-
【办公自动化】用Python批量从上市公司年报中获取主要业务信息

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

目录
一、Python处理PDF
-
Python处理PDF的好处
-
自动化和批量处理:使用Python,你可以自动处理大量的PDF文件,例如从扫描仪生成的文档、报告、合同等。这可以节省大量时间和努力,尤其是在需要重复性任务时。
-
文本提取:Python可以轻松地从PDF中提取文本内容,使其可搜索、可编辑和可分析。这对于文本分析、数据挖掘和文档检索等任务非常有用。
-
报告生成:你可以使用Python创建自定义的PDF报告,将数据、图表和图像等信息以专业的方式呈现。这对于生成自动化的业务报告、数据可视化和数据分析很有帮助。
-
PDF编辑:Python库和工具使你能够合并、拆分、旋转、裁剪和编辑PDF文件的页面。这对于在不使用专业PDF编辑软件的情况下进行简单的文档编辑很有用。
-
图像提取:Python允许你从PDF文件中提取图像,这对于处理包含图形、图表和图片的文档非常有帮助。
-
数据提取:当PDF文件包含表格或结构化数据时,Python可以用于提取和转换这些数据,以便进一步分析或导入到数据库中。
-
自定义处理:Python提供了多种用于PDF处理的库,允许你根据项目的需求进行自定义处理。你可以选择适合你需求的库,以满足具体要求。
-
跨平台:Python是跨平台的,因此你可以在不同操作系统上运行相同的代码,而无需担心兼容性问题。
Python处理PDF文件的主要第三方库包括:
-
PyPDF2:PyPDF2是一个用于处理PDF文件的库,可以用于提取文本、合并、拆分和旋转PDF文件的页面。它还支持添加页面、水印和书签等功能。
-
ReportLab:ReportLab是一个用于创建PDF文件的库,允许你以编程方式构建PDF文档,包括添加文本、图像、表格等。
-
PDFMiner:PDFMiner是一个用于提取文本和元数据的PDF处理库。它可以解析PDF文件并提取文本、布局信息和链接等。
-
pdf2image:pdf2image是一个用于将PDF文件转换为图像的库,这对于处理包含图形的PDF文件非常有用。
-
fpdf2:fpdf2是一个用于创建PDF文件的库,支持自定义字体、图像和表格等。
-
PyMuPDF:PyMuPDF是一个用于处理PDF文件的库,可以用于提取文本、图像和元数据。它还支持PDF文件的渲染和转换为图像。
-
Camelot:Camelot是一个用于提取表格数据的库,特别适用于从PDF文件中提取表格数据。
-
Tabula-py:Tabula-py是一个用于提取表格数据的库,可将PDF中的表格转换为DataFrame对象。
-
开发环境
操作系统:使用windows, mac都可以
Python版本:系统中需要安装Python3.6以上的版本,Python2已经过期不建议使用,Python3.6以前的版本功能相对弱,最好就是采用Python3.6以上的版本
开发工具:有两个可以选择,jupyter notebook,是个网页编辑器,可以运行Python,常常用于交互性、探索性的开发;pycharm,用于成熟脚本,或者web服务的一些开发;这两个工具可以随意选择。
二、用Python将PDF文件转存为图片
技术工具:
Python版本:3.9
代码编辑器:jupyter notebook
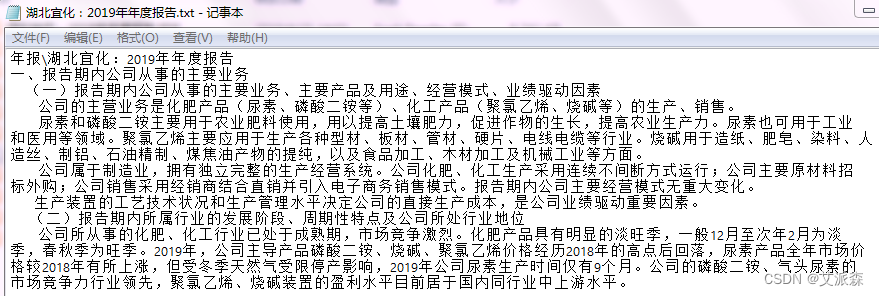
要求批量从上市公司年报中截取公司从事的主要业务信息,以便进行后续的分析。首先我们要分析一下上市公司年报的结构,及目标信息所在位置。一般上市公司的年报都是公开的,可随意下载。其格式一般是PDF。年报内容包含的板块几乎相同,只是深圳市场与上海市场略有区别。随机挑选了10家上市公司的年报(如下图)。可见,公司业务都位于“第三节公司业务概要”,只是上海市场的年报,“第三节”后有空格。其所在页基本在8,9,10页。“第三节”里的第一个小标题,两个市场也有点不同。主要业务介绍完后,接下来都是介绍“主要资产重大变化情况”,这部分及以后的内容都不是我们想要的。因此,打算确定关键词“公司业务概要”及“重大变化情况”,作为文字截取的起始关键词。当然,如果年报中还有其它内容也涉及到这两个词,就会造成干扰。保险起见,在PDF文档内搜索一下,运气不错,这两个关键词在文档中是唯一的,也就是只在这两个地方出现。那就可以放心干了。

以下,先随便找一家上市公司的年报来测试一下。先导入`pdfplumber`模块,用于提取Pdf文件中的文字(也可以用PyPDF2模块,但读取中文容易出错,因此放弃)。然后设定关键词“重大变化情况”,作为停止搜索标志(这个词后面的内容不是我们想要的)。再打开PDF文件,从第7页开始提取文字,26页终止(因为绝大部分年报的“主要业务”内容在8~15页,有个别到23页了)。将每页的文字信息存入`data`字典。再用`if`语句设定一个终止程序,即当关键词“重大变化情况”出现在当页的内容中时,就停止后续的读取了,因为后续读取到的内容已经不是我们想要的了。这样可以节省时间。打个比方,如果我们要的内容在8~9页,程序只会提取7~9页的内容,后面就不会再提取了。
- #获取年报中的“主要业务”信息
- import pdfplumber
- file = r"年报\东旭蓝天:2019年年度报告.PDF"
- data = []
- key_words = "重大变化情况"
- with pdfplumber.open(file) as p:
- for i in range(6,26): #公司主要业务主要年报的在8~23页范围内
- page = p.pages[i] #选页
- page_text = page.extract_text() #提取文字
- data.append(page_text) #将提取的文字加入列表
- if key_words in page_text: #到结束关键词即结束抓取信息,避免浪费时间
- break # 终止for循环
得到的结果如下:
data
然后,我们就用开始关键词“公司业务概要”和结束关键词“重大变化情况”来截取二者之间的文字。先定义一个文字截取函数,传入起始关键词,及待处理的字符串。通过`find()`方法确定起始关键词对应的位置索引,然后截取二者之间的字符。
- #从字符串中提取指定首尾的文字
- def Get_text(start_str, end_str, source_str):
- start = source_str.find(start_str) #找到开始关键词对应的位置索引
- if start >= 0:
- start += len(start_str)
- end = source_str.find(end_str, start)#找到结束关键词对应的位置索引
- if end >= 0:
- return source_str[start:end].strip() #截取起始位置之间的字符
- #将数据列表`data`转换成一个大字符串
- source_str = "".join(data)
- #截取文字
- start_str = "公司业务概要"
- end_str = "重大变化情况"
- text_wanted = Get_text(start_str, end_str, source_str)
- text_wanted

以上,就把想要的内容基本提取出来了。但最后那个几个字“二、主要资产”不是我们要的,因此需要将其去除。先将以上字符串`text_wanted`按照换行符“\n”进行分割,在砍掉最后一个元素,即可得到最终想要的字符串。
- final_text = text_wanted.split("\n")[:-1]
- final_text

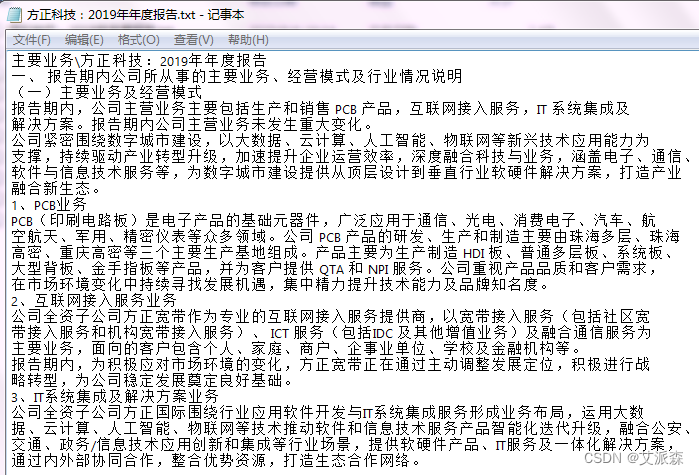
将以上字符串写入txt文件,并按公司名称命名保存。写入的txt文件结果如下:
- #定义写入txt的函数
- def To_txt(filename, final_text):#filename为写入文件的路径,data为要写入数据列表.
- file = open(filename + '.txt','w',encoding="utf-8")
- file.write(filename + "\n")
- for i in range(len(final_text)):
- text = final_text[i]
- if i != len(final_text)-1: #判断是否最后一个元素
- text = text+'\n' #若不是最后一个元素才换行
- file.write(text)
- file.close()
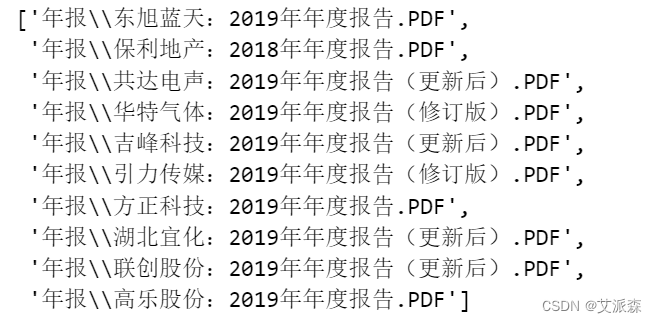
- To_txt(r"年报\东旭蓝天:2019年年度报告",final_text)
成功搞定一个之后,我们就可以批量处理了。将待处理的年报放入指定路径,然后获取其路径,存入列表`files`。稍微整合一下程序,运行。10份年报,用时144秒,平均1份年报14秒。
- #获取待处理的年报的路径
- import os
- path='年报' #文件所在文件夹
- files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
- files
- import pdfplumber
- import time
- time0= time.time()
- #从字符串中提取指定首尾的文字
- def Get_text(start_str, end_str, source_str):
- start = source_str.find(start_str) #找到开始关键词对应的位置索引
- if start >= 0:
- start += len(start_str)
- end = source_str.find(end_str, start)#找到结束关键词对应的位置索引
- if end >= 0:
- return source_str[start:end].strip() #截取起始位置之间的字符
- #定义写入txt的函数
- def To_txt(filename, final_text):#filename为写入文件的路径,data为要写入数据列表.
- file = open(filename + '.txt','w',encoding="utf-8")
- file.write(filename + "\n")
- for i in range(len(final_text)):
- text = final_text[i]
- if i != len(final_text)-1: #判断是否最后一个元素
- text = text+'\n' #若不是最后一个元素才换行
- file.write(text)
- time.sleep(0.1) #加入一个延时,避免批量写入出现乱码
- file.close()
- #获取年报中的“主要业务”信息
- for file in files:
- data = []
- key_words = "重大变化情况"
- with pdfplumber.open(file) as p:
- for i in range(6,26): #公司主要业务主要年报的在8~23页范围内
- page = p.pages[i] #选页
- page_text = page.extract_text() #提取文字
- data.append(page_text) #将提取的文字加入列表
- if key_words in page_text: #到结束关键词即结束抓取信息,避免浪费时间
- break # 终止for循环
- #将数据列表`data`转换成一个大字符串
- source_str = "".join(data)
- #截取文字
- start_str = "公司业务概要"
- end_str = "重大变化情况"
- text_wanted = Get_text(start_str, end_str, source_str)
- #去掉不需要的尾巴
- final_text = text_wanted.split("\n")[:-1]
- new_file = "主要业务\\" + file.split("\\")[1][:-4]
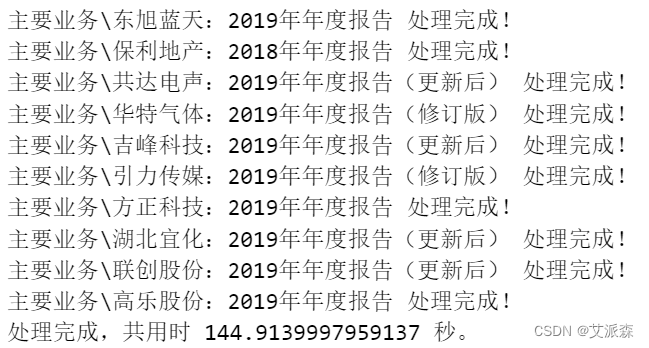
- To_txt(new_file,final_text)
- print("{} 处理完成!".format(new_file))
- time1= time.time()
- print("处理完成,共用时 {} 秒。".format(time1-time0))
三、往期推荐
四、文末推荐与福利

清华社【秋日阅读企划】领券立享优惠
IT好书 5折叠加10元无门槛优惠券:https://u.jd.com/Yqsd9wj
活动时间:9月4日-9月17日,先到先得,快快来抢!








-
-
相关阅读:
c++ 服务器编程tcp
Django(三、数据的增删改查、Django生命周期流程图)
leecode1123. 最深叶节点的最近公共祖先
vue项目打包部署流程
LeetCode地平线专场——第308场周赛题解
探讨Java死锁的现象和解决方法
接口测试的概念、目的、流程、测试方法有哪些?
uniapp-video自定义视频封面
Linux一行命令筛选并停止某个服务的进程
关于汽车html网页设计完整版,10个以汽车为主题的网页设计与实现
- 原文地址:https://blog.csdn.net/m0_64336780/article/details/132818914