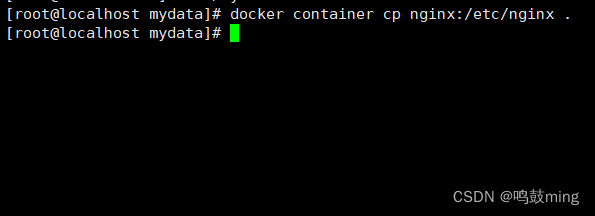
复制成功
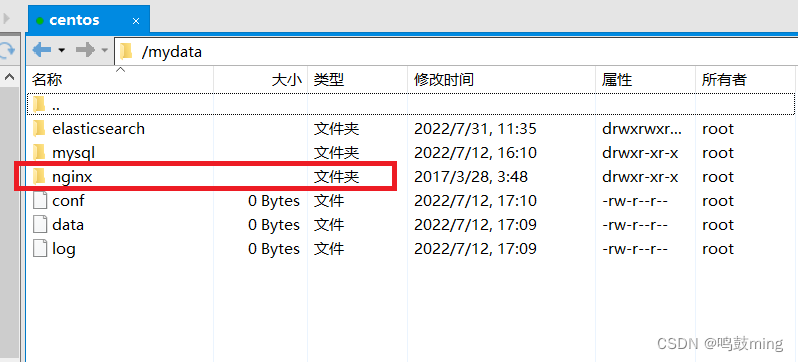
为了方便管理把nginx改名为conf, 并给它创建一个父目录也叫ngnix(可以用命令修改, 我就直接使用Xftp修改, 比较快)
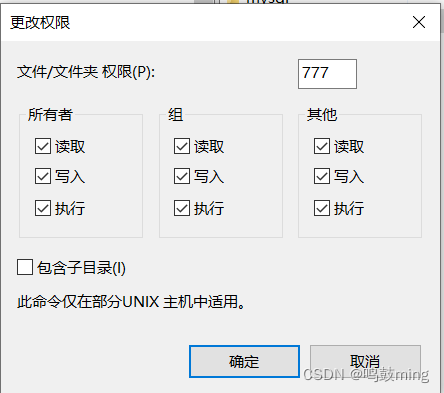
并设置ngnix文件夹全部人可读可写
删除原来的ngnix容器, 并创建新的ngnix容器
docker stop nginx- 1
docker rm $ContainerId- 1

docker run -p 80:80 --name nginx \ -v /mydata/nginx/html:/usr/share/nginx/html \ -v /mydata/nginx/logs:/var/log/nginx \ -v /mydata/nginx/conf:/etc/nginx \ --restart=always \ -d nginx:1.10- 1
- 2
- 3
- 4
- 5
- 6
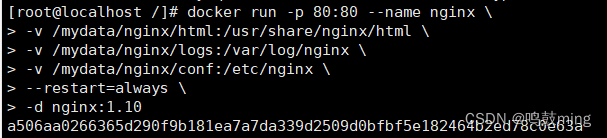
当我们设置文件挂载后, 发现容器总是无法正常启动, 这是因为CentOS7中的安全模块selinux把权限禁掉了,无法使用-v命令进行挂载

解决方法:添加selinux规则,将要挂载的目录添加到白名单
chcon -Rt svirt_sandbox_file_t /mydata/nginx/html chcon -Rt svirt_sandbox_file_t /mydata/nginx/logs chcon -Rt svirt_sandbox_file_t /mydata/nginx/conf- 1
- 2
- 3

重启nginxdocker restart 容器id- 1

在挂载目录/mydata/nginx/html里创建一个index.html文件
内容如下(随便写点正确html语言就行)<h1>welcome to ngnixh1>- 1
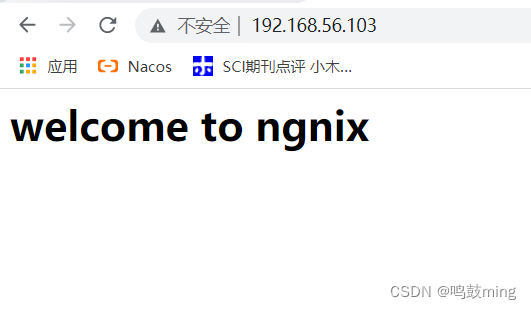
浏览器访问ngnix
http://192.168.56.103:80- 1
这样就表示ngnix安装成功了
2.添加自定义词库文件
1.在此之前, 我们先看看没添加自定义词库的效果
POST _analyze { "analyzer": "ik_smart", "text": "尚硅谷有一个乔碧萝老师" }- 1
- 2
- 3
- 4
- 5
响应数据
{ "tokens" : [ { "token" : "尚", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "硅谷", "start_offset" : 1, "end_offset" : 3, "type" : "CN_WORD", "position" : 1 }, { "token" : "有", "start_offset" : 3, "end_offset" : 4, "type" : "CN_CHAR", "position" : 2 }, { "token" : "一个", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 3 }, { "token" : "乔", "start_offset" : 6, "end_offset" : 7, "type" : "CN_CHAR", "position" : 4 }, { "token" : "碧", "start_offset" : 7, "end_offset" : 8, "type" : "CN_CHAR", "position" : 5 }, { "token" : "萝", "start_offset" : 8, "end_offset" : 9, "type" : "CN_CHAR", "position" : 6 }, { "token" : "老师", "start_offset" : 9, "end_offset" : 11, "type" : "CN_WORD", "position" : 7 } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
可以看到默认 尚硅谷, 乔碧萝 这个两个词语是无法识别的
2.在挂载目录/mydata/ngnix/html里创建es文件夹, 并在里面创建词库文件words.txt
words.txt内容就是添加我们的自定义词语尚硅谷 乔碧萝- 1
- 2
这里再次提醒一下
要修改ik分词器的配置文件 IKAnalyzer.cfg.xml, 文件可以通过挂载目录
/mydata/elasticsearch/plugins/ik/config 修改(也可以进入docker容器内部修改)

DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置comment> <entry key="ext_dict">entry> <entry key="ext_stopwords">entry> <entry key="remote_ext_dict">http://192.168.56.103:80/es/words.txtentry> properties>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里解释一下 http://192.168.56.103:80/es/words.txt nginx会默认把 http://192.168.56.103:80(或 http://192.168.56.103) 映射到ngnix/html文件夹 /es/words.txt就是我们的词库文件在ngnix/html文件夹中的位置- 1
- 2
- 3
3.重启es
docker restart 容器id- 1
3.测试
POST _analyze { "analyzer": "ik_smart", "text": "尚硅谷有一个乔碧萝老师" }- 1
- 2
- 3
- 4
- 5
响应数据
{ "tokens" : [ { "token" : "尚硅谷", "start_offset" : 0, "end_offset" : 3, "type" : "CN_WORD", "position" : 0 }, { "token" : "有", "start_offset" : 3, "end_offset" : 4, "type" : "CN_CHAR", "position" : 1 }, { "token" : "一个", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 2 }, { "token" : "乔碧萝", "start_offset" : 6, "end_offset" : 9, "type" : "CN_WORD", "position" : 3 }, { "token" : "老师", "start_offset" : 9, "end_offset" : 11, "type" : "CN_WORD", "position" : 4 } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
可以看到自定义分词成功了
-
相关阅读:
go语言中的数组指针和指针数组的区别详解
OA系统、ERP系统、MIS系统的区别
【C++】string 类 ( 上)
网工内推 | 实施工程师,有软考证书优先,上市公司,最高14薪
Docker学习笔记(二)
从化区委刘棕会访从玉农业 林裕豪:再入大湾区菜篮子工程
js继承,原型链继承,构造函数继承,组合式继承,原型式继承,寄生式继承,组合寄生式继承,extends继承
【单片机】14-I2C通信之EEPROM
python进阶系列 - 13讲 生成器generator
数仓GreenPlum中数据实时同步的方式
- 原文地址:https://blog.csdn.net/qq_41865229/article/details/126124423
